本文主要是介绍如何本地部署Elasticsearch+cpolar实现公网查询与管理内网数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 系统环境
- 1. Windows 安装Elasticsearch
- 2. 本地访问Elasticsearch
- 3. Windows 安装 Cpolar
- 4. 创建Elasticsearch公网访问地址
- 5. 远程访问Elasticsearch
- 6. 设置固定二级子域名
正文开始前给大家推荐个网站,前些天发现了一个巨牛的 人工智能学习网站, 通俗易懂,风趣幽默,忍不住分享一下给大家。[点击跳转到网站]
Elasticsearch是一个基于Lucene库的分布式搜索和分析引擎,它提供了一个分布式、多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档,同时也是是一个非常强大的工具,可以用于各种用途,例如日志分析、搜索引擎、安全分析等等。
远程连接的好处在于可以让用户从远程位置访问Elasticsearch集群,这样可以方便地进行数据查询和管理。具体好处如下:
- 方便远程协作:远程连接可以让多个用户从不同的地方同时访问Elasticsearch集群,方便团队协作和数据共享。
- 提高数据安全性:远程连接可以让用户在本地进行数据查询和管理,避免了在服务器上直接操作数据的风险,提高了数据的安全性。
- 方便数据备份:远程连接可以让用户方便地将数据备份到本地,避免了数据丢失的风险。
- 提高数据处理效率:远程连接可以让用户在本地进行数据处理和分析,避免了数据传输的时间和带宽限制,提高了数据处理效率。
下面介绍在Windows 安装Elasticsearch 并结合Cpolar实现远程连接和访问!
系统环境
JDK 1.8
1. Windows 安装Elasticsearch
进入官方下载界面: https://www.elastic.co/downloads/elasticsearch,选择windows版本下载,Elasticsearch 运行需要java 环境,如果没有安装环境,需要提前安装 JDK.
下载完成后进行解压,进入bin目录,找到elasticsearch.bat脚本文件执行一键启动.
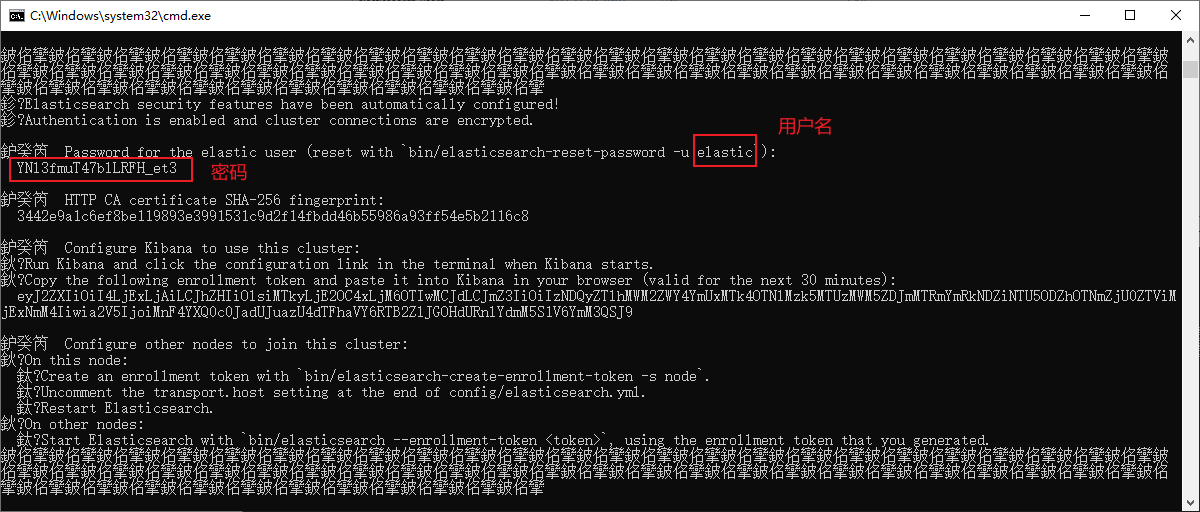
启动后,特别注意一下cmd窗口的一个用户名和一个密码信息,访问登录需要这个用户名密码
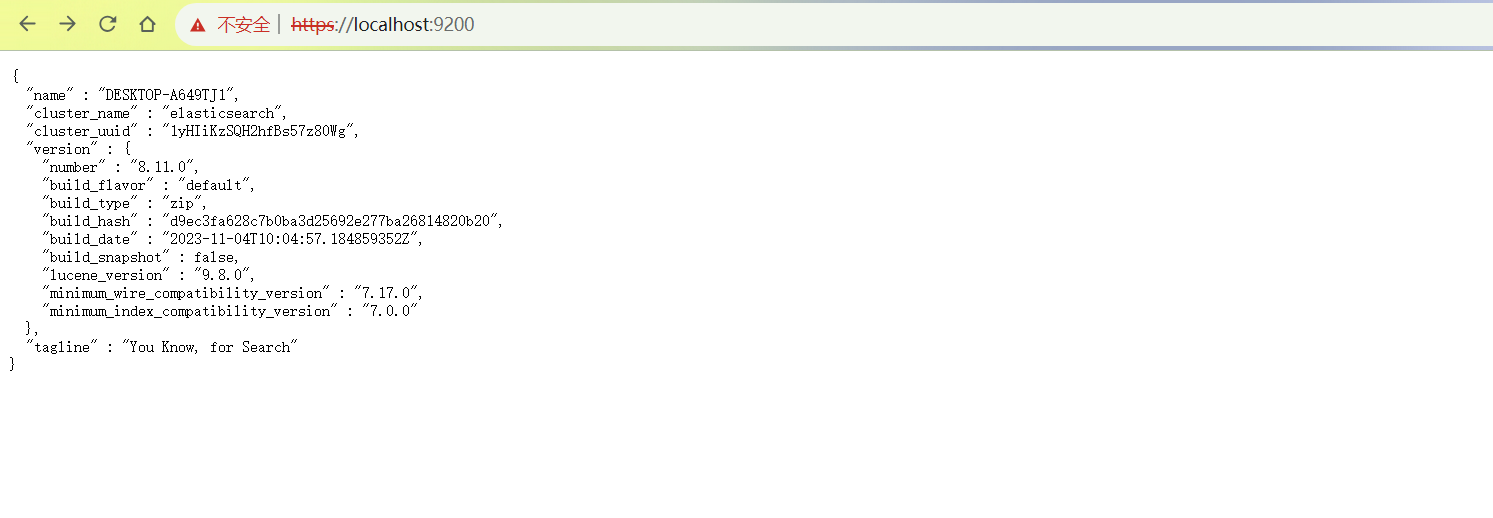
2. 本地访问Elasticsearch
运行服务后,浏览器输入https://lcoalhost:9200,会提示输入用户名密码,填写上面我们看到的用户名:elastic 和对应的密码,即可访问成功,下面进行安装Cpolar 工具,实现远程访问
