本文主要是介绍Mapbox Android学习笔记(5)表达式、数据集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
表达式
与Mapbox开发人员体验的其他部分一样,表达式都是关于细粒度控制的。表达式使您能够基于数据的属性动态设置空间数据的样式。它们为您提供许多灵活而强大的操作。您可以同时使用多个特性属性对数据进行样式化,应用条件逻辑,并使用算术或字符串操作操作数据,以便在数据和数据样式之间建立更复杂的关系。
任何布局属性、画图属性或过滤器的值都可以指定为表达式。表达式定义了使用下面描述的操作符计算属性值的公式。
Mapbox GL提供的表达式运算符集包括:
- 对数值执行算术和其他操作的数学运算符
- 用于操作布尔值和作出条件决策的逻辑操作符
- 用于操作字符串的字符串操作符
- 数据操作符,提供对源特性属性的访问
- 相机操作符,提供对定义当前地图视图的参数的访问
表达式表示为JSON数组。表达式数组的第一个元素是一个命名表达式运算符的字符串。例如,“*”或“case”。下一个元素(如果有的话)是表达式的参数。每个参数要么是一个文字值(字符串、数字、布尔值或null),要么是另一个表达式数组。
Popular expressions
虽然有许多表达式可供选择,但您应该首先熟悉以下表达式,这些表达式可能会帮助您实现数据驱动的样式目标:
- get
- match
- switchCase
- equal
- literal
Learning resources
有几个Mapbox资源可以提供更多的指导和示例,帮助理解表达式的概念。
- Javadocs – Android的Mapbox Maps SDK中的表达式Java类提供了解释和代码示例来解释应该如何使用每种表达式方法
- The Mapbox Android demo app – 应用程序的数据驱动样式文件夹中有许多以不同方式使用表达式的示例
- Introductory blog post – 阅读我们的博客文章,这篇文章介绍了Mapbox GL JS发布时的表达式。这篇文章没有与Android平台相关的例子/语法,但是它有助于理解表达式的概念,以及为什么Mapbox首先引入了表达式。
