本文主要是介绍科技部发布 164 家独角兽企业:11 家云服务/大数据,9 家 AI/智能硬件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天上午, 科技部火炬中心、中关村管委会、长城战略咨询、中关村银行联合主办“2017中国独角兽企业发展报告”发布会。

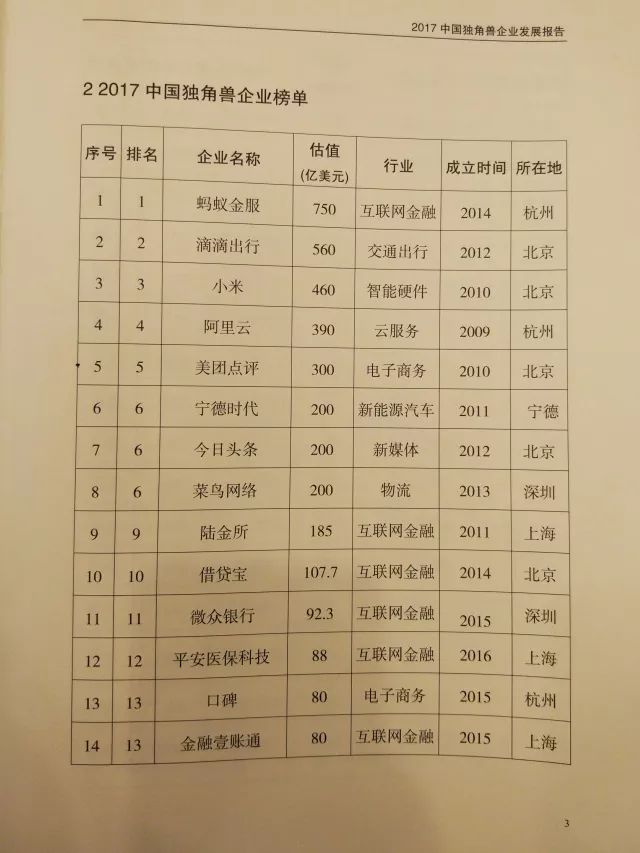
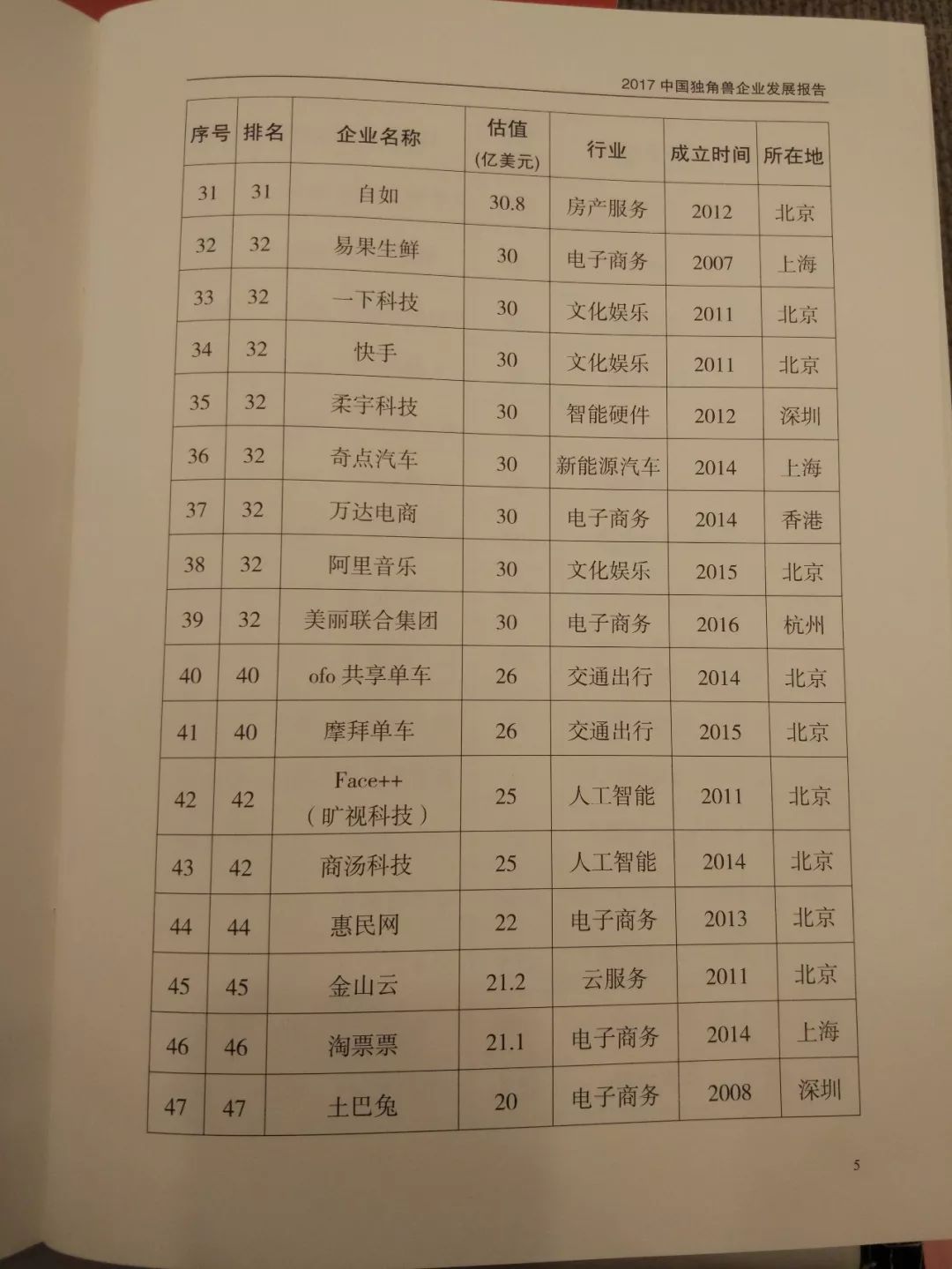
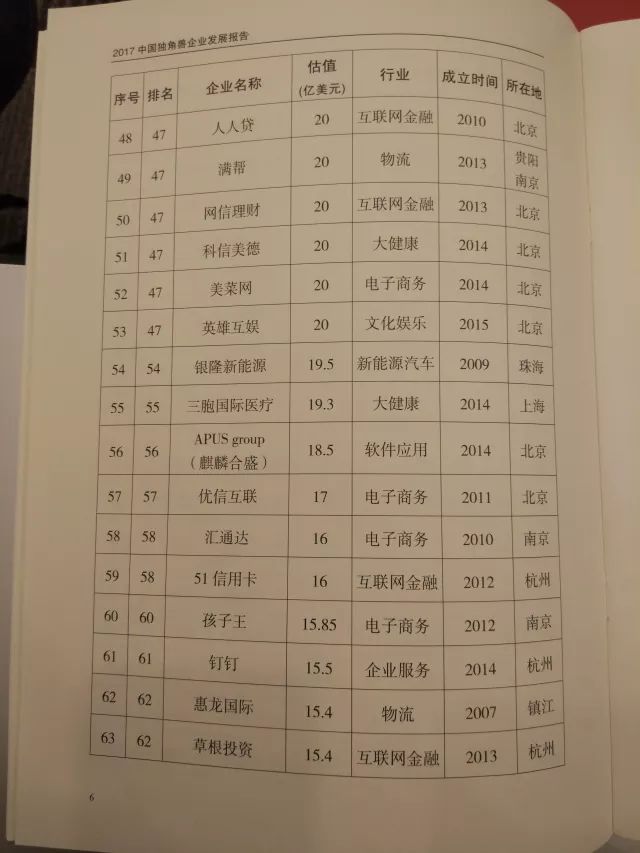
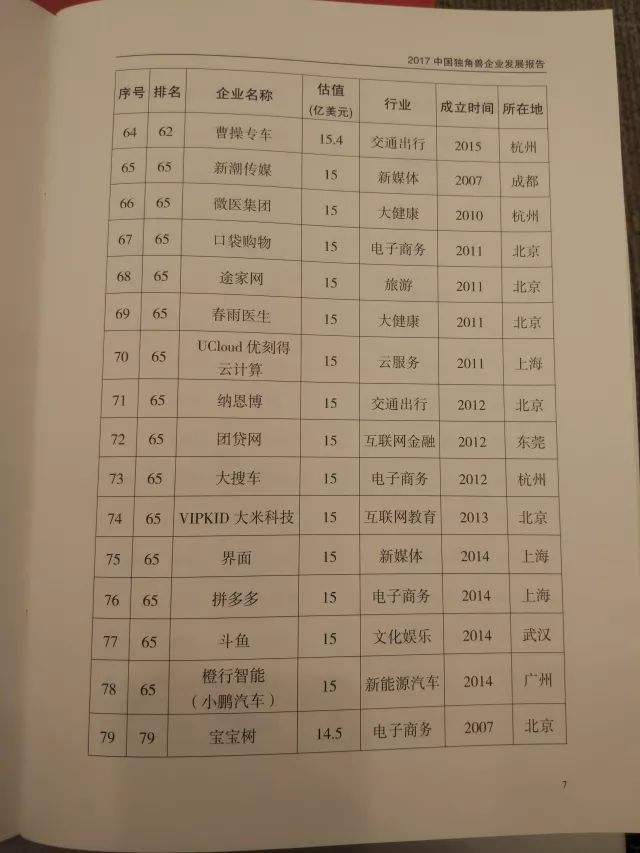
《2017中国独角兽企业发展报告》显示: 2017年中国独角兽企业共164家,新晋62家,总估值6284亿美元。
入榜云服务企业有:
阿里云,估值:390亿美元
腾讯云,估值:33亿美元
金山云,估值:21.2亿美元
UCloud,估值:15亿美元
百望云,估值:11.2亿美元
七牛云,估值:10亿美元
腾云天下(大数据),估值10亿美元
Geo集奥聚合(大数据),估值10亿美元
QingCloud,估值10亿美元
同盾科技(大数据),估值10亿美元
华云数据,估值10亿美元
AI企业有:
小米(智能硬件),460亿美元
优必选科技,估值:40亿美元
柔宇科技,估值:30亿美元
Face++(旷视科技),估值25亿美元
商汤科技,估值25亿美元
依图科技,估值10亿美元
出门问问,估值10亿美元
智米科技,估值10亿美元
寒武纪科技,估值10亿美元
榜单如下——





