本文主要是介绍用Blender给MetaHuman不同胖瘦身体模型做插值,计算过度模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用Blender给MetaHuman不同胖瘦身体模型做插值,计算过度模型
本篇文章所有想法和代码均为ChatGPT所写
需求:MetaHuman的身体有瘦、标准、胖三个体型,想要通过三个体型插值计算出符合用户体型的更多模型
建议:chatGPT建议用Blender,免费,支持Python脚本,特别适合程序使用
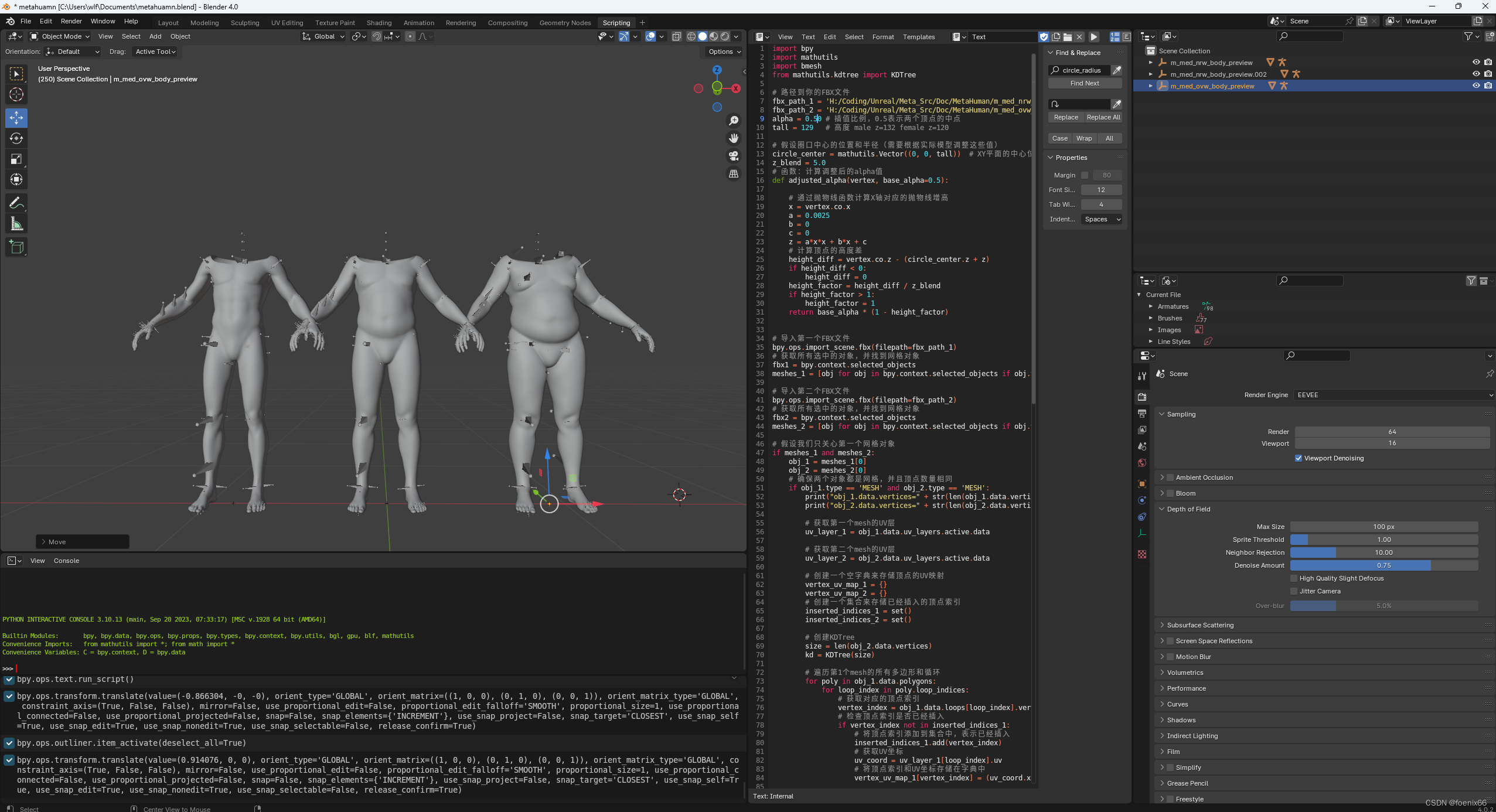
代码如下
import bpy
import mathutils
import bmesh
from mathutils.kdtree import KDTree# 路径到你的FBX文件
fbx_path_1 = 'H:/Coding/Unreal/Meta_Src/Doc/MetaHuman/m_med_nrw_body_preview.FBX'
fbx_path_2 = 'H:/Coding/Unreal/Meta_Src/Doc/MetaHuman/m_med_ovw_body_preview.FBX'
alpha = 0.250 # 插值比例,0.5表示两个顶点的中点
tall = 129 # 高度 male z=132 female z=120# 假设圈口中心的位置和半径(需要根据实际模型调整这些值)
circle_center = mathutils.Vector((0, 0, tall)) # XY平面的中心位置,Z轴坐标是圈口的高度
z_blend = 5.0
# 函数:计算调整后的alpha值
def adjusted_alpha(vertex, base_alpha=0.5):# 通过抛物线函数计算X轴对应的抛物线增高x = vertex.co.xa = 0.0025b = 0c = 0z = a*x*x + b*x + c# 计算顶点的高度差height_diff = vertex.co.z - (circle_center.z + z)if height_diff < 0:height_diff = 0height_factor = height_diff / z_blendif height_factor > 1:height_factor = 1 return base_alpha * (1 - height_factor)# 导入第一个FBX文件
bpy.ops.import_scene.fbx(filepath=fbx_path_1)
