本文主要是介绍【APP_TYC】数据采集案例天眼APP查_查壳脱壳反编译_③,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
是不是生活太艰难 还是活色生香
我们都遍体鳞伤 也慢慢坏了心肠
你得到你想要的吗
换来的是铁石心肠
可曾还有什么人 再让你幻想
🎵 朴树《清白之年》
查壳
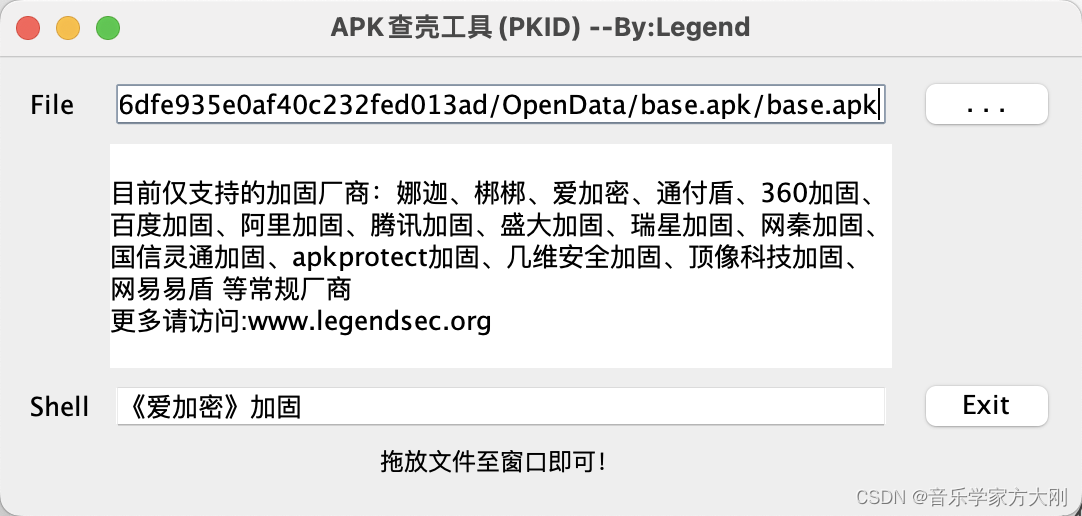
工具介绍Frida-dexDump
-
Frida-dexDump简介
Frida-dexDump是基于Frida的一个工具,Frida是一个著名的动态代码插桩工具,允许研究员挂钩到应用程序的运行过程中。Frida-dexDump利用Frida的能力,专注于自动化提取Android应用中的Dex文件,这对于后续的逆向工程分析至关重要。 -
Frida-dexDump的工作原理
