本文主要是介绍连夜帮美女小姐姐爬取文献,第二天早晨给她一个Excel文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
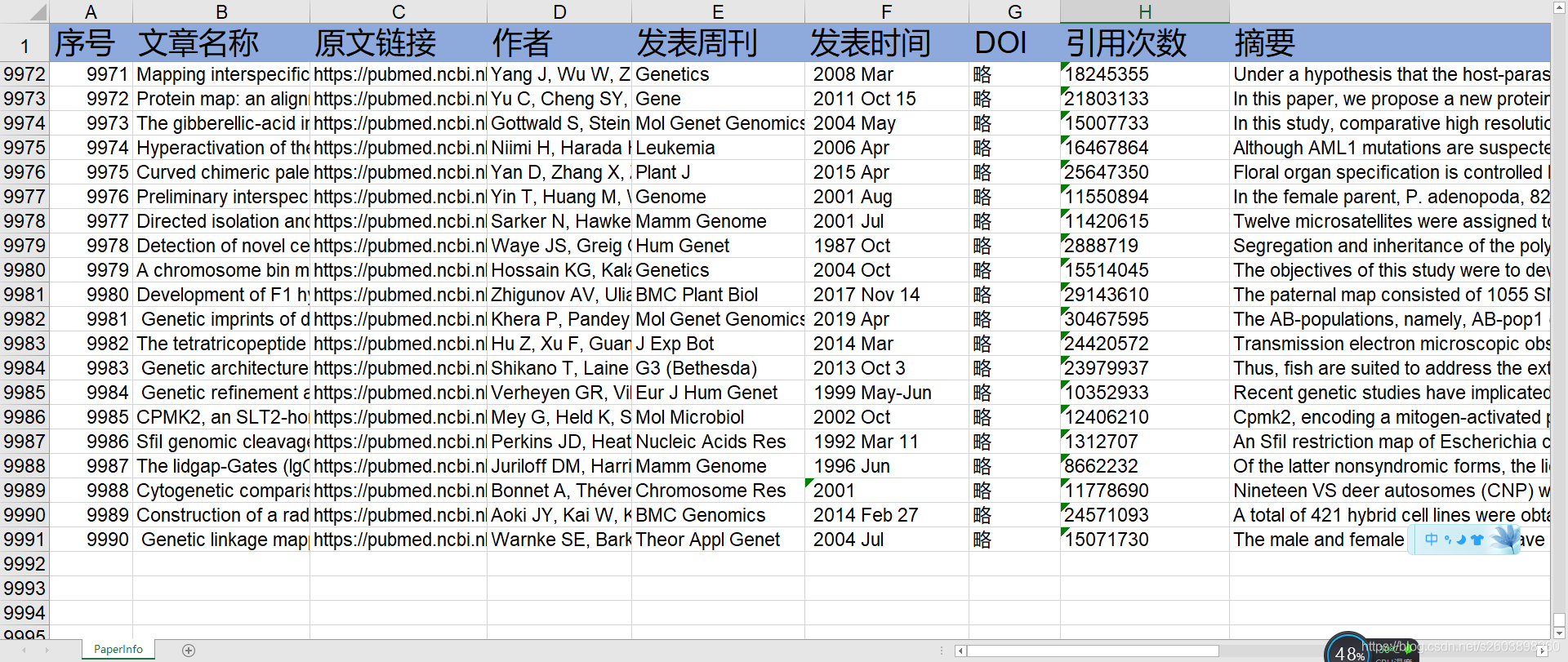
最后爬取的结果如下:
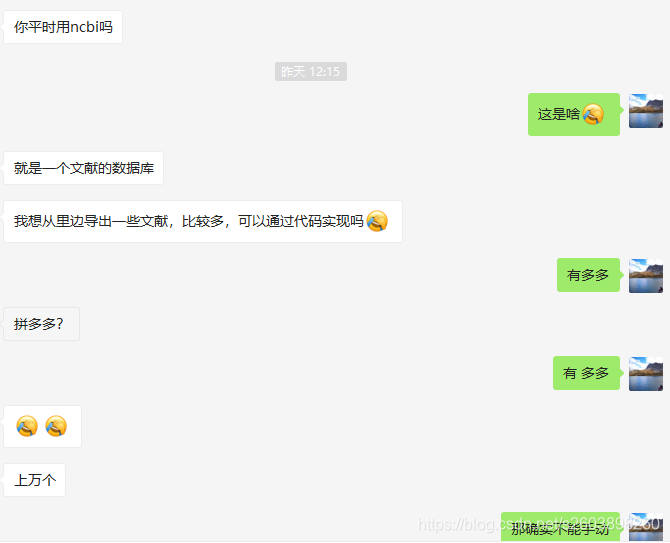
某天中午收到漂亮小姐姐微信,是这样的:
然后晚上10点下班回家开始了连夜写爬虫脚本,终于在2点的时候基本可以用了:

然后早上醒来直接将爬下来的文章发了过去O(∩_∩)O哈哈~。
代码实现如下:
# Author : 叨陪鲤
# Date : 2021/4/10
# Position : Beijing
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
from urllib import request
from urllib import error
import xlwt
import re
import timeTotalNum=0class Article(object):title = ""link = ""authors = ""magz = ""time = ""doi = ""cite = ""snip = ""def __init__(self):title = "New Paper"def html_request(url):if url is None:returnprint("download html is :{0}".format(url))# 如果url包含中文,则需要进行编码# 模拟浏览器行为headers = {'UserAgent': str(UserAgent().random)}req = request.Request(url, headers=headers)try:html = request.urlopen(req).read().decode('utf-8')except error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return None# print(html)return htmldef save_xls(sheet,paper):# 将数据按列存储入excel表格中global TotalNumsheet.write(TotalNum, 0, TotalNum)sheet.write(TotalNum, 1, paper.title)sheet.write(TotalNum, 2, paper.link)sheet.write(TotalNum, 3, paper.authors)sheet.write(TotalNum, 4, paper.magz)sheet.write(TotalNum, 5, paper.time)sheet.write(TotalNum, 6, paper.doi)sheet.write(TotalNum, 7, paper.Cite)sheet.write(TotalNum, 8, paper.Snip)TotalNum += 1# 最初用来调试解析页面用的
def html_parser0():if url is None or html is None:return# 使用正则匹配所有的文章列表pattern_article = '<article class="full-docsum" data-rel-pos=(.+?)</article>'articles = re.compile(pattern_article, re.S).findall(html.replace('\n', ''))# 遍历每一个文章的相关信息for article in articles:soup = BeautifulSoup(article, 'html.parser')title = soup.find('a', attrs={'class': 'docsum-title'})print("[Title]:{0}".format(title.text.replace(' ', '')))print("[Link]:{0}{1}".format("https://pubmed.ncbi.nlm.nih.gov", title.attrs['href']))authors = soup.find('span', attrs={'class': 'docsum-authors full-authors'})print("[Author]:{0}".format(authors.text))citationInfos = soup.find('span', attrs={'class': 'docsum-journal-citation full-journal-citation'})Mtd = "{0}".format(citationInfos.text).split('.')print("[MAGZ]:{0}".format(Mtd[0]))print("[Time]:{0}".format(Mtd[1].split(';')[0]))print("[DOI]:{0}".format(Mtd[2].split(':')[1]))citation = soup.find('span', attrs={'class': 'citation-part'})print("[Cite]:{0}".format(citation.text.split(':')[1]))citation = soup.find('div', attrs={'class': 'full-view-snippet'})print("[Snip]:{0}\n".format(citation.text).replace(' ', ''))def html_parser(sheet, html):if url is None or html is None:return# 使用正则匹配所有的文章列表pattern_article = '<article class="full-docsum" data-rel-pos=(.