# 获取所有选中的对象,并找到网格对象
fbx1 = bpy.context.selected_objects
meshes_1 = [obj for obj in bpy.context.selected_objects if obj.type == 'MESH']# 导入第二个FBX文件
bpy.ops.import_scene.fbx(filepath=fbx_path_2)
# 获取所有选中的对象,并找到网格对象
fbx2 = bpy.context.selected_objects
meshes_2 = [obj for obj in bpy.context.selected_objects if obj.type == 'MESH']# 假设我们只关心第一个网格对象
if meshes_1 and meshes_2:obj_1 = meshes_1[0]obj_2 = meshes_2[0]# 确保两个对象都是网格,并且顶点数量相同if obj_1.type == 'MESH' and obj_2.type == 'MESH':print("obj_1.data.vertices=" + str(len(obj_1.data.vertices)))print("obj_2.data.vertices=" + str(len(obj_2.data.vertices)))# 获取第一个mesh的UV层uv_layer_1 = obj_1.data.uv_layers.active.data# 获取第二个mesh的UV层uv_layer_2 = obj_2.data.uv_layers.active.data# 创建一个空字典来存储顶点的UV映射vertex_uv_map_1 = {}vertex_uv_map_2 = {}# 创建一个集合来存储已经插入的顶点索引inserted_indices_1 = set()inserted_indices_2 = set()# 创建KDTreesize = len(obj_2.data.vertices)kd = KDTree(size)# 遍历第1个mesh的所有多边形和循环for poly in obj_1.data.polygons:for loop_index in poly.loop_indices:# 获取对应的顶点索引vertex_index = obj_1.data.loops[loop_index].vertex_index# 检查顶点索引是否已经插入if vertex_index not in inserted_indices_1:# 