本文主要是介绍超拟人语音合成上线,打造有温度的交互新体验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语言使得人类可以构建共同想象的现实,即共同的信念,从而进行大规模团结合作,这是认知革命赋予人类力量的核心。在《人类简史》中,语言被描述成为人类进化的关键力量,而语音的能力是推动语言逐渐进化的火花。
人工智能的出现,让机器也能拥有如同人类一般的语音能力。但伴随人机交互的普及,机器要突破的不只是能听会说,还需要精准表达性格与情感,成为人机交互的新趋势。
作为人工智能发展长河中最早起步,也是落地最早的技术之一,语音技术正朝着让人惊叹的方向不断进化。
历经百年,语音合成走进千行百业
语音合成采用先进的深度学习技术,可实现文本转化成拟人化的语音。即“赋予机器像人一样自如说话的能力”,是语音交互、语音翻译的关键接口能力。

(图片由讯飞星火生成)
1779年,德裔丹麦科学家 Christian Gottlieb Kratzenstein 建造了人类的声道模型,使其可以产生五个长元音。这可以说是语音合成技术最早的起源。
1960年,瑞典科学家G. Fant的著作《语音产生的声学理论》建立了现代语音分析、合成的理论基础,极大推动了语音合成技术的进步。
到20世纪90年代,语音合成已经可以商业应用。然而,当时中文语音市场几乎全部掌握在跨国公司手中。1999年,科大讯飞成立后,这一切发生了改变。以语音合成技术为基础,讯飞持续深耕语音领域。2010年10月28日,科大讯飞发布了提供移动互联网智能语音交互能力平台——讯飞语音云,向全世界开发者开放自己的语音合成技术。
语音合成技术飞速发展,从实验室悄无声息地渗入我们每个人的生活,有时,你甚至毫无察觉。
上班途中,你不仅可以使用各种阅读软件翻阅书籍,还能戴上耳机“听”书;
驾车时,打开导航软件,可以听到流畅的人声实时为你导航;
下班回到家,躺在沙发上和音箱对话,音箱将为你播放想听的音乐;
然而应用初期,传统合成技术受制于声音采集的因素,合成出来的声音,刻板、不接地气,缺乏像真人声音一样的抑扬顿挫,很容易分辨出是由机器合成的,让人产生听觉疲劳。
近年来,越来越多的科技企业将眼光转向音色合成、情感合成等领域,力求使语音合成的声音更加自然,并具备个性化特征。
坚持源头技术创新,效果国际领先
自上世纪90年代,科大讯飞开始在语音领域的探索,确立了「让机器能听会说,能理解会思考;用人工智能建设美好世界」的公司使命。坚持源头技术创新,2006年到2019年,连续14年蝉联国际语音合成大赛冠军,持续走在世界前列。
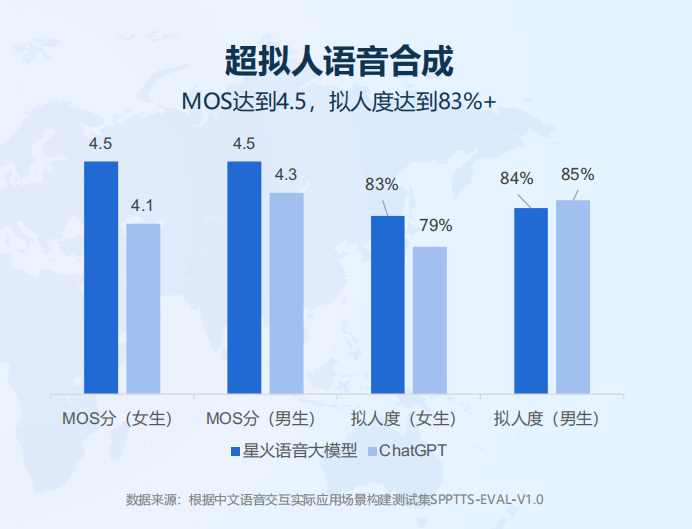
2024年1月30日,讯飞星火V3.5正式发布。大模型技术加持下,语音合成的韵律表现力和拟人度有了大幅提升,超拟人语音合成MOS达到4.5,拟人度达到83%+。
在语音合成领域,通常采用MOS(Mean Opinion Score,平均得分法)对语音质量进行评价,分值为1-5分,分值越高语音质量和自然度也越高。
其合成效果类似人类在日常生活的口语化表达习惯,像人类一样拥有副语言(呼吸、叹气)、变换语速、口误、 长停顿思考、轻重读等副语言表达能力,让合成听起来更具“人味儿”。
无论是轻松的日常聊天,还是复杂的专业问答,都能得到快速而精准的回复,声音中蕴含着温暖和情感,让人几乎忘记了是在与机器进行对话。
声情并茂,有温度的交互体验
近期,超拟人语音合成能力在讯飞开放平台上线,将文字转化为自然流畅的人声,在实时语音合成的基础上,进一步提升了语音的自然度和表现力,精准模拟人类的副语言现象,如呼吸、叹气、语速变化等,使得语音不仅流畅自然,更富有情感和生命力。

在产品设计上,“超拟人合成”采用业内领先的语音合成框架。其功能包括针对书面语转译成口语化文本和新版语音合成引擎。
其中新版语音合成引擎,使用大型语言模型对日常交流中的副语言现象进行建模,针对拟声词、话语符号、韵律等副语言标签进行预测。利用语音大模型对副语言标签进行还原,从而极大地提高了合成的拟人化效果。
与传统的语音合成相比,超拟人语音合成具有以下优势:
- 大模型加持,拟人效果升级
大型语言模型针对拟声词、话语符号、韵律等副语言标签进行预测,极大提升合成的拟人化效果。
- 真实自然,专业实力
专注语音20年,技术实力雄厚;人声自然饱满,逼真度高,富有表现力,人机交互更具真实感
- 智能读法判断
根据上下文和语境判断数字以及英文的朗读方式
- 动态调参,自由配置
随心调节语调/语速/音量等参数,满足复杂场景需求
超拟人语音合成+大模型,让人机交互深入人心
目前,超拟人语音合成能力已在讯飞星火APP上应用,让超2400万用户能体验到更自然、生动且有温度的声音。
用户只需打开讯飞星火APP,开启通话模式,即可听到星火发出如邻家大哥哥/大姐姐一样的声音,与你唠嗑,为你遇到的工作生活难题解惑、陪你度过孤独无聊的时光。
星火APP提供了“聆飞逸”、“聆小玥”男女声两种发音人,可自由切换。音色自然,还像人一样时不时有停顿、“嗯……”等语气词。打断后,可继续提问下一个问题,也可以直接“挂断”语音,切回到文字模式,看到刚刚整个对话过程的文字版。
除了讯飞星火APP,在使用场景方面,超拟人语音合成还可应用在新闻播报、智能硬件、电话客服、出行导航、有声阅读、无障碍播报等,提升用户体验,带去温情的服务。
随着超拟人语音合成能力的上线,开发者可以通过直接调用WebAPI接口,将其应用在开发的产品之中。期待超拟人语音合成能力解锁更丰富场景,为用户提供更加美好的语音交互体验,让全世界享受AI带来的乐趣。
进入讯飞开放平台,完成实名认证,可免费领取服务量和发音人
这篇关于超拟人语音合成上线,打造有温度的交互新体验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







