本文主要是介绍【python】flask模板渲染引擎Jinja2,通过后端数据渲染前端页面,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN新星创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Python全栈,前后端开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,linux,shell脚本等实操经验,网站搭建,面试宝典等分享。所属的专栏:flask框架零基础,进阶应用实战教学
景天的主页:景天科技苑
文章目录
- Jinja2模板引擎
- 模板基本使用
- pycharm未识别模板文件配置
- 模板输出变量
- 总结
Jinja2模板引擎
flask在执行过程中的流程
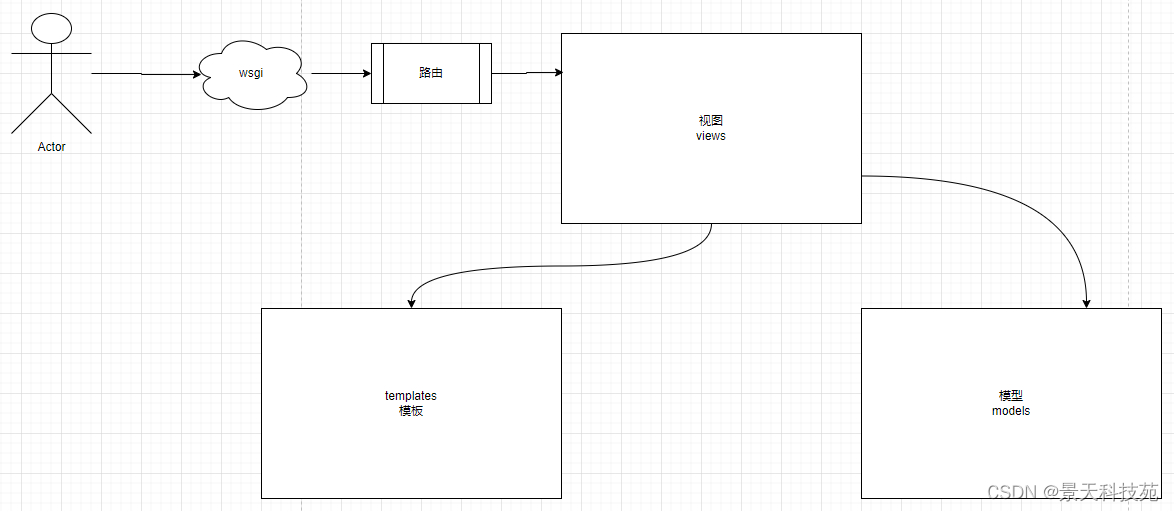
Flask内置的模板引擎Jinja2,它的设计思想来源于 Django 的模板引擎DTP(DjangoTemplates),并扩展了其语法和一系列强大的功能。
- Flask提供的 render_template 函数封装了该模板引擎Jinja2
- render_template 函数的第一个参数是模板的文件名,后面的参数都是键值对,表示模板中变量对应的数据值。
我们在安装flask的时候就依赖安装了Jinja2

模板基本使用
- 在flask应用对象创建的时候,设置template_folder参数,默认值是templates也可以自定义为其他目录名,需要手动创建模板目录。
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
