本文主要是介绍用Yarn你还能做的五件事,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在有很多javascript的包管理器:land,bower,component和volo还有很多,在写这篇文章时最流行的javascript包管理器是npm,npm客户端提供了成千上万的在npm中注册过的代码库。就在最近,Facebook推出了一款新的javascript包管理器Yarn,并声称比npm更快,更值得信赖,并且更安全,在这篇文章里,你可以学到五件可以做的事情。
Yarn是一款由Facebook为javascript开发的新的包管理器,它为那些在他们的项目中使用了javascript的开发者提供了更快,更可靠,更安全的使用体验。
1.离线工作
Yarn给你提供了在离线模式下工作的的能力,如果你之前安装过一个包,你可以在没有网络的情况下重新安装它,一个经典的例子如下:
当有网络的时候,我用Yarn安装了两个包像这样

用yarn初始化创建一个package.json文件

用yarn安装express和jsonwebtoken

安装完成
在安装完成后,把我的orijin目录下的包删除掉并且断开网络连接,我又运行yarn

Yarn在离线的情况下安装了包
厉害了!!在不超过两秒的情况下所有的包都被重新安装上了,显然Yarn把下载的所有的包缓存到硬盘上,所以重复安装的时候不需要网络。通过并行操作,yarn最大化的进行资源利用,所以它的安装时间要快很多。
2.从多种渠道中安装
