本文主要是介绍superset 二开增加 flink 数据源连接通过flink sql 查询数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
superset 目前还不支持 flink 的数据源连接,目前我们公司在探索使用数据湖那一套东西:
- 使用 flink 作为计算引擎
- 使用 paimon + oss对象存储对接 flink 作为底层存储
- 使用 superset 通过 flink gateway 查询 paimon 数据形成报表
增加flink数据源
界面配置
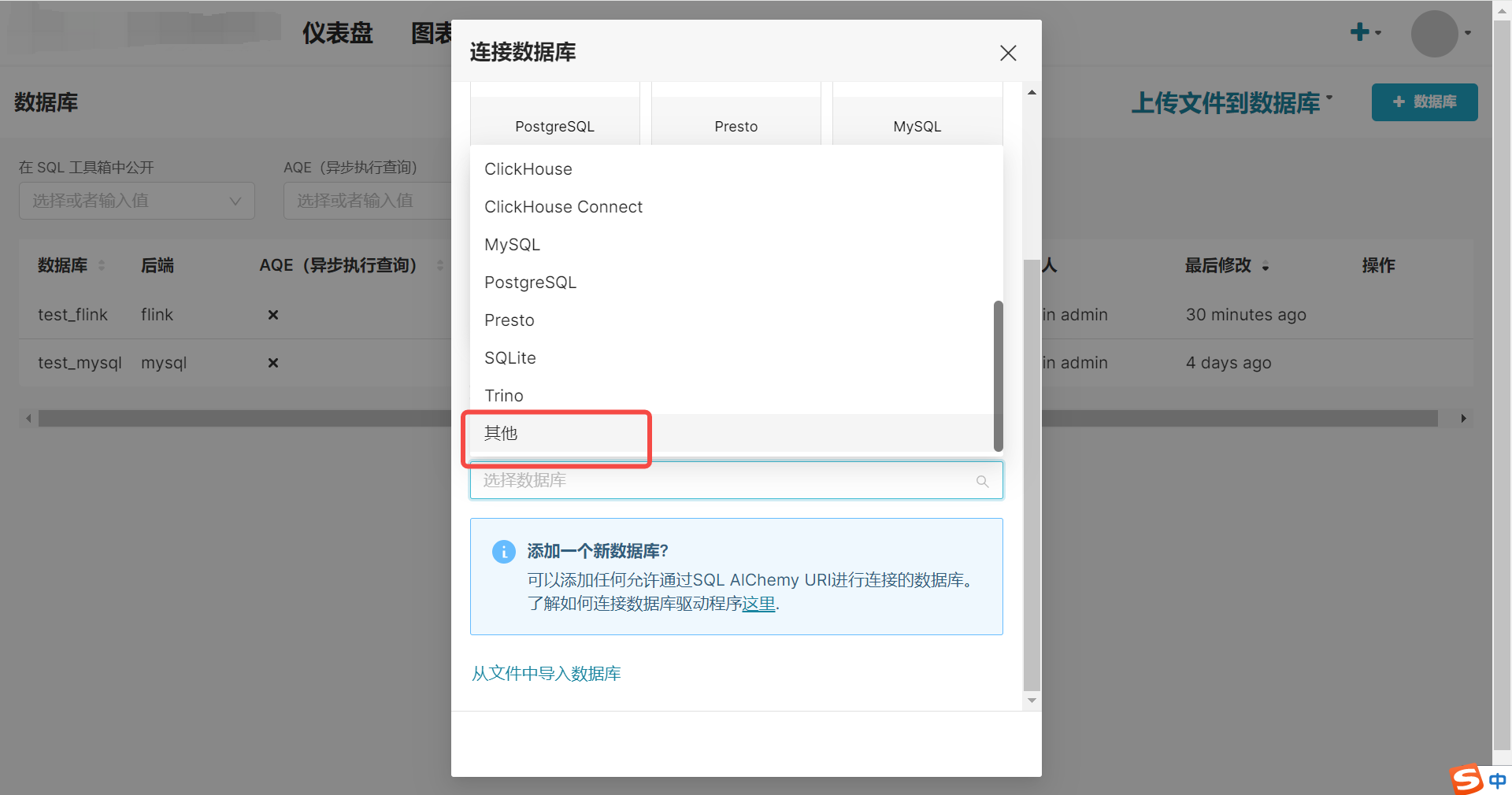
我们通过添加其他数据源连接来增加 flink 的数据源连接。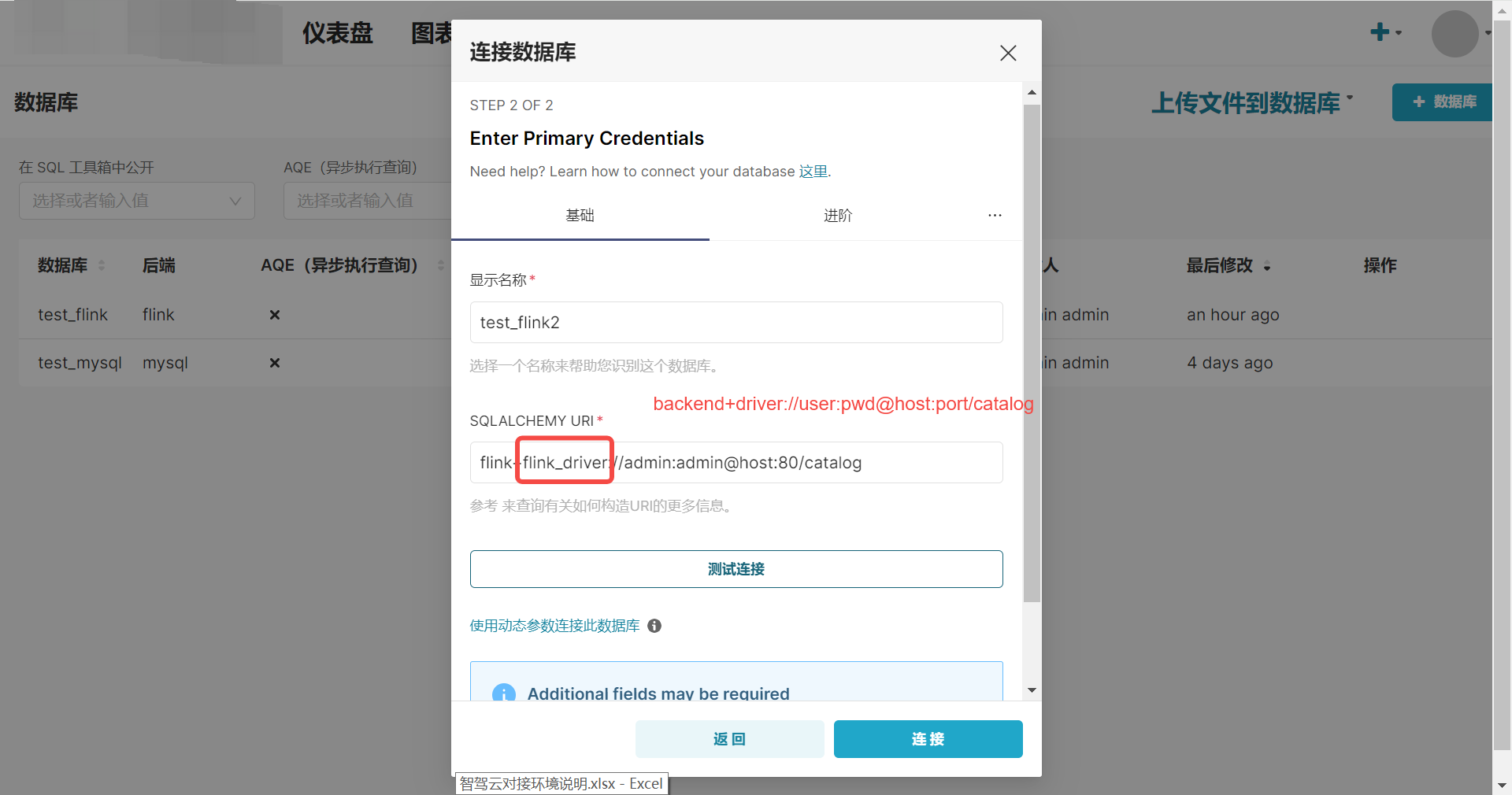
在填写 SQL_ALCHEMY_URI 的时候这里的 driver需要注意,后边在二开代码的时候,需要根据这个 driver 识别到不同的 engine。
我们是通过 flink gateway 提供的 HTTP 接口来进行 flink sql 查询的,所以这里的 host, port 就是 flink gateway 的地址。
在添加连接的时候必须指定 catalog,不然在 superset 的 sqllab 左下侧就没法显示对应的 databases 和 tables。
如果我们的连接需要一些额外参数,可以通过右侧的进阶添加一些额外的参数,在业务代码里使用: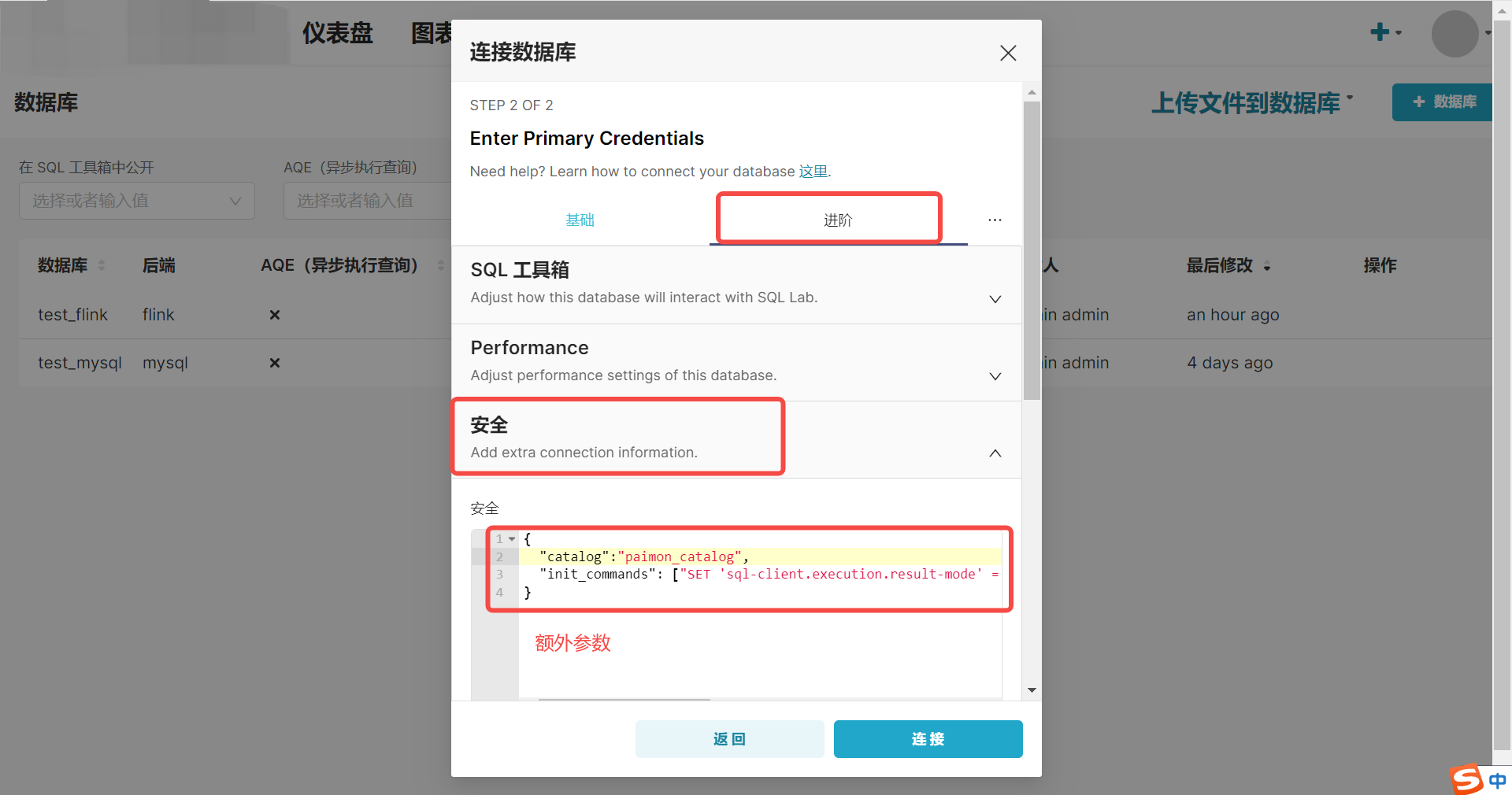
我这里就指定了该连接使用的 catalog, 以及每次执行 sqllab 查询的时候初始化的一些命令。
代码开发
定义 flink.py 文件
我们需要在 superset/superset/db_engine_specs目录下新增一个 flink.py文件包含三个类:
FlinkClient: 用于和 flink gateway 交互执行 flink sql。FlinkEngine: 模拟 mysql 的 cursor, 在一个 cursor 实例的生命周期内,就是和 flink gateway 的session 生命周期,当cursor 结束时,就是断开 session 的时候。FlinkEngineSpec: 继承 superset 自身的BaseEngineSpect, superset 的业务代码需要通过该类执行 sql 和查询结果。
FlinkClient
import logging
from typing import Any, Dict, Optional, Tuple, List, Union, Set
import time
import reimport requests
import sqlparse
from sqlalchemy import types, select
from sqlalchemy.orm import Session
from sqlalchemy.sql import text
from sqlalchemy.engine import Enginefrom superset.models.core import Database
from superset.config import FLINK_HOST
from superset.db_engine_specs.base import BaseEngineSpec
from superset.models.sql_lab import Querylogger = logging.getLogger(__name__)class FlinkClient:result_type = {"NOT_READY": "NOT_READY", # 表明 sql 还在执行中"PAYLOAD": "PAYLOAD", # 表明 sql 已经在 flink 集群上执行了,需要 client 循环获取结果"EOS": "EOS" # 表明已经获取到 sql 执行结果了,可以退出循环}result_kind = {"SUCCESS_WITH_CONTENT": "SUCCESS_WITH_CONTENT", # 执行的是查询结果的 sql"SUCCESS": "SUCCESS" # 执行的是命令}def __init__(self, **kwargs):self.session_id = Noneself.operation_ids = []# 添加连接时在额外参数中填写的初始化命令# 在执行 sql 前会先执行话初始化命令self.init_commands = kwargs.get("init_commands", [])# FLINK_HOST 就是 flink gateway 