本文主要是介绍论文浅尝 | KGNLI: 知识图谱增强的自然语言推理模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

笔记整理 | 韩振峰,天津大学硕士
链接:https://aclanthology.org/2020.coling-main.571.pdf
动机
自然语言推理 (NLI) 是自然语言处理中的一项重要任务,它旨在识别两个句子之间的逻辑关系。现有的大多数方法都是基于训练语料库来获得语义知识从而进行推理的,很少采用背景知识或者限制与少量特定类型的知识。本文提出了一种新颖的知识图谱增强的NLI模型(KGNLI),以利用知识图谱中的背景知识。KGNLI 模型由三个模块组成:知识关系表示模块、语义关系表示模块和标签预测模块。与以前的方法不同,本文提出的 KGNLI 模型中可以灵活地组合各种背景知识。在四个数据集(SNLI、MultiNLI、SciTail和BNLI)上的实验验证了模型的有效性。
亮点
KGNLI的亮点主要包括:
1.提出使用句子中的主语、谓语和宾语来构建知识图谱子图,从而获取句子的知识关系表示。2.使用BiLSTM获取句子的语义关系表示,并将其与知识关系表示进行融合。3.模型在四个数据集上都取得了很多好的效果。
概念及模型
KGNLI模型由知识关系表示、语义关系表示和标签预测三个模块组成,模型整体框架如下:
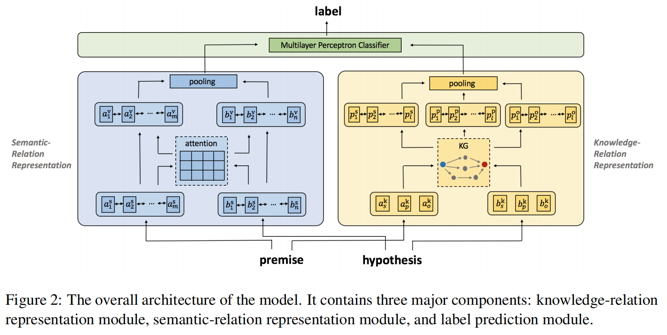
•知识关系表示
本文假设句子对 p 和 h 之间的关系由它们的主语、宾语和谓语之间的关系决定。
背景关系子图:给本文将句子对 p 和 h 中的主语对、谓语对和宾语对分别表示为(p_s, h_s)、(p_p, h_p)和(
这篇关于论文浅尝 | KGNLI: 知识图谱增强的自然语言推理模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