3. Windows 安装 Cpolar
访问cpolar官网,注册一个账号,然后下载并安装客户端,具体安装教程可以参考官网文档教程。
Cpolar官网:https://www.cpolar.com/download
- windows系统:在官网下载安装包后,双击安装包一路默认安装即可。
- linux系统:支持一键自动安装脚本,详细请参考官网文档——入门指南
注意! Cpolar安装成功后,默认Cpolar web 界面访问端口也是9200,和Elasticsearch 会有冲突,需要修改一下Cpolar 管理界面端口,如果Elasticsearch 的端口不是9200,可以不用修改.
找到cpolar配置文件:c:\Users\用户名\.cpolar\cpolar.yml,使用Notepad++编辑工具或者其他软件打开
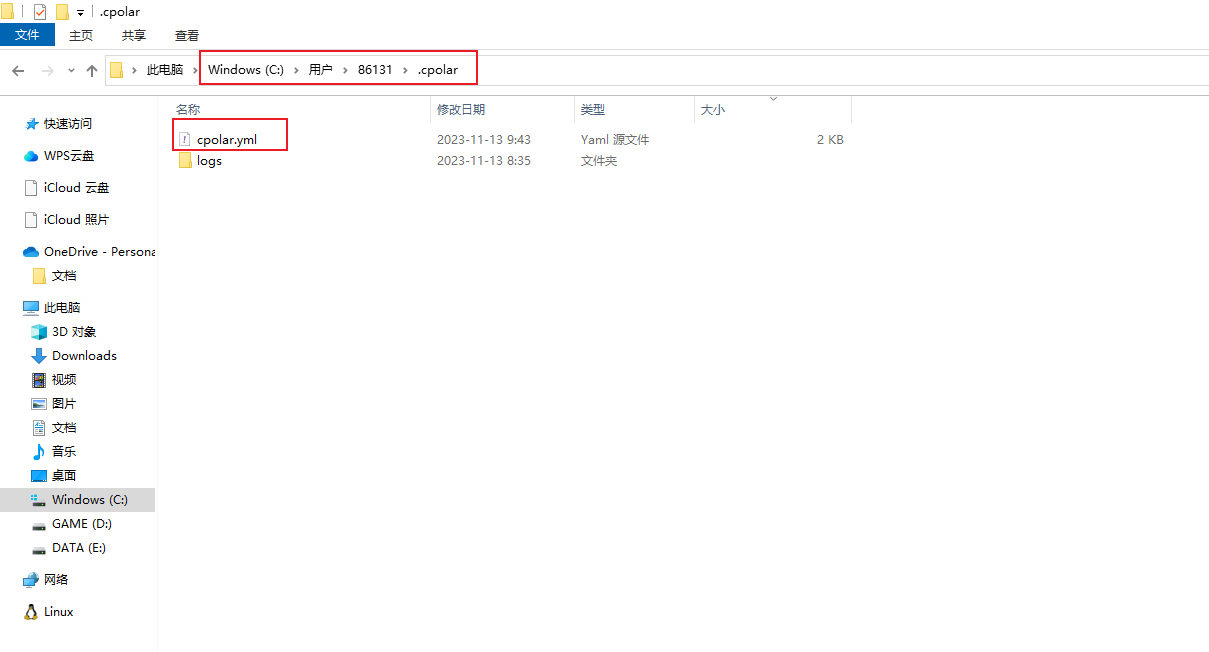
在配置文件中,增加一行:client_dashboard_addr: 127.0.0.1:9800,端口可以自定义,这边使用9800
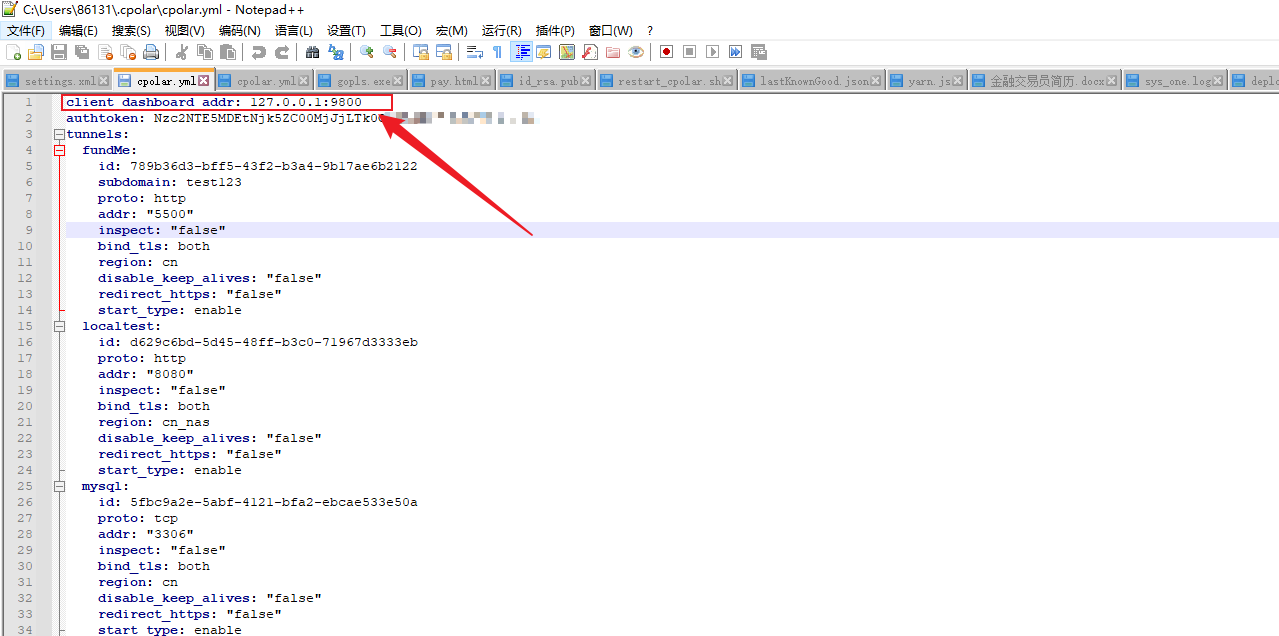
修改好后,记得保存配置文件,然后在控制面板–管理工具—服务—cpolar service,重启cpolar服务
然后浏览器输入localhost:9800,即可访问到了Cpolar Web UI 管理界面,输入官网注册的账号即可登录操作了.