的地址,我是从环境变量中获取的self.get_session_url = FLINK_HOST + "/v1/sessions", "POST"self.execute_statement_url = FLINK_HOST + "/v1/sessions/{SESSION_ID}/statements/", "POST"self.fetch_result_url = FLINK_HOST + "/v1/sessions/{SESSION_ID}/operations/{OPERATION_ID}/result/{BATCH_NUM}", "GET"self.kwargs = kwargsdef __enter__(self):# 使用上下文模式,调用的时候获取 session 和执行初始化命令self.get_session()for c in self.init_commands:operation_id = self.execute(c)self.fetch_result(operation_id=operation_id)return selfdef __exit__(self, exc_type, exc_value, traceback):if exc_type is not None:logger.error(f"flink gateway got error: {exc_type}, {exc_value}")return Falsedef handle_request(self,url: str,method: str,form_data: Dict[str, Any] = None,json_data: Dict[str, Any] = None,params: Dict[str, Any] = None,headers: Dict[str, Any] = None,timeout: Tuple[int, ...] = (10, 60)) -> Dict[str, Any]:try:kwargs = {"timeout": timeout,"headers": {"Content-Type": "application/json"}}if form_data:kwargs["data"] = form_dataif params:kwargs["params"] = paramsif json_data:kwargs["json"] = json_dataif headers:kwargs["headers"].update(headers)# logger.info(f"request to flink gateway url: {url}")# logger.info(f"request to flink gateway kwargs: {kwargs}")if method == 'GET':response = requests.get(url, **kwargs)elif method == 'POST':response = requests.post(url, **kwargs)elif method == 'PUT':response = requests.put(url, **kwargs)elif method == 'DELETE':response = requests.delete(url, **kwargs)else:raise ValueError("Unsupported HTTP method")response.raise_for_status()res = {'status_code': response.status_code,'headers': dict(response.headers),'data': response.json()}# logger.info(f"flink gateway response: {res}")return resexcept Exception as e:logger.error(f"flink gateway res error: {str(e)}")raise edef get_session(self):res = self.handle_request(self.get_session_url[0], self.get_session_url[1])self.session_id = res['data'].get('sessionHandle')def ping(self):operation_id = self.execute("select 1")return True if self.fetch_result(operation_id=operation_id) else Falsedef execute(self, statement: str):# 执行 