- Style specification – 想知道每个表情的详细信息吗?Mapbox样式规范有它们。
数据集群
通常,一张地图一次可以显示太多的数据。标记相互重叠。这张地图看起来杂乱无章。用户无法快速理解数据应该说什么。
通过使用用于Android的Mapbox Maps SDK的数据驱动样式化功能,完全可以显示集群数据。
将地图上显示的数据量调整到地图的相机缩放级别,可以为用户提供更清晰的UI体验和更少的压倒性位置数据体验。
CircleLayer
使用 CircleLayers 是显示数据集群的两种推荐方法之一。不同的圆形颜色可以表示不同的数据范围。例如,蓝色圆圈可能是包含100多个数据点的集群,红色圆圈包含50多个数据点,绿色圆圈包含10多个数据点。一旦地图被放大到足够大,就只能看到单独的数据点。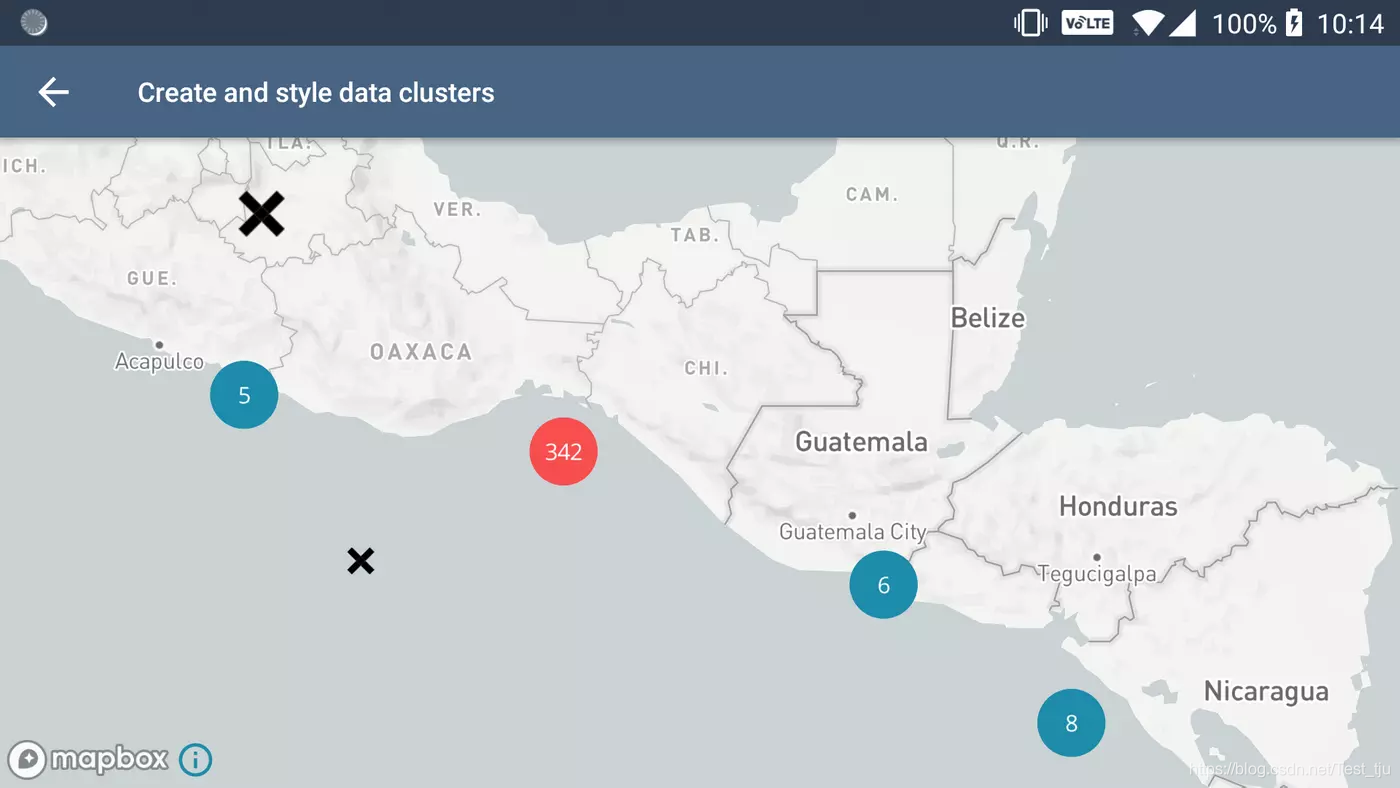
SymbolLayer
符号层稍微复杂一些,但本质上与上面的 CircleLayer 实现相同。根据您使用的符号层图标的形状/大小,您可能必须使用 propertyfactory 的 iconTranslate 方法来确保数据计数符号层编号文本直接排列在符号层集群图标的顶部。不同的图标可以表示不同的数据范围。例如,一个图像可以是包含100多个数据点的集群,第二个图像包含50多个数据点,第三个图像包含10多个数据点。一旦地图被放大到足够大,就只能看到单独的数据点。
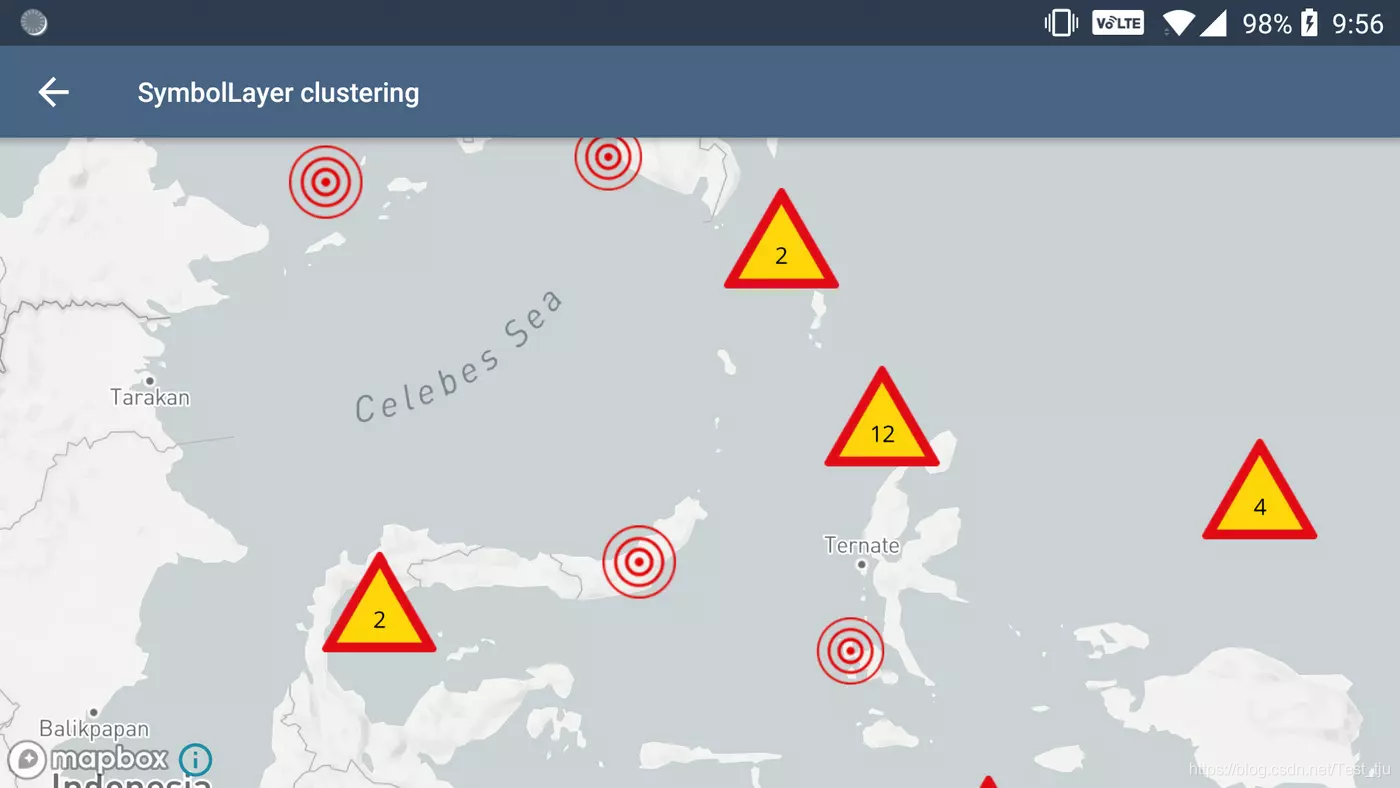
实现方法:
1.使用GeoJSON数据源并将其作为GeoJsonSource添加到Mapbox Map中。
try {mapboxMap.getStyle().addSource(new GeoJsonSource("GEOJSON_SOURCE_ID",new URL("URL_POINTING_TO_GEOJSON_FILE"),new GeoJsonOptions().withCluster(true).withClusterMaxZoom(MAX_ZOOM).withClusterRadius(DESIRED_CLUSTER_RADIUS)));