+?)</article>'articles = re.compile(pattern_article, re.S).findall(html.replace('\n', ''))# 遍历每一个文章的相关信息for article in articles:paper = Article() # 创建一个对象,用来存储文章信息soup = BeautifulSoup(article, 'html.parser')# 分别用来获取不同的关键信息title = soup.find('a', attrs={'class': 'docsum-title'})authors = soup.find('span', attrs={'class': 'docsum-authors full-authors'})citationInfos = soup.find('span', attrs={'class': 'docsum-journal-citation full-journal-citation'})Mtd = "{0}".format(citationInfos.text).split('.')cite = soup.find('span', attrs={'class': 'citation-part'})snip = soup.find('div', attrs={'class': 'full-view-snippet'})# 将信息存储在paper对象上paper.title = "{0}".format(title.text.replace(' ', ''))paper.link = "{0}{1}".format("https://pubmed.ncbi.nlm.nih.gov",title.attrs['href'])paper.authors = "{0}".format(authors.text)paper.magz = "{0}".format(Mtd[0])paper.time = "{0}".format(Mtd[1].split(';')[0])# doi = "{0}".format(Mtd[2].replace(' ','').split(':')[1])paper.doi = "略"paper.Cite = "{0}".format(cite.text.replace(' ','').split(':')[1])paper.Snip = "{0}".format(snip.text).replace(' ', '')save_xls(sheet, paper)# print(Mtd)# print(paper.title)# print(paper.link)# print(paper.authors)# print(paper.magz)# print(paper.time)# print(paper.doi)# print(paper.Cite)# print(paper.Snip)# print("\n")# print("[Title]:{0}".format(title.text.replace(' ', '')))# print("[Link]:{0}{1}".format("https://pubmed.ncbi.nlm.nih.gov",title.attrs['href']))# print("[Author]:{0}".format(authors.text))# print("[MAGZ]:{0}".format(Mtd[0]))# print("[Time]:{0}".format(Mtd[1].split(';')[0]))# print("[DOI]:{0}".format(Mtd[2].split(':')[1]))# print("[Cite]:{0}".format(cite.text.split(':')[1]))# print("[Snip]:{0}\n".format(snip.text).replace(' ', ''))if __name__ == '__main__':myxls = xlwt.Workbook()sheet1 = myxls.add_sheet(u'PaperInfo',True)column = ['序号','文章名称','原文链接','作者','发表周刊','发表时间','DOI','引用次数','摘要']for i in range(0, len(column)):sheet1.write(TotalNum, i, column[i])TotalNum+=1page = 1while page <= 1000:url = "https://pubmed.ncbi.nlm.nih.gov/?term=genetic%20map&page="+str(page)html = html_request(url)html_parser(sheet1, html)myxls.save('NCBI文章之geneticMap.xls')page += 1myxls.save('NCBI文章之geneticMap.xls')
这篇关于连夜帮美女小姐姐爬取文献,第二天早晨给她一个Excel文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








