本文主要是介绍[蓝桥杯 2023 省 A] 颜色平衡树:从零开始理解树上莫队 一颗颜色平衡树引发的惨案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
十四是一名生物工程的学生,他已经7年没碰过信息学竞赛了,有一天他走在蓝桥上看见了一颗漂亮的颜色平衡树:
[蓝桥杯 2023 省 A] 颜色平衡树 - 洛谷

十四想用暴力解决问题,他想枚举每个节点,每个节点代表一棵树,他想只要建立一个桶数组把每次出现的颜色放在桶里,每次遍历完一个节点和它的所有子节点后就统计这个桶数组里的所有非零颜色是否相同,如果相同的话这就是一棵颜色平衡树,如果不相同的话这就不是一棵颜色平衡树。
但是这引来了时间之神乌露提亚的不满:

时间之神乌露提亚说她用尽了所有的魔力和生命也只能让这个世界回退一分钟,所以你必须在一秒之内解决这个问题,十四看了看CCF老爷机每秒只能计算10^8次,然而使用暴力的话时间复杂度怎么着也来到了O(n^2)的级别,所以愚蠢的十四只能求助题解,题解说要用树上莫队,但是愚蠢的十四并不会用树上莫队,所以让我们和十四一起愉快地学习树上莫队吧~
树上莫队前置知识:分块,普通莫队,修改莫队,回滚莫队
十四是要成为火影的男人,所以他并不会把前置知识列出来然后让看题解小伙伴们自己去找资料学习这些内容,所以让我们和十四一起愉快地学习分块吧~
分块算法
我们先来看一道题:
https://www.acwing.com/problem/content/description/244/


屏幕前的大佬一眼就看出来了这是一道线断树的板子题,但是愚蠢的十四并不会写线断树,所以十四本能地想用暴力解决问题:
十四每次在修改指令的时候从左到右枚举,把数列中的数字一个一个加上指定的值,然后在询问的时候也从做到右一个一个把数列上的数字加起来得到结果,每次操作预期进行n次运算,要进行m次这样的操作,那么时间复杂度就来到了O(nm),但是N和M的最大值是10^5,如果有10^5个数,和10^5次操作的话,一秒内就有10^5*10^5=10^10次操作,但是可怜的CCF老爷机一秒只能进行10^8次运算,所以十四决定对这个暴力的办法进行一些优化:
十四想要把N个数的序列从头到尾分成长度相等的很多很多部分,每次C操作的时候,如果操作的序列[l,r]能覆盖很多区间的话,就会有以下情况:
我们假设5个数字为一部分(一块),于是11~15、16~20、21~25、25~30将这个序列分成了四块,此时我们想进行这样的操作:C 13 27 3 也就是把从13到27的数字每个加上3
| 数列下标 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 数值 | 1 | 1 | 4 | 5 | 1 | 4 | 1 | 9 | 1 | 9 | 8 | 1 | 0 | 1 | 1 | 4 | 5 | 1 | 4 | 1 |
我们用黄色和绿色表示分隔开来的分块,用紫色表示需要修改的区间,那么显然我们看见紫色的区域完整地覆盖住了16~20、21~25这两块,十四想到能不能建立一个块标记数组,这个数组存的是完整的块中的每个数字需要加上的数字,例如这里就要把16~20和21~25这两个完整的块中每个数字都要加上3,于是我们引入块标记数组:
| 数列下标 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 数值 | 1 | 1 | 4 | 5 | 1 | 4 | 1 | 9 | 1 | 9 | 8 | 1 | 0 | 1 | 1 | 4 | 5 | 1 | 4 | 1 |
| 块 | 11~15 | 16~20 | 21~25 | 26~30 |
| 块标记 | 0 | 3 | 3 | 0 |
十四发现只要这次对块进行标记,只进行了2次标记就操作了2*5=10个数字,非常节省时间,但是这时候就出现了另外一个问题:完整的块之外的数字怎么进行操作?
我们发现13~15和26~27这两部分还没有进行操作,如果改动11~15和26~30这两个块的块标记的话就会牵连到无辜的11~12和28~30,所以十四决定一个一个地把13、14、15、26、27的数加上3:
| 数列下标 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 数值 | 1 | 1 | 7 | 8 | 4 | 4 | 1 | 9 | 1 | 9 | 8 | 1 | 0 | 1 | 1 | 7 | 8 | 1 | 4 | 1 |
| 块 | 11~15 | 16~20 | 21~25 | 26~30 |
| 块标记 | 0 | 3 | 3 | 0 |
这样就完美地解决了C 13 27 3的操作,但是屏幕前的你提出了异议(一斤鸭梨):如果对所有没有被完整覆盖的块里需要修改的元素一个一个地修改的话不是仍然有和暴力一样的复杂度吗?这样的话和直接暴力有什么很大的区别吗?
