本文主要是介绍2023混合多比特层-RDHEI Based on the Mixed Multi-Bit Layer Embedding Strategy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RRBE
本文仅供自我学习记录,切勿转载和搬运,如有侵权联系立删!
方法总框架
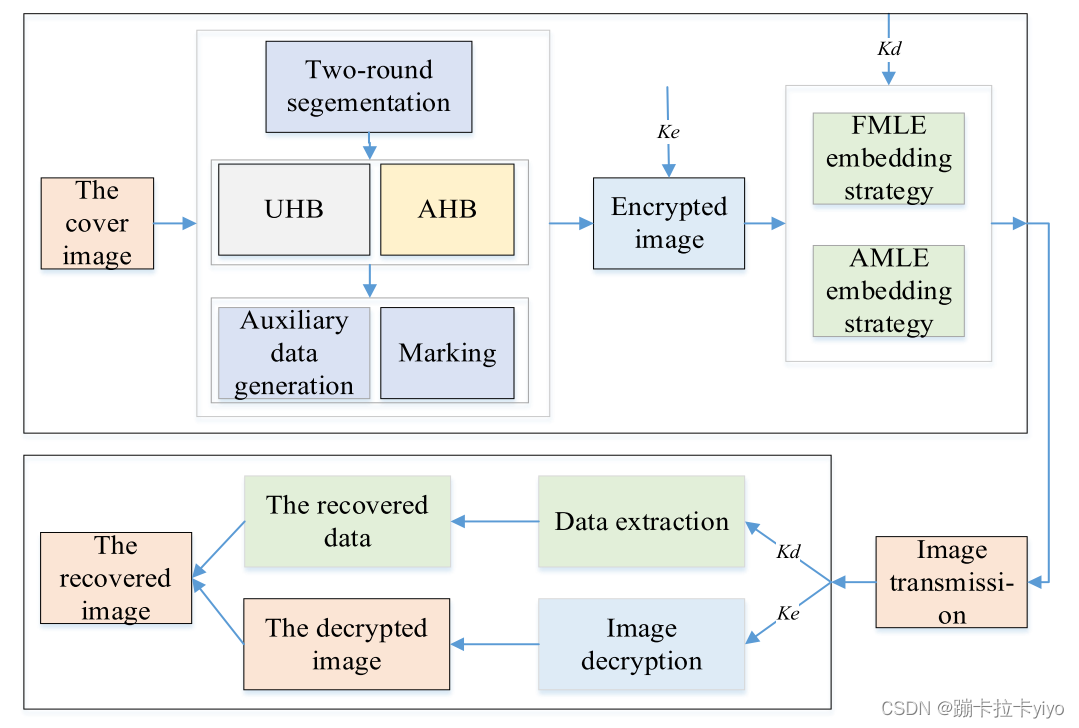
首先,发送者将载体图像进行两轮的不重叠块分割,分为可用隐藏块(AHB)和不可用隐藏块(UHB),然后通过依次处理可用块的像素信息产生location图来创造空间,接着通过密钥将载体进行加密,最后使用数据隐藏密钥将辅助数据和秘密数据加密后通过两个嵌入策略FMLE、AMLE完成嵌入;接收者可以根据所拥有的密钥类型来分别提取所需的数据和恢复封面图象。
方法详细介绍
A图像预处理
加密之前腾出空间的操作,主要包含两轮分割、参数的设置、辅助信息的生成和其他步骤。
A.1第一轮分割
将原始图像按行进行不重叠的分块,每块的大小为
,每个块所包含的像素有
,块内像素的索引被表示为向量
。接下来设置阈值
(2的指数),来判断块是否可嵌。每个块内以第一个像素
为参考像素,依次计算块内剩下的像素与
的差,将差序列记录为
,取
与阈值进行
比较,如果
,证明该块是平滑块,通过修改
的LSB位为1进行标记该块属于AHB,类型为
;相反,如果
这篇关于2023混合多比特层-RDHEI Based on the Mixed Multi-Bit Layer Embedding Strategy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)