2.在手动创建 templates 目录下创建一个模板html文件 index.html,代码:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{title}}</title>
</head>
<body><h1>{{content}}</h1>
</body>
</html>
3.在视图函数设置渲染模板并设置模板数据
from flask import Flask, render_template
#通过template_folder参数指定模板路径目录app = Flask(__name__, template_folder="templates")@app.route("/")
def index():title = "网页标题"content = "网页正文内容"#这里写模板文件。基于templates来写路径,locals()可以收集局部变量成字典类型数据,此处使用星星打散的方式,将字典数据转化为键值对形式传参#类似于这种# return render_template("index.html", title=title,content=content)return render_template("index.html", **locals())if __name__ == '__main__':app.run()
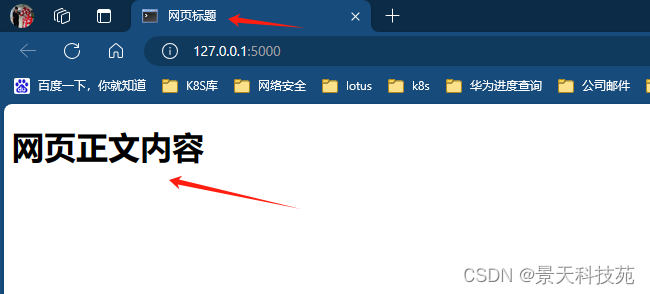
运行程序,浏览器访问,可以看到网页标题和网页内容都是我们设置的字段内容
flask中提供了2个加载模板的函数:render_template与render_template_string。
render_template:基于参数1的模板文件路径,读取html模板内容,返回渲染后的HTML页面内容,类型是字符串,不是response对象。