但是通过观察,我们发现:每次操作的过程中没有被覆盖的块最多两个,也就是说,我们需要一个一个操作的块最多是两个。那么我们假设每块里面有a个元素,这样的话序列中的n个元素就被我们分成了(n/a)块,对于我们每次的操作,我们最多要对(n/a)块进行块标记,并且对没有覆盖的2块内最多有2*a=2a个元素一个一个进行修改,所以对于每次操作,我们有(n/a)+2a次操作要进行,要把这个次数降到最少,我们不妨把a定为 ,这样我们就发现(n/a)和2a的操作次数在同一个数量级,于是我们得出结论,在这一题的分块中,我们把每块的元素个数定为
可以使得操作的次数降到最低,那么对m次操作,我们题的时间复杂度也就算出来了:O(m
),怎么样,是不是比之前的O(nm)要优化了一些呢? 机遇这样的时间复杂度,我们这题的所有数据也能在一秒之内算出来了。
最后剩下一个问题:对于询问的Q l r,我们要怎么操作呢?
类似于修改的操作,我们把每块的和计为sum,在输入的时候对每块进行预处理,在修改的时候,加上块内修改元素的个数乘以修改的值,这样我们就能轻松维护块内所有值的和,对于被询问区间完全覆盖的块,我们直接加上这块的和值,对于没有被完全覆盖的块(同样也是最多两个这样的块),我们直接暴力加起来就好啦~
对于所有在块内的询问和操作区间,我们全部暴力就好啦,反正块内的元素最多个,暴力同样不会增加时间复杂度~
下面附上十四的AC代码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
using namespace std;
long long a[100001],devi[100001];
struct node{long long sum=0;long long tag=0;int l=0,r=0;
}blk[100001];
void add(int u,int v,long long k){int LP=devi[u],RP=devi[v];if(LP==RP){for(int i=u;i<=v;i++)a[i]+=k;blk[LP].sum+=k*(v-u+1);}else{for(int i=u;i<=blk[LP].r;i++)a[i]+=k;blk[LP].sum+=k*(blk[LP].r-u+1);for(int i=blk[RP].l;i<=v;i++)a[i]+=k;blk[RP].sum+=k*(v-blk[RP].l+1);for(int i=LP+1;i<RP;i++){blk[i].tag+=k;blk[i].sum+=k*(blk[i].r-blk[i].l+1);}}return ;
}
long long quest(int u,int v){int LP=devi[u],RP=devi[v];long long ans=0;if(LP==RP){for(int i=u;i<=v;i++)ans+=a[i]+blk[LP].tag;return ans;}else{for(int i=u;i<=blk[LP].r;i++)ans+=a[i]+blk[LP].tag;for(int i=blk[RP].l;i<=v;i++)ans+=a[i]+blk[RP].tag;for(int i=LP+1;i<RP;i++)ans+=blk[i].sum;return ans;}
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,m,n;long long k;scanf("%d%d",&n,&m);int len=sqrt(n);for(i=1;i<=n;i++){scanf("%lld",&a[i]);devi[i]=(i-1)/len+1;blk[devi[i]].sum+=a[i];if(i%len==0) blk[devi[i]].r=i;if((i-1)%len==0) blk[devi[i]].l=i;}char c[2];while(m--){int u,v;scanf("%s",c);scanf("%d%d",&u,&v);if(u>v){ int t=u;u=v;v=t; }if(c[0]=='C'){scanf("%lld",&k);add(u,v,k);}else printf("%lld\n",quest(u,v));}return 0;
}
我们再来看一道分块的题:Anton and Permutation - 洛谷

emmm我们先来看看逆序对是什么:逆序对是对于给定的一段正整数序列,存在序列中ai>aj且i<j的有序对。(百度百科就是好,一下就帮我水了十几个字),那么每次交换两个数a[u],a[v](u<v),这两个数坐标之外的数自然不会被影响,序列中在这两个数中间的数,当且仅当数字满足min(a[u],a[v])<a[q]<max(a[u],[v])且u<q<v的时候,如果a[u]>a[v],a[q]就会和a[u]、a[v]a产生两个新的逆序对,但如果a[u]<a[v],a[q]则与a[u]、a[v]原先产生的逆序对就会消失,我们针对这一点对整个序列分块之后,每块内初始的元素都是从小到大的顺序陈列的,我们每次交换之后只需维护每块内从小到大的顺序,每次块外查询直接暴力(分一个不排序的数组a记前后顺序),块内直接二分查看有多少个数字在(a[u],a[v])范围之内(这个操作用到二分,当然就用有顺序的数组v啦)
下面附上十四的AC码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<vector>
using namespace std;
vector<int> v[501];
int a[200001],devi[200001];
struct node{int l,r;
}blk[501];