flink sqldata = {"statement": statement}res = self.handle_request(self.execute_statement_url[0].format(SESSION_ID=self.session_id),self.execute_statement_url[1],json_data=data)self.operation_ids.append(res['data'].get('operationHandle'))return res['data'].get('operationHandle')def fetch_result(self, batch_num: int = 0, operation_id: str =None) -> Dict[str, Any]:"""通过 flink gateway 获取执行结果:gateway 将 sql 提交至集群后返回 PAYLOAD 状态表示提交成功,否则返回 NOT_READY 状态。当提交至集群成功后,如果执行的 sql 是查询内容的,需要通过 batch_num(nextResultUri) 不断循环请求执行结果,直到 gateway 返回 EOS 状态,表示集群执行完毕,获取结果完毕。"""url = self.fetch_result_url[0].format(SESSION_ID=self.session_id,OPERATION_ID=operation_id,BATCH_NUM=batch_num)res_data = []res = self.handle_request(url, self.fetch_result_url[1])# 后续考虑是否做成从环境变量中获取超时时间,且超时后是否考虑杀死集群上执行的任务timeout = 300 # flink gateway 提交任务至 session 集群超时时间while timeout and res['data']['resultType'] == self.result_type['NOT_READY']:time.sleep(1)timeout -= 1res = self.handle_request(url, self.fetch_result_url[1])# 等待集群执行完毕,获取结果if res['data']['resultKind'] == self.result_kind['SUCCESS_WITH_CONTENT']:timeout = 3600 # flink gateway 从集群获取结果超时时间while timeout and res['data']['resultType'] != self.result_type['EOS']:time.sleep(3)timeout -= 1res_data.extend(res['data']['results']['data'])logger.info(f"jobID: {res['data'].get('jobID')} waiting for result")next_result_url = FLINK_HOST + res['data']['nextResultUri']res = self.handle_request(next_result_url, self.fetch_result_url[1])res['data']['results']['data'] = res_datareturn res['data']['results']def get_schema_names(self, catalog: str) -> List[str]:operation_id = self.execute(f"use catalog {catalog}")self.fetch_result(operation_id=operation_id)operation_id = self.execute(f"show databases")res = self.fetch_result(operation_id=operation_id)return [i['fields'][0] for i in res['data']]def get_table_names(self, catalog: str, schema: str) -> List[str]:operation_id = self.execute(f"use catalog {catalog}")self.fetch_result(operation_id=operation_id)operation_id = self.execute(f"use {schema}")self.fetch_result(operation_id=operation_id)operation_id = self.execute("show tables")res = self.fetch_result(operation_id=operation_id)return [i['fields'][0] for i in res['data']]def get_columns(self, catalog: str, schema: str, table_name: str) -> List[str]:operation_id = self.execute(f"use catalog {catalog}")self.fetch_result(operation_id=operation_id)operation_id = self.execute(f"use {schema}")self.fetch_result(operation_id=operation_id)operation_id = self.execute(f"desc {table_name}")res = self.fetch_result(operation_id=operation_id)return [i['fields'] for i in res['data']]
这里与 flink gateway 交互获取结果有个需要注意的地方就是,我们将执行 sql 提交至 flink gateway 后, gateway resultType 会很快返回 PAYLOAD状态,这个时候不代表 sql 执行完了,代表的是集群在执行中了,我们可以阻塞获取执行结果了,然后我们在阻塞获取结果,当状态变为 EOS的时候,代表我们获取到了结果了,这个时候可以退出阻塞了。
官方的流程图说明如下: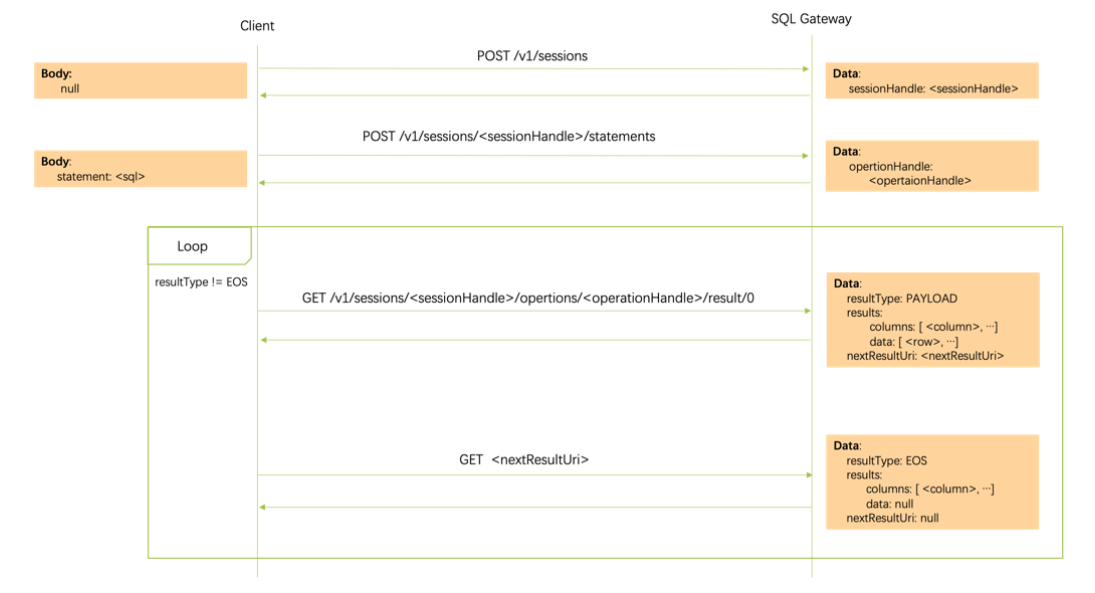
这里需要了解下我们的客户端通过 HTTP 接口与 gateway 交互的流程,不熟悉的可以先通过官方文档了解下:
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/sql-gateway/overview/
FlinkEngine
FlinkEngine 模拟的是类似 sql dialect 的 cursor, 通过该方法可以返回一个连接 flink gateway 的 client,在 cursor 的整个实例生命周期内使用的是同一个 FlinkClient 的 session。
class FlinkEngine:def __init__(self, catalog: str, schema: str = None,init_commands: List[str] = None, **kwargs):self.catalog = catalogself.schema = schemaself.init_commands = init_commands if init_commands else []self.kwargs = kwargsself.client: Optional[FlinkClient] = Noneself.columns = None@propertydef engine(self) -> 'FlinkEngine':return selfdef raw_connection(self) -> 'FlinkEngine':# 实例化 flink clint 生成一个 session, 当 cursor 结束时重置 clientwith FlinkClient(catalog=self.catalog, init_commands=self.init_commands) as c:self.client = creturn selfdef cursor(self) -> 'FlinkEngine':"""Return a new :py:class:`Cursor` object using the connection."""return selfdef close(self):self.client = Noneself.columns = Nonedef commit(self):"""Presto does not support transactions"""pass@propertydef description(self):"""This read-only attribute is a sequence of 7-item sequences.Each of these sequences contains information describing one result column:- name- type_code- display_size (None in current implementation)- internal_size (None in current implementation)- precision (None in current implementation)- scale (None in current implementation)- null_ok (always True in current implementation)The ``type_code`` can be interpreted by comparing it to the Type Objects specified in thesection below."""if self.columns is None:return Nonereturn [# name, type_code, display_size, internal_size, precision, scale, null_ok(col['name'], col['type'], None, None, None, None, True)for col in self.columns]
FlinkEngineSpec
该方法需要继承 superset 的 BaseEngineSpec, 需要定义 engine 信息和 drivers 信息, 在 superset 的 sqllab 执行 sql 的时候会通过 drivers 定位到该方法执行。
所以在前边界面配置的时候需要注意连接信息中的 driver_name 要和类属性 drivers 匹配。
class FlinkEngineSpec(BaseEngineSpec):engine = "flink"engine_name = "Apache Flink"# 我们后边在业务代码中会通过判断连接的 driver_name 是否为 flink_driver 来调用该类中的方法# 因此需要注意前端界面配置是否一致drivers = {"flink_driver": "flink gateway engine"}default_driver = "flink_driver"client_init_commands = []@classmethoddef get_schema_names(cls, catalog: str) -> List[str]:with FlinkClient(init_commands=cls.client_init_commands) as c:names = c.get_schema_names(catalog)return names@classmethoddef get_table_names(cls, catalog: str, schema: str, database=None) -> List[str]:with FlinkClient(init_commands=cls.client_init_commands) as c:names = c.get_table_names(catalog, schema)return names@classmethoddef get_view_names(cls, catalog: str, schema: str, database=None) -> Set[str]:return set()@classmethoddef get_columns(cls, catalog: str, schema: str, table: str) -> List[Dict[str, Any]]:with FlinkClient(init_commands=cls.client_init_commands) as c:cs = c.get_columns(catalog, schema, table)result: List[Dict[str, Any]] = []for column in cs:column_spec = cls.get_column_spec(column[1])column_type = column_spec.sqla_type if column_spec else Noneif column_type is None:column_type = types.String()c = {"name": column[0],"type": column_type,"nullable": column[2],"default": None,"key": column[3]}try:c.update({"comment": column[6]})except Exception:passresult.append(c)return result@classmethoddef get_pk_constraint(cls, catalog: str, schema: str, table: str) -> Dict[str, Any]:with FlinkClient(init_commands=cls.client_init_commands) as c:cs = c.get_columns(catalog, schema, table)pks = {"constrained_columns": None, "name": None}for column in cs:_type = column[3]if isinstance(_type, str) and _type.startswith("PRI"):matches = re.findall(r'\((.