本文主要是介绍超越 GPT-4V 和 Gemini Pro!HyperGAI 发布最新多模态大模型 HPT,已开源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着AI从有限数据迈向真实世界,极速增长的数据规模不仅赋予了模型令人惊喜的能力,也给多模态模型提供了更多的可能性。OpenAI在发布GPT-4V时就已经明确表示:
将额外模态(如图像输入)融入大语言模型(LLMs)被认为是 AI 研究和发展的一个关键新领域。
昨天,HyperGAI 研究团队推出了 HPT(Hyper-Pretrained Transformers)系列,包含两个模型,HPT Air 和 HPT Pro。
其中HPT Pro 在部分基准测试中已经超越了 GPT-4V 和 Gemini Pro 的表现。同时,高效的版本 HPT Air 也相当强大,在同等小规模的模型中效果达到了最优,且已经开源。
分享几个自用的Claude 3和GPT-4的镜像站给大家吧,均为国内可用:
hujiaoai.cn(最牛的Claude 3 Opus,注册即用,测评下来完全吊打了GPT4)
higpt4.cn(稳定使用一年的chatgpt-4研究测试站,非商业目的,而且用的是最牛的128k窗口的版本)
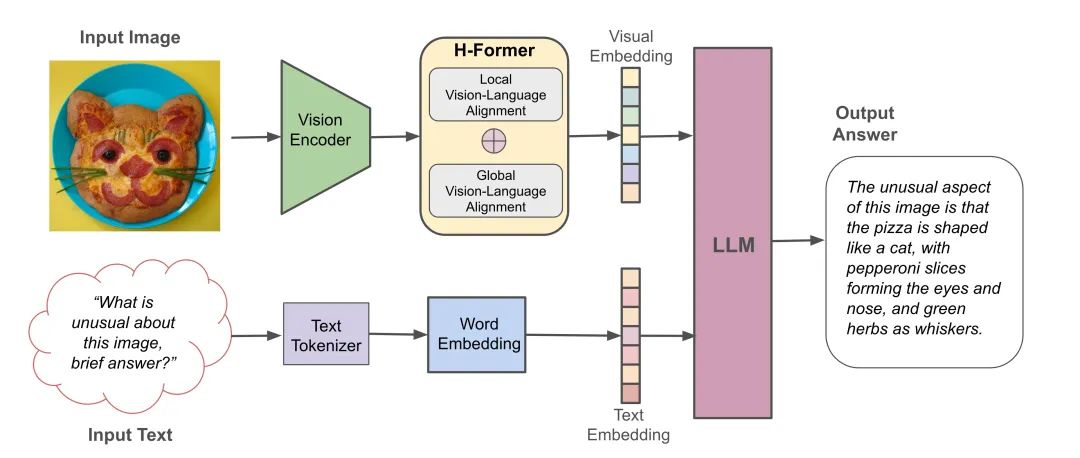
图1.HPT(Hyper-Pretrained Transformers)模型结构的介绍。
项目地址:
Github: https://github.com/hyperGAI/HPT