long long solve(int l,int r){if(l==r) return 0;int xx=a[l],yy=a[r];int LP=devi[xx],RP=devi[yy],k;long long f=1,ans=0;k=find(v[LP].begin(),v[LP].end(),xx)-v[LP].begin();v[LP][k]=yy; devi[yy]=LP;sort(v[LP].begin(),v[LP].end());k=find(v[RP].begin(),v[RP].end(),yy)-v[RP].begin();v[RP][k]=xx; devi[xx]=RP;sort(v[RP].begin(),v[RP].end());if(xx>yy){f=-1;int t=xx; xx=yy; yy=t;}if(LP==RP){for(int i=l+1;i<r;i++)if(xx<a[i] && a[i]<yy)ans++;}else{for(int i=l+1;i<=blk[LP].r;i++)if(xx<a[i] && a[i]<yy)ans++;for(int i=blk[RP].l;i<r;i++)if(xx<a[i] && a[i]<yy)ans++;for(int i=LP+1;i<RP;i++)ans+=lower_bound(v[i].begin(),v[i].end(),yy)-upper_bound(v[i].begin(),v[i].end(),xx);}int t=a[l];a[l]=a[r];a[r]=t;return (ans*2+1)*f;
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,k,m,n,q,tot=0;scanf("%d%d",&n,&q);int len=sqrt(n);for(i=0;i<=n;i++){ devi[i]=0;a[i]=0; }for(i=1;i<=n;i++){a[i]=i;devi[i]=(i-1)/len+1;v[devi[i]].push_back(i);if((i-1)%len==0) blk[++tot].l=i;if(i%len==0) blk[tot].r=i;}long long ans=0;while(q--){int l,r;scanf("%d%d",&l,&r);if(l>r){ int t=l;l=r;r=t; }ans+=solve(l,r);printf("%lld\n",ans);}return 0;
}十四的内心逐渐膨胀了起来,觉得紫题不过如此,于是决定再切一道分块紫题:作诗 - 洛谷
同一块内出现的偶数元素当然是固定的,但是在一段区间内,有其他的块,也有一些不完整的块内元素,所以对于不完整的块内元素每次固然是暴力统计,然而对于完整的块,我们可以提前预处理出完整的块相连中偶数次出现的元素个数f,同时用cnt记录从每块的头开始记录每个元素出现到整个数列结尾的次数,这样通过相减可以便捷地统计出每个元素在连接的完整的块间的出现次数,这样可以和两边暴力统计出来的元素个数相加,得出新的对偶元素,同时也可以去掉由于完整的块间是偶数次出现次数,而加上边缘暴力统计之后沦落为奇数次出现的元素。
按照惯例,下面附上十四的AC码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
using namespace std;
struct node{int l,r;
}blk[100001];
int a[100001],devi[100001],n,c;
int cnt[320][100001],f[320][320];
int lst[100001],num[100001];
int solve(int l,int r){int LP=devi[l],RP=devi[r];if(LP==RP){int sum=0,top=0;for(int i=l;i<=r;i++){num[a[i]]++;lst[++top]=a[i];}while(top){if(num[lst[top]]%2==0 && num[lst[top]]!=0)sum++;num[lst[top]]=0;top--;}return sum;}else{int sum=0,top=0;if(RP>LP+1) sum=f[LP+1][RP-1];for(int i=l;i<=blk[LP].r;i++){num[a[i]]++;lst[++top]=a[i];}for(int i=blk[RP].l;i<=r;i++){num[a[i]]++;lst[++top]=a[i];}while(top){int t=lst[top];if(num[t]!=0 && t!=0){int u=cnt[LP+1][t]-cnt[RP][t];if(u%2==1 && num[t]%2==1) sum++;if(u==0 && num[t]%2==0) sum++;if(u%2==0 && num[t]%2==1 && u>0) sum--;}num[t]=0;top--;}return sum;}
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,k,m,tot=0;scanf("%d%d%d",&n,&c,&m);int len=sqrt(n);for(i=0;i<=len+1;i++)for(j=0;j<=len+1;j++)f[i][j]=0;for(i=0;i<=len+1;i++)for(j=0;j<=c;j++)cnt[i][j]=0;for(i=0;i<=n;i++){ lst[i]=0;num[i]=0; }for(i=1;i<=n;i++){scanf("%d",&a[i]);devi[i]=(i-1)/len+1;if((i-1)%len==0) blk[++tot].l=i;if(i%len==0) blk[tot].r=i;}blk[tot].r=n;for(i=1;i<=n;i+=len){int di=devi[i],sum=0;for(j=i;j<=n;j++){cnt[di][a[j]]++;if(cnt[di][a[j]]%2!