*?)\)', _type)pks["constrained_columns"] = [field.strip() for field in matches[0].split(',')]breakreturn pks@classmethoddef select_star( # pylint: disable=too-many-arguments,too-many-localscls,database: Database,table_name: str,engine: Engine,schema: Optional[str] = None,limit: int = 100,show_cols: bool = False,indent: bool = True,latest_partition: bool = True,cols: Optional[List[Dict[str, Any]]] = None,) -> str:fields: Union[str, List[Any]] = "*"cols = cols or []if (show_cols or latest_partition) and not cols:cols = database.get_columns(table_name, schema)if show_cols:fields = cls._get_fields(cols)if schema:full_table_name = f"{schema}.{table_name}"else:full_table_name = f"{table_name}"qry = select(fields).select_from(text(full_table_name))if limit:qry = qry.limit(limit)if latest_partition:partition_query = cls.where_latest_partition(table_name, schema, database, qry, columns=cols)if partition_query is not None:qry = partition_querysql = str(qry.compile(compile_kwargs={"literal_binds": True}))if indent:sql = sqlparse.format(sql, reindent=True)return sql@classmethoddef execute( # pylint: disable=unused-argumentcls,cursor: FlinkEngine,query: str,**kwargs: Any,) -> None:"""执行 flink sql 语句"""return cursor.client.execute(query)@classmethoddef handle_cursor(cls, cursor: FlinkClient, query: Query, session: Session) -> None:"""在执行 flink sql 执行过程中,执行一些动作:记录flink sql 任务的一些关键信息记录一些执行日志sleep 等待执行结果 等"""return@classmethoddef fetch_data(cls, cursor: FlinkEngine, limit: Optional[int] = None) -> List[Tuple[Any, ...]]:res = cursor.client.fetch_result(operation_id=cursor.client.operation_ids[-1])cursor.columns = [{"name": i['name'], "type": i["logicalType"]["type"]} for i inres.get('columns', [])]return [tuple(i['fields']) for i in res['data']]@classmethoddef