huggingface: https://huggingface.co/HyperGAI/HPT
过去模型只处理单一类型的数据,如文本、图像或者音频,往往单一模态下优化的模型的能力要强于多模态的模型。
去年,许多研究团队推出了自己的多模态大模型,比如DeepMind的Flamingo、Salesforce的Blip、Google的PaLM-E和Gemini等。从输入输出看,多模态可以简单分为模态转换、输入多模态、输出多模态,输入输出多模态。
HyperGAI 研究团队提出了一种名为“Hyper-Pretrained Transformers”(HPT)的新型多模态LLM预训练框架,可以理解多种输入模态。
HPT介绍
HPT的主要部件,如大语言模型和视觉编码器都可以使用开源的预训练模型,而HPT中连接视觉和语言模态的桥梁,称之为H-former,它将视觉数据转换为语言标记。
为了使语言模型能够充分理解视觉信息,H-Former 采用双网络设计,学习视觉—语言对齐的本地特征和全局特征,使 HPT 能够理解细粒度细节和抽象的高层信息。
如下图所示,H-former将图像转换成视觉嵌入,该嵌入具备与文本对齐的信息,可以直接作为视觉嵌入与文本嵌入一齐送入语言模型,如Yi-6B。

图2.H-former在传统的视觉编码器之后对视觉嵌入进行重新表示,生成的视觉嵌入可与文本嵌入组合送入预训练语言模型。

图3. 破案了,其实H-former就是Q-former,或者说是基于Q-former,其全局与局部的视觉—语言对齐应该是体现在对q_feat的处理上。