render_template_string:基于参数1以字符串的方式传参的模板内容,返回渲染后的HTML页面内容。
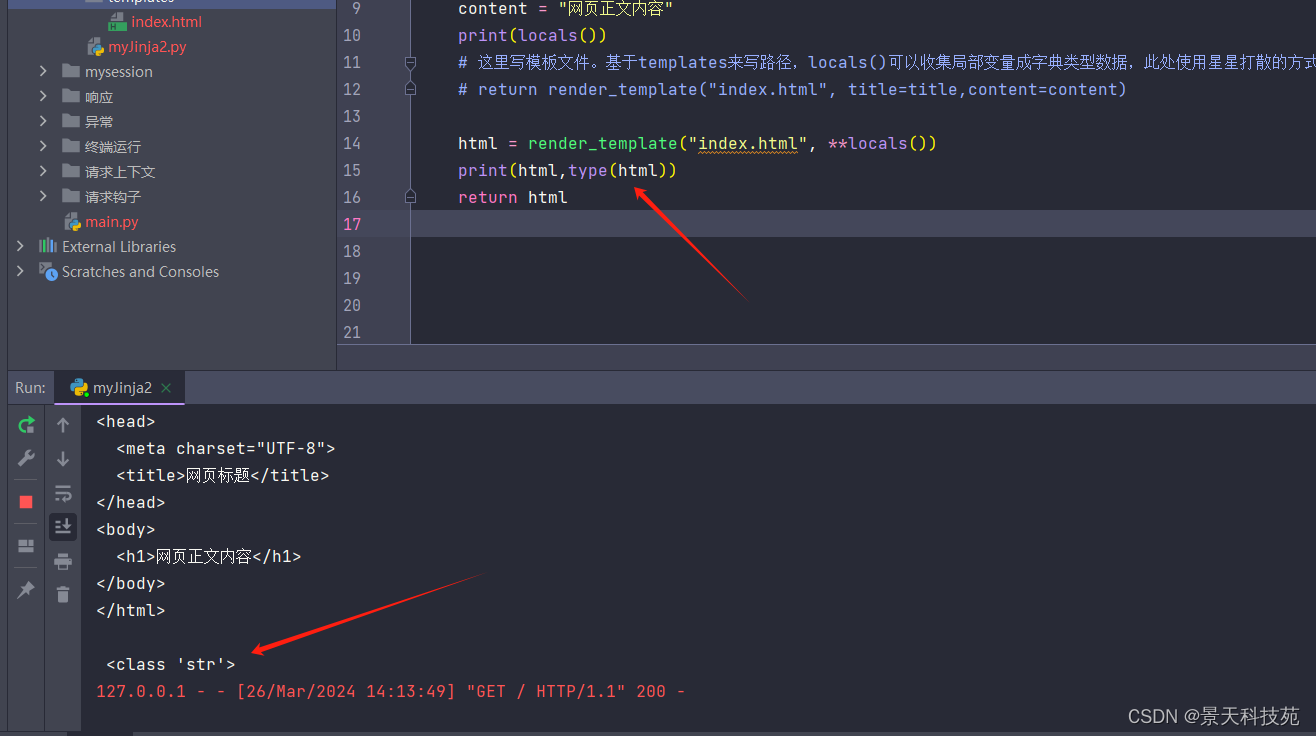
代码案例:
from flask import Flask, render_template,render_template_stringapp = Flask(__name__, template_folder="templates")@app.route("/")
def index():title = "网页标题"content = "网页正文内容"print(locals())# 这里写模板文件。基于templates来写路径,locals()可以收集局部变量成字典类型数据,此处使用星星打散的方式,将字典数据转化为键值对形式传参# return render_template("index.html", title=title,content=content)html = render_template("index.html", **locals())print('rend_template返回',html,type(html))return html#rend_template_string
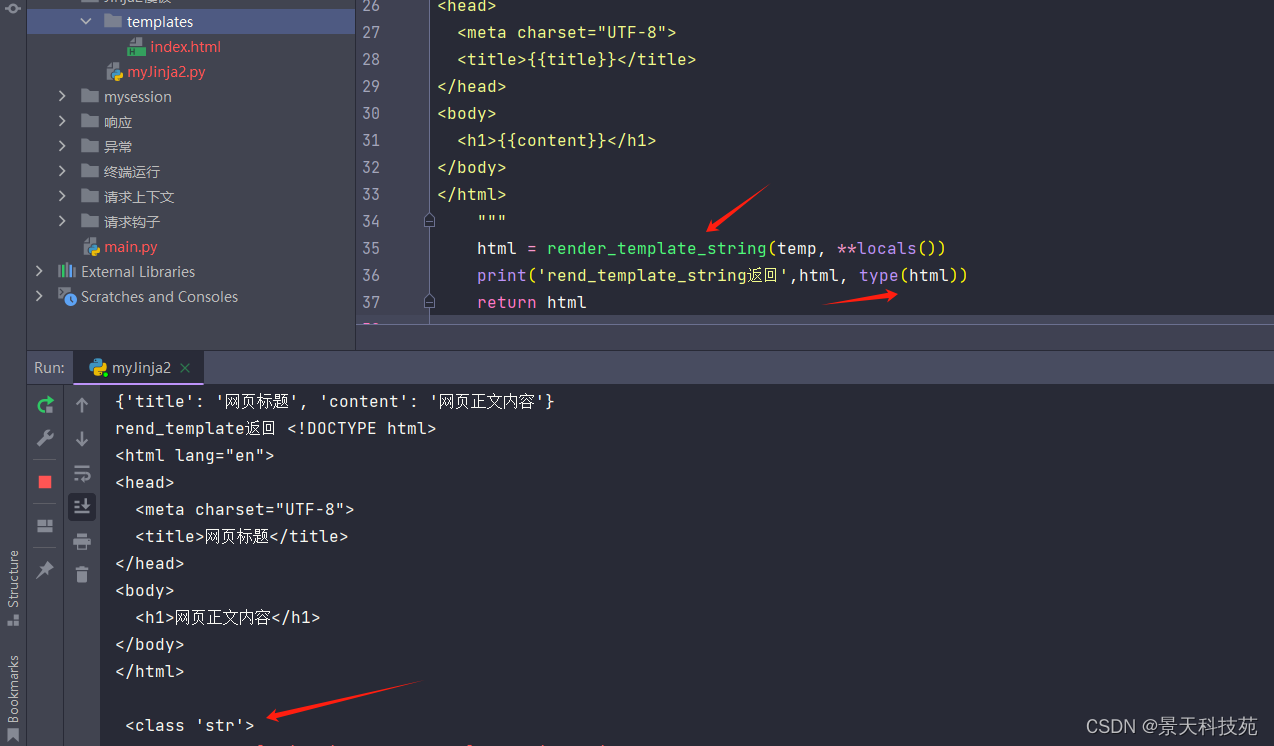
@app.route("/tmp")
def tmp():title = "网页标题"content = "网页正文内容"#将网页内容以字符串的形式传参temp = """<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{title}}</title>