Frida-dexDump通过在运行时挂钩到Android应用的关键函数(如加载Dex文件的函数)来工作。当这些函数被调用时,Frida-dexDump捕获并提取正在加载的Dex文件,然后将其保存到磁盘上。这一过程不需要对应用程序进行任何修改,可以在非root设备上进行。 -
如何使用Frida-dexDump
使用Frida-dexDump通常包括以下几个步骤:环境准备:确保您的设备已安装Frida,并且能够与目标设备通信。
安装Frida-dexDump:通过Git或其他方式下载Frida-dexDump,并确保其依赖项得到满足。
选择目标应用:确定您想要提取Dex文件的目标Android应用。
运行Frida-dexDump:使用Frida-dexDump对目标应用进行监控,并提取Dex文件。
分析提取的Dex文件:使用反编译工具(如JADX)对提取的Dex文件进行逆向工程分析。
frida-dexdump使用
-
安装
pip install frida-dexdump -
获取目标进程
frida-ps -Ua
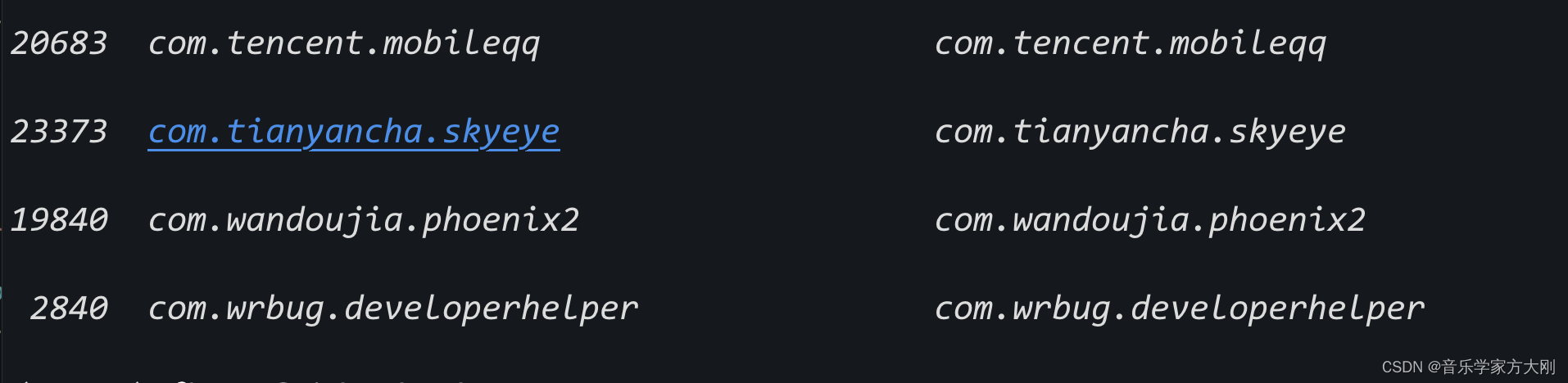
-
提取dex文件
frida-dexdump -UF -p 23373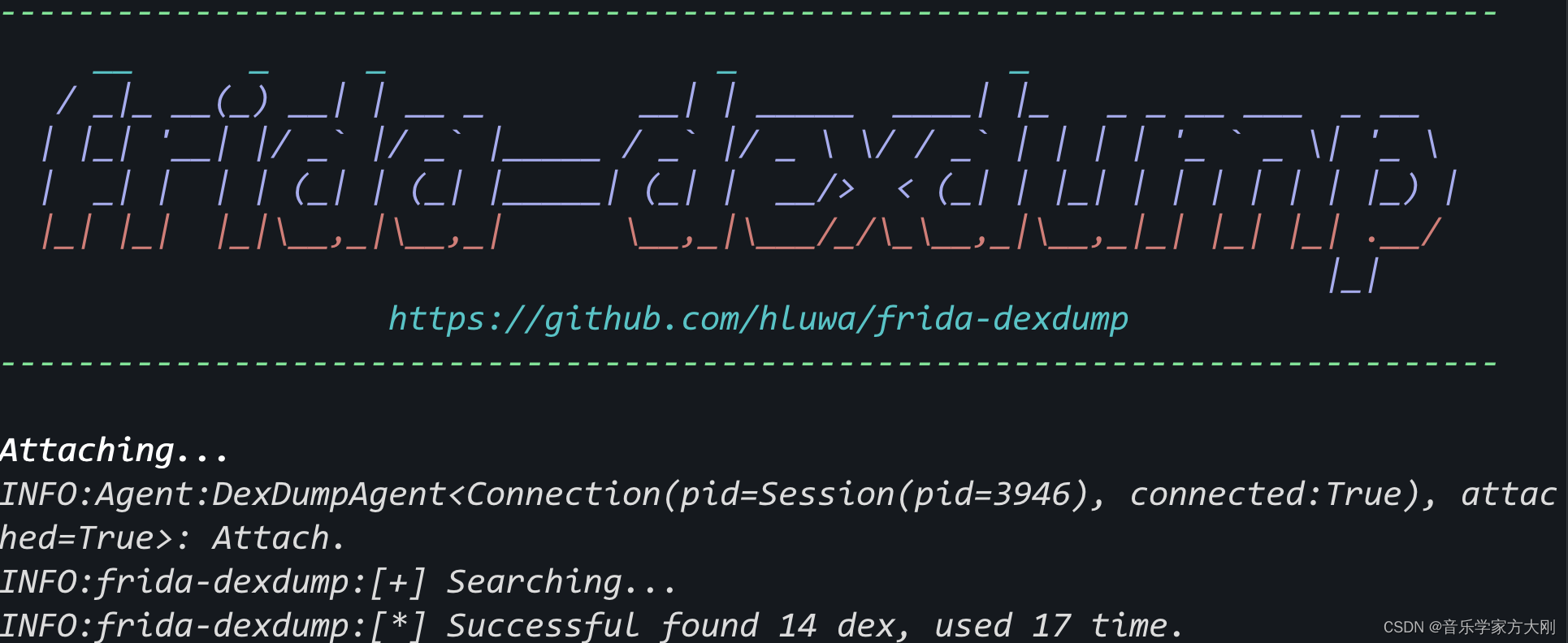
-
用jdax打开dex文件夹
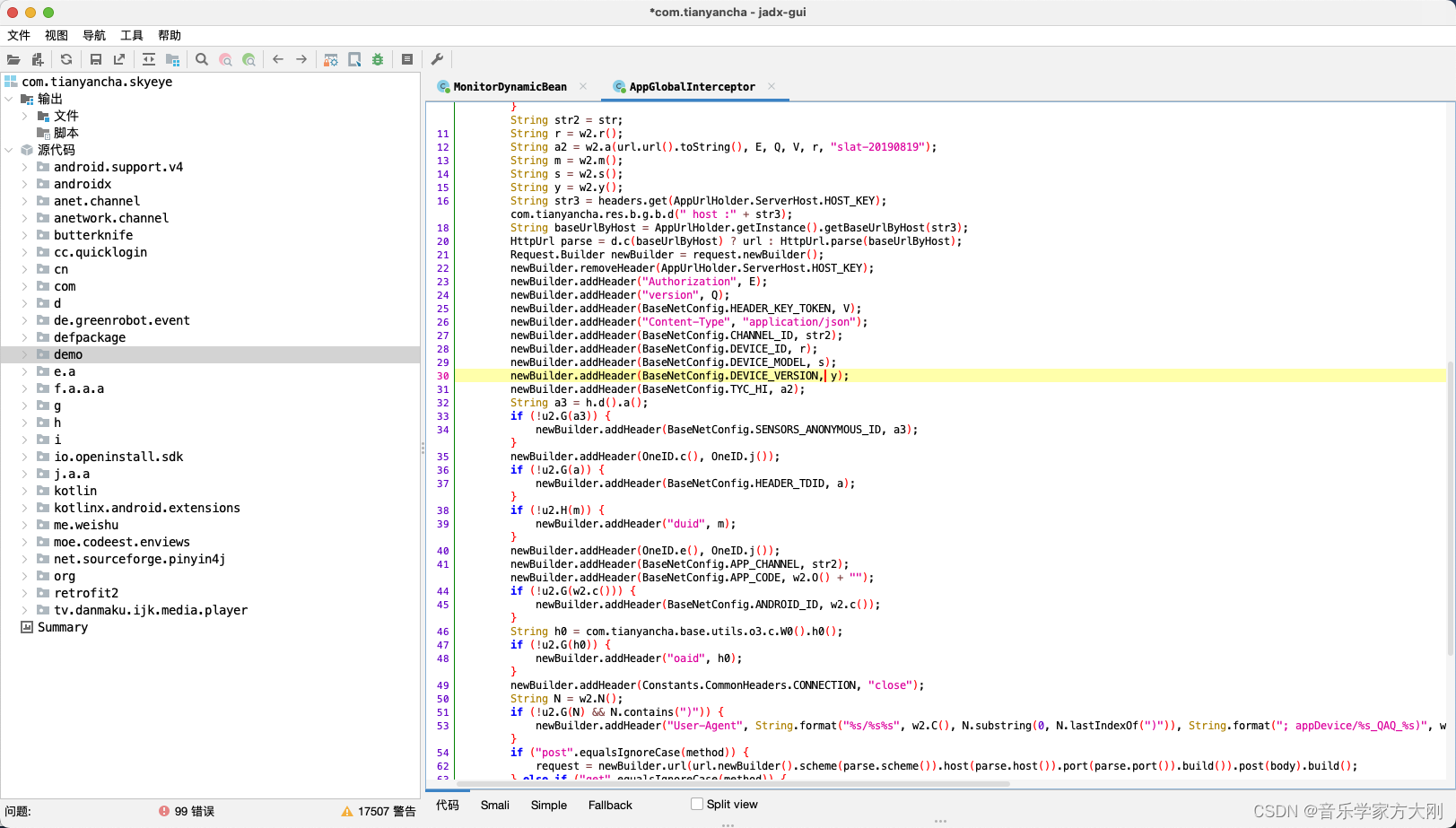
Frida-dexDump为安全研究员提供了一种强大的工具,以更高效的方式进行移动应用的逆向工程和安全分析。
这篇关于【APP_TYC】数据采集案例天眼APP查_查壳脱壳反编译_③的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






