本文主要是介绍每周一算法:迭代加深A*,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目链接
AcWing 180. 排书
题目描述
给定 n n n 本书,编号为 1 ∼ n 1\sim n 1∼n。
在初始状态下,书是任意排列的。
在每一次操作中,可以抽取其中连续的一段,再把这段插入到其他某个位置。
我们的目标状态是把书按照 1 ∼ n 1\sim n 1∼n 的顺序依次排列。
求最少需要多少次操作。
输入格式
第一行包含整数 T T T,表示共有 T T T组测试数据。
每组数据包含两行,第一行为整数 n n n,表示书的数量。
第二行为 n n n个整数,表示 1 ∼ n 1\sim n 1∼n 的一种任意排列。
同行数之间用空格隔开。
输出格式
每组数据输出一个最少操作次数。
如果最少操作次数大于或等于 5 5 5次,则输出5 or more。
每个结果占一行。
数据范围
1 ≤ n ≤ 15 1≤n≤15 1≤n≤15
输入样例
3
6
1 3 4 6 2 5
5
5 4 3 2 1
10
6 8 5 3 4 7 2 9 1 10
输出样例
2
3
5 or more
算法思想
根据题目描述,需要对 1 ∼ n 1\sim n 1∼n的一个排列,进行若干次操作,在每一次操作中,可以抽取序列中连续的一段,再把这段插入到其他某个位置。问最少经过几次操作,可以将序列变为按照 1 ∼ n 1\sim n 1∼n 的顺序依次排列。
先考虑每一次操作的决策数量:
- 当从序列中抽取长度为 i i i的一段时,有 n − i + 1 n-i+1 n−i+1种选择。例如:对于长度 n = 6 n=6 n=6的序列中,抽取长度为 i = 3 i=3 i=3的连续一段,有 4 4 4种选择,如下图所示

- 对于每种抽法,有 n − i n-i n−i种放法,即将长度为 i i i的一段插入其它 n − i n-i n−i个空中。例如:
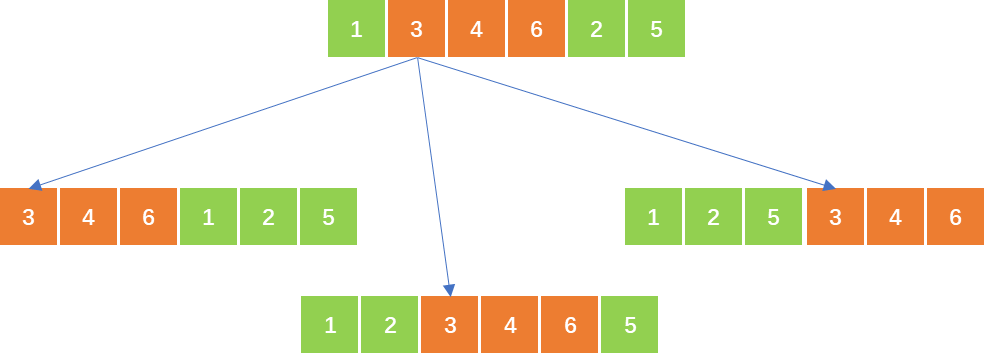
那么每一步状态数量为 ( n − i ) × ( n − i + 1 ) (n-i)\times(n-i+1) (n−i)×(n−i+1),但将某一段向前移动,等价于将跳过的那段向后移动,因此每种移动方式被计算了两次,还要除以 2 2 2。所以状态空间的大小为 ∑ i = 1 n ( n − i ) × ( n − i + 1 ) / 2 ≤ ( 15 × 14 + 14 × 13 + . . . + 2 × 1 ) / 2 = 560 \sum_{i=1}^n(n-i)\times(n-i+1)/2\le(15\times14+14\times13+...+2\times1)/2=560 ∑i=1n(n−i)×(n−i+1)/2≤(15×14+14×13+...+2×1)/2=560。
考虑在 4 4 4步内找到答案,最多有 56 0 4 560^4 5604个状态,暴力搜索会超时。可以使用双向广搜 或者迭代加深A*(IDA* )来优化。
迭代加深A*
在A*算法算法中,将估价函数与优先队列BFS结合,提高了搜索效率。那么把估价函数与迭代加深的DFS结合就是迭代加深 A* \text{A*} A*( IDA* \text{IDA*} IDA*)。
迭代加深 A* \text{A*} A*要限定一个深度,在不超过该深度的前提下执行DFS,若找不到解,就扩大深度限制,重新进行搜索;除此之外,还要设计一个估价函数,估算从每个状态到目标状态需要的“步数”。与 A* \text{A*} A*算法一样,估价函数需要遵守“预计值不大于未来实际步数”的准则。
基本思想是以迭代加深DFS的搜索框架为基础,把原来简单的深度限制加强为:若当前深度+未来估计步数>深度限制,则立即从当前分支回溯。
估价函数
IDA* \text{IDA*} IDA*的算法的关键在于设计估价函数,那么本题的估价函数如何设计?考虑对于目标状态,第 i i i本书后边应该是第 i + 1 i+1 i+1本书,那么认为 i + 1 i+1 i+1是 i i i的正确后继。