has_implicit_cancel(cls) -> bool:"""该方法是sqllab 界面执行 sql 中点击暂停时调用的这里直接返回了 True, 因为 gateway 的 session 自己有过期时间我们也可以通过调用 gateway 的关闭 session 接口主动关闭"""return True@classmethoddef cancel_query( # pylint: disable=unused-argumentcls,cursor: FlinkClient,query: Query,cancel_query_id: str,) -> bool:"""该方法是sqllab 界面执行 sql 中点击暂停时调用的这里直接返回了 True, 因为 gateway 的 session 自己有过期时间我们也可以通过调用 gateway 的关闭 session 接口主动关闭"""return True
修改测试连接逻辑
测试连接入口方法在 superset/databases/commands/test_connection.py下的 TestConnectionDatabaseCommand 类中的 run 方法,我们需要通过连接的 driver 来通过 FLinkClient 测试与 Flink gateway 的连接是否正常: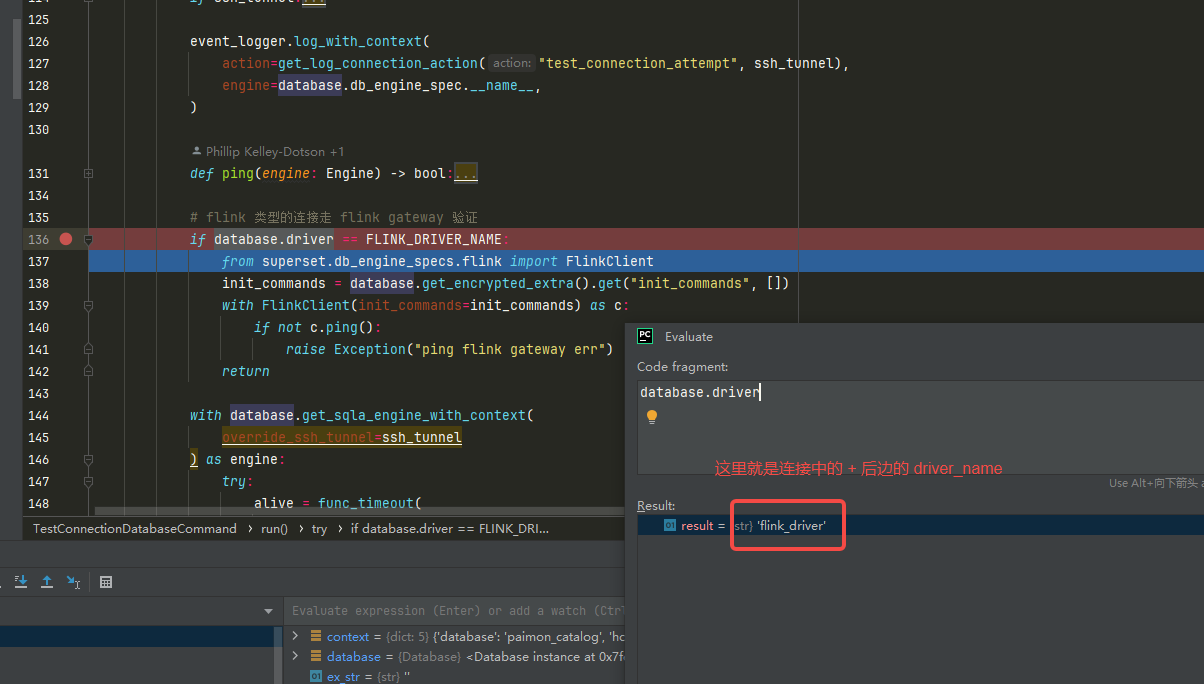
# flink 类型的连接走 flink gateway 验证
if database.driver == FLINK_DRIVER_NAME:from superset.db_engine_specs.flink import FlinkClientinit_commands = database.get_encrypted_extra().get("init_commands", [])with FlinkClient(init_commands=init_commands) as c:if not c.ping():raise Exception("ping flink gateway err")return
修改 sqllab 界面逻辑
sqllab 界面需要修改获取库表信息和执行 sql 的接口逻辑: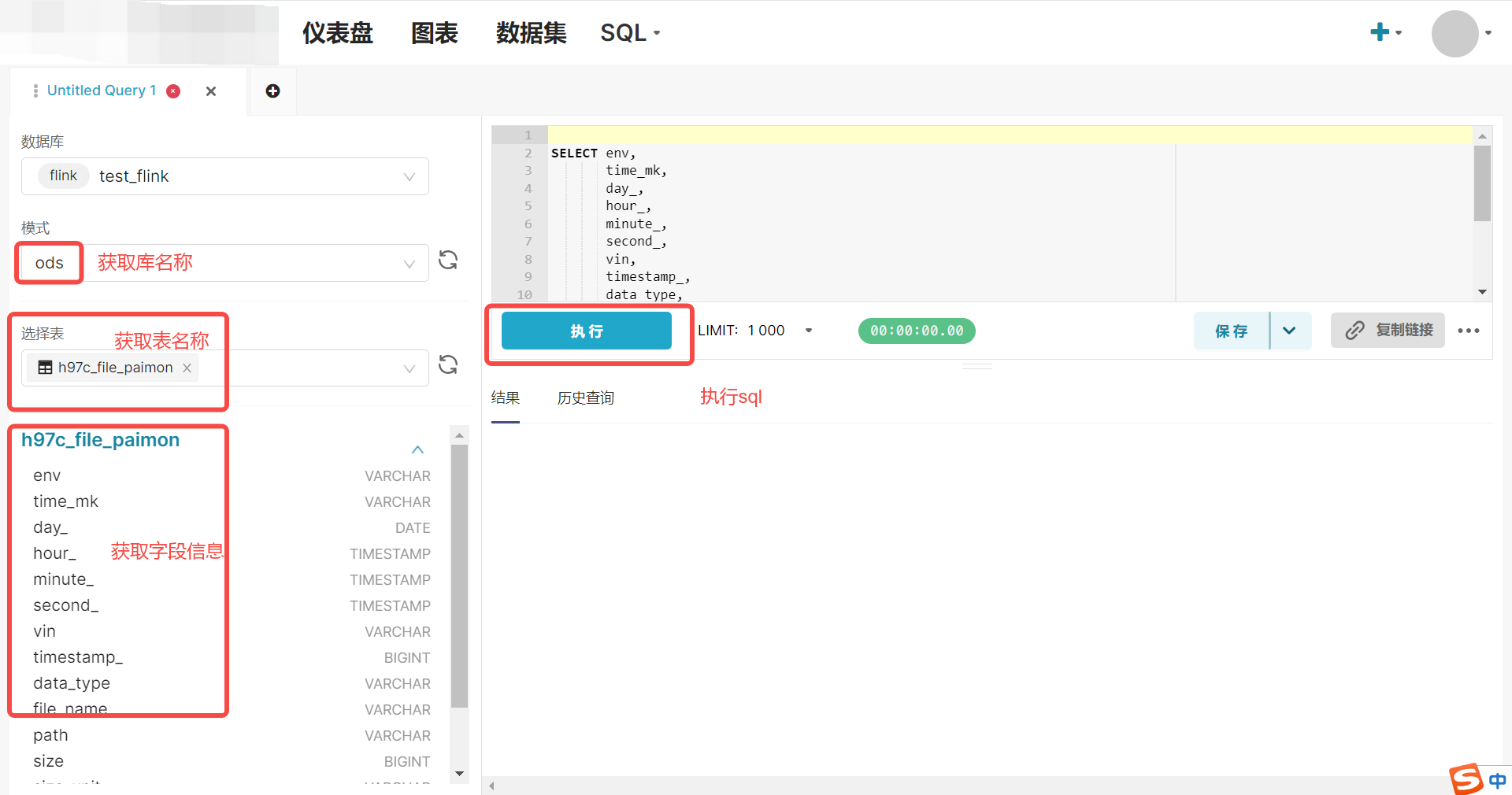
查询库表字段信息的接口入口类都在 superset/superset/databases/api.py中: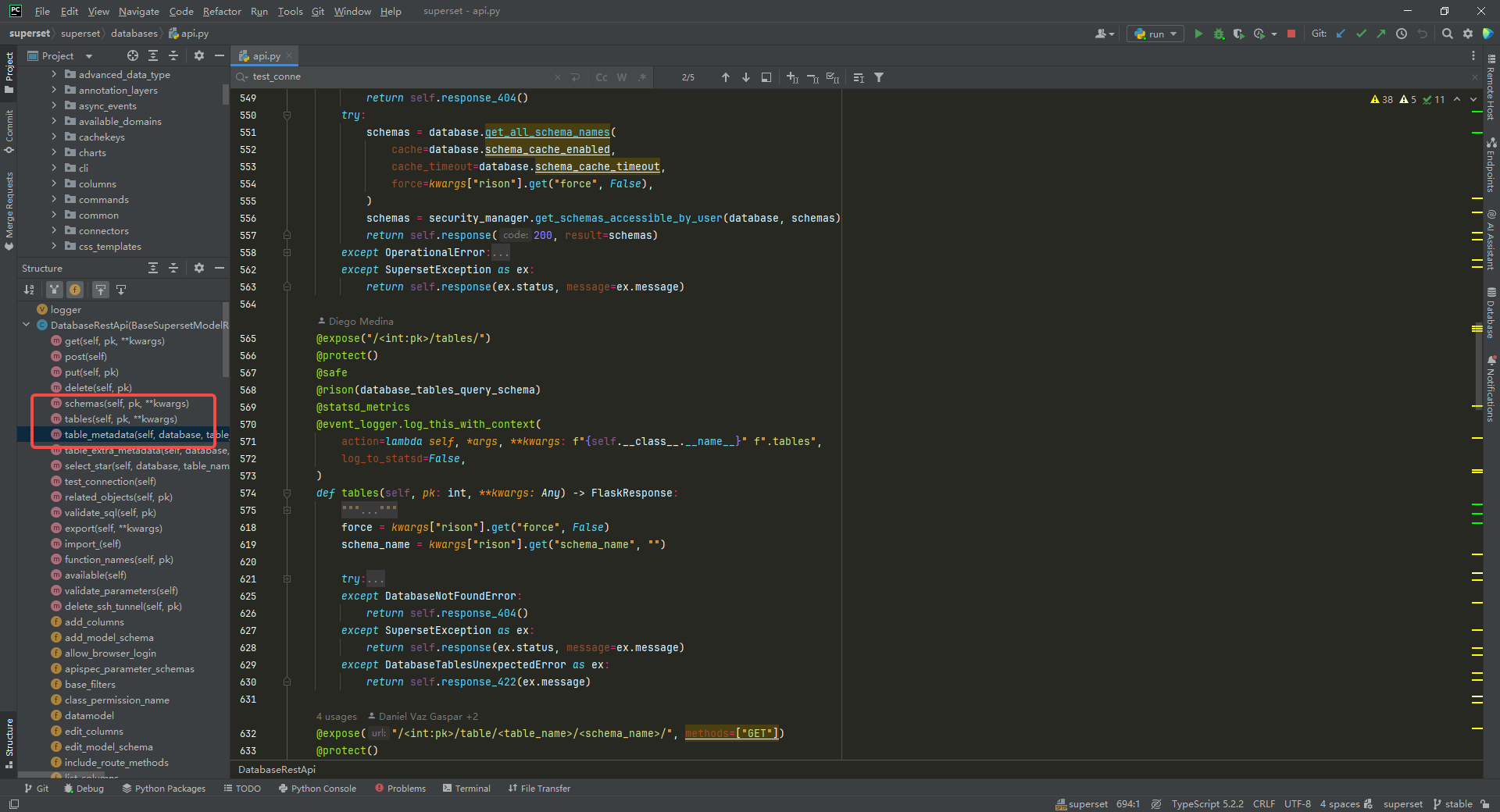
api 入口的代码逻辑不需要修改。
获取库名称列表,修改 superset/superset/models/core.py中 Database类中的 get_all_schema_names方法: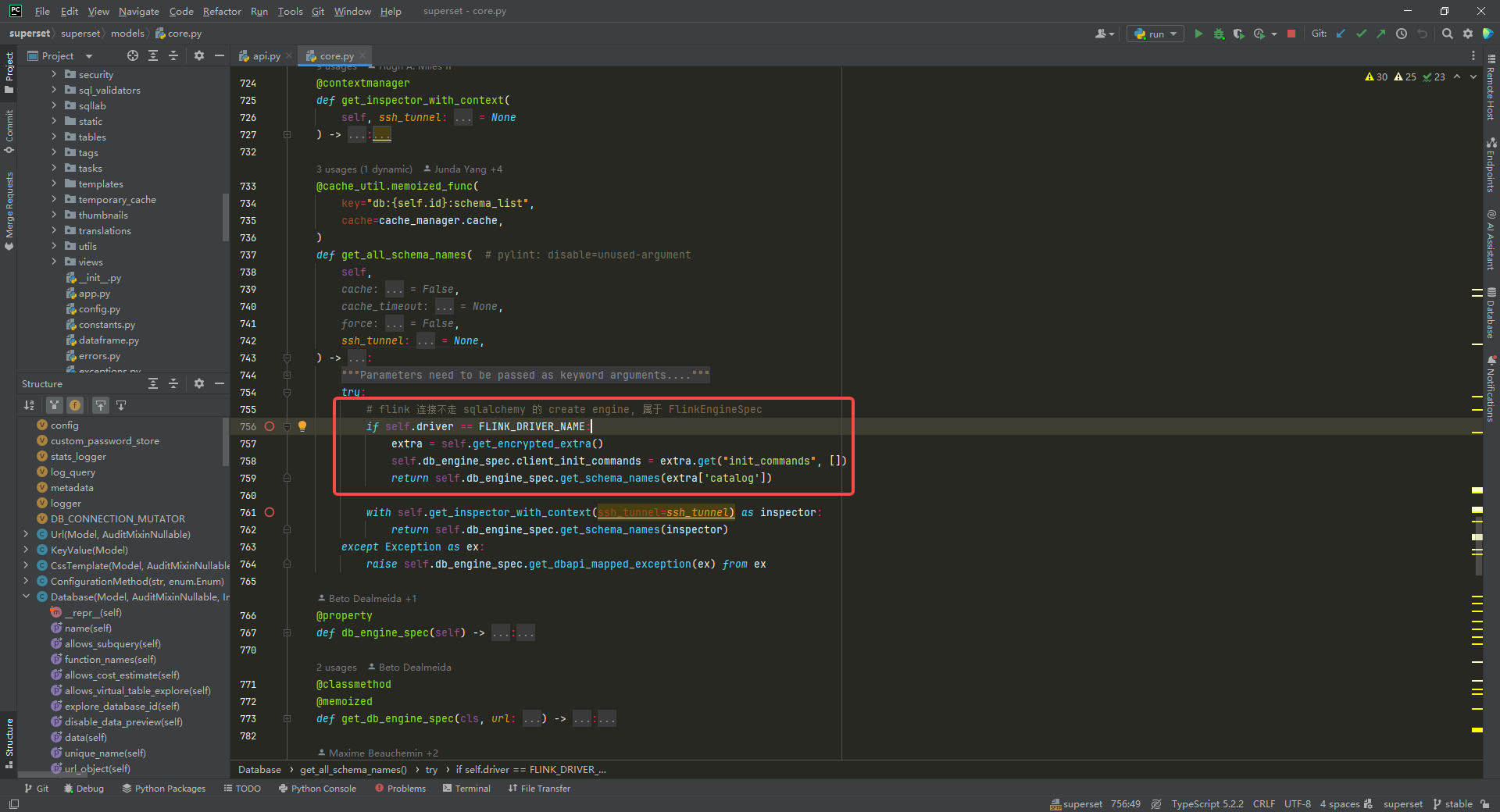
# flink 连接不走 sqlalchemy 的 create engine, 属于 FlinkEngineSpec
if self.driver == FLINK_DRIVER_NAME:extra = self.get_encrypted_extra()self.db_engine_spec.client_init_commands = extra.get("init_commands", [])return self.db_engine_spec.get_schema_names(extra['catalog'])
获取表名称列表,修改 superset/superset/models/core.py中 Database类中的 get_all_table_names_in_schema方法和 get_all_view_names_in_schema方法: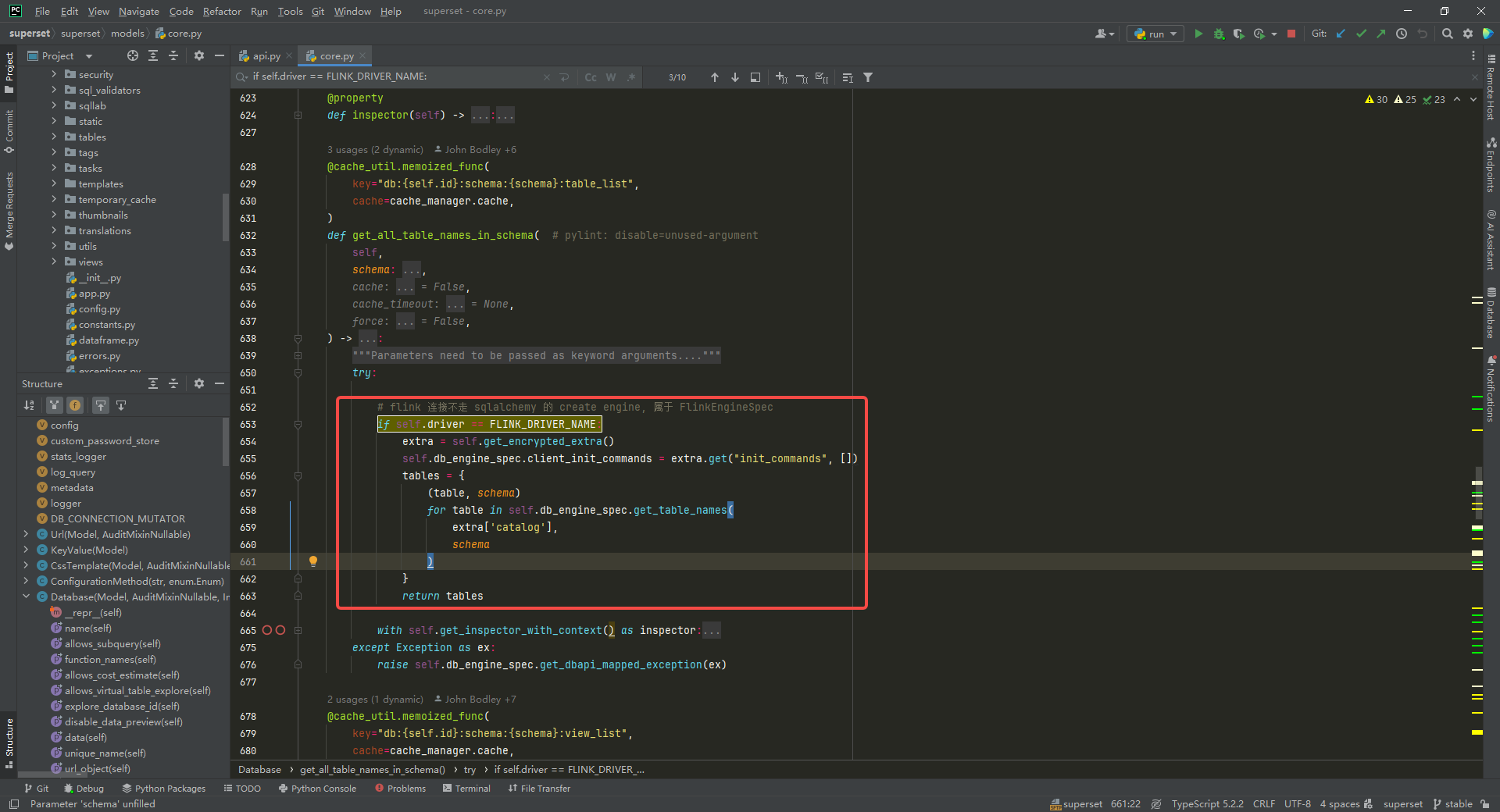
# flink 连接不走 sqlalchemy 的 create engine, 属于 FlinkEngineSpec
if self.driver == FLINK_DRIVER_NAME:extra = self.get_encrypted_extra()self.db_engine_spec.client_init_commands = extra.get("init_commands", [])tables = {(table, schema)for table in self.db_engine_spec.get_table_names(extra['catalog'],schema)}return tables
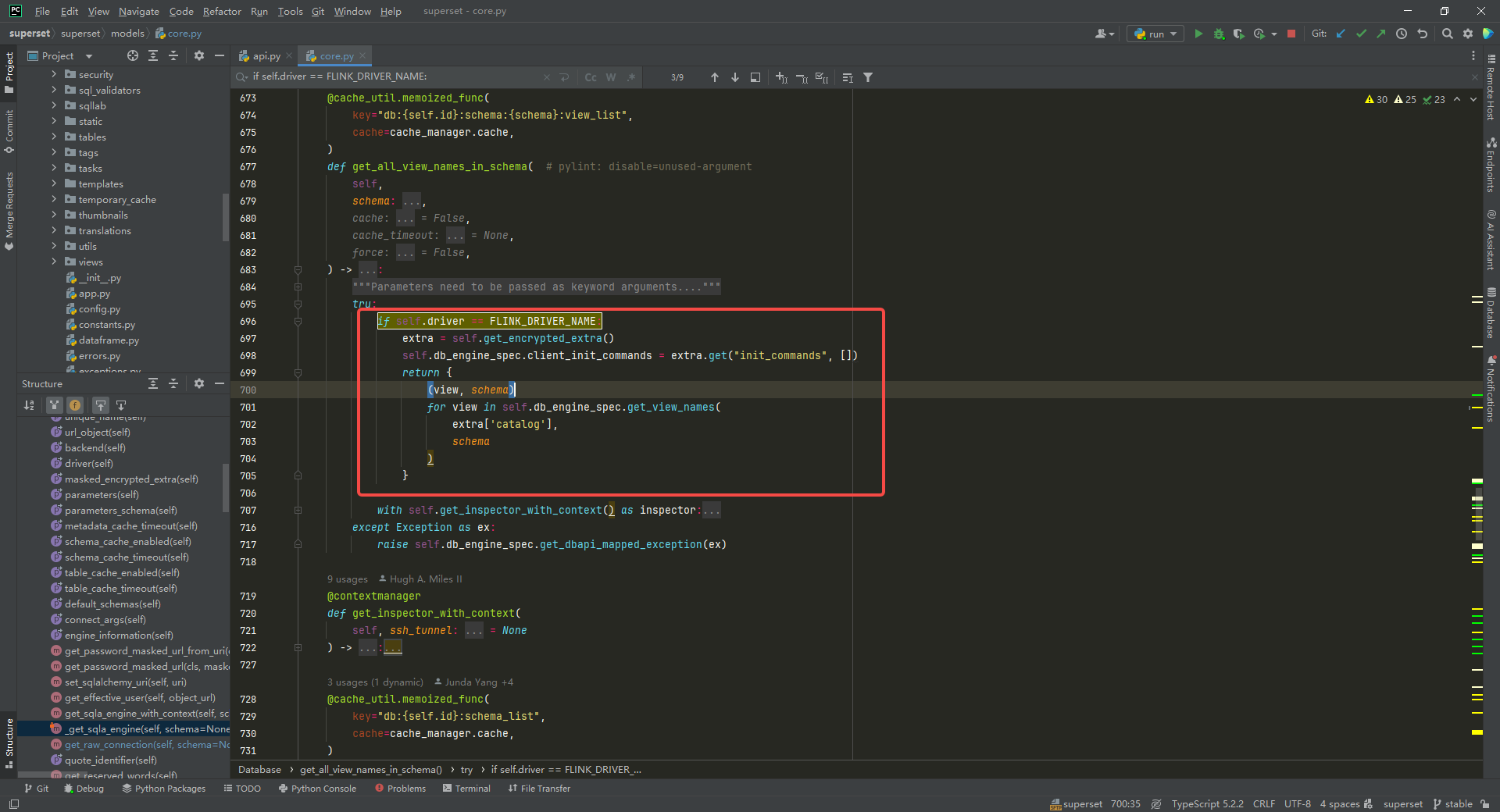
