本文主要是介绍python 人岗推荐论文,SHPJF模型代码,人岗推荐思路和实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.《Leveraging Search History for Improving Person-Job Fit》论文精讲:
摘要不多说,自己看。




文章的核心就是思路:
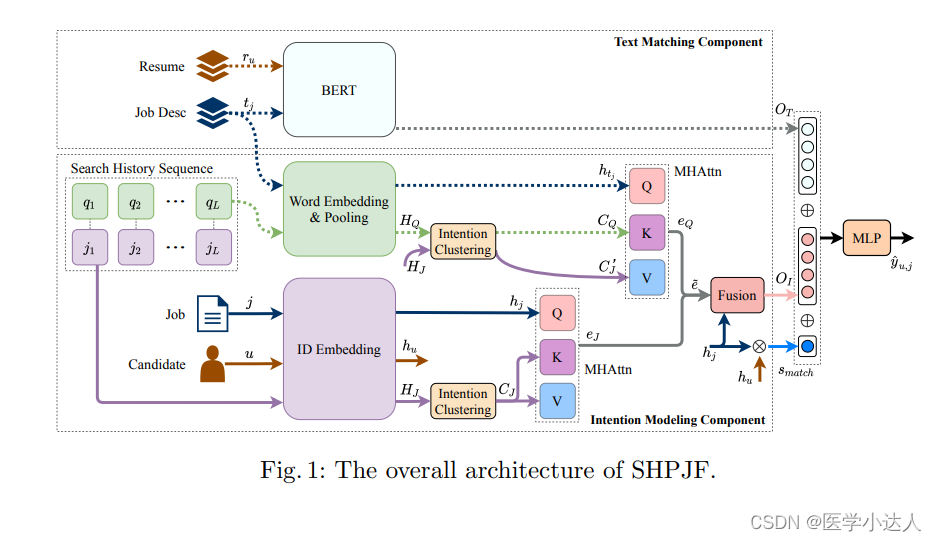
(1)首先把简历(resume) 和工作简介(job desc)用bert进行训练,请看公式一(竟然用bert的下一句预测思路去训练,而不是sbert,文中说单个模型比双塔模型要好一些,个人持怀疑态度),输出结果Ot,后面备用;
(2)对历史的qurey记录和工作、候选者的id进行id embedding,分别得到hj(job的id embedding结果)、hu(candidate的输出)、Hj(job history的输出),最后输出为Q、K、V,最后计算attention,输出ej,公式2-8;
(3)对history query进行word embedding,然后平均池化,输出为HQ,对job desc进行word embedding输出为htj,作为Q,然后HQ和Hj作用输出CQ作为K,CJ-hat作为V,然后计算attention输出eQ;公式9-14
(4)然后ej和eQ,通过e˜ = λeJ + (1 − λ)eQ组合;再把前面的结果进行拼接(oI = MLP [e˜; hj ; e˜ − hj ; e˜ ◦ hj ],由原向量和求差值和乘积),得到oI,公式15-16;
(5)hj 和hu乘积,得到s-match;
(6)最后三部分向量拼接,经过全连接MLP,最后由sigmoid输出为概率值;yˆu,j = σ(MLP [oT ; oI ; smatch] ),公式17
(7)损失函数为:简单的交叉熵损失函数。








 2. 模型代码
2. 模型代码
代码乱糟糟的,无力吐槽
SHPJF_model
import torch
import torch.nn as nnfrom model.abstract import PJFModel
from model.layer import MLPLayersclass SHPJF(PJFModel):def __init__(self, config, pool):super(SHPJF, self).__init__(config, pool)self.wd_embedding_size = config['wd_embedding_size']self.user_embedding_size = config['user_embedding_size']self.bert_embedding_size = config['bert_embedding_size']self.hd_size = config['hidden_size']self.dropout = config['dropout']self.num_heads = config['num_heads']self.query_his_len = config['query_his_len']self.max_job_longsent_len = config['job_longsent_len']self.pretrained_mf_path = config['pretrained_mf_path']self.beta = config['beta']self.k = config['k']self.emb = nn.Embedding(pool.wd_num, self.wd_embedding_size, padding_idx=0)self.geek_emb = nn.Embedding(self.geek_num, self.user_embedding_size, padding_idx=0)nn.init.xavier_normal_(self.geek_emb.weight.data)self.job_emb = nn.Embedding(self.job_num, self.user_embedding_size, padding_idx=0)nn.init.xavier_normal_(self.job_emb.weight.data)self.text_matching_fc = nn.Linear(self.bert_embedding_size, self.hd_size)self.pos_enc = nn.parameter.Parameter(torch.rand(1, self.query_his_len, self.user_embedding_size), requires_grad=True)self.q_pos_enc = nn.parameter.Parameter(torch.rand(1, self.query_his_len, self.user_embedding_size), requires_grad=True)self.job_desc_attn_layer = nn.Linear(self.wd_embedding_size, 1)self.wq = nn.Linear(self.wd_embedding_size, self.user_embedding_size, bias=False)self.text_based_lfc = nn.Linear(self.query_his_len, self.k, bias=False)self.job_emb_lfc = nn.Linear(self.query_his_len, self.k, bias=False)self.text_based_attn_layer = nn.MultiheadAttention(embed_dim=self.user_embedding_size,num_heads=self.num_heads,dropout=self.dropout,bias=False)self.text_based_im_fc = nn.Linear(self.user_embedding_size, self.user_embedding_size)self.job_emb_attn_layer = nn.MultiheadAttention(embed_dim=self.user_embedding_size,num_heads=self.num_heads,dropout=self.dropout,bias=False)self.job_emb_im_fc = nn.Linear(self.user_embedding_size, self.user_embedding_size)self.intent_fusion = MLPLayers(layers=[self.user_embedding_size * 4, self.hd_size, 1],dropout=self.dropout,activation='tanh')self.pre_mlp = MLPLayers(layers=[self.hd_size \+ 1 \+ 1 \, self.hd_size, 1],dropout=self.dropout,activation='tanh')self.sigmoid = nn.Sigmoid()self.loss = nn.BCEWithLogitsLoss(pos_weight=torch.FloatTensor([config['pos_weight']]))def _text_matching_layer(self, interaction):x = bert_vec = interaction['bert_vec'] # (B, bertD)x = self.text_matching_fc(bert_vec) # (B, wordD)return xdef _intent_modeling_layer(self, interaction):job_longsent = interaction['job_longsent']job_longsent_len = interaction['job_longsent_len']job_desc_vec = self.emb(job_longsent) # (B, L, wordD)job_desc_mask = torch.arange(self.max_job_longsent_len, device=job_desc_vec.device) \.expand(len(job_longsent_len), self.max_job_longsent_len) \>= job_longsent_len.unsqueeze(1)job_desc_attn_weight = self.job_desc_attn_layer(job_desc_vec)job_desc_attn_weight = torch.masked_fill(job_desc_attn_weight, job_desc_mask.unsqueeze(-1), -10000)job_desc_attn_weight = torch.softmax(job_desc_attn_weight, dim=1)job_desc_vec = torch.sum(job_desc_attn_weight * job_desc_vec, dim=1)job_desc_vec = self.wq(job_desc_vec) # (B, idD)job_id = interaction['job_id'] # (B)job_id_vec = self.job_emb(job_id) # (B, idD)job_his = interaction['job_his'] # (B, Q)job_his_vec = self.job_emb(job_his) # (B, Q, idD)job_his_vec = job_his_vec + self.pos_encqwd_his = interaction['qwd_his'] # (B, Q, W)qlen_his = interaction['qlen_his'] # (B, Q)qwd_his_vec = self.emb(qwd_his) # (B, Q, W, wordD)qwd_his_vec = torch.sum(qwd_his_vec, dim=2) / \qlen_his.unsqueeze(-1) # (B, Q, wordD)qwd_his_vec = self.wq(qwd_his_vec) # (B, Q, idD)qwd_his_vec = self.q_pos_enc + qwd_his_vecproj_qwd_his_vec = self.text_based_lfc(qwd_his_vec.transpose(2, 1)).transpose(2, 1) * self.k / self.query_his_len# (B, K, idD)proj_job_his_vec = self.job_emb_lfc(job_his_vec.transpose(2, 1)).transpose(2, 1) * self.k / self.query_his_len# (B, K, idD)text_based_intent_vec, _ = self.text_based_attn_layer(query=job_desc_vec.unsqueeze(0),key=proj_qwd_his_vec.transpose(1, 0),value=proj_job_his_vec.transpose(1, 0))text_based_intent_vec = text_based_intent_vec.squeeze(0)# (B, idD)text_based_intent_vec = self.text_based_im_fc(text_based_intent_vec)job_emb_intent_vec, _ = self.job_emb_attn_layer(query=job_id_vec.unsqueeze(0),key=proj_job_his_vec.transpose(1, 0),value=proj_job_his_vec.transpose(1, 0),)job_emb_intent_vec = job_emb_intent_vec.squeeze(0) # (B, idD)job_emb_intent_vec = self.job_emb_im_fc(job_emb_intent_vec)intent_vec = (1 - self.beta) * text_based_intent_vec + self.beta * job_emb_intent_vecintent_modeling_vec = self.intent_fusion(torch.cat([job_id_vec, intent_vec, job_id_vec - intent_vec, job_id_vec * intent_vec], dim=1))return intent_modeling_vecdef _mf_layer(self, interaction):geek_id = interaction['geek_id']job_id = interaction['job_id']geek_vec = self.geek_emb(geek_id)job_vec = self.job_emb(job_id)x = torch.sum(torch.mul(geek_vec, job_vec), dim=1, keepdim=True)return xdef predict_layer(self, vecs):x = torch.cat(vecs, dim=-1)score = self.pre_mlp(x).squeeze(-1)return scoredef forward(self, interaction):text_matching_vec = self._text_matching_layer(interaction)intent_modeling_vec = self._intent_modeling_layer(interaction)mf_vec = self._mf_layer(interaction)score = self.predict_layer([text_matching_vec, intent_modeling_vec, mf_vec])return scoredef calculate_loss(self, interaction):label = interaction['label']output = self.forward(interaction)return self.loss(output, label)def predict(self, interaction):return self.sigmoid(self.forward(interaction))abstract.py
rom logging import getLogger
import numpy as np
import torch.nn as nnclass PJFModel(nn.Module):r"""Base class for all Person-Job Fit models"""def __init__(self, config, pool):super(PJFModel, self).__init__()self.logger = getLogger()self.device = config['device']self.geek_num = pool.geek_numself.job_num = pool.job_numdef calculate_loss(self, interaction):"""Calculate the training loss for a batch data.Args:interaction (dict): Interaction class of the batch.Returns:torch.Tensor: Training loss, shape: []"""raise NotImplementedErrordef predict(self, interaction):"""Predict the scores between users and items.Args:interaction (dict): Interaction class of the batch.Returns:torch.Tensor: Predicted scores for given users and items, shape: [batch_size]"""raise NotImplementedErrordef __str__(self):"""Model prints with number of trainable parameters"""model_parameters = filter(lambda p: p.requires_grad, self.parameters())params = sum([np.prod(p.size()) for p in model_parameters])return super(PJFModel, self).__str__() + '\n\tTrainable parameters: {}'.format(params)layer.py