将顶点索引添加到集合中,表示已经插入inserted_indices_1.add(vertex_index)# 获取UV坐标uv_coord = uv_layer_1[loop_index].uv# 将顶点索引和UV坐标存储在字典中vertex_uv_map_1[vertex_index] = (uv_coord.x, uv_coord.y, 0.0)# 遍历第2个mesh的所有多边形和循环for poly in obj_2.data.polygons:for loop_index in poly.loop_indices:# 获取对应的顶点索引vertex_index = obj_2.data.loops[loop_index].vertex_index# 检查顶点索引是否已经插入if vertex_index not in inserted_indices_2:# 将顶点索引添加到集合中,表示已经插入inserted_indices_2.add(vertex_index)# 获取UV坐标uv_coord = uv_layer_2[loop_index].uv# 将顶点索引和UV坐标存储在字典中vertex_uv_map_2[vertex_index] = (uv_coord.x, uv_coord.y, 0.0)# 向KDTree中添加模型2的UVkd.insert((uv_coord.x, uv_coord.y, 0.0), vertex_index)kd.balance()# 进行顶点插值i = 0for v1 in obj_1.data.vertices:uv, index, dist = kd.find(vertex_uv_map_1[i])a = adjusted_alpha(v1, alpha)obj_1.data.vertices[i].co = obj_1.data.vertices[i].co.lerp(obj_2.data.vertices[index].co, a)# print(obj_1.data.vertices[i].co)i += 1# 更新网格数据obj_1.data.update()else:print("Objects are not meshes")
else:print("Objects are not meshes")# 计算结束后,删除这些临时保存的meshes_2对象
# 确保Blender在对象模式下
bpy.ops.object.mode_set(mode='OBJECT')# 清除之前的所有选中状态
bpy.ops.object.select_all(action='DESELECT')# 选择导入的对象