4. 创建Elasticsearch公网访问地址
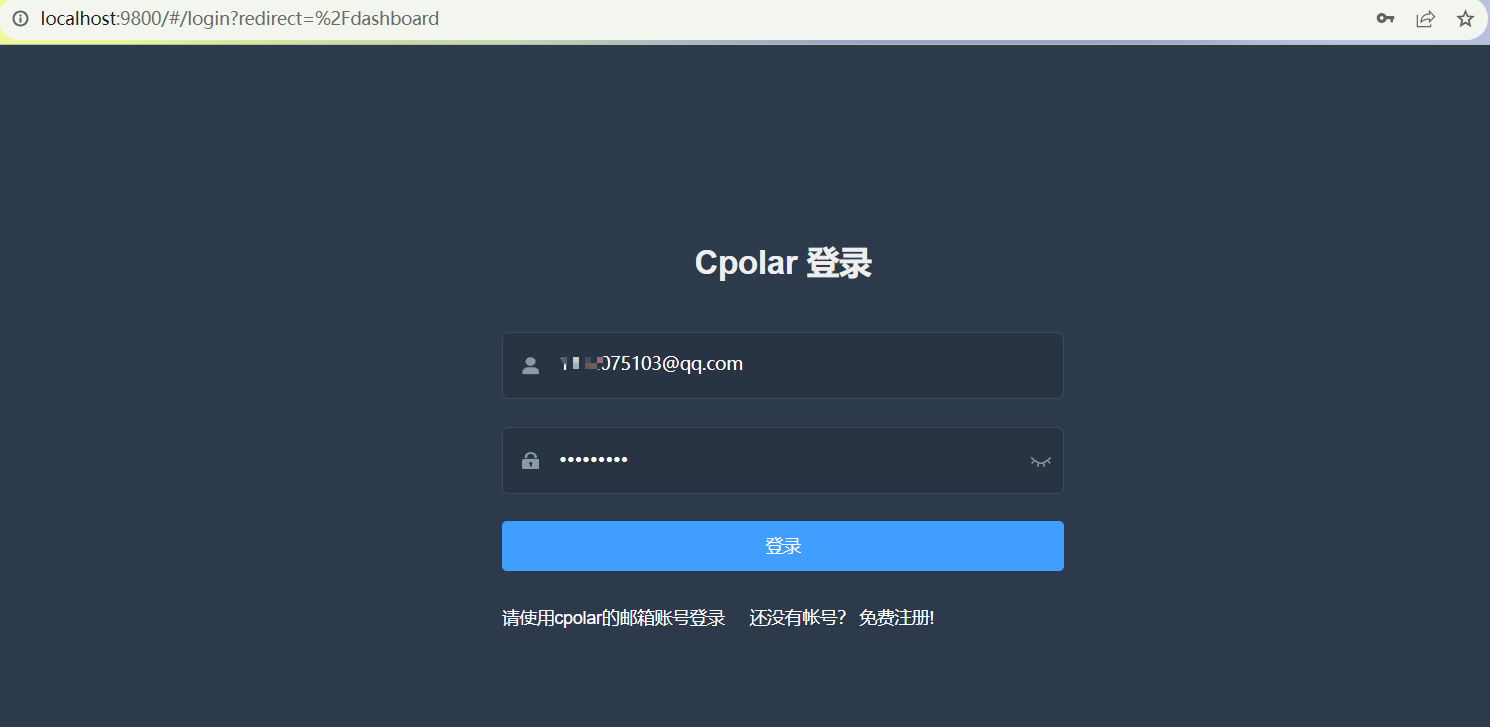
登录后,点击左侧仪表盘的隧道管理——创建隧道,创建一个9200的http隧道
- 隧道名称:可自定义命名,注意不要与已有的隧道名称重复
- 协议:选择http
- 本地地址:https://127.0.0.1:9200 (https本地访问的方式填写完整地址)
- 域名类型:免费选择随机域名
- 地区:选择China
点击创建