} catch (MalformedURLException malformedUrlException) {Log.e(TAG, "Check the URL " + malformedUrlException.getMessage());
}
2.创建一个符号层,其中的图标表示当点没有聚集时的单个数据点。这些图标只有当地图的摄像头离地图足够近时才会显示。记住,地图的缩放值越高,相机的缩放就越大。缩放级别12比缩放值4更接近地图。
3.为各种数据范围创建尽可能多的额外符号层或循环层。您可能用红色的圆圈表示具有10-30个数据点的数据集群,然后用蓝色圆圈表示具有50个或更多数据点的数据集群。数据驱动的样式和表达式过滤将决定哪些集群层显示在哪个缩放级别。
4.为隐藏的数据量文本创建一个符号层。也就是说,出现的数字告诉用户还有多少数据点隐藏在集群图标/圆圈后面,如果将地图放大,就可以看到这些数据点。不要忘记使用运行时样式来调整文本大小、文本颜色和其他文本属性:
SymbolLayer count = new SymbolLayer("SYMBOL_LAYER_COUNT_LAYER_ID", "GEOJSON_SOURCE_ID");count.setProperties(textField(Expression.toString(get("point_count"))),textSize(TEXT_SIZE),textColor(TEXT_COLOR),textIgnorePlacement(true),textAllowOverlap(true));
mapboxMap.getStyle().addLayer(count);
这篇关于Mapbox Android学习笔记(5)表达式、数据集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