Yarn可以从多种不同的渠道安装包,例如npm,bower,你的git仓库,甚至你的本地文件。
通常,它会为你的包扫描npm像下面这样
yarn add <pkg-name>从一个远程的打包文件中安装包像这样
yarn add <https://thatproject.code/package.tgz>从你的本地文件中安装包
yarn add file:/path/to/local/folder这对那些经常发布javascript包的开发者来说是很有用的,在发布之前你可以使用这个功能来测试你的包。
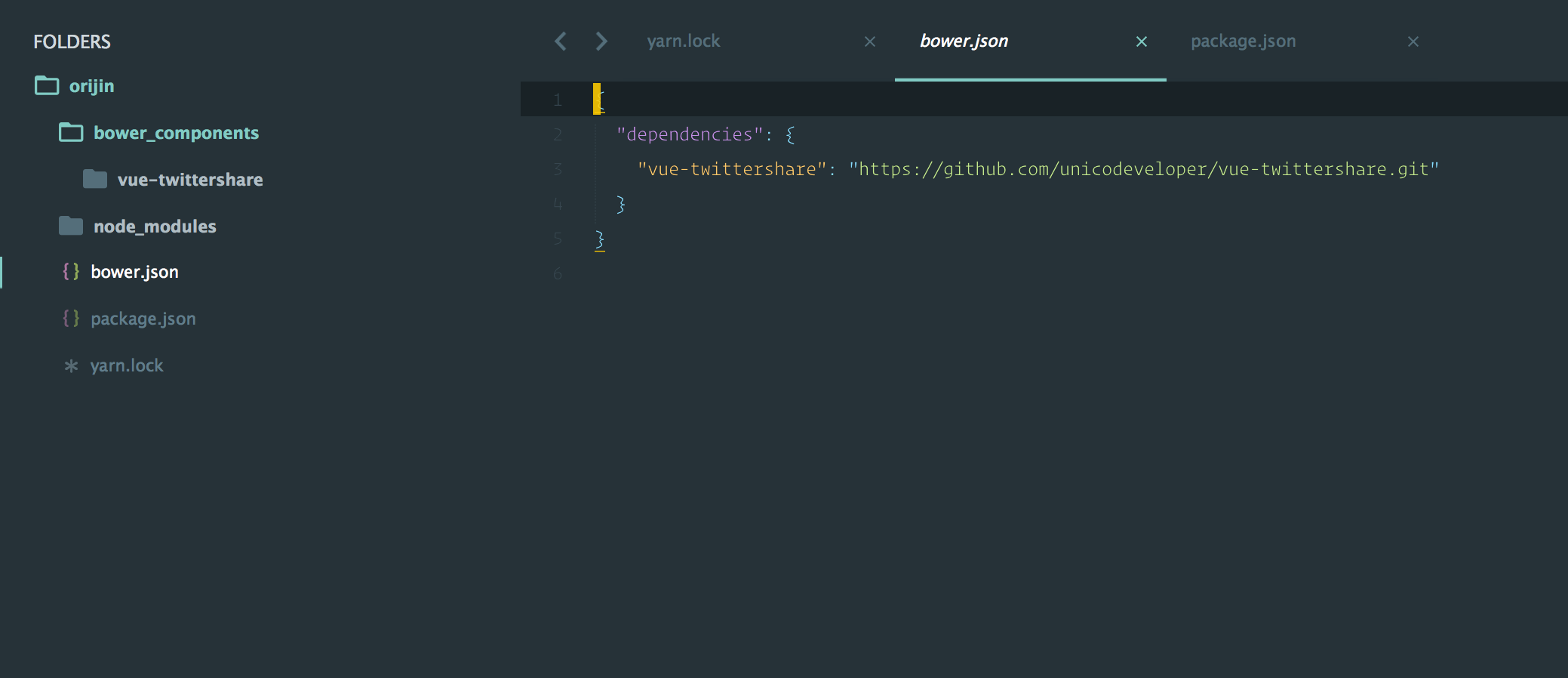
从git仓库中安装包
yarn add <git remote-url>
从github中安装
3.快速的获取到包
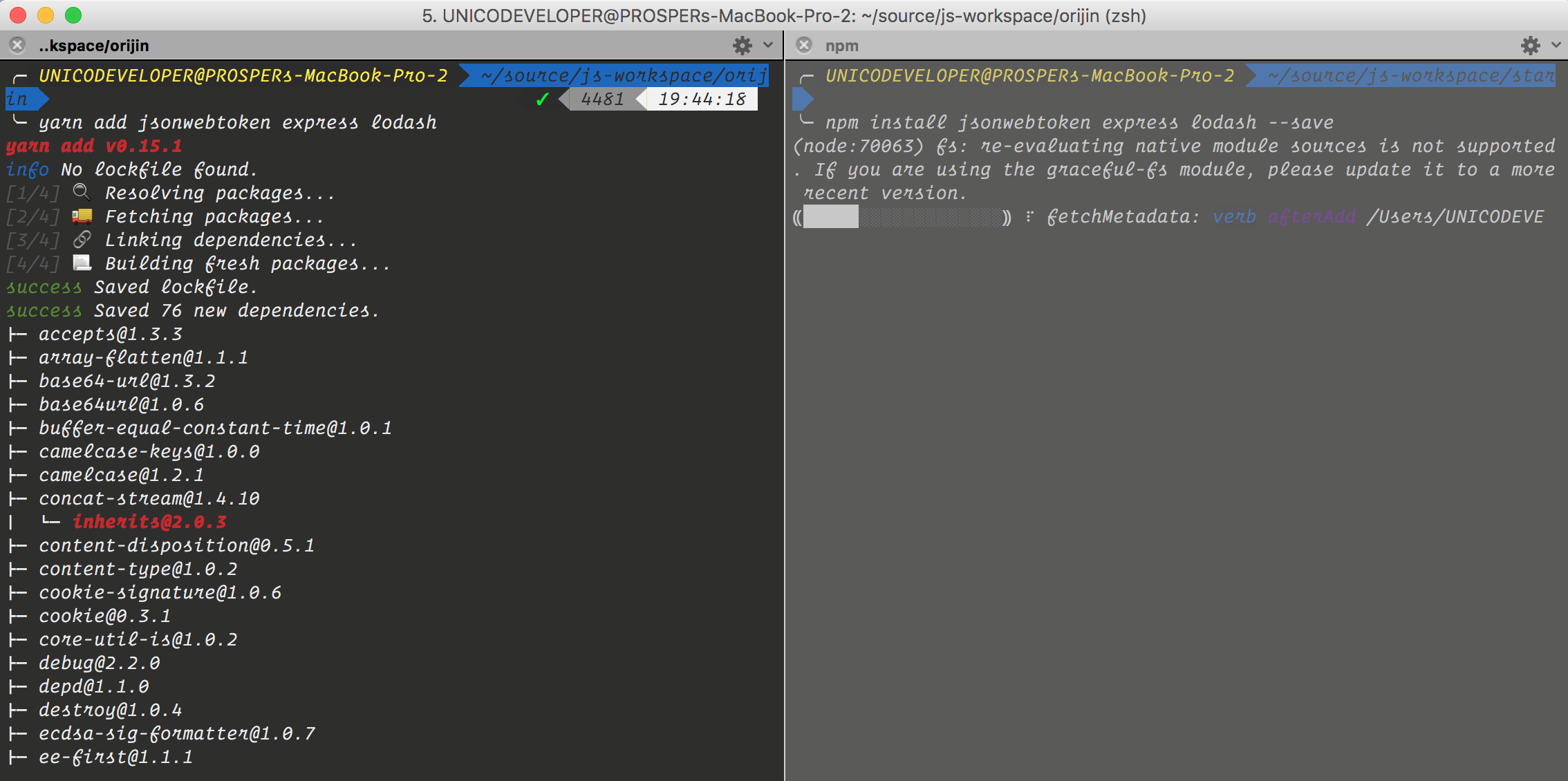
如果你之前使用过npm,当你运行npm install 后,你可能去看一场电影再回来检查一下是否把包安装成功了。使用yarn,安装时间会从等待几分钟变成几秒钟。
Yarn高效的将请求序列化来尽可能的利用网络,开始时它为请求注册信息并且递归的查找每个依赖,接下来,它在全部缓存目录下查找这个包是否之前被安装过,如果之前没有安装过,Yarn就会获取到包并且把它放到缓存目录下使它能够离线工作,并且以后不需要再次下载了。
在安装过程中,Yarn是并行运行的,这样可以使安装速度更快,我刚刚安装了三个包,jsonwebtoken,express和lodash,分别使用npm和yarn,在yarn安装完成后,npm还在安装。。。