=0 && cnt[di][a[j]]>1){sum--;}else if(cnt[di][a[j]]%2==0) sum++;if(j==n) f[di][devi[j]]=sum;else if(j%len==0) f[di][devi[j]]=sum;}}int lans=0;while(m--){int l,r;scanf("%d%d",&l,&r);l=((l+lans)%n)+1;r=((r+lans)%n)+1;if(l>r){ int t=l;l=r;r=t; }int ans=solve(l,r);printf("%d\n",ans);lans=ans;}return 0;
}
十四彻底膨胀了,他决定再来一道紫题目:[Violet] 蒲公英 - 洛谷
我们可以申请n个vector数组储存每种元素出现的坐标,这样我们就可以在之后方便地统计元素的出现次数,同样分块,统计连接的块之间最大的出现次数和加上块外的部分最大出现次数的元素~
那么我们就愉快地和十四一起AC掉这道题吧:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<vector>
using namespace std;
struct node{int l,r;
}blk[205];
vector<int> v[40010];
int devi[40010],a[40010];
int cnt[40010],f[205][205];
int c[40010];
int lst[40010],num[40010];
int get_num(int &l,int &r,int &k){return upper_bound(v[k].begin(),v[k].end(),r)-lower_bound(v[k].begin(),v[k].end(),l);
}
int solve(int l,int r){int LP=devi[l],RP=devi[r];if(LP==RP){int ans=0,maxsum=0;for(int i=l;i<=r;i++){int t=get_num(l,r,a[i]);if(t>maxsum || (t==maxsum && a[i]<ans)){ans=a[i];maxsum=t;}}return c[ans];}else{int ans=0,maxsum=0;if(RP>LP+1){ans=f[LP+1][RP-1];maxsum=get_num(l,r,ans);}for(int i=l;i<=blk[LP].r;i++){int t=get_num(l,r,a[i]);if(t>maxsum || (t==maxsum && a[i]<ans)){ans=a[i];maxsum=t;}}for(int i=blk[RP].l;i<=r;i++){int t=get_num(l,r,a[i]);if(t>maxsum || (t==maxsum && a[i]<ans)){ans=a[i];maxsum=t;}}return c[ans];}
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,k,m,n,tot=0;scanf("%d%d",&n,&m);int len=sqrt(n);for(i=1;i<=n;i++){scanf("%d",&a[i]);devi[i]=(i-1)/len+1;if((i-1)%len==0) blk[++tot].l=i;if(i%len==0) blk[tot].r=i;c[i]=a[i];}blk[tot].r=n;sort(c+1,c+n+1);for(i=1;i<=n;i++){a[i]=lower_bound(c+1,c+n+1,a[i])-c;v[a[i]].push_back(i);}for(i=1;i<=n;i+=len){int di=devi[i];int maxn=0;memset(cnt,0,sizeof(cnt));for(j=i;j<=n;j++){cnt[a[j]]++;if(cnt[a[j]]>cnt[maxn] || (cnt[a[j]]==cnt[maxn] && a[j]<maxn)) maxn=a[j];if(j==n) f[di][devi[j]]=maxn;if(j%len==0) f[di][devi[j]]=maxn;}}int lans=0;while(m--){int u,v;scanf("%d%d",&u,&v);u=((u+lans-1)%n)+1;v=((v+lans-1)%n)+1;if(u>v){ int t=u;u=v;v=t; }int ans=solve(u,v);printf("%d\n",ans);lans=ans;}return 0;
}莫队算法
通过上面的例题,你已经熟练地掌握了分块,那么我们就来看看莫队算法吧~
不知道屏幕前的小伙伴们在做题的时候有没有发现上面有很多题里面提到了“在线”这一概念,其实在线的意思就是通过各种办法强行让你按照题目所给出的询问顺序来进行查询操作,具体能强制你在线的方法大概有:每一次询问区间由上一次询问的结果加密得到,或者是在询问的区间内加上一些修改的操作,那么出题人为什么对在线这么重视呢?这当然是因为“离线”即不按照题给的顺序进行查询能对时间的要求降低很多。
莫队就是这样一种针对离线查询的算法:我们将众多的询问按照以下规则进行排序:1.区间左边所在的块下标靠前的排在前面;2.区间左边在同一个块内的话按照区间右边从小到大排序。
电视机前的小伙伴们于是就有了疑问:对于区间的右边我们按元素从小到大排序,那我们为什么不对区间左边边按元素从小到大排序呢?这样不是更佳精准吗?