对于任意状态,考虑整个排列中错误的后继总数,将其记为tot,可以发现每次操作至多更改 3 3 3本数的后继,例如,将 346 346 346移动到 2 2 2的后面, 1 、 2 、 6 1、2、6 1、2、6的后继被更改,如下图所示:
也就是说,在最理想的情况下,每次操作都能把 3 3 3个错误后继全部该对,那么消除所有错误后继的操作次数也至少需要 ⌈ t o t 3 ⌉ \lceil\frac{tot}{3}\rceil ⌈3tot⌉次。
因此,可以把一个状态state的估价函数设计为 h ( s t a t e ) = ⌈ t o t 3 ⌉ h(state)=\lceil\frac{tot}{3}\rceil h(state)=⌈3tot⌉,其中tot表示在当前状态state下书的错误后继总数。
算法实现
基本思想是使用迭代加深的方法,从 1 ∼ 4 1\sim4 1∼4依次限制搜索深度,然后从起始状态出发进行DFS。对于当前状态:
- 如果若当前步数+未来估计步数>深度限制,则搜索结束返回无解。
- 如果到达最终状态,搜索结束返回有解。
- 枚举要抽连续的一段的左右位置 [ L , R ] [L, R] [L,R],以及插入位置 i i i,将 [ L , R ] [L, R] [L,R]这一段插入到 i i i位置后
- 继续搜索下一阶段的状态
代码实现
#include <bits/stdc++.h>
using namespace std;
const int N = 20;
int n, q[N], b[5][N]; //备份数组
int h() //估价函数
{int tot = 0; //统计错误后继总数for(int i = 0; i + 1 < n; i ++)if(q[i] + 1 != q[i + 1]) tot ++;return (tot + 2) / 3; //总数÷3向上取整
}
bool check()
{for(int i = 0; i < n; i ++)if(q[i] != i + 1) return false;return true;
}
//当前步数k,限制深度depth
bool dfs(int k, int depth)
{if(k + h() > depth) return false; //当前步数+估计步数超过限制if(check()) return true;//枚举抽取的左右两端和插入位置for(int L = 0; L < n; L ++)for(int R = L; R < n; R ++)for(int i = R + 1; i < n; i ++) //注意只需要枚举后面的插入位置即可{memcpy(b[k], q, sizeof q); //备份,方便恢复现场int x, y;//将[R+1,i]位置上的数向前移动for(x = R + 1, y = L; x <= i; x ++, y ++) q[y] = b[k][x];//将[L,R]位置上的数,向后移动for(x = L; x <= R; x ++, y ++) q[y] = b[k][x];if(dfs(k + 1, depth)) return true;memcpy(q, b[k], sizeof q); //备份,方便恢复现场}return false;
}
int main()
{int T;cin >> T;while(T --){cin >> n;for(int i = 0; i < n; i ++) cin >> q[i];int depth = 0;while(depth < 5 && !dfs(0, depth)) depth ++;if(depth >= 5) puts("5 or more");else cout << depth << '\n';}return 0;
}
这篇关于每周一算法:迭代加深A*的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