在原则上,HPT 可以从头开始训练,也可以利用现有的预训练视觉和语言模型。对于开源的 HPT Air 模型,作者利用了一个预训练的语言模型(Yi-6B)和视觉编码器(clip-vit-large-patch14-336),在只有大约 160 万个文本—图像样本的多模态训练数据集上进一步训练,其中文本仅使用英文数据。
实验结果
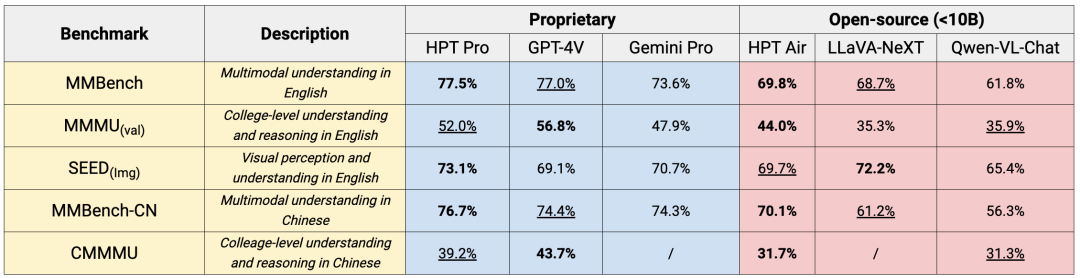
作者在多个具有挑战性的多模态基准上进行了实验,包括 MMMU、CMMMU、SEED(img)、MMBench 和 MMBench-CN。
这些基准涵盖了各种图像类别,包括图表、图解、肖像和照片,需要对大学水平的学科知识和多学科领域的推理(MMMU 和 CMMMU),或者对各种视觉和语言任务中的常识和空间理解(SEED(img)、MMBench 和 MMBench-CN)。
在许多情况下,HPT Pro 和 HPT Air 在多项基准测试中表现出色,优于 GPT-4V、Gemini Pro 和 Qwen-VL 等。例如,在 SEED(img)基准测试中,HPT Pro 在所有对比的方法里取得了最佳结果(73.1%),而 HPT Air 在性能上超过了 Qwen-VL-Chat(69.7% 比 65.4%),甚至接近 Gemini Pro 的性能水平(69.7% 比 70.7%)。
在 MMBench 和 MMBench-CN 基准测试中也可以观察到类似的结论,唯一的例外是 LLaVA-NeXT 在 SEED(img)基准测试上优于 HPT Air。
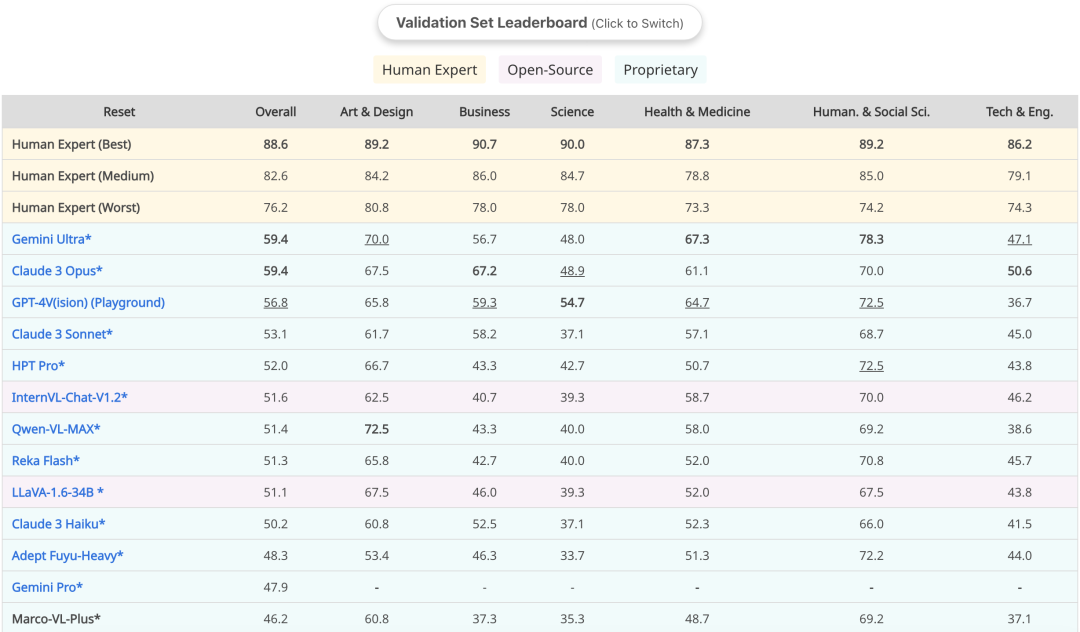
