本文主要是介绍【爬虫基础】第10讲 urlerror的使用及捕获异常,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
URLError是Python中的一个异常类,用于处理与URL相关的错误。它是urllib.error模块中的一个类。
URLError通常在以下情况下被引发:
- 网络连接问题:例如无法连接到服务器、超时等。
- URL不正确:例如无效的URL、无法解析主机名等。
- 服务器错误:例如服务器返回500错误。
以下是使用URLError处理URL连接错误的示例.我们尝试打开一个不存在的URL,并使用try-except语句来捕获可能发生的URLError异常。
如果包含
code属性,则说明是服务器错误。
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
from urllib.error import URLErrorurl='http://127.0.0.1:81/1123/'
headers = {'User-Agent' : UserAgent().chrome
}
req = Request(url,headers=headers)
try:resp = urlopen(req)print(resp.read().decode())
except URLError as e:# print(e)if e.args:print(e.args[0].errno)else:print(e.code)
print('爬取完毕')代码执行结果

如果
URLError包含reason属性,则说明是网络连接问题;
代码实现:
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
from urllib.error import URLErrorurl='http://127.0.0.1:5000/zendao/'
headers = {'User-Agent' : UserAgent().chrome
}
req = Request(url,headers=headers)
try:resp = urlopen(req)print(resp.read().decode())
except URLError as e:# print(e)if e.args:print(e.args[0].errno)else:print(e.code)
print('爬取完毕')执行结果:

参考异常调试返回结果
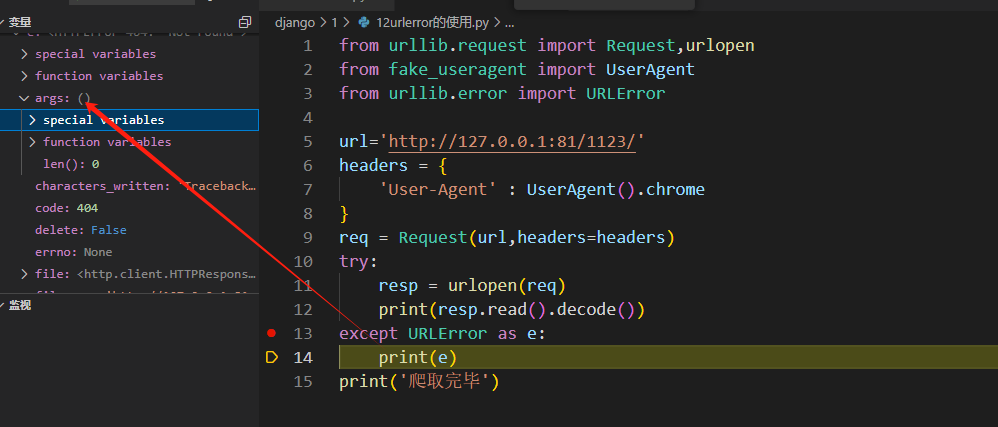
我们通过e.args函数来检查是否存在这些属性,并打印相应的错误信息。
需要注意的是,URLError是HTTPError的父类,HTTPError是另一个与HTTP相关的异常类,用于处理HTTP请求错误(例如404错误)。如果需要更具体的错误处理,可以使用HTTPError来捕获HTTP请求错误。
这篇关于【爬虫基础】第10讲 urlerror的使用及捕获异常的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