我们先来看一道题目:
[SDOI2009] HH的项链 - 洛谷
我们首先按照上述规则对询问区间进行排序,然后设置左指针lz=1和右指针rz=0,对区间按顺序进行如下操作:
while(lz<l) del(a[lz++],sum);while(lz>l) add(a[--lz],sum);while(rz<r) add(a[++rz],sum);while(rz>r) del(a[rz--],sum);那么我们如何让时间复杂度尽量低呢?自然是减少指针的移动次数,回到上面提出的疑问,如果我们对区间的左边进行严格排序而不是按照分块排序的话,区间右边自然不能愉快地从小到大排序,所以右指针在这一排序规则下移动次数会大很多,而对于莫队算法的排序,左指针的移动次数仅仅限制在一个区间范围之内,而右指针在左区间相同的条件下也只有一个移动方向,这自然最大程度地避免了指针来回移动,同时能将时间复杂度降到最低。
通过上述思考,我们知道了莫队是基于对离线的询问进行排序,然后用指针进行暴力移动,在此基础上尽量减少指针的移动次数的算法。
下面附上十四的代码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
using namespace std;
int a[1000010],devi[1000010];
int cnt[1000010];
struct node{int id,l,r;
}q[1000010];
int ans[1000010];
bool cmp(const node& a,const node& b){int LP=devi[a.l],RP=devi[b.l];if(LP!=RP) return LP<RP;return a.r<b.r;
}
void add(int x,int &sum){if(!cnt[x]) sum++;cnt[x]++;
}
void del(int x,int &sum){cnt[x]--;if(!cnt[x]) sum--;
}
int main(){int i,j,k,m,n;scanf("%d",&n);int len=sqrt(n);for(i=1;i<=n;i++){scanf("%d",&a[i]);devi[i]=(i-1)/len+1;cnt[a[i]]=0;}scanf("%d",&m);for(i=1;i<=m;i++){q[i].id=i;scanf("%d%d",&q[i].l,&q[i].r);}sort(q+1,q+m+1,cmp);int lz=0,rz=0,sum=0;for(k=1;k<=m;k++){int l=q[k].l,r=q[k].r,id=q[k].id;while(lz<l) del(a[lz++],sum);while(lz>l) add(a[--lz],sum);while(rz<r) add(a[++rz],sum);while(rz>r) del(a[rz--],sum);ans[id]=sum;}for(i=1;i<=m;i++) printf("%d\n",ans[i]);return 0;
}修改莫队
通过上述的了解,我们知道了莫队是对于在线非常敏感的算法,但是对于一些修改类的强制在线,我们是可以用一些神奇的膜法绕过去的,我们来看这道题:[国家集训队] 数颜色 / 维护队列 - 洛谷

我们按照操作顺序设置一个时间戳,每次操作推进时间向前一步
for(i=1;i<=m;i++){char op[2];int u,v;scanf("%s%d%d",op,&u,&v);if(*op=='Q'){mq++; q[mq].id=mq;q[mq].l=u;q[mq].r=v;q[mq].t=mc;}else if(*op=='R'){c[++mc].q=u;c[mc].c=v;}}那么对于所有的询问来说,有哪些可以被影响到呢?我们通过思考可以想到对于这样的区间当切仅当满足以下条件:1.这个询问的时间戳在修改区间的时间之后,2.这个询问的区间和修改的区间范围有交集
如果不满足以上两点我们自然可以愉快地按照莫队算法进行计算,那么如果这个区间被影响了要怎么办呢?这里涉及到一个小技巧:我们可以把所有的修改操作存在一个数组里,当修改进行时,只需要将当前的数和修改数组里的数进行交换即可,那么在改回来的时候再次交换就又换回了原来的数。
下面附上十四的AC代码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
using namespace std;
const int N=2000000;
int devi[N],a[N],mc,mq,cnt[N],ans[N];
struct Query{int id,l,r,t;
}q[N];
struct Modify{int q,c;
}c[N];
bool cmp(const Query& a,const Query& b){int al=devi[a.l],ar=devi[a.r];int bl=devi[b.l],br=devi[b.r];if(al!=bl) return al<bl;if(ar!=br) return ar<br;return a.t<b.t;
}
void add(int x,int &sum){if(!cnt[x]) sum++;cnt[x]++;
}
void del(int x,int &sum){cnt[x]--;if(!cnt[x]) sum--;