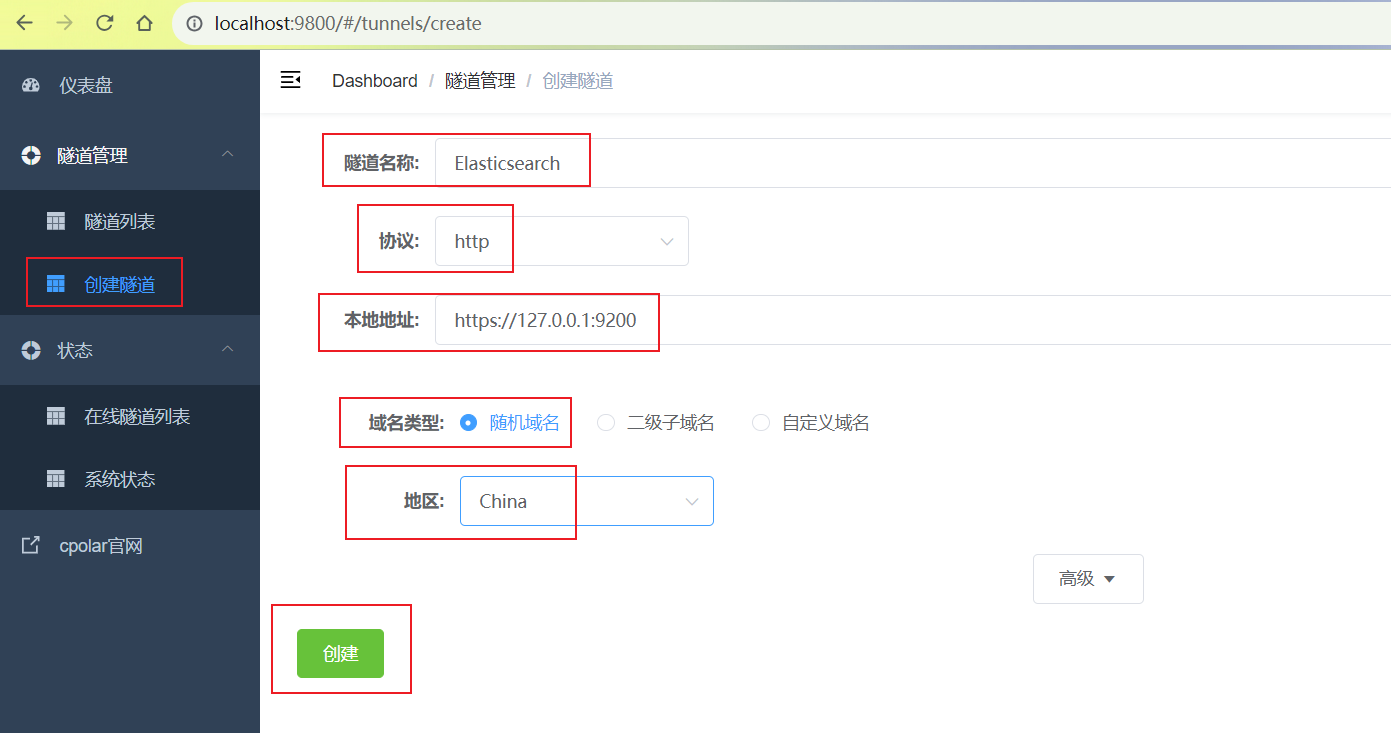
隧道创建成功后,点击左侧的状态——在线隧道列表,查看所生成的公网访问地址,有两种访问方式,一种是http 和https,由于本地是https,我们只需要使用https地址即可
5. 远程访问Elasticsearch
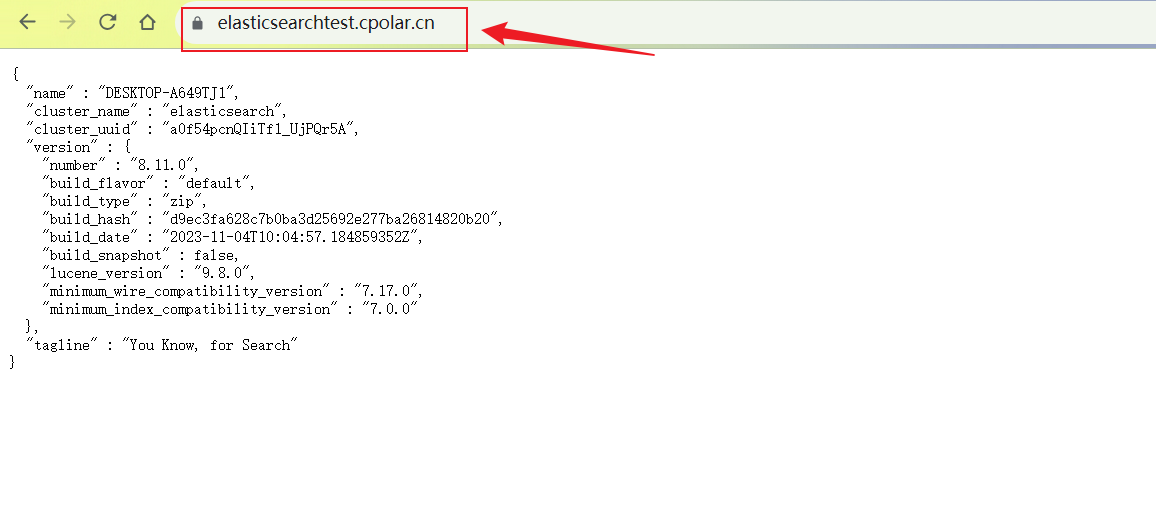
打开浏览器,使用Cpolar https公网地址访问,可以看到,访问成功,这样一个远程或者任意设备浏览器访问的公网地址就设置好了.