4.自动锁定包的版本
Npm有个功能叫做shrinkwrap,为了在使用时锁定包的依赖,使用shinkwrap的困难在于开发者需要 手动的运行npm shinkwrap来生成npm-shinkwrap.json文件, 开发者也是人啊。。
使用yarn那就完全不一样了,在安装期间,yarn.lock文件会被自动生成,这和PHP开发者熟悉的composer.lock文件很像。yarn.lock文件准确的锁定包的版本和包所需要的依赖。有了这个文件,你可以确信你的项目组里的每个成员的都安装正确的包,并且可以在没有任何bug的情况下重新部署。
5.在机器上用相同的方式安装依赖
开发者A和B在使用npm在安装相同依赖文件的时候可能会得到不同的node_modules目录文件。npm使用不确定的方法来安装包的依赖,这也是很容易产生bug的原因。
在使用yarn时,上锁文件的存在和安装算法保证了安装的依赖关系产生额外的完全相同的文件和文件夹结构通过开发机器和将应用程序部署到生产。
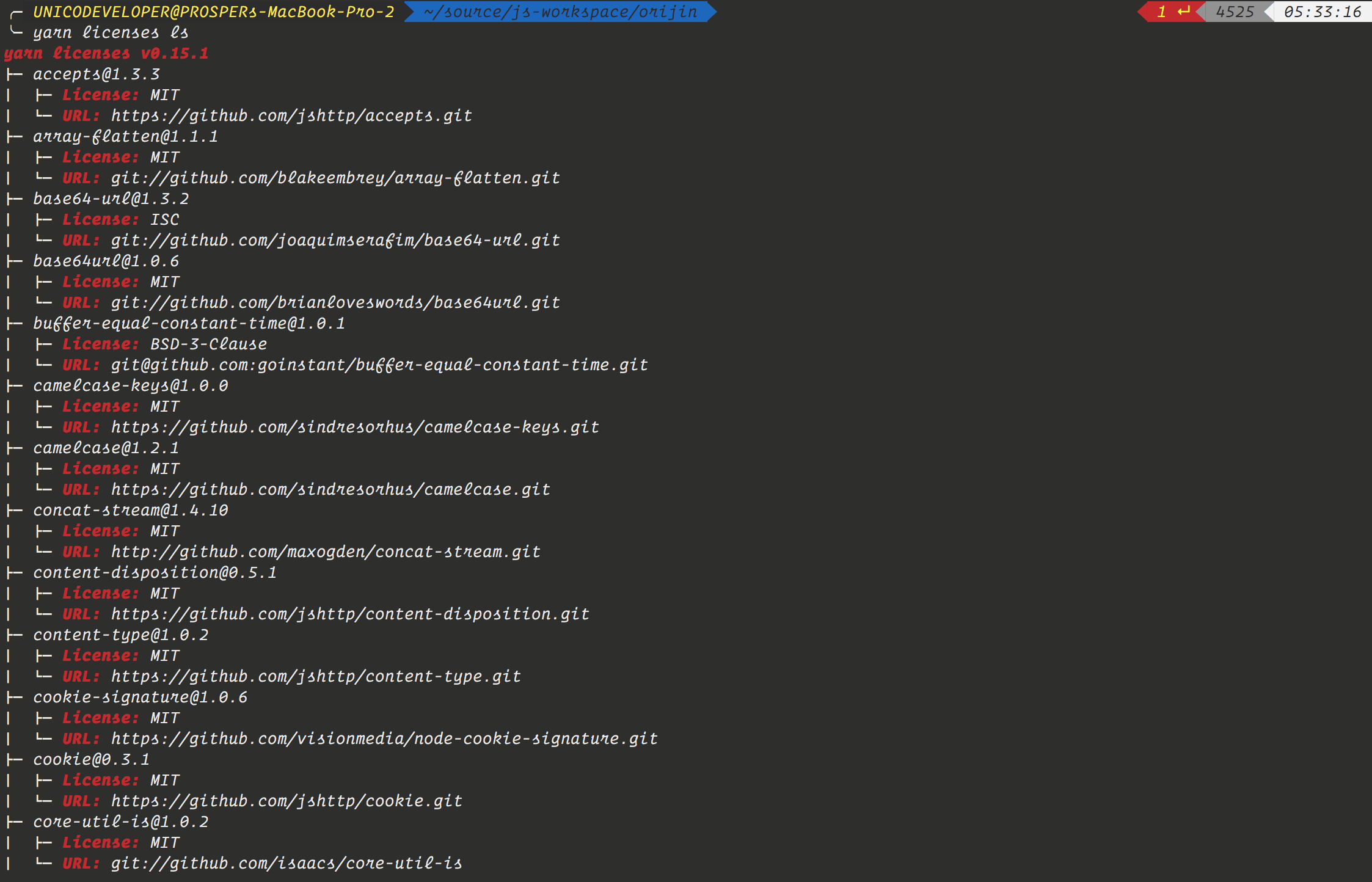
在你的根目录下运行yarn licenses ls可以查看许可文件类型
总结
Yarn在它的初始阶段,就在安装速度和保证安全性方面带来了巨大的进步。yarn将来会成为javascript开发者最喜欢的包管理器吗,让我们期待吧!!!
这篇关于用Yarn你还能做的五件事的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