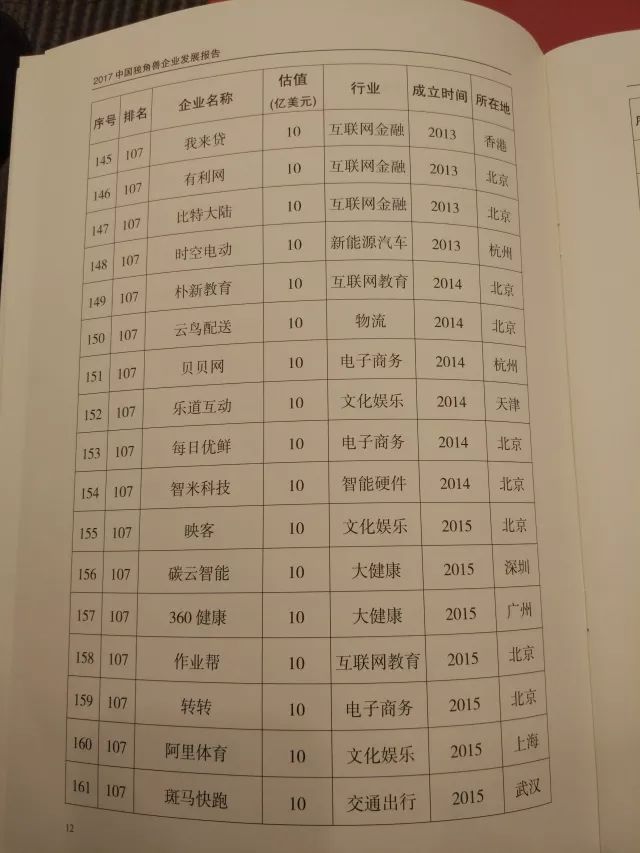

报告显示
2017年因上市而毕业的独角兽有9家:
众安保险
IReader掌阅科技
趣分期
易鑫金融
融360
阅文集团
拍拍贷
分期乐
奇思科技
其中互联网金融独角兽上市6家,占比较大。
本榜单中确定的中国独角兽企业标准是:
①在中国境内注册的,具有法人资格的企业;
②成立时间不超过十年(2007年及之后成立);
③获得过私募投资,且尚未上市;
④符合条件①②③,且企业估值超过(含)10亿美元的称为独角兽;
⑤符合条件①②③,且企业估值超过(含)100亿美元的称为超级独角兽。(估值以2017年12月31日前最新一轮融资为依据)
经由企业自主申报、公开数据搜集、重点高新区推荐、长城战略咨询数据库筛选、第三方机构数据支撑等方式汇总备选企业数据,经审核筛选出164家符合标准的独角兽企业。

文章来源:云头条

这篇关于科技部发布 164 家独角兽企业:11 家云服务/大数据,9 家 AI/智能硬件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