小结
为了更好地演示,我们在前述过程中使用了cpolar生成的隧道,其公网地址是随机生成的。
这种随机地址的优势在于建立速度快,可以立即使用。然而,它的缺点是网址由随机字符生成,不太容易记忆(例如:3ad5da5.r10.cpolar.top)。另外,这个地址在24小时内会发生随机变化,更适合于临时使用。
我一般会使用固定二级子域名,原因是我希望将网址发送给同事或客户时,它是一个固定、易记的公网地址(例如:crm.cpolar.cn),这样更显正式,便于流交协作。
6. 设置固定二级子域名
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访问。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化【ps:cpolar.cn已备案】
注意需要将cpolar套餐升级至基础套餐或以上,且每个套餐对应的带宽不一样。【cpolar.cn已备案】
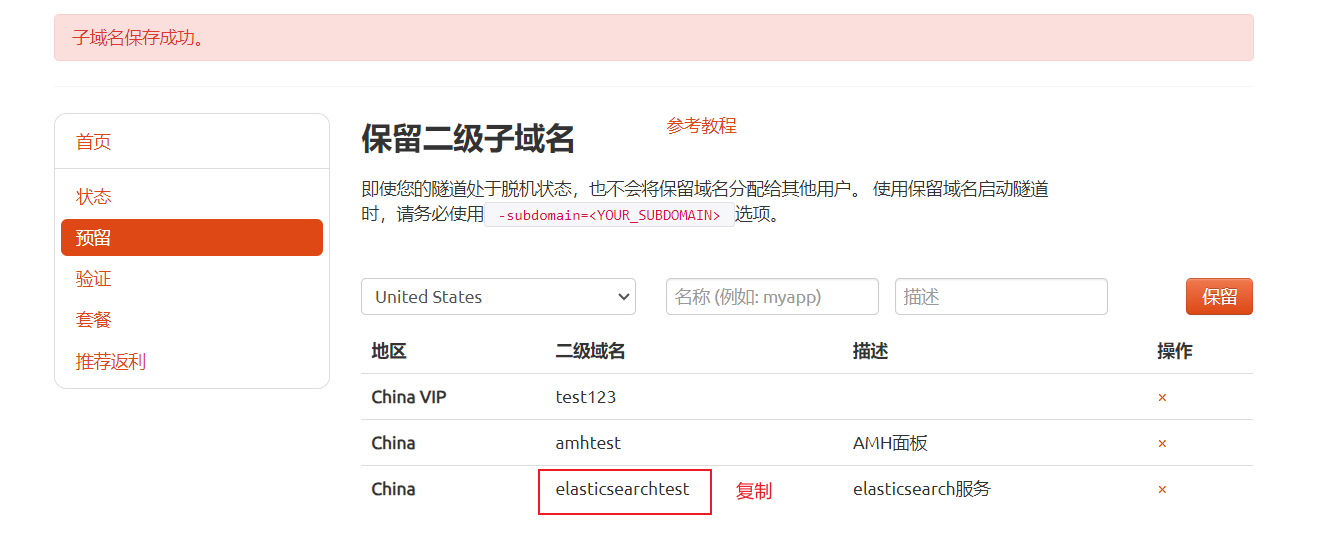
登录cpolar官网后台,点击左侧的预留,选择保留二级子域名,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称
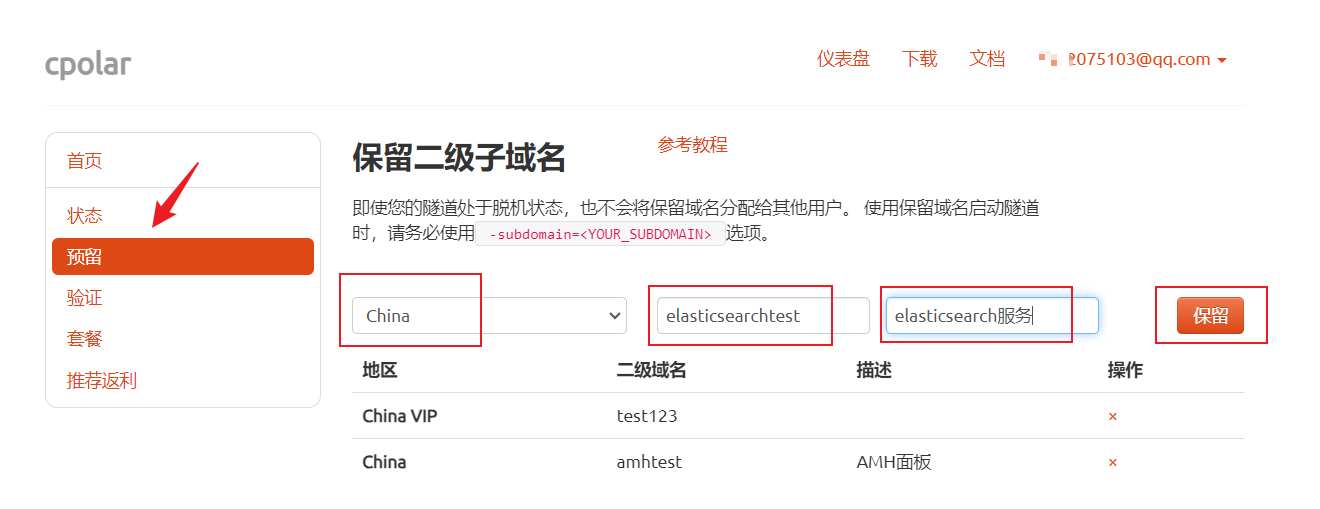
保留成功后复制保留的二级子域名地址
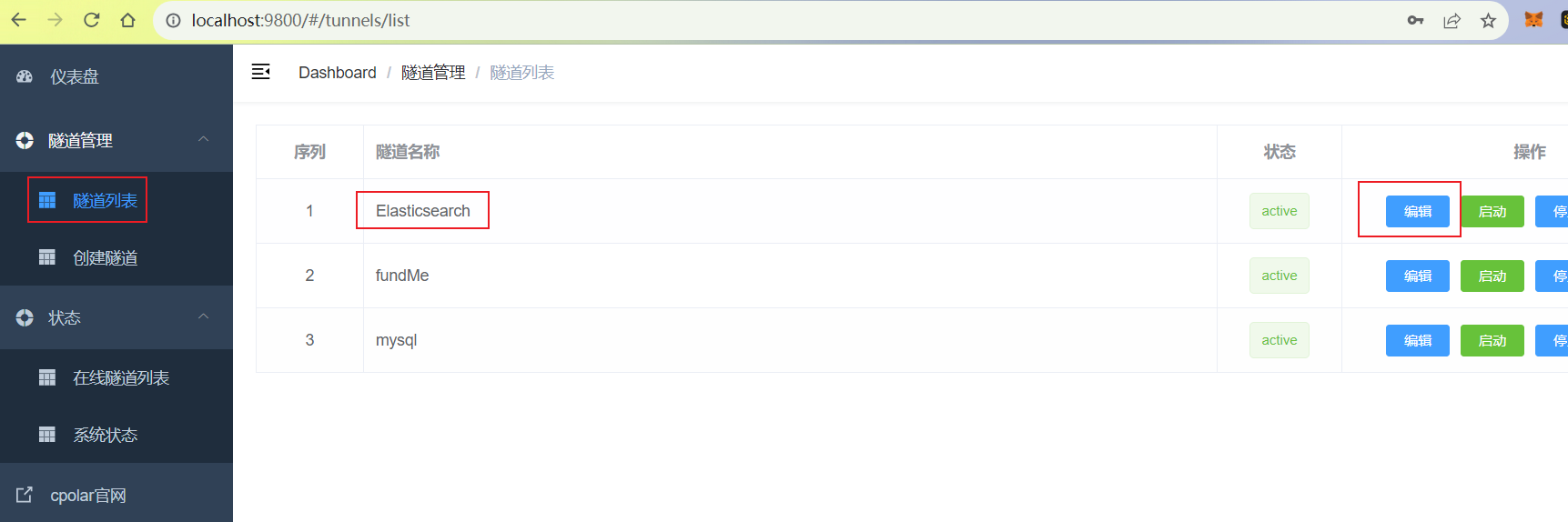
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑
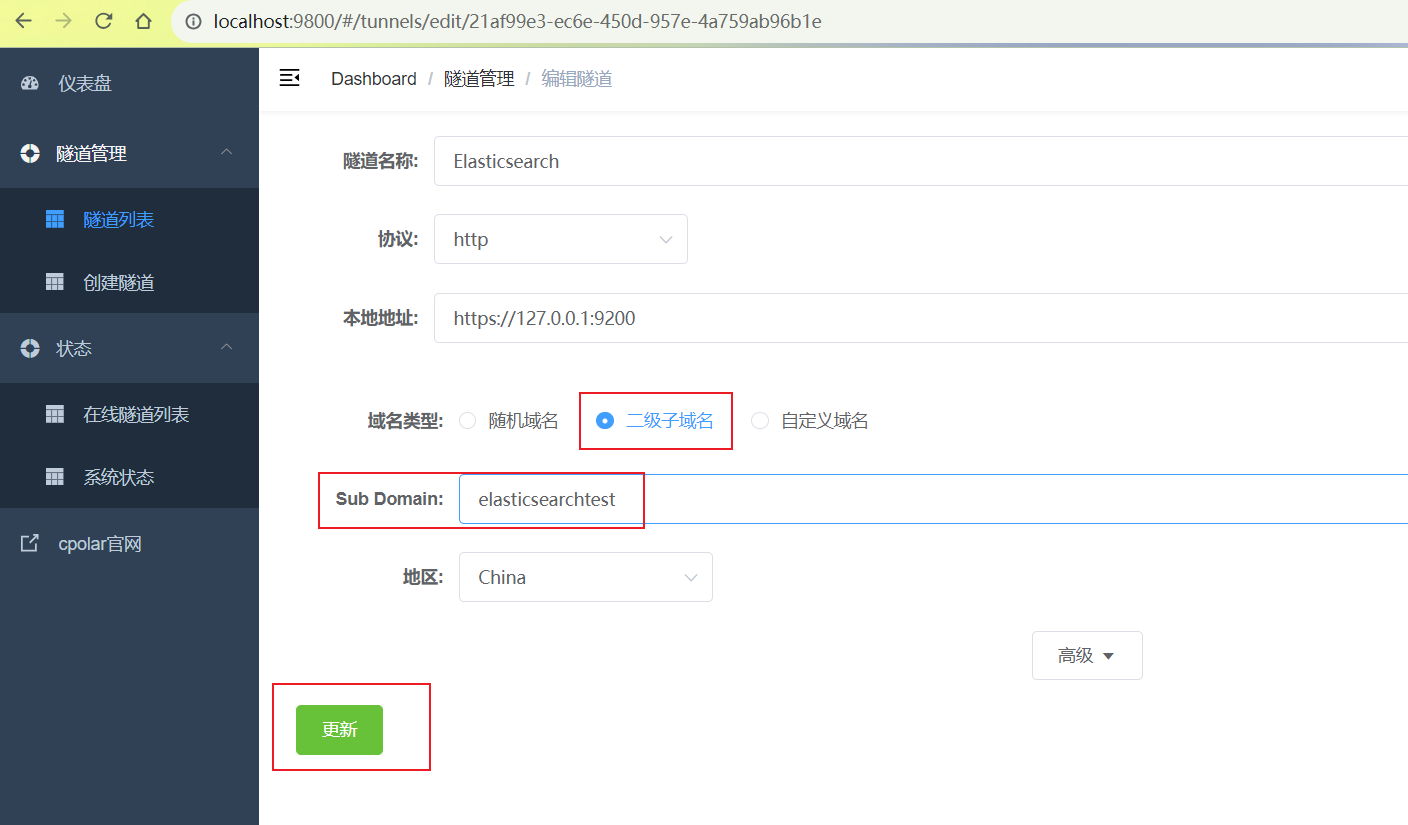
修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
点击更新
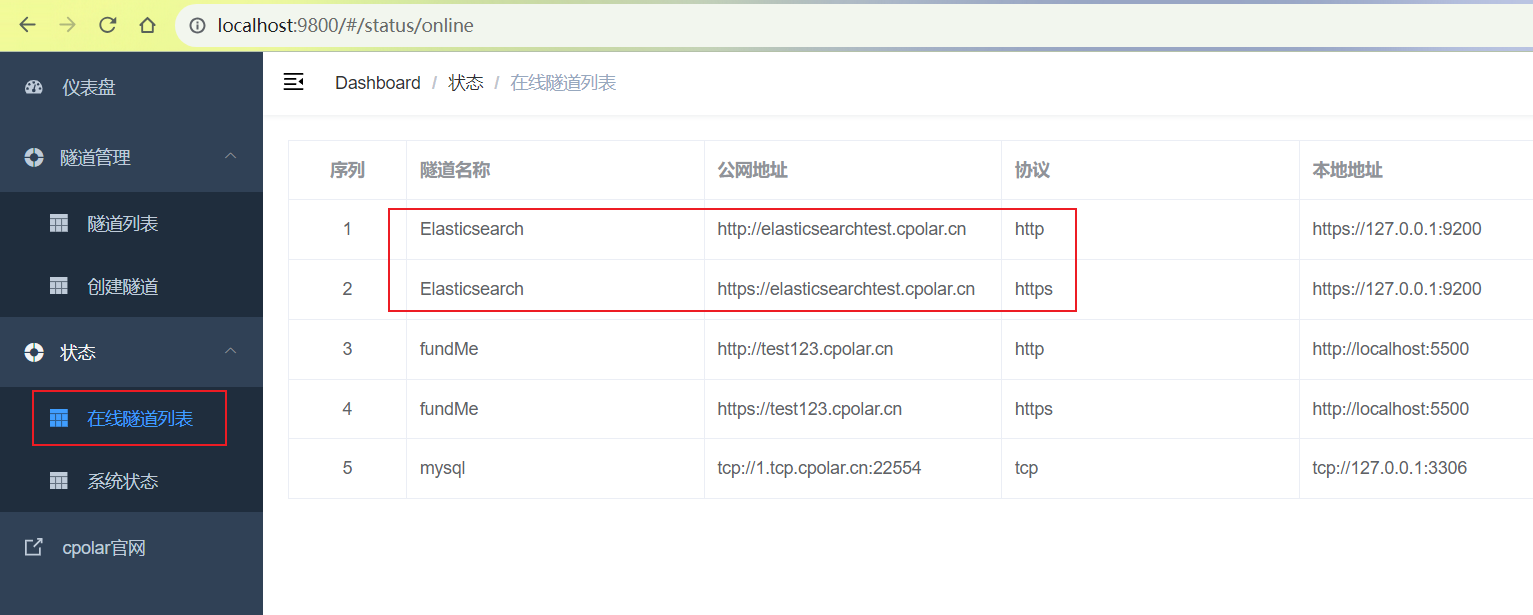
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了保留和固定的二级子域名名称
最后,使用固定的域名公网https地址访问,可以看到同样也是访问成功,这样一个永久固定不变的公网地址就设置好了!
这篇关于如何本地部署Elasticsearch+cpolar实现公网查询与管理内网数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