对于需要大学级学科知识和深思熟虑的 MMMU 和 CMMMU 基准测试,HPT Pro 和 HPT Air 分别是同类尺寸模型中最好的。截止至2024年3月21日,MMMU官网的验证集leaderboard如下:
据作者介绍,HPT 模型仅基于英语多模态数据进行训练,但在 Bench-CN 和 CMMMU 基准测试上的竞争表明,HPT 模型可以很好地泛到其他语言,比如中文。综合来看,HPT模型在多模态基准测试中的成绩还是非常出色的。
HPT示例效果
在一系列实际的定性示例中,展示了 HPT 的多模态能力,包括理解、推理、艺术表达等方面的能力。以下的示例均来自官方博客:
-
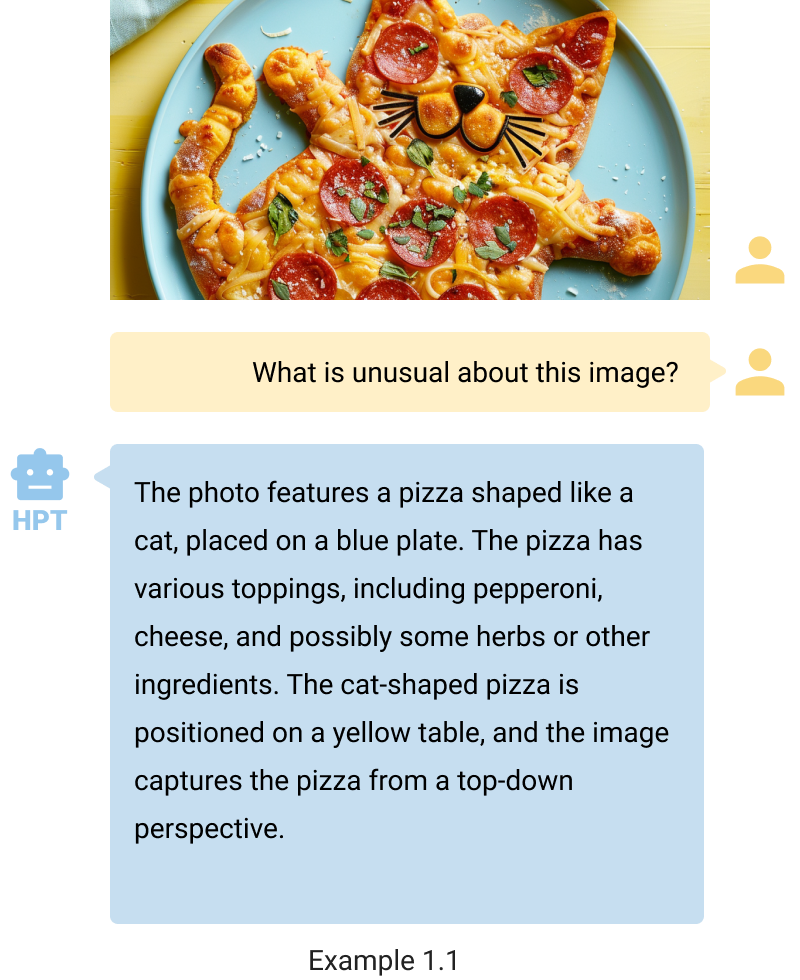
查看、描述并遵循指令 HPT可以理解和表达视觉图像的内容。尽管示例 1.1 和 1.2 中的图像具有非常规性质,但 HPT 准确地辨别了主要主题并阐明了其特征。值得注意的是,示例 1.1 与图 1 中的示例相似。HPT 可以根据用户偏好定制其描述的详细程度,在提示关键字“简短答案”时提供简洁的响应。此功能可确保 HPT 可以按照说明满足用户的需求。
|
|
|
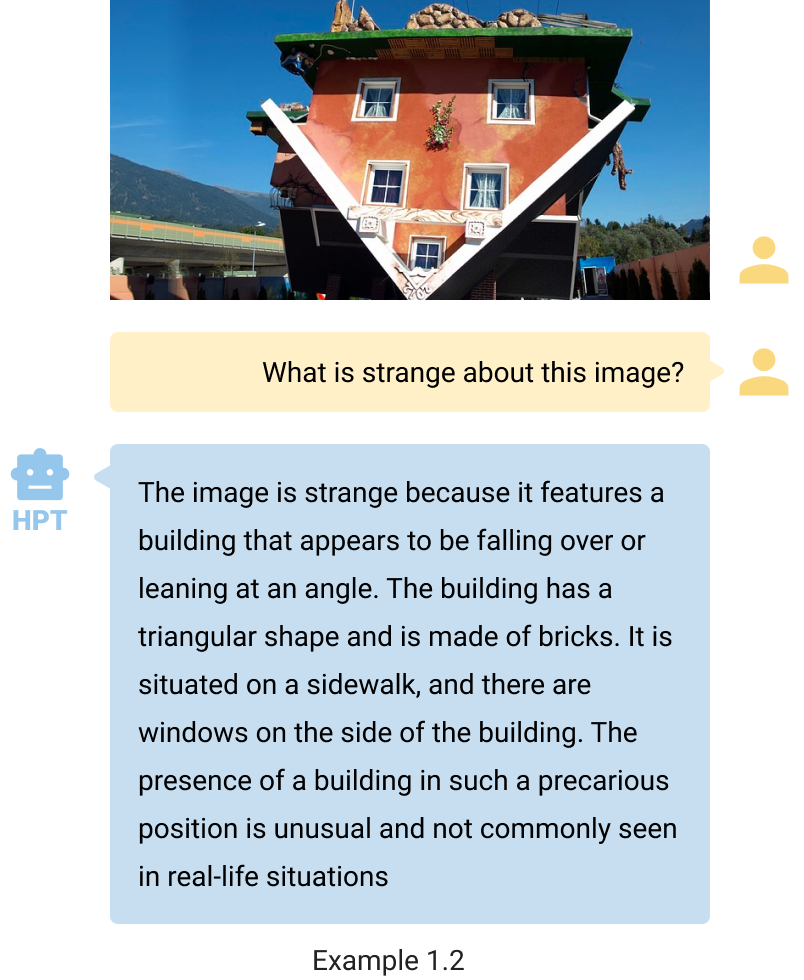
-
解释和推理。HPT 可以解释图表、图表,并回答基于所提供数据的科学问题。例如,在示例 2.1 中,HPT 演示了其识别与图表数据相对应的数字序列(76、_、68、67、58)的能力,能够通过图表分析推断出缺失的数字。在示例 2.2 中,HPT 可以回答大学水平的问题并提供正确的解释。这些例子说明了HPT从视觉数据中提取和应用信息以解决复杂问题。