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,k,m,n;scanf("%d%d",&n,&m);for(i=1;i<=n;i++)scanf("%d",&a[i]);mc=0;mq=0;for(i=1;i<=m;i++){char op[2];int u,v;scanf("%s%d%d",op,&u,&v);if(*op=='Q'){mq++; q[mq].id=mq;q[mq].l=u;q[mq].r=v;q[mq].t=mc;}else if(*op=='R'){c[++mc].q=u;c[mc].c=v;}}int len=cbrt((double)n * max(1,mc))+1;for(i=1;i<=max(n,m);i++) devi[i]=i/len;c[0].q=0;sort(q+1,q+mq+1,cmp);int lz=1,rz=0,sum=0,tz=0;memset(cnt,0,sizeof(cnt));for(i=1;i<=mq;i++){int l=q[i].l,r=q[i].r,t=q[i].t,id=q[i].id;while(rz<r) add(a[++rz],sum);while(rz>r) del(a[rz--],sum);while(lz<l) del(a[lz++],sum);while(lz>l) add(a[--lz],sum);while(tz<t){tz++;int cge=c[tz].q;if(l<=cge && cge<=r){add(c[tz].c,sum);del(a[cge],sum);}swap(a[cge],c[tz].c);}while(tz>t){int cge=c[tz].q;if(l<=cge && cge<=r){add(c[tz].c,sum);del(a[cge],sum);}swap(a[cge],c[tz].c);tz--;}ans[id]=sum;}for(i=1;i<=mq;i++) printf("%d\n",ans[i]);return 0;
}✳️回滚莫队/不删除莫队
我们来看这样一道题目:给你一个长度为n的数组A和m个询问区间,每次询问区间【L,R】内重要度最大的数字,要求输出其重要度,这里i的重要度的定义是i*i在区间内出现的次数
对于区间内出现的次数增加我们自然是很好操作的,那么对于删除呢?我们即便可以将左指针向右推,我们也不能对与区间最大的重要度去除对于删除元素的影响,那么我们可以进行如下操作:
如果询问区间在同一个块内,我们直接从左到右暴力即可
对于所有左区间在一个块内的询问区间我们将指针移动分为两拨,我们设置一个right=blk[LP].r,我们把左指针lz=right+1,右指rz=right。
我们先移动又指针到q[x].r,由于询问区间已经按照规则排序的缘故,在计算之后的区间时,右指针只有向右移动这一个方向。移动好之后我们先用一个临时变量记录一下这时候最重要的状态。
接下来我们向左边移动左指针,移动到q[x].l时候,更新最重要的状态,并且在这时候记录到ans数组里面。
记录完之后,我们将最重要的状态赋值为之前用临时变量记录的状态,这一步的操作就叫做回滚,这样我们就回到了不被左边影响的状态。
接下来我们将左指针移动到right+1处,进行下一个询问的统计。
当所有区间左边在一个块内的询问处理好之后,我们把一切记录状态的数组和变量清零,进行下一个询问区间的操作。
这就是回滚莫队,通过巧妙的指针移动避开了难以维护的状态。
✳️树上莫队
经过了上面的铺垫,我们终于可以来理解树上莫队啦~
按照惯例我们来看一道题目:COT2 - Count on a tree II - 洛谷

这题给出的树是这样的:
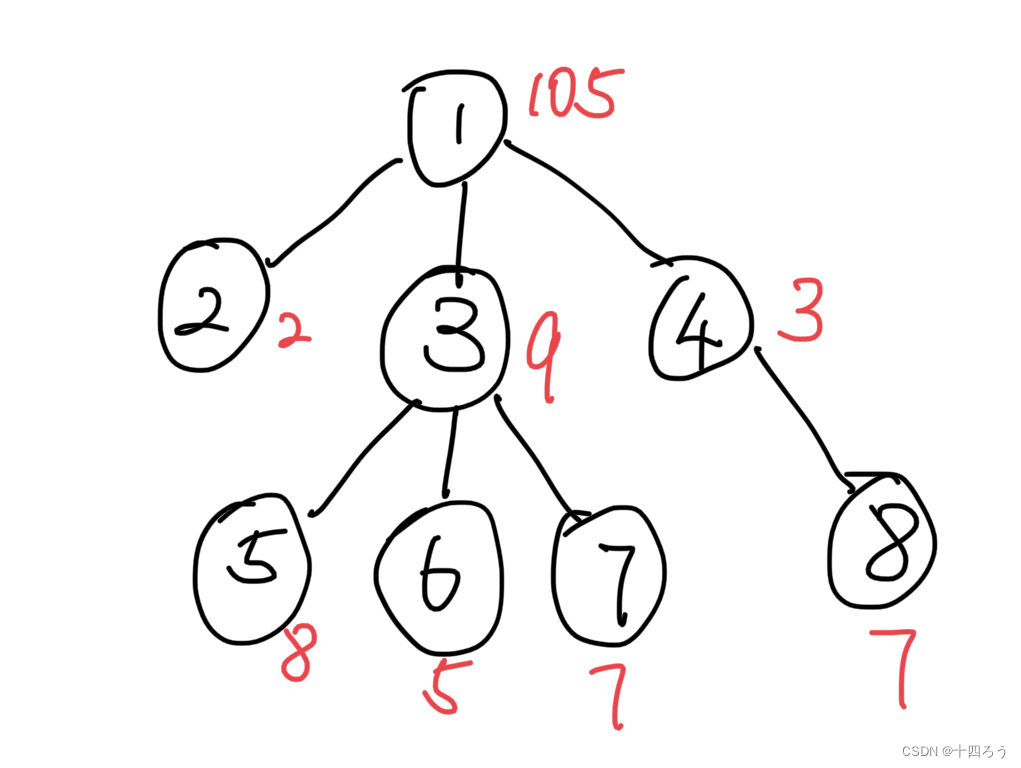
我们引入一个新的概念:欧拉数列,即在dfs遍历的时候,最开始的时候记录一下,结束的时候记录一下:
void bjdfs(int x,int father){ora[++oranum]=x;fst[x]=oranum;for(int i=pre[x];i!=0;i=edge[i].next){int y=edge[i].to;if(y==father) continue;bjdfs(y,x);}ora[++oranum]=x;lst[x]=oranum;return ;
}这样这棵树就被ora序列就记录成了: 1 4 8 8 4 3 7 7 6 6 5 5 3 2 2 1
我们同时可以顺手记录下每个元素出现的位置fst[i]和结束时出现的位置lst[i],我们通过观察可以发现对于两个元素u,v的路径上出现的元素,只会在lst[u]道fst[v]上出现一次,并且路径上两节点的最近公共祖先lca则不会出现,所以对于每条路径,我们只要记录欧拉序列中出现一次的元素和lca即可,记得要考虑好u是u和v的lca这样的情况。
下面附上十四的代码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<vector>
using namespace std;
const int N=1000100;
struct Query{int id,l,r,p;
}q[N];
struct node{int next,to;
}edge[N];
int fst[N],lst[N],a[N],len,tot,pre[N],ans[N];
int ora[N],cnt[N],oranum,depth[N],vis[N],dp[N][20];