</head>
<body><h1>{{content}}</h1>
</body>
</html>"""html = render_template_string(temp, **locals())print('rend_template_string返回',html, type(html))return htmlif __name__ == '__main__':app.run(debug=True)
浏览器访问/tmp路径url。返回也是字符串
pycharm未识别模板文件配置
pycharm中,当我们设置了模板文件,但是pycharm并未识别
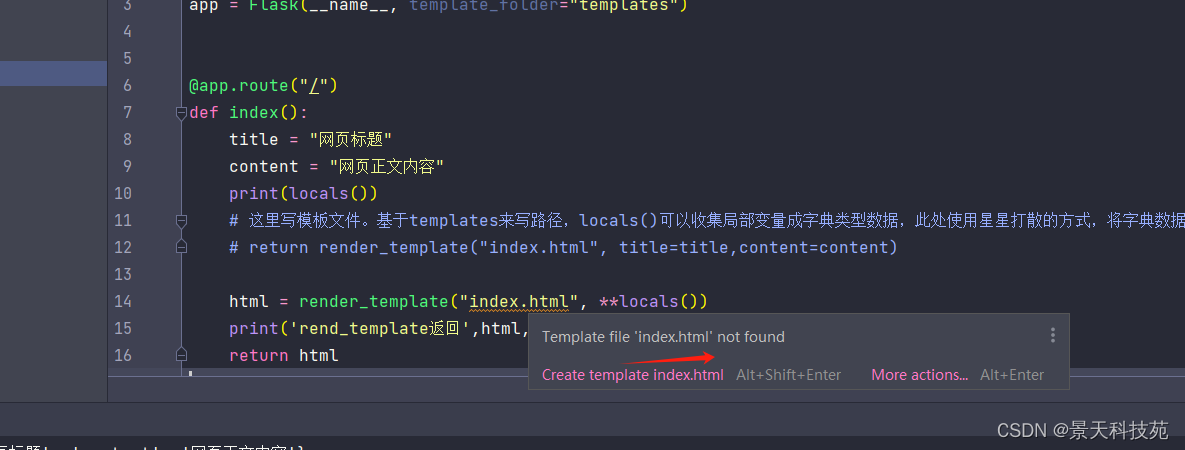
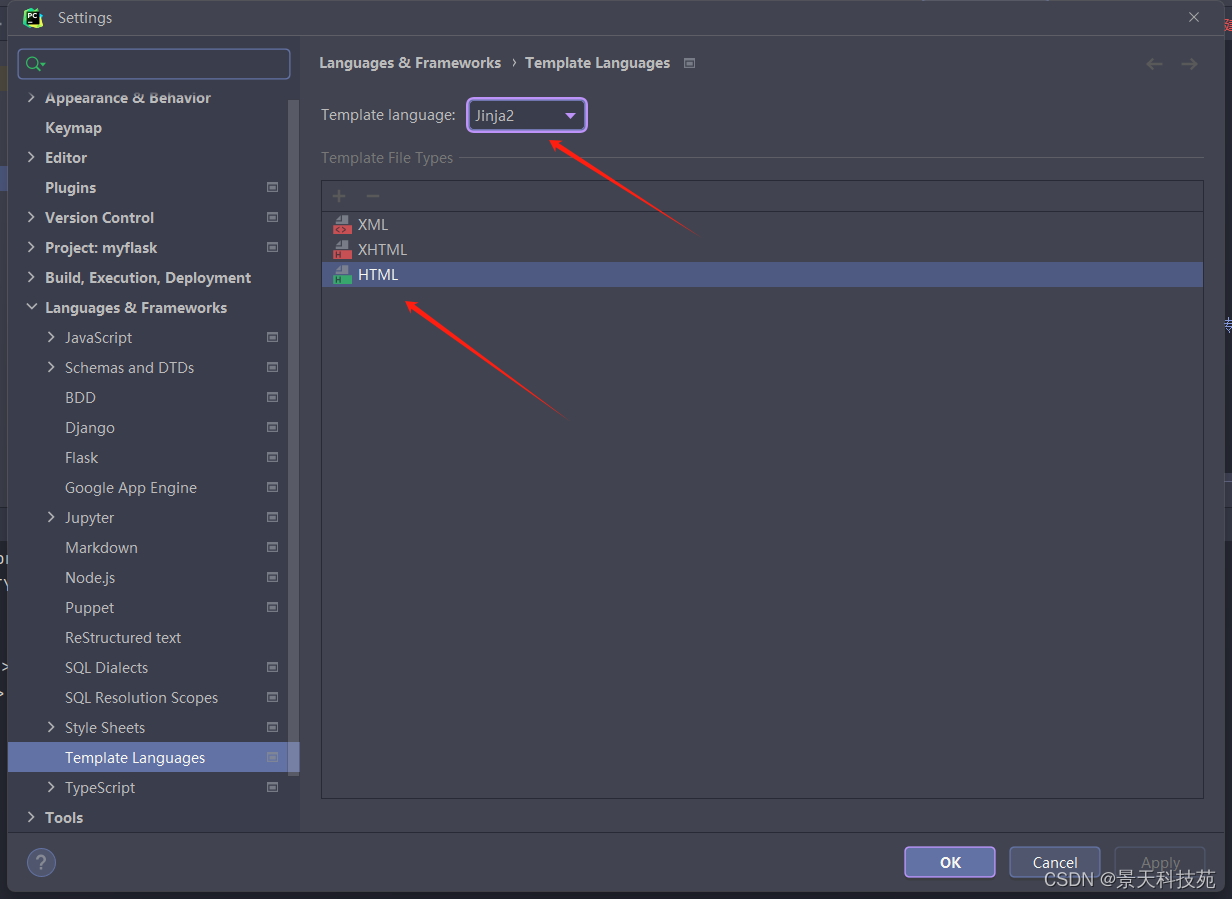
此时我们可以设置当前项目的模板语言:
设置路径
files/settings/languages & frameworks/python template languages。
设置下拉框为jinja2,保存
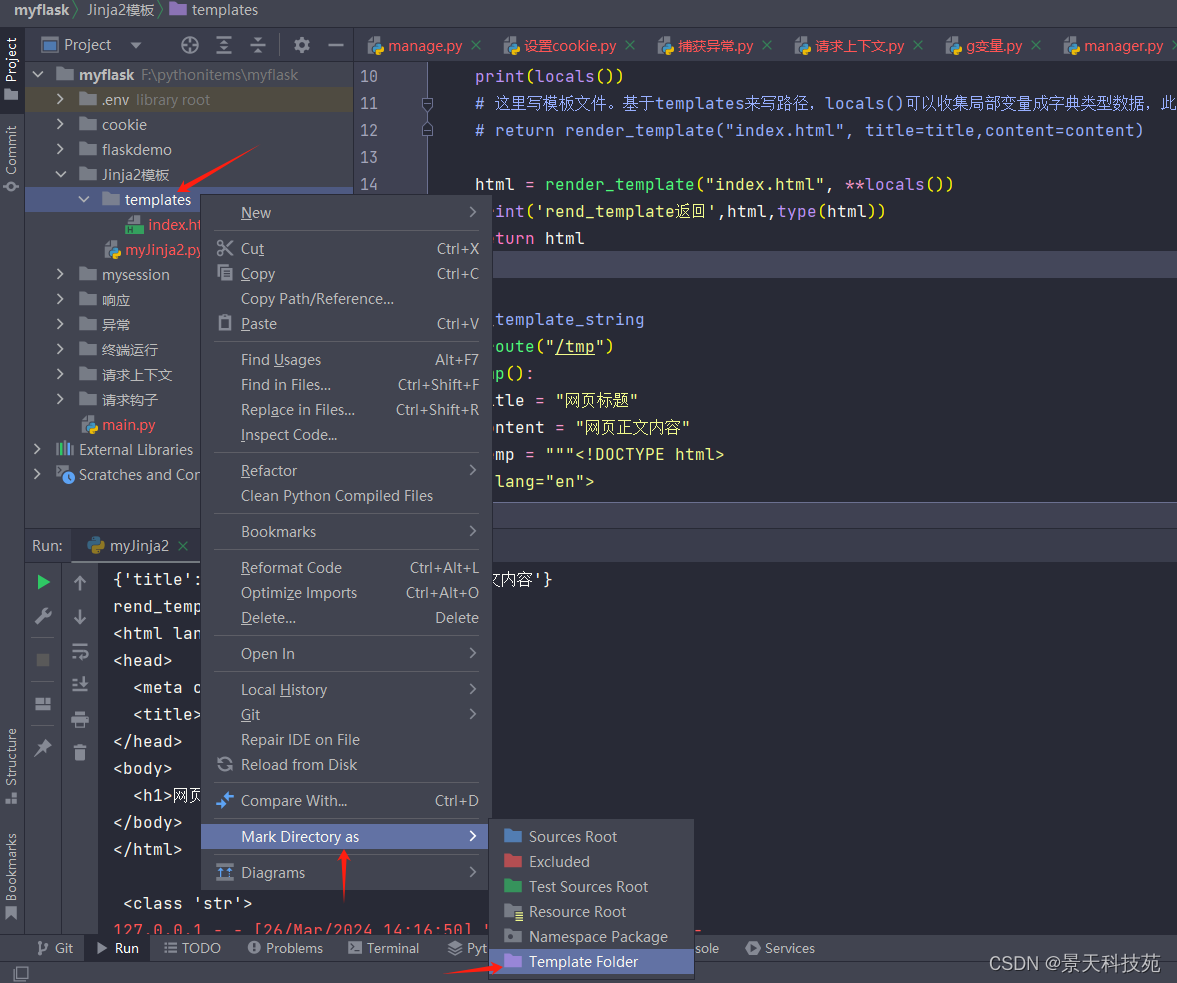
设置指定目录为模板目录,鼠标右键->Mark Directory as …-> Template Folder
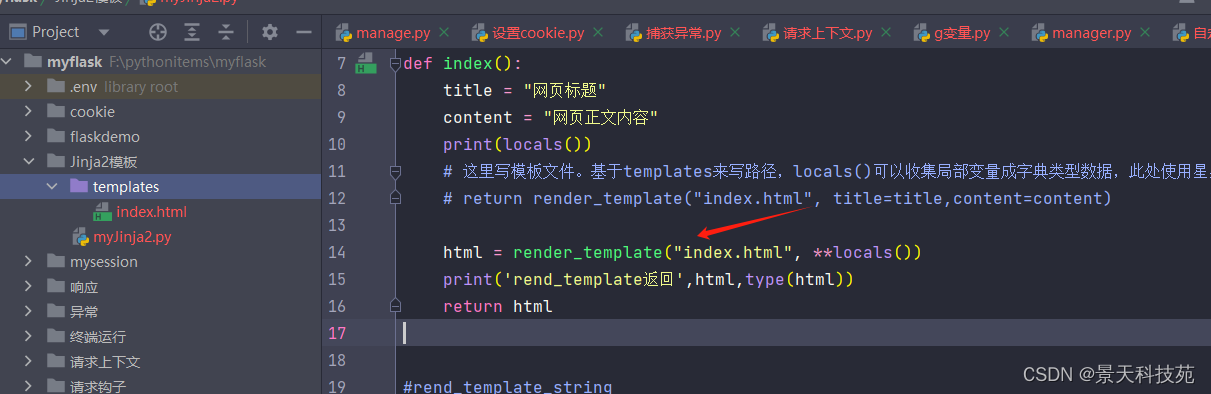
此时,pycahrm就不再有警告了
模板输出变量
{{ 变量名 }},这种 {{ }} 语法叫做 变量代码块
Jinja2 模版中的变量代码块的输出的内容可以是Python的任意类型数据或者对象,只要它能够被 Python 的 __str__ 方法或者str()转换为一个字符串就可以,比如,可以通过下面的方式显示一个字典或者列表中的某个元素:
视图代码:
from flask import Flask, render_template, session, gapp = Flask(__name__, template_folder="templates")app.config["SECRET_KEY"] = "my secret key"@app.route("/")
def index():# 基本类型num = 100num2 = 3.14is_bool = Truetitle = "网页标题"# 复合类型set_var = {1,2,3,4}list_var = ["小明", "小红", "小白"]dict_var = {"name": "root", "pwd": "1234557"}tuple_var = (1,2,3,4)# 更复杂的数据结构book_list = [{"id": 10, "title": "图书标题10a", "description": "图书介绍",},{"id": 13, "title": "图书标题13b", "description": "图书介绍",},{"id": 21, "title": "图书标题21c", "description": "图书介绍",},]session["uname"] = "root"g.num = 300html = render_template("index.html", **locals())return html@app.route("/user/<uid>")
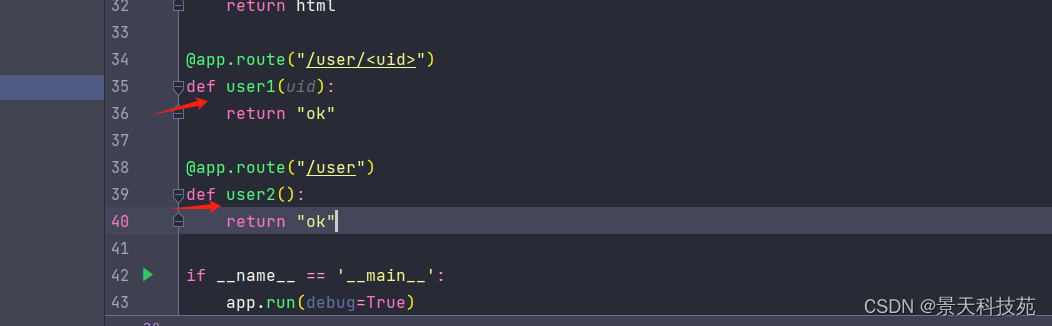
def user1(uid):return "ok"@app.route("/user")
