本文主要是介绍DBO优化LSBoost回归预测(matlab代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DBO-LSBoost回归预测matlab代码
蜣螂优化算法(Dung Beetle Optimizer, DBO)是一种新型的群智能优化算法,在2022年底提出,主要是受蜣螂的的滚球、跳舞、觅食、偷窃和繁殖行为的启发。
数据为Excel股票预测数据。
数据集划分为训练集、验证集、测试集,比例为8:1:1
模块化结构:代码按照功能模块进行划分,清晰地分为数据准备、参数设置、算法处理块和结果展示等部分,提高了代码的可读性和可维护性。
数据处理流程清晰:对数据进行了标准化处理,包括Zscore标准化,将数据分为训练集、验证集和测试集,有助于保证模型训练的准确性和可靠性。
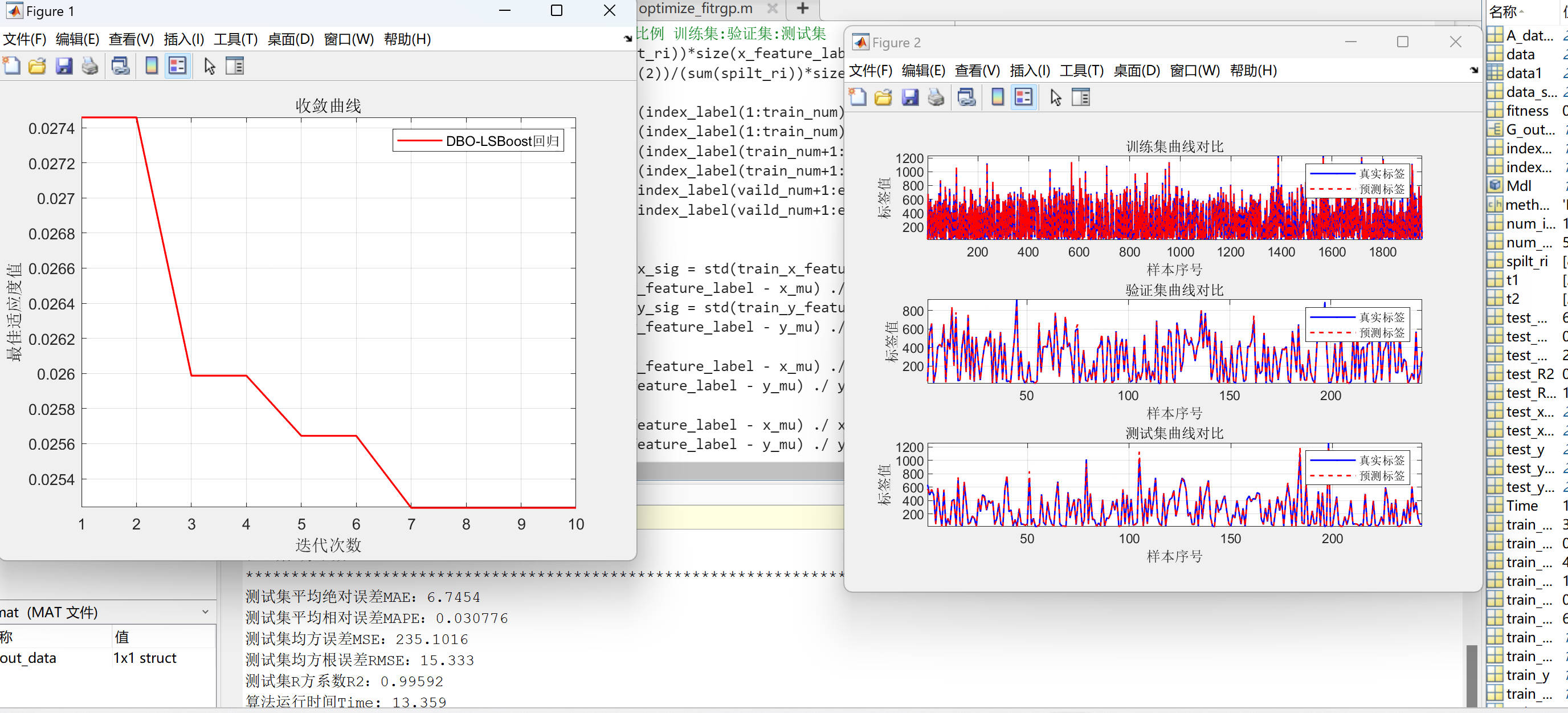
结果可视化:通过绘制DBO寻优过程收敛曲线、训练集、验证集和测试集的真实标签与预测标签的曲线对比图,直观地展示了模型的预测效果,便于用户理解算法和模型的性能。
同时输出多个评价指标:
平均绝对误差(MAE)
平均相对误差(MAPE)
均方误差(MSE)
均方根误差(RMSE)
R方系数(R2)
代码有中文介绍。
代码能正常运行时不负责答疑!
代码运行结果如下:


部分代码如下:
% 清除命令窗口、工作区数据、图形窗口、警告
clc;
clear;
close all;
warning off;
load('data.mat')
data1 = readtable('股票价格.xlsx'); % 读取数据
data2=data1(:,2:end);
data=table2array(data1(:,2:end));
A_data1=data;
data_select=A_data1;
%% 数据划分
x_feature_label=data_select(:,1:end-1); %x特征
y_feature_label=data_select(:,end); %y标签
index_label1=1:(size(x_feature_label,1));
index_label=G_out_data.spilt_label_data; % 数据索引
if isempty(index_label) index_label=index_label1;
end
spilt_ri=G_out_data.spilt_rio; %划分比例 训练集:验证集:测试集
train_num=round(spilt_ri(1)/(sum(spilt_ri))*size(x_feature_label,1)); %训练集个数
vaild_num=round((spilt_ri(1)+spilt_ri(2))/(sum(spilt_ri))*size(x_feature_label,1)); %验证集个数
%训练集,验证集,测试集
train_x_feature_label=x_feature_label(index_label(1:train_num),:);
train_y_feature_label=y_feature_label(index_label(1:train_num),:);
vaild_x_feature_label=x_feature_label(index_label(train_num+1:vaild_num),:);
vaild_y_feature_label=y_feature_label(index_label(train_num+1:vaild_num),:);
test_x_feature_label=x_feature_label(index_label(vaild_num+1:end),:);
test_y_feature_label=y_feature_label(index_label(vaild_num+1:end),:);这篇关于DBO优化LSBoost回归预测(matlab代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





