本文主要是介绍利用tensorflow使用预训练神经网络(VGG16)来训练模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
利用tensorflow使用预训练神经网络(VGG16)来训练模型
文章目录
- 利用tensorflow使用预训练神经网络(VGG16)来训练模型
- 1.预训练神经网络是什么
- 2.数据集以及神经网络的选择
- 3.VGG网络架构
- 4.确定我们训练的步骤
- 5.微调
- 结语
1.预训练神经网络是什么
预训练神经网络是提前在大型数据库上训练过的网络,他蕴含了在大型数据集上训练过的权重,我们可以将他迁移到小型数据集上从而得到较高的准确率,举个例子来说,原本的神经网络是对几百种分类的大型数据上进行学习的,我们得到的训练模型含有获得的权重,我们将他迁移到只有几种分类的小型数据上从而来完成分类识别任务,这种又称迁移学习(**所谓迁移学习,**或者领域适应Domain Adaptation,一般就是要将从源领域(Source Domain)学习到的东西应用到目标领域(Target Domain)上去。源领域和目标领域之间往往有gap/domain discrepancy(源领域的数据和目标领域的数据遵循不同的分布)。
迁移学习能够将适用于大数据的模型迁移到小数据上,实现个性化迁移。)。
那么,这里我们有一个明显的问题,熟悉神经网络的同学肯定知道,我们训练模型其实就是训练神经网络的各项参数,让每个权重结合,最终能够完成得到正确的输出,那么举个例子,在识别椅子与桌子之上的数据集,上的网络,得到的权重为什么能够应用到其他地方上呢。其实我们换个地方想想,在分类问题上,到底几个分类是由我们最后的输出层(全连接层,分类器)决定的,而底层的卷积层只是负责提取特征,所以我们可以使用预训练神经网络的卷积来提取特征(这里是出自网络上搜索,以及询问他人得到的理解,有不对的可以评论区指正)。
2.数据集以及神经网络的选择
迁移学习一般用于小型数据上的识别上,我们再把著名的猫狗大战数据集拿出来,该数据集由一堆猫和狗的图片来识别
然后在预训练神经网络上的选择,keras其中有提供一堆预训练神经网络,比如有VGG16,VGG19,ResNet,Xception等许多预训练神经网络,我们在这里选择VGG16(其实我也有拿Xception来测试,但可能由于代码编写问题,拿到的正确率并不高,所以我并没有拿出来。。。)
3.VGG网络架构
VGG是一个十分经典的神经网络,网上资料很多,我找到了该网络的各项模型的具体层结构: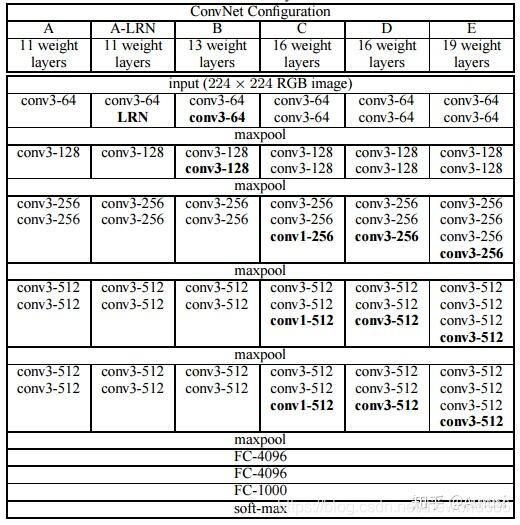
我们其实可以自己来构造当前的层次,但是我们使用预训练神经网络主要是想拿他训练过的权重,
4.确定我们训练的步骤
预训练神经网络步骤可以由下面这张图来确定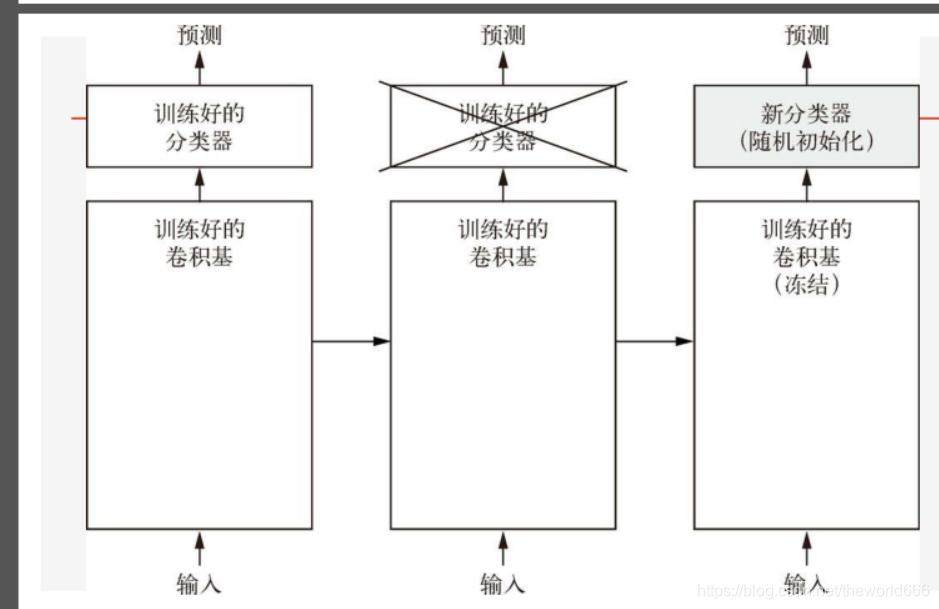
我们获得预训练网络的卷积基,抛弃直接连接输出的分类器,冻结卷积基(就是不让卷积基础的权重随着后面我们新加入的分类器传播的权重来改变),然后根据具体的任务我们添加新的分类器从而来进行新的训练
所以我们直接编写代码如下:
import tensorflow as tf
from tensorflow import keras
from keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import os