import torch
import torch.nn as nn
from torch.nn.init import normal_class MLPLayers(nn.Module):""" MLPLayersArgs:- layers(list): a list contains the size of each layer in mlp layers- dropout(float): probability of an element to be zeroed. Default: 0- activation(str): activation function after each layer in mlp layers. Default: 'relu'.candidates: 'sigmoid', 'tanh', 'relu', 'leekyrelu', 'none'Shape:- Input: (:math:`N`, \*, :math:`H_{in}`) where \* means any number of additional dimensions:math:`H_{in}` must equal to the first value in `layers`- Output: (:math:`N`, \*, :math:`H_{out}`) where :math:`H_{out}` equals to the last value in `layers`Examples:>>> m = MLPLayers([64, 32, 16], 0.2, 'relu')>>> input = torch.randn(128, 64)>>> output = m(input)>>> print(output.size())>>> torch.Size([128, 16])"""def __init__(self, layers, dropout=0., activation='relu', bn=False, init_method=None):super(MLPLayers, self).__init__()self.layers = layersself.dropout = dropoutself.activation = activationself.use_bn = bnself.init_method = init_methodmlp_modules = []for idx, (input_size, output_size) in enumerate(zip(self.layers[:-1], self.layers[1:])):mlp_modules.append(nn.Dropout(p=self.dropout))mlp_modules.append(nn.Linear(input_size, output_size))if self.use_bn:mlp_modules.append(nn.BatchNorm1d(num_features=output_size))activation_func = activation_layer(self.activation, output_size)if activation_func is not None:mlp_modules.append(activation_func)self.mlp_layers = nn.Sequential(*mlp_modules)if self.init_method is not None:self.apply(self.init_weights)def init_weights(self, module):# We just initialize the module with normal distribution as the paper saidif isinstance(module, nn.Linear):if self.init_method == 'norm':normal_(module.weight.data, 0, 0.01)if module.bias is not None:module.bias.data.fill_(0.0)def forward(self, input_feature):return self.mlp_layers(input_feature)def activation_layer(activation_name='relu', emb_dim=None):"""Construct activation layersArgs:activation_name: str, name of activation functionemb_dim: int, used for Dice activationReturn:activation: activation layer"""if activation_name is None:activation = Noneelif isinstance(activation_name, str):if activation_name.lower() == 'sigmoid':activation = nn.Sigmoid()elif activation_name.lower() == 'tanh':activation = nn.Tanh()elif activation_name.lower() == 'relu':activation = nn.ReLU()elif activation_name.lower() == 'leakyrelu':activation = nn.LeakyReLU()elif activation_name.lower() == 'none':activation = Noneelif issubclass(activation_name, nn.Module):activation = activation_name()else:raise NotImplementedError("activation function {} is not implemented".format(activation_name))return activationclass SimpleFusionLayer(nn.Module):def __init__(self, hd_size):super(SimpleFusionLayer, self).__init__()self.fc = nn.Linear(hd_size * 4, hd_size)def forward(self, a, b):assert a.shape == b.shapex = torch.cat([a, b, a * b, a - b], dim=-1)x = self.fc(x)x = torch.tanh(x)return xclass FusionLayer(nn.Module):def __init__(self, hd_size):super(FusionLayer, self).__init__()self.m = SimpleFusionLayer(hd_size)self.g = nn.Sequential(nn.Linear(hd_size * 2, 1),nn.Sigmoid())def _single_layer(self, a, b):ma = self.m(a, b)x = torch.cat([a, b], dim=-1)ga = self.g(x)return ga * ma + (1 - ga) * adef forward(self, a, b):assert a.shape == b.shapea = self._single_layer(a, b)b = self._single_layer(b, a)return torch.cat([a, b], dim=-1)这篇关于python 人岗推荐论文,SHPJF模型代码,人岗推荐思路和实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