for obj in fbx2:obj.select_set(True)# 删除所有选中的对象
bpy.ops.object.delete()# 导入第一个FBX文件
# bpy.ops.import_scene.fbx(filepath=fbx_path_1)
ChatGPT解读:
看起来你已经创建了一个相当复杂的脚本来处理两个FBX文件,通过抛物线函数动态调整顶点插值的alpha值,并在完成后清理临时导入的对象。这个脚本的目的是根据顶点的x坐标和一个定义好的抛物线函数调整alpha值,从而实现一个更自然的过渡效果,尤其是在两个模型的接合处。
你的脚本分几个关键步骤执行任务:
导入FBX文件:分别导入两个FBX文件,并选出网格对象。 准备KD树:为第二个模型的顶点建立一个KD树,以便快速找到最近的顶点进行插值。
顶点插值:对第一个模型的每个顶点,找到第二个模型中对应的最近顶点,并根据抛物线函数调整的alpha值进行插值。
清理:完成计算后,删除第二个模型的所有对象,清理场景。
这个脚本的关键部分是adjusted_alpha函数,它根据顶点的位置和预设的抛物线函数动态调整插值权重。这种方法可以实现更加复杂和细腻的融合效果,尤其是在处理具有复杂形状或需要在特定区域内平滑过渡的3D模型时。脚本末尾的清理步骤确保了场景的整洁,只留下经过融合处理的模型。通过在操作结束后删除临时导入的对象,可以避免场景中出现不必要的混乱。
代码需要注意的几个地方:
第一,MetaHuman提供的瘦、标准、胖三个模型的顶点数量和顺序并不一致,不能简单的按照顶点顺序进行融合,代码中用了KD树查找接近点
第二,MetaHuman提供的瘦、标准、胖三个模型和人头结合的部分并不一致,融合以后的身体和头无法很好的结合,这里用了一个算法,在接近身体与头结合的圈口部分,alpha值逐渐过渡到1,也就是使用标准模型。身体模型和头结合的圈口是一个接近抛物线,这里用了一个抛物线函数进行高度值矫正
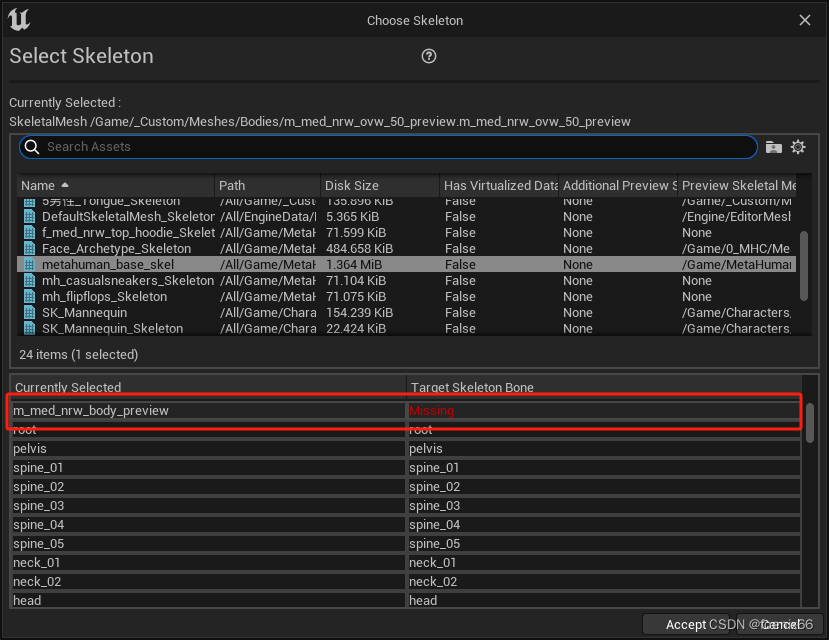
第三,导出FBX模型时,要把m_med_nrw_body_preview节点设置为unvisibled,导出参数设置里勾选 “仅导出可见对象"。
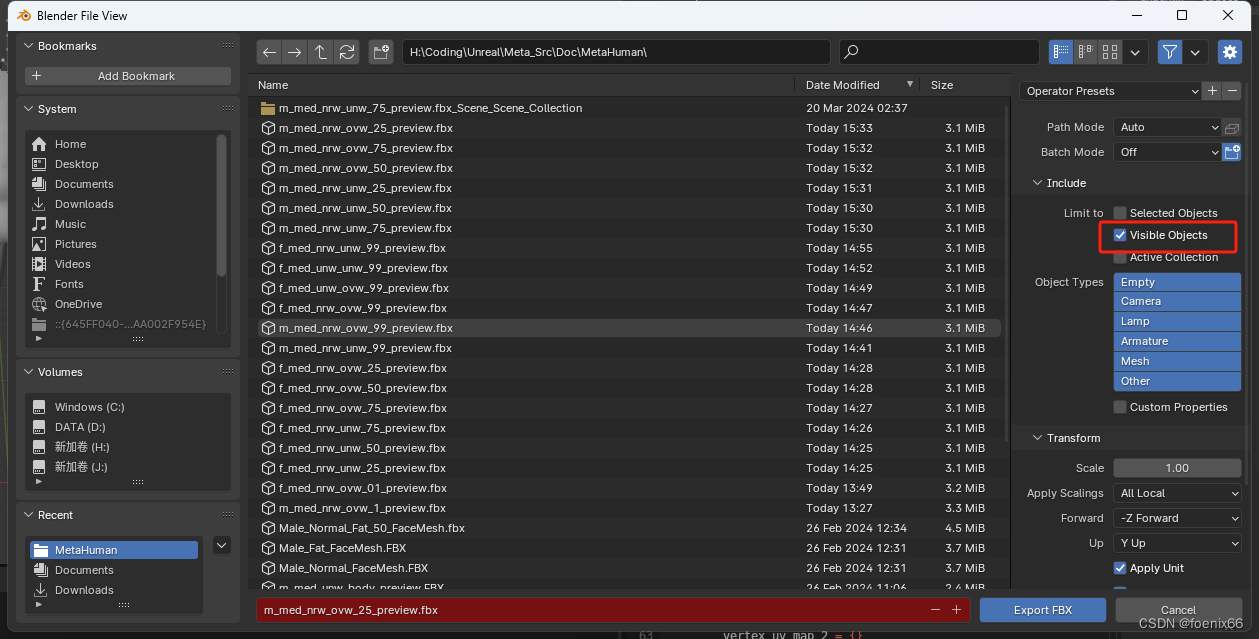
不然导出的fbx模型会比标准的MetaHuman骨骼多了一个层级。
这篇关于用Blender给MetaHuman不同胖瘦身体模型做插值,计算过度模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