if self.driver == FLINK_DRIVER_NAME:extra = self.get_encrypted_extra()self.db_engine_spec.client_init_commands = extra.get("init_commands", [])return {(view, schema)for view in self.db_engine_spec.get_view_names(extra['catalog'],schema)}
获取字段信息,修改 superset/superset/models/core.py中 Database类中的 get_columns方法: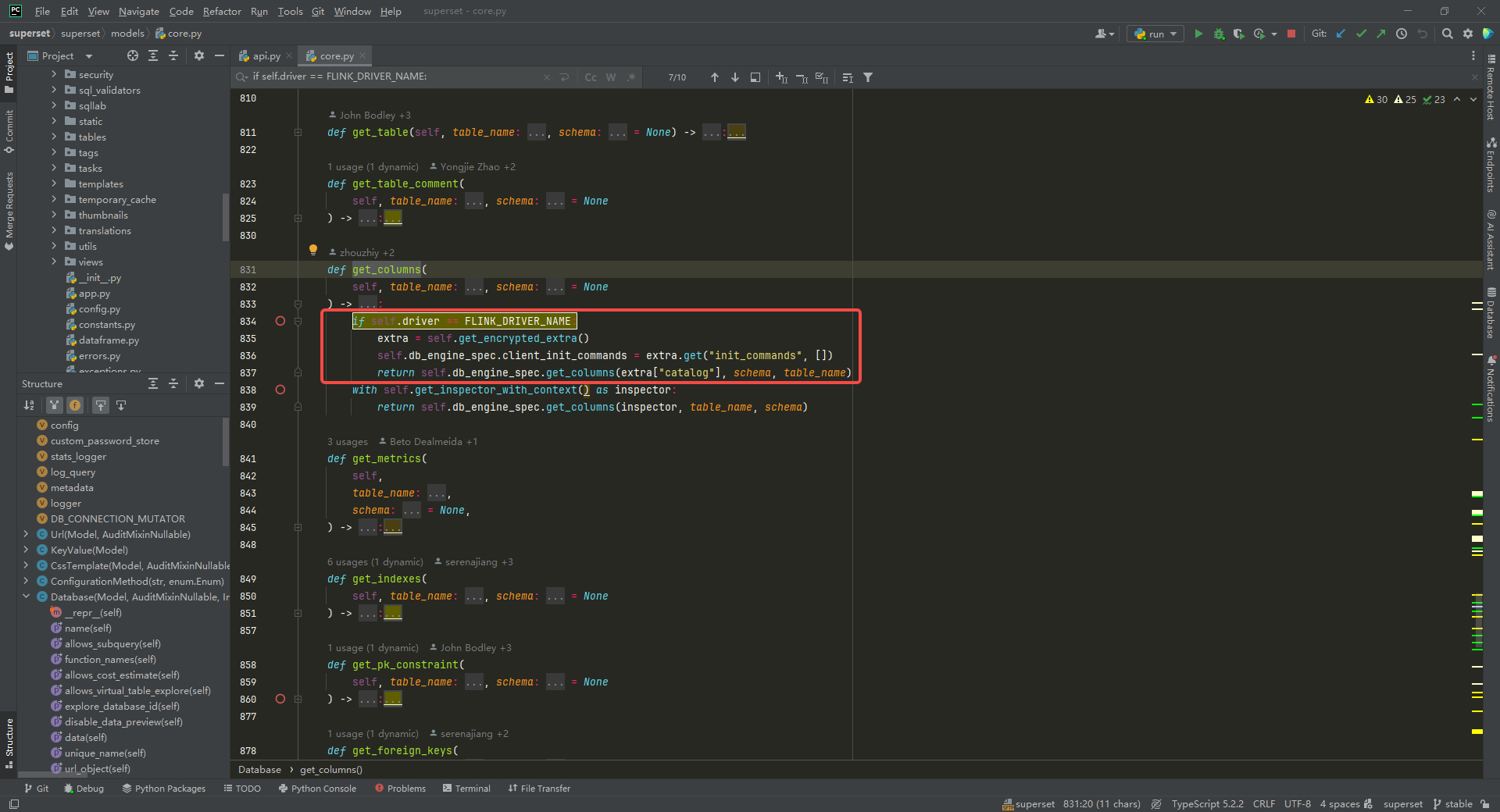
if self.driver == FLINK_DRIVER_NAME:extra = self.get_encrypted_extra()self.db_engine_spec.client_init_commands = extra.get("init_commands", [])return self.db_engine_spec.get_columns(extra["catalog"], schema, table_name)
获取表 comment 信息,修改 get_table_comment方法,这个目前还没有找到通过 flink sql 查询表 comment 信息的方法,这里直接返回空: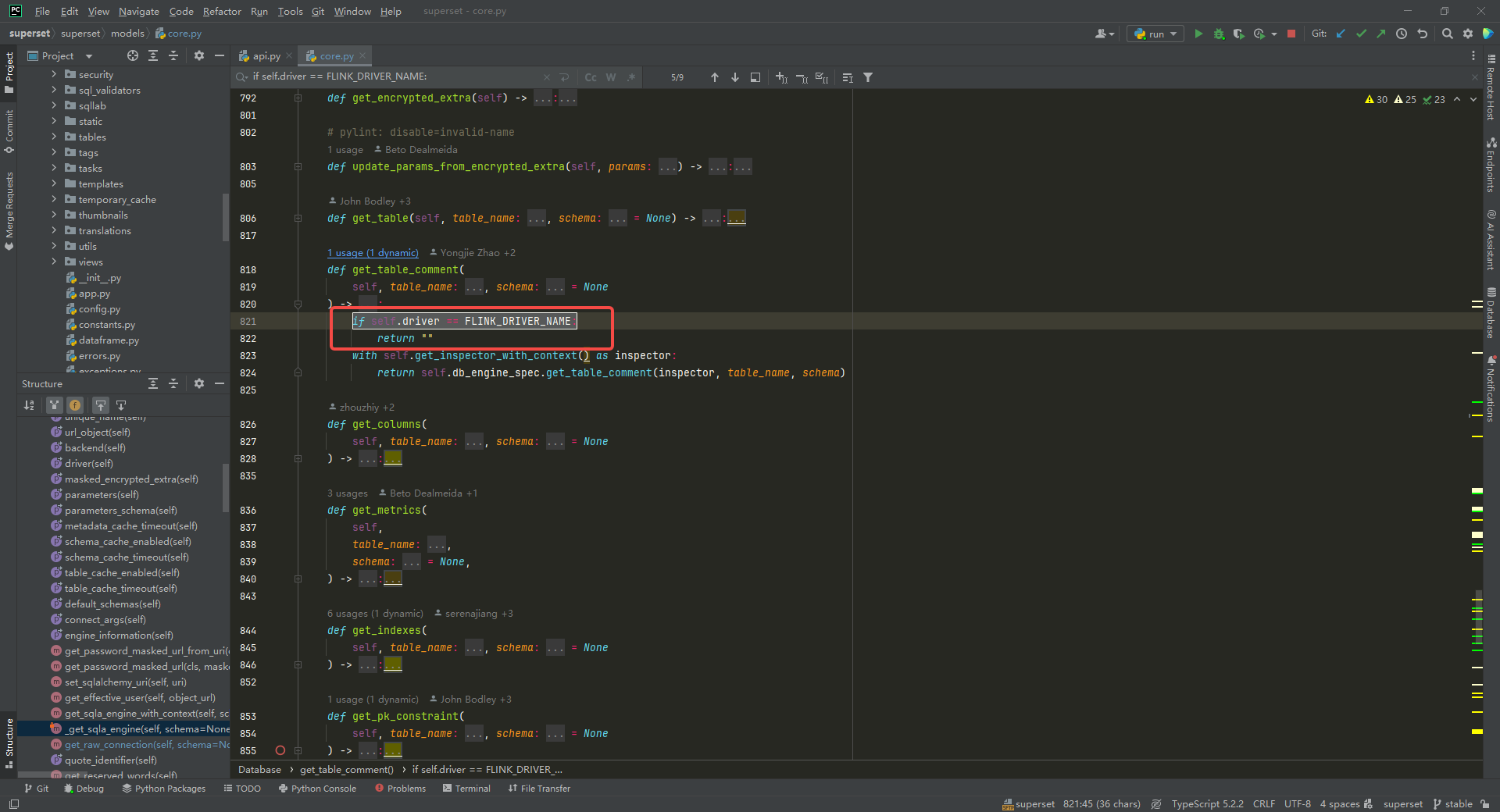
if self.driver == FLINK_DRIVER_NAME:return ""
获取索引信息,修改 get_indexes方法,返回空列表: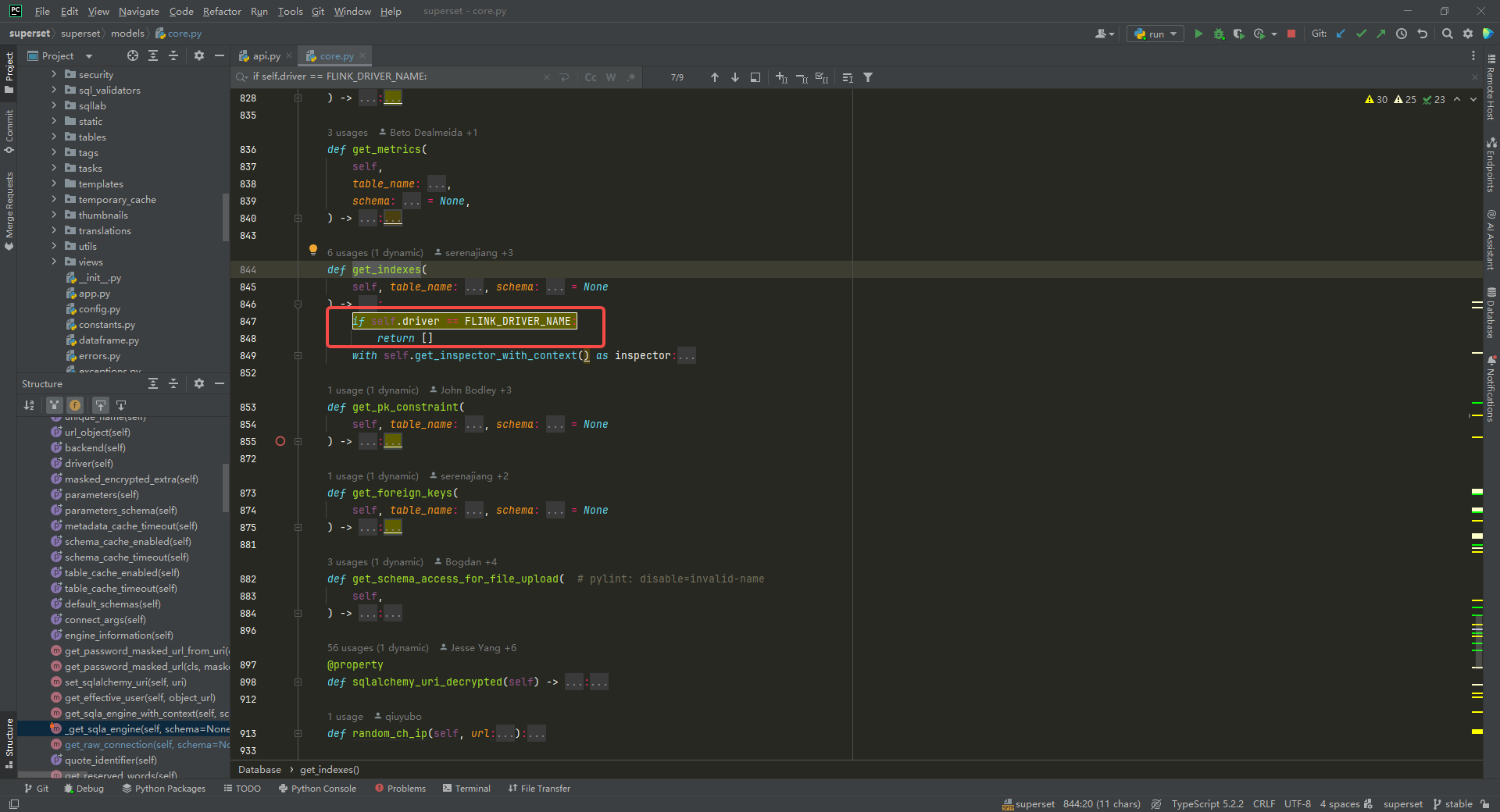
if self.driver == FLINK_DRIVER_NAME:return []
获取主键信息,修改get_pk_constraint方法: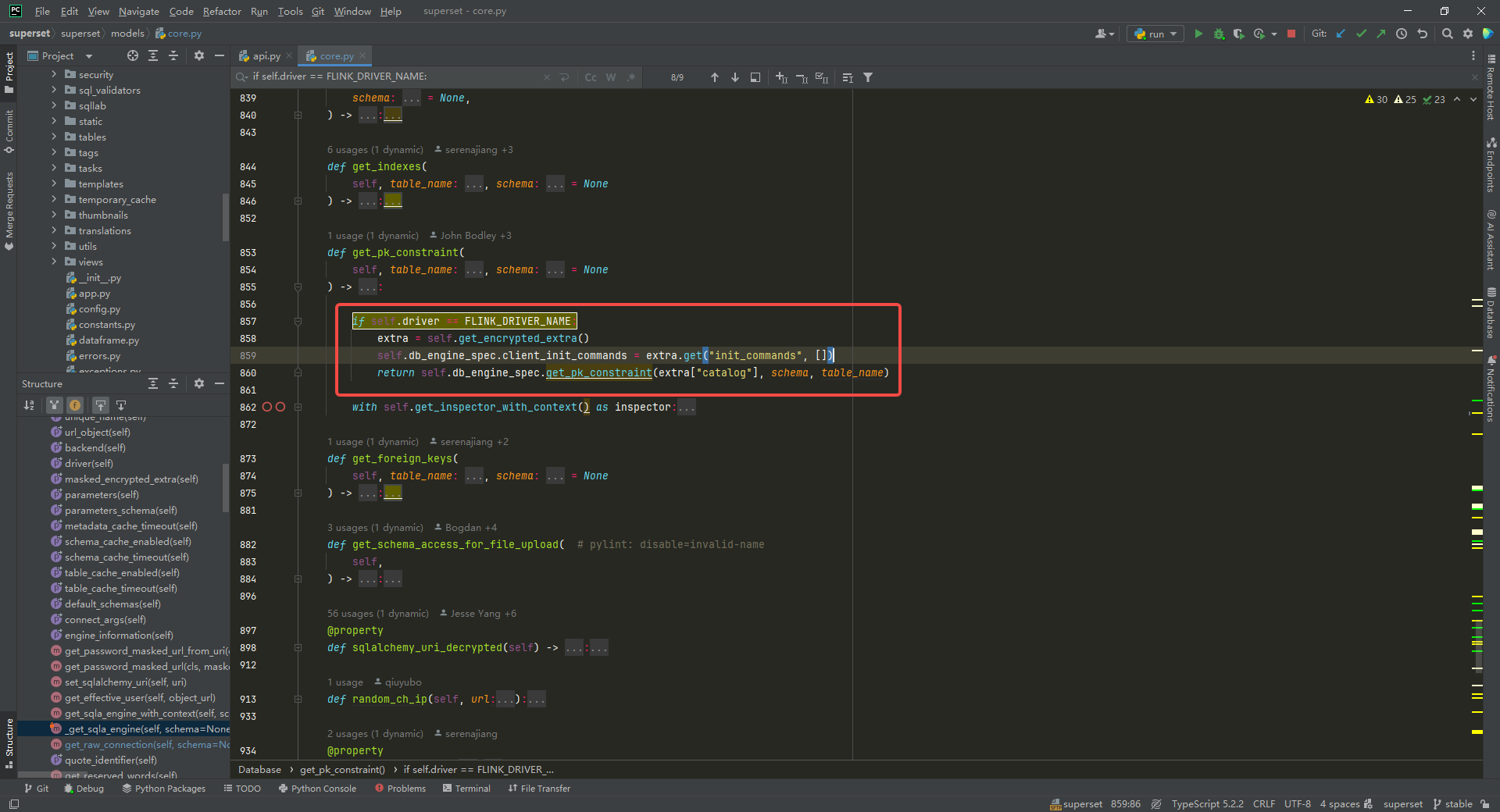
if self.driver == FLINK_DRIVER_NAME:extra = self.get_encrypted_extra()self.db_engine_spec.client_init_commands = extra.get("init_commands", [])return self.db_engine_spec.get_pk_constraint(extra["catalog"], schema, table_name)
获取外键信息,修改get_foreign_keys方法: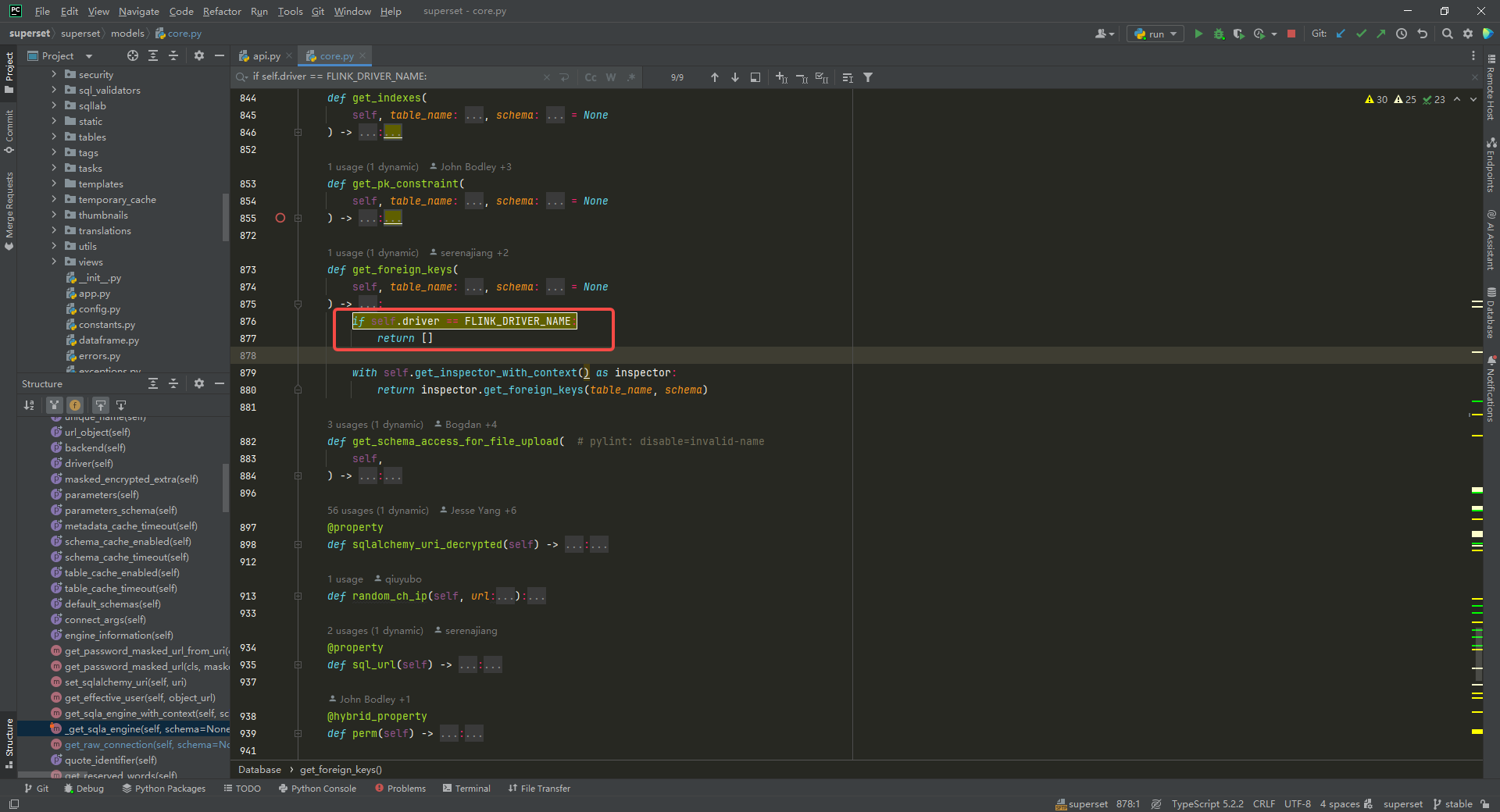
if self.driver == FLINK_DRIVER_NAME:return []
执行 sql 相关的需要修改 _get_sqla_engine方法。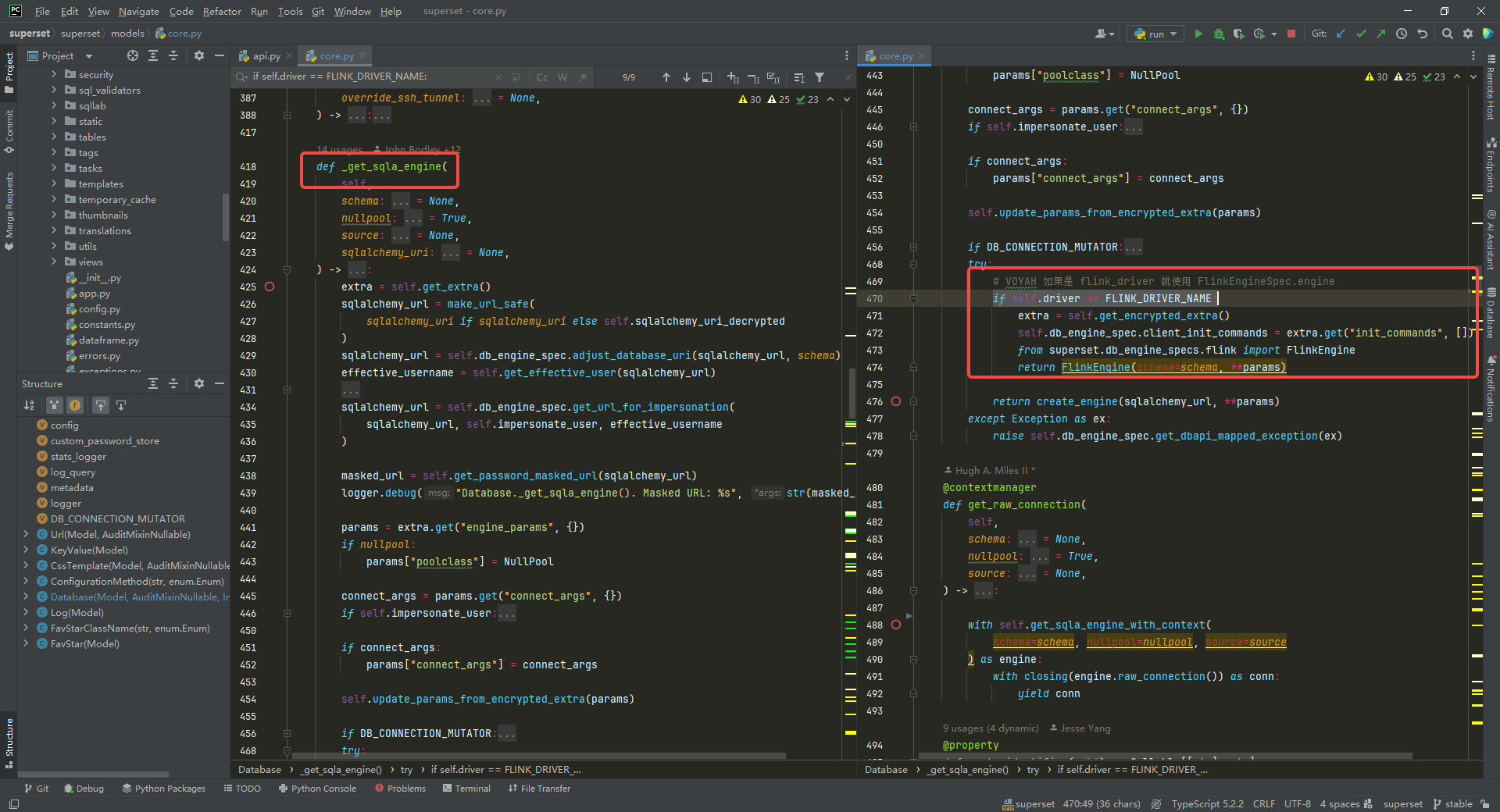
# VOYAH 如果是 flink_driver 就使用 FlinkEngineSpec.engine
if self.driver == FLINK_DRIVER_NAME:extra = self.get_encrypted_extra()self.db_engine_spec.client_init_commands = extra.get("init_commands", [])from superset.db_engine_specs.flink import FlinkEnginereturn FlinkEngine(schema=schema, **params)
总结
增加其他数据源连接,主要需要修改两个文件新增一个文件:
-
修改
superset/databases/commands/test_connection.py中的TestConnectionDatabaseCommand类中的 run 方法。修改
superset/superset/models/core.py中Database类中的get_all_table_names_in_schema,get_all_view_names_in_schema,get_columns,get_table_comment,get_indexes,get_pk_constraint,get_foreign_keys,_get_sqla_engine方法。 -
在
superset/superset/db_engine_specs目录下新增一个flink.py文件。
这篇关于superset 二开增加 flink 数据源连接通过flink sql 查询数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






