本文主要是介绍Hbase shell终端操作之表数据操作1(Hbase对表数据操作),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hbase shell终端操作之表数据操作1(Hbase对表数据操作)
【注】本课程文章为笔者2016年期间为北京某高校硕士班编写的Hbase实验课程,现分享至此,供大家学习。
【实验目的】
- 学会向表中添加记录
- 学会添加记录时动态添加列
- 学会查看一条记录
- 学会查看表中的记录总数
- 学会删除记录
【实验demo】
- 实验环境介绍
- 演示简要过程
- 演示实验结果
【实验原理】
Hbase shell作为Hbase数据的客户端,可以连接hbase,通过命令行方式和hbase进行交互。
Hbase shell是一个封装了Java客户端API的JRuby应用软件。
在终端中执行hbase shell命令启动Shell,即可操作hbase。
Shell可以支持命令自动补全和命令文档内联访问。
【实验环境】
本次环境是:centos6.5+jdk1.7.0_79+hbase0.96+hbase shell
host01是计算机名称对应ip地址为 192.168.0.131,可以在/etc/hosts文件中查看映射关系
【实验步骤】
一、项目准备阶段
-
- 启动hbase。进入$HBASE/bin/目录,执行命令./start-hbase.sh。如下图1所示。
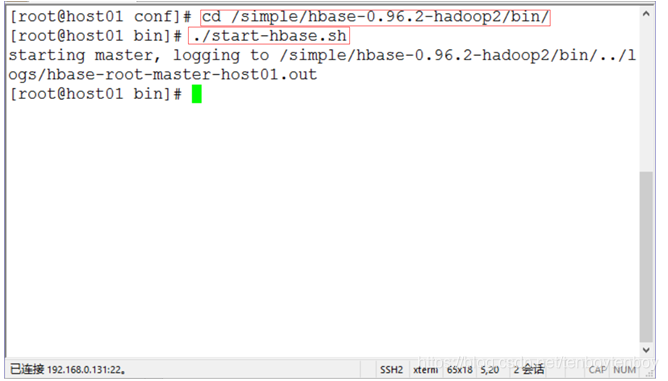
图1
-
- 启动shell模式。进入$HBASE/bin目录,执行./hbase shell命令。如下图2所示。

图2
-
- 创在测试表。在命令行中输入create 'people', {NAME =>'info', VERSIONS=>3}, {NAME=>'data', VERSIONS=>1}创建people表。如下图3所示。

图3
二、向表中添加记录
-
- 查看插入操作帮助。在命令行中执行执行help 'put',可以查看相关帮助文档。如下图4所示

图4
-
- 向第一个列族的第一个列插入一条记录。
| 说明: 插入一行数据到列族info的列name中。在命令行中执行put 'people' , 'rk0001', 'info:name', 'MaYun'。其中,rk0001为行健值,MaYun为列族info中字段name的值。 |
如下图5所示。
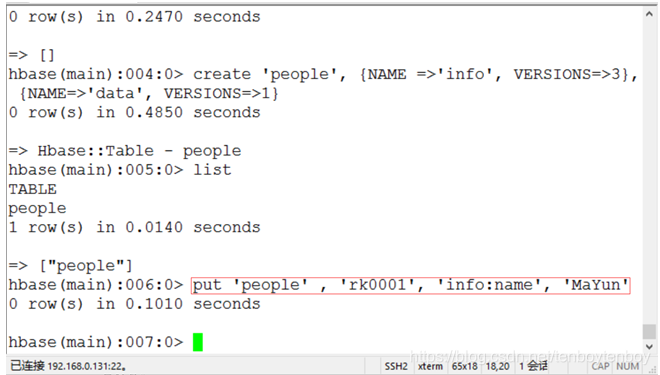
图5
-
- 向第一个列族的第二个列插入一条记录。
| 说明: 插入一行数据到列族info的列gender中。在命令行中执行put 'people' , 'rk0001', 'info:gender', 'male'。其中,rk0001为行健值,male为列族info中字段gender的值。插入该记录之后,列族info下面将会含有两个列name和gender |
如下图6所示。

图6
-
- 向第二个列族的第一个列插入一条记录。
| 说明: 插入一行数据到列族data的列myurl中。在命令行中执行put 'people' , 'rk0001', 'data:myurl', 'www.yun.alibaba.com/myURL'。其中,rk0001为行健值,www.yun.alibaba.com/myURL为列族data中字段myurl的值。 |
如下图7所示。