def user2():return "ok"if __name__ == '__main__':app.run(debug=True)
模板代码:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{{title}}</title>
</head>
<body><p>基本类型<br>num = {{num}}<br>{{num2}}<br>{{is_bool}}<br>{{title}}<br></p><p>{# 此处为模板注释 #}复合类型<br>
{# {{set_var}}<br>#}{{set_var.pop()}}<br>{{list_var}}<br>{{list_var[1]}}<br>{{list_var.0}}<br>{{list_var[-1]}},点语法不能写负数下标<br>{{dict_var}}<br>{{dict_var["name"]}}<br>{{dict_var.name}}<br>{{tuple_var}}<br>{{tuple_var.0}}<br></p><p>更复杂的数据结构<br>{{book_list}}<br>{{book_list.2}}<br>{{book_list.1.title}}<br></p><p>内置的全局变量 <br>{{request}}<br>{{request.path}}<br>{{request.method}}<br>{{session.get("uname")}}<br>{{g.num}}<br></p>{# 配置信息#}<p>{{ config.ENV }}</p><p>{{ url_for("user1", uid=3) }}</p> {# /user/3 #}<p>{{ url_for("user2", uid=3) }}</p> {# /user?uid=3 #}
</body>
</html>
页面访问
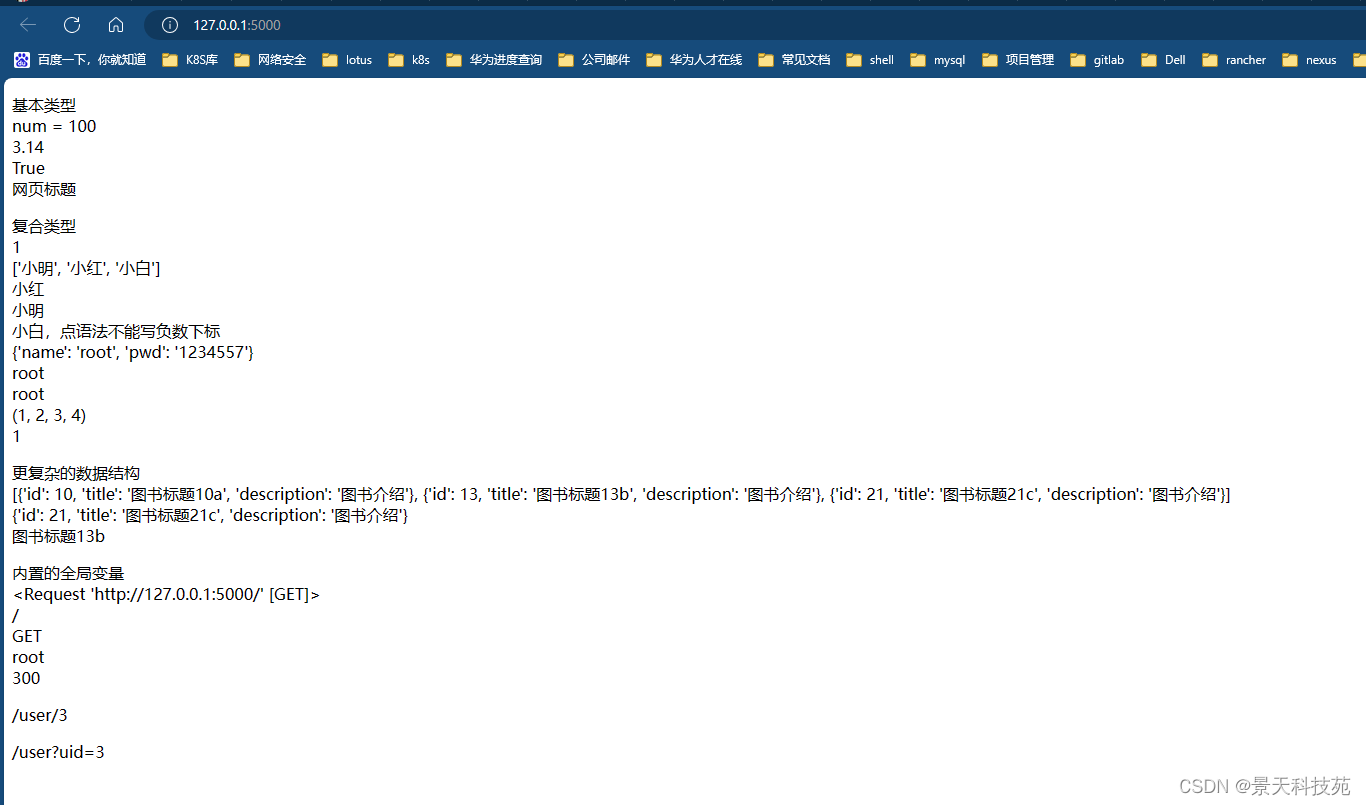
代码分析:
使用 {# #} 进行注释,注释的内容不会在html中被渲染出来
{# <h1>{{ title }}!!</h1>#}
{# <p>{{ data_list }}</p>#}
{# <p>{{ data_list.1 }}</p>#}<p>{{ data_list[-1]}}</p><p>{{ data_list | last }}</p><p>{{ data_list | first }}</p><p>{{ data_dict }}</p><p>{{ data_dict.name }}</p><p>{{ user_list.0 }}</p>
{# <p>{{ user_list.0.name }}</p>#}
##模板中内置的变量和函数
你可以在自己的模板中访问一些 Flask 默认内置的函数和对象
####config
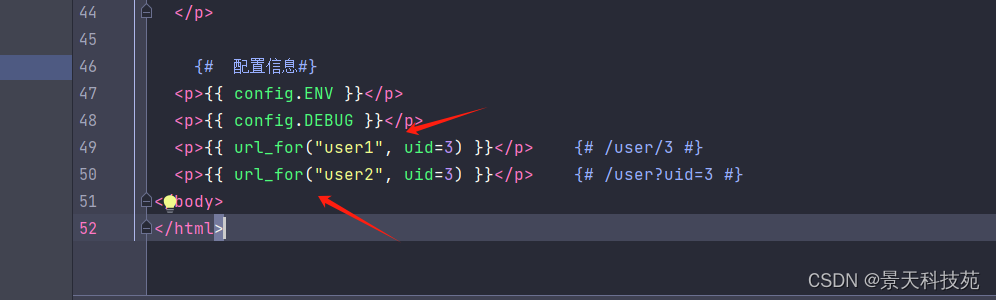
你可以从模板中直接访问Flask当前的config对象:
<p>{{ config.ENV }}</p>
<p>{{ config.DEBUG }}</p>

####request
就是flask中代表当前请求的request对象:
<p>{{ request.url }}</p>
<p>{{ request.path }}</p>
<p>{{ request.method }}</p>
####session
为Flask的session对象,显示session数据
{{session.get("uname")}}