#提取新的与训练神经网络我们不要输出层,只要中间提取特征的卷积层
conv_base=keras.applications.VGG16(weights='imagenet',include_top=False)#使用在imageNet上使用的权重
#include_top表示是否需要哪些全连接层
#查看一下获取的网络结构
conv_base.summary()

然后我们根据具体的分类器来调整我们最后的输出层,最后是二分类问题,所以我们构造后面的分类器如下:
model=keras.Sequential()
#因为我们使用了已经提前训练好的参数,我们并不希望该权重改变,所以我们要将该权重设置为不可训练
conv_base.trainable=False
model.add(conv_base)
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.summary()
之后我们开始训练(一些其他数据读取与训练代码与博主上期博客一样),我们查看每次训练的结果:
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------->
Epoch 1: loss: 0.329, accuracy: 0.855
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------->
Epoch 2: loss: 0.250, accuracy: 0.893
可以看到仅仅只是,两次训练
准确率便能接近达到0.893,但是在接下来的训练上准确率是在90左右,无法上升,达到过拟合了,我们为了进一步提高准确率,可以使用微调方法。
5.微调
刚才我们说过底层的卷积基是负责提取特征的部分,含有的权重是可以迁移过来直接使用的,那么接近输出层的卷积层的权重,是不是意味着可以调整。使得我们增加我们的准确率,但是有一个前提是我们的分类器必须提前训练好的,不然随机初始化后的分类器可能会破坏我们调整的卷积基。所以我们接下来的微调都是在第一轮训练过的分类器
#使得一些高层的卷积基可以训练
conv_base.trainable=True
for layers in conv_base.layers[:-3]:layers.trainable=False
optimizer=keras.optimizers.Adam(0.00005)#同时需要调整更低的学习速率
然后我们开始我们第二波的训练
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------->
Epoch 1: loss: 0.196, accuracy: 0.915
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------->
Epoch 2: loss: 0.136, accuracy: 0.944
可以看到,我们的正确率开始迅速上升达到95左右,说明我们的微调还是十分有用的。
结语
对于本次使用预训练神经网络中,我省略了一些代码,重点介绍了如何使用预训练神经网络以及微调上,有什么问题和独到的见解可以评论区指正,谢谢。
这篇关于利用tensorflow使用预训练神经网络(VGG16)来训练模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