|
|
|

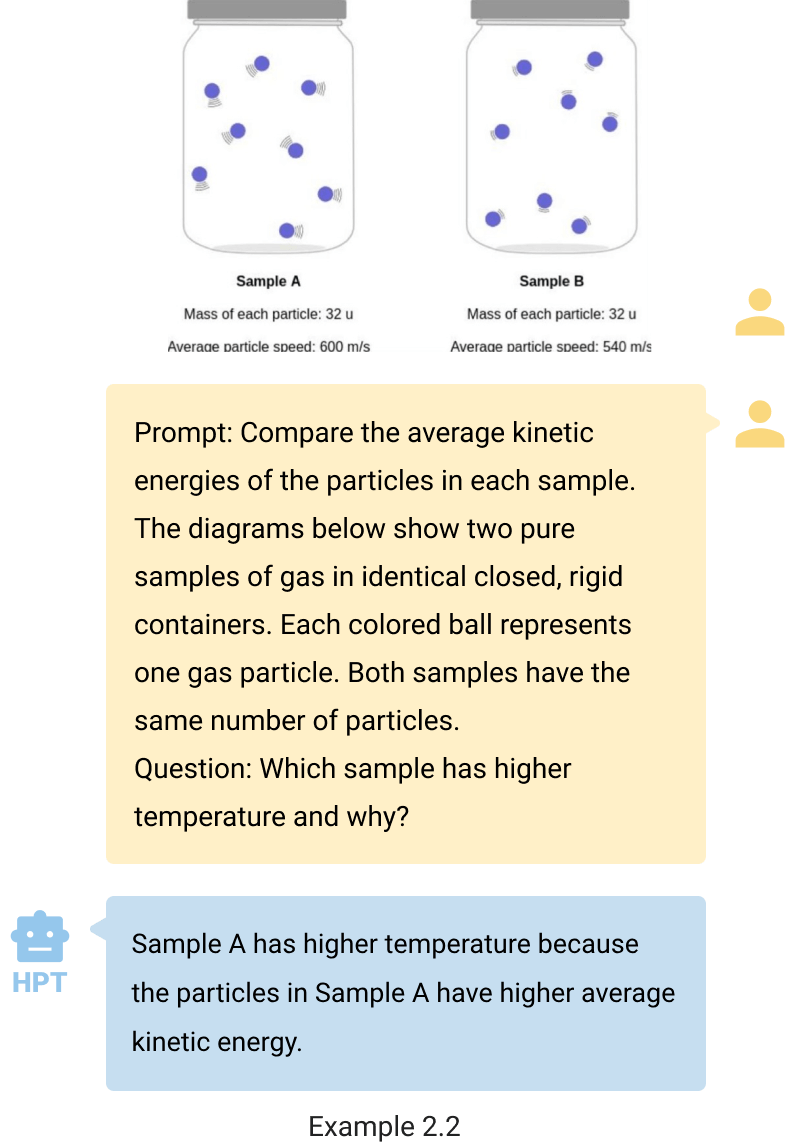
-
了解概念艺术。HPT还擅长把握艺术表现形式,准确诠释例3.1中传达的情感,并在例3.2中认识到鱼尾狮作为新加坡象征的文化意义。这种能力证明了HPT在分析和理解艺术品中复杂的视觉和概念线索方面的熟练程度。
|
|
|


-
创意。 HPT不仅理解力强,而且创造力强。如例 4.1 所示,它不仅了解在爱因斯坦时代不存在智能手机,而且还可以创造性地推测他获得现代技术的可能性。此外,HPT准确地解释了代词的引用,如第二个问题所示,它正确地将“他”识别为阿尔伯特·爱因斯坦并做出适当的回应。这凸显了HPT细致入微的理解和富有想象力的推理。HPT 还可以根据提供的图像编写有趣的小说故事,如示例 4.2 所示。
|
|
|


-
推荐和协助。HPT还可以提供有用的建议。尽管示例 5.1 中的视觉外观很棘手,但它理解图像内容,推荐可以使用此类食材烹制的菜肴,以及享用此类餐点的地方。同样,根据用户的图像,HPT 可以帮助规划下一艘游轮并提供缓解晕船的建议(示例 5.2)。这展示了HPT提供可操作的见解和有用建议以增强用户体验的能力。
|
|
|



这篇关于超越 GPT-4V 和 Gemini Pro!HyperGAI 发布最新多模态大模型 HPT,已开源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