图7
-
- 插入第二行数据。
| 说明: Hbase中用rowkey来判断数据属于哪一行,上面数据的rowkey为rk0001,下面将用rk0002做为rowkey来插入第二列数据。 插入一行数据到列族info的列name中。在命令行中执行put 'people' , 'rk0002', 'info:name', 'LiuChangle'。其中,rk0002为行健值,LiuChangle为列族info中字段name的值。 |
如下图8所示。
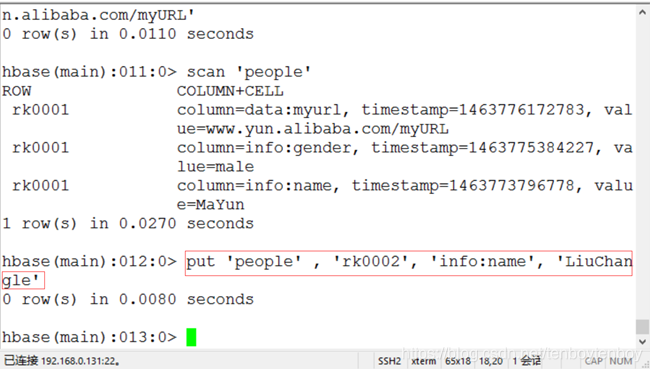
图8
三、查看表中一条记录
4.1 已知rowkey值为rk0001,执行语句get ‘people’, ‘rk0001’,查询该rowkey对应的一条记录。如下图9所示。
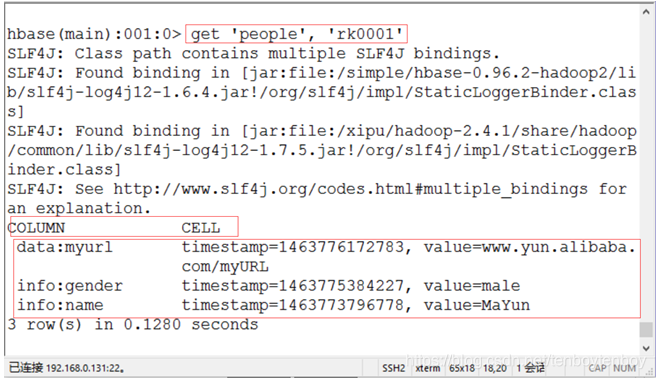
图9
四、查看表中的记录总数
4.1 查询表people中的记录总数。执行语句count ‘people’返回记录数。如下图10所示。
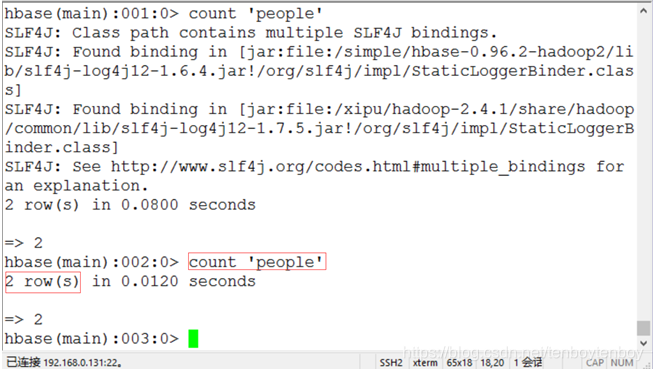
图10
五、删除表中的记录
5.1 删除数据之前,首先插入测试数据。如下图11所示。
| 测试数据如下: put 'people' , 'rk0003', 'info:name', 'MaYun2' put 'people' , 'rk0003', 'info:gender', 'male' put 'people' , 'rk0003', 'data:myurl', 'www.yun.alibaba.com/myURL2' |
 图11
图11
5.2 查询上面插入的数据。执行命令get 'people', 'rk0003'。如下图12所示。
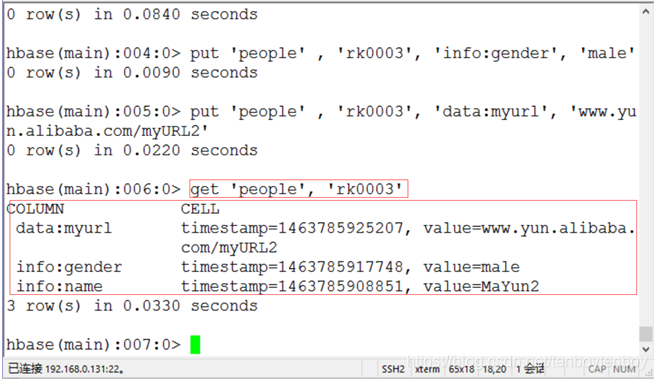
图12
5.3 删除rowkey为rk0003的值的记录。执行命令deleteall 'people','rk0003'。如下图13所示。
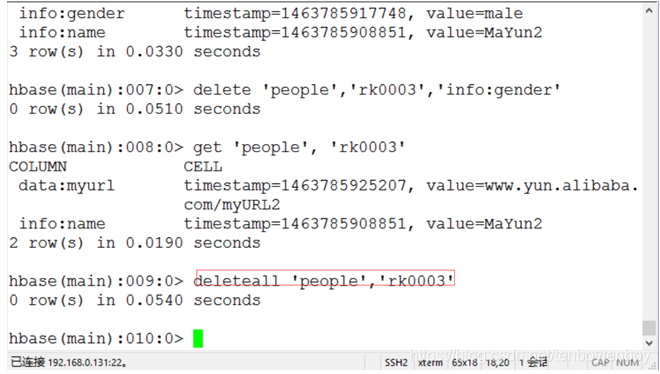
图13
执行命令get 'people', 'rk0003'查看结果,发现记录数为0,说明删除成功。如下图14所示。
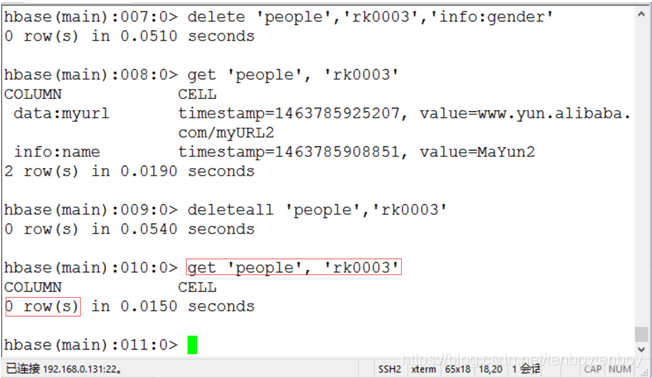
图14
【实验思考】
1.思考hbase向表中添加记录时动态添加列的意义,关系型数据库是否也可以动态添加列?
题目一下面哪个语句是查看people表中的rowkey为rk0001的记录 D
A :scan ‘people’,‘rk0001’
B :help ‘people’,‘rk0001’
C :list‘people’,‘rk0001’
D :get‘people’,‘rk0001’
这篇关于Hbase shell终端操作之表数据操作1(Hbase对表数据操作)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