int appt[N];
vector<int> px;
int get_devi(int x){return (x-1)/len+1;
}
int cmp(const Query& a,const Query& b){int LP=get_devi(a.l),RP=get_devi(b.l);if(LP!=RP) return LP<RP;return a.r<b.r;
}
void addedge(int u,int v){edge[++tot].next=pre[u];edge[tot].to=v; pre[u]=tot;return ;
}
void bjdfs(int x,int father){ora[++oranum]=x;fst[x]=oranum;for(int i=pre[x];i!=0;i=edge[i].next){int y=edge[i].to;if(y==father) continue;bjdfs(y,x);}ora[++oranum]=x;lst[x]=oranum;return ;
}
void lcadfs(int x){for(int i=1;(i<<i)<depth[x];i++)dp[x][i]=dp[dp[x][i-1]][i-1];for(int i=pre[x];i!=0;i=edge[i].next){int y=edge[i].to;if(vis[y]) continue;vis[y]=1;dp[y][0]=x;depth[y]=depth[x]+1;lcadfs(y);}return ;
}
void add(int x,int &sum){appt[x]^=1;if(appt[x]){if(!cnt[a[x]]) sum++;cnt[a[x]]++;}else{cnt[a[x]]--;if(!cnt[a[x]]) sum--;}return ;
}
int lca(int a,int b){int u=a,v=b;if(depth[u]<depth[v]) swap(u,v);int k=log2(depth[u]-depth[v]);for(int i=k;i>=0;i--)if(depth[dp[u][i]]>=depth[v])u=dp[u][i];if(u==v) return u;k=log2(depth[u]);for(int i=k;i>=0;i--){if(dp[u][i]==dp[v][i]) continue;u=dp[u][i];v=dp[v][i];}return dp[u][0];
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,k,m,n;scanf("%d%d",&n,&m);for(i=1;i<=n;i++){scanf("%d",&a[i]);px.push_back(a[i]);}sort(px.begin(),px.end());px.erase(unique(px.begin(),px.end()),px.end());for(i=1;i<=n;i++) a[i]=lower_bound(px.begin(),px.end(),a[i])-px.begin();for(i=1;i<n;i++){int u,v;scanf("%d%d",&u,&v);addedge(u,v);addedge(v,u);}bjdfs(1,-1);len=sqrt(oranum);memset(depth,0,sizeof(depth));memset(vis,0,sizeof(vis));memset(dp,0,sizeof(dp));depth[1]=1;vis[1]=1;lcadfs(1);for(i=1;i<=m;i++){int u,v;scanf("%d%d",&u,&v);if(fst[u]>fst[v]) swap(u,v);int p=lca(u,v);if(p==u){q[i].id=i;q[i].l=fst[u];q[i].r=fst[v];}else{q[i].id=i;q[i].l=lst[u];q[i].r=fst[v];q[i].p=p;}}sort(q+1,q+m+1,cmp);int lz=1,rz=0,sum=0;memset(cnt,0,sizeof(cnt));memset(appt,0,sizeof(appt));for(int i=1;i<=m;i++){int l=q[i].l,r=q[i].r,p=q[i].p,id=q[i].id;while(rz<r) add(ora[++rz],sum);while(rz>r) add(ora[rz--],sum);while(lz>l) add(ora[--lz],sum);while(lz<l) add(ora[lz++],sum);if(p) add(p,sum);ans[id]=sum;if(p) add(p,sum);}for(int i=1;i<=m;i++)printf("%d\n",ans[i]);return 0;
}最后我们来看看颜色平衡树这道题
十四经过上面的联系,十四不由自主地想出了这样一个解法:对于欧拉数列,从fst[i]到lst[i]即可表达一颗完整的子树,而通过枚举n个节点,统计其对应的所有fst[i]~lst[i]中的颜色数量即可,可以先自己制造问题:所有的fst[i]~lst[i],然后基于欧拉数列的分块进行排序这些询问区间,然后用莫队的算法通过移动指针得到每个区间的颜色数量。