####g变量
在视图函数中设置g变量的 name 属性的值,然后在模板中直接可以取出
{{ g.name }}
####url_for()
url_for会根据传入的路由器函数名,返回该路由对应的URL,在模板中始终使用url_for()就可以安全的修改路由绑定的URL,则不比担心模板中渲染出错的链接:
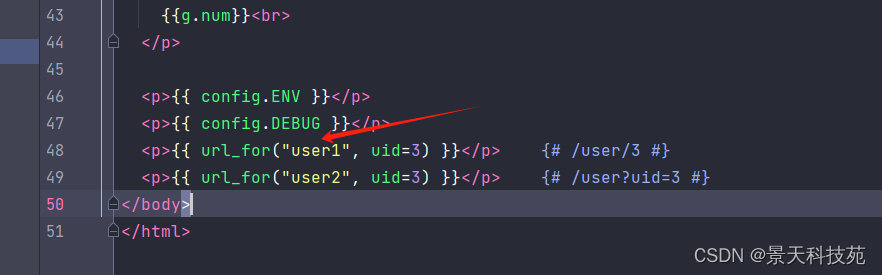
<p>{{ url_for("user1", uid=3) }}</p> {# /user/3 #}<p>{{ url_for("user2", uid=3) }}</p> {# /user?uid=3 #}
浏览器查看

如果我们定义的路由URL是带有参数的,则可以把它们作为关键字参数传入url_for(),Flask会把他们填充进最终生成的URL中:
{{ url_for('index', id=1)}}
/index/1 {# /index/<int:id> id被声明成路由参数 #}
/index?id=1 {# /index id被声明成查询参数 #}
总结
flask内置的模板引擎Jinja2,它的设计思想来源于 Django 的模板引擎DTP(DjangoTemplates),并扩展了其语法和一系列强大的功能。学会使用Jinja2,自己可以轻松开发出一个自己喜欢的网站,
我们在模板中多用变量,少用函数,函数放在视图函数中使用,这才符合MVT思想的路线。喜欢的朋友可以一键三连,flask高阶用法持续更新中!!!
这篇关于【python】flask模板渲染引擎Jinja2,通过后端数据渲染前端页面的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