问题来了,既然维护的是颜色出现的次数,每次要进行判断,我们自然不肯能枚举每个元素,然后挨个挨个查非零的元素是否出现了同样的次数,那我们对于删除元素的处理自然非常麻烦,于是我们想到了用回滚莫队的方法维护last数组
下面是十四的AC代码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<algorithm>
using namespace std;
const int N=400100;
int len,ora[N],oranum,tot,fst[N],lst[N];
int cnt[N],last[N],color[N],top,pre[N];
struct node{int next,to;
}edge[N];
struct Query{int l,r;
}q[N];
struct block{int l,r;
}blk[N];
int get_devi(int x){return (x-1)/len+1;
}
int cmp(const Query& a,const Query& b){int LP=get_devi(a.l),RP=get_devi(b.l);if(LP!=RP) return LP<RP;else return a.r<b.r;
}
void addedge(int u,int v){edge[++tot].next=pre[u];pre[u]=tot;edge[tot].to=v;return ;
}
void bjdfs(int x){ora[++oranum]=x;fst[x]=oranum;for(int i=pre[x];i!=0;i=edge[i].next){int y=edge[i].to;bjdfs(y);}ora[++oranum]=x;lst[x]=oranum;return ;
}
void add(int x){cnt[x]++;return ;
}
void del(int x){cnt[x]--;return ;
}
int main(){//freopen("test.in","r",stdin);//freopen("test.out","w",stdout);int i,j,k,m,n,s;scanf("%d",&n);for(i=1;i<=n;i++){int u,v;scanf("%d%d",&u,&v);color[i]=u;if(v==0){ s=i; continue; }addedge(v,i);}bjdfs(s);len=sqrt(oranum);int blktot=0;for(i=1;i<=oranum;i++){if((i-1)%len==0) blk[++blktot].l=i;if(i%len==0) blk[blktot].r=i;}blk[blktot].r=oranum;int qsnum=0;for(i=1;i<=n;i++){q[++qsnum].l=fst[i];q[qsnum].r=lst[i];}sort(q+1,q+n+1,cmp);memset(cnt,0,sizeof(cnt));memset(last,0,sizeof(last));int lz=1,rz=0;top=0;int ans=0,x;for(x=1;x<=n;){int y=x;while(y<=n && get_devi(q[y].l)==get_devi(q[x].l)) y++;int right=blk[get_devi(q[x].l)].r;while(x<y && q[x].r<=right){int l=q[x].l,r=q[x].r;for(j=l;j<=r;j++){add(color[ora[j]]);last[++top]=color[ora[j]];}int flag=1,asnum=cnt[last[top]];top--;while(top>0){if(cnt[last[top]]!=asnum){flag=0;break;}top--;}top=0;if(flag==1)ans++;for(j=l;j<=r;j++) del(color[ora[j]]);x++;}int rz=right,lz=right+1;while(x<y){int l=q[x].l,r=q[x].r,sign;while(rz<r){add(color[ora[++rz]]);last[++top]=color[ora[rz]];}sign=top;while(lz>l){add(color[ora[--lz]]);last[++top]=color[ora[lz]];}int ttop=top,asnum=cnt[last[ttop]];ttop--; int flag=1;while(ttop>0){if(cnt[last[ttop]]!=asnum){flag=0;break;}ttop--;}if(flag==1) ans++;top=sign;while(lz<right+1) del(color[ora[lz++]]);x++;}top=0;memset(cnt,0,sizeof(cnt));}printf("%d\n",ans);return 0;
}
嗨嗨嗨,十四这下终于能睡个好觉了,让我们来恭喜他吧~
这篇关于[蓝桥杯 2023 省 A] 颜色平衡树:从零开始理解树上莫队 一颗颜色平衡树引发的惨案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








