4v专题

MiniCPM-V: A GPT-4V Level MLLM on Your Phone
MiniCPM-V: A GPT-4V Level MLLM on Your Phone 研究背景和动机 现有的MLLM通常需要大量的参数和计算资源,限制了其在实际应用中的范围。大部分MLLM需要部署在高性能云服务器上,这种高成本和高能耗的特点,阻碍了其在移动设备、离线和隐私保护场景中的应用。 文章主要贡献: 提出了MiniCPM-V系列模型,能在移动端设备上部署的MLLM。 性能优越:

在高质量视频生成文本、图像生成文本的GLM-4V-Plus技术加持下医疗未来的方向
人工智能的进步为医疗领域带来了巨大的变革,尤其是视频生成文字、图片生成文字和医学统计数据生成文字等技术的应用。这些技术使得我们能够更全面地利用大数据来辅助诊断,为患者提供更加精确和个性化的医疗服务。以下是一些可能的应用场景和优势: 1. 多模态数据整合 这三种方法都利用AI技术为医学领域提供强有力的支持,从而提高医疗质量和效率。下面是这些方法的具体作用和潜在影响: 视频生成文字: 作用:通

HTN7862 4V~65V输入,2.8A异步降压变换器
1、特点 2.8A降压,内置260mΩ功率管 输入电压范围:4V~65V 脉冲跳跃模式使得轻载下高效率 ·110uA静态电流 最高2MHZ可编程开关频率 峰值电流控制架构 欠压保护、过流保护和过热关断保护 无铅封装,ESOP8 2、应用 ·12V,24V,48V工业和电信电源轨系统 ·汽车系统 分布式电源系统 高压电源转换 3、概述 HTN7862是2.8A降压转换器,具有从4
GPT-4V 和 Gemini对比
GPT-4V 和 Gemini 的原理及对比 GPT-4V和Gemini都是当代领先的多模态AI模型,但它们在设计原理、实现方法和应用场景上有一些显著的区别。下面将详细解释这些模型的原理,并比较它们的优缺点。 GPT-4V 的原理 GPT-4V 是 OpenAI 开发的 GPT-4 的多模态版本,具有处理文本和图像的能力。以下是它的核心原理: Transformer 架构: GPT-

GLM-4开源版本终于发布!!性能超越Llama3,多模态媲美GPT-4V,MaaS平台全面升级
今天上午,在 AI 开放日上,备受关注的大模型公司智谱 AI 公布了一系列行业落地数据: 根据最新统计,智谱 AI 大模型开放平台目前已拥有 30 万注册用户,日均调用量达到 4000 亿 Tokens。GPT-4o深夜发布!Plus免费可用!https://www.zhihu.com/pin/1773645611381747712 没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几
【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
目录 一、引言 二、模型简介 2.1 GLM4-9B 模型概述 2.2 GLM4-9B 模型架构 三、模型推理 3.1 GLM4-9B-Chat 语言模型 3.1.1 model.generate 3.1.2 model.chat 3.2 GLM-4V-9B 多模态模型 3.2.1 多模态模型概述 3.2.2 多模态模型实践 四、总结 一、引

维修Philips IU22飞利浦四维多普勒彩超诊断仪 V6-2 L12-5 C8-4V深圳捷达工控维修
专为新时代而设计。专为更多而设计。 超声波在抗击 COVID-19 中的成像作用不断扩大,并且对血管和心脏检查的需求不断增加,因此比以往任何时候都更有价值。飞利浦的超声产品组合(包括 EPIQ Elite)为一线护理人员提供了宝贵的诊断支持。 飞利浦 iU22 一经推出,就在通用成像超声领域树立了新标准。飞利浦 EPIQ Elite 系统建立在这段丰富的历史之上,不断突破界限,应对优质超声不断

InternVL——GPT-4V 的开源替代方案
您的浏览器不支持 video 标签。 在人工智能领域,InternVL 无疑是一颗耀眼的新星。它被认为是最接近 GPT-4V 表现的可商用开源模型,为我们带来了许多惊喜。 InternVL 具备强大的功能,不仅能够处理图像和文本数据,还能精妙地理解它们之间的复杂关系。比如,它可以准确地识别图像中的对象,并与相关描述对应起来。在 OCR 和文档理解方面,这款模型更是表现出色,能够有效

每日论文推荐:我们距离GPT-4V有多远,最接近GPT-4V的开源多模态大模型
📌 元数据概览: 标题:How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites作者:Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, K

超越GPT-4V!马斯克发布Grok-1.5 With Vision
在 Grok-1 开源后不到一个月,xAI 的首个多模态模型就问世了。Grok-1.5V是XAI的第一代多模态模型,除了其强大的文本处理能力之外,Grok现在还能够处理包括文档、图表、图形、屏幕截图和照片在内的各种视觉信息。相信Grok-1.5V将很快提供给现有的Grok用户和早期测试者来使用。 功能 Grok-1.5V在多个领域与现有的前沿多模态模型具有竞争力,这些领域包括跨学科推理、理解文

【AIGC调研系列】Grok-1.5v与Gpt-4v的效果对比
Grok-1.5V与GPT-4V的效果对比中,Grok-1.5V在多个领域和基准测试中表现优于GPT-4V。具体来说,Grok-1.5V在多学科推理、文档理解、科学图表处理等方面表现出色[1]。它还特别强调了其在理解物理世界的能力上的优势[4][8][12],并且在RealWorldQA基准测试中也优于GPT-4V[1]。此外,Grok-1.5V被描述为一种多模态模型,能够在理解和处理文本的同时,

HPT发布HyperGAI 多模态大模型:性能领先GPT-4V,全面胜过Gemini Pro
前言 HyperGAI研究团队自豪地宣布推出HPT——新一代领先的多模态大型语言模型(Multimodal Large Language Model, Multimodal LLM)。作为人工通用智能(Artificial General Intelligence, AGI)构建的基石,HPT跨入多模态理解的新时代奠定了基础。与传统的仅文本LLM不同,多模态LLM旨在理解包括文本、图像、视频等在

超越 GPT-4V 和 Gemini Pro!HyperGAI 发布最新多模态大模型 HPT,已开源
随着AI从有限数据迈向真实世界,极速增长的数据规模不仅赋予了模型令人惊喜的能力,也给多模态模型提供了更多的可能性。OpenAI在发布GPT-4V时就已经明确表示: 将额外模态(如图像输入)融入大语言模型(LLMs)被认为是 AI 研究和发展的一个关键新领域。 昨天,HyperGAI 研究团队推出了 HPT(Hyper-Pretrained Transformers)系列,包含两个模型,H

惊艳!2.77亿参数锻造出Agent+GPT-4V模型组合,领航AI领航机器人、游戏、医疗革新,通用智能时代你准备好了吗?
更多内容迁移知乎账号,欢迎关注:https://www.zhihu.com/people/dlimeng 斯坦福、微软、UCLA的顶尖学者联手,推出了一个全新交互式基础代理模型! 这个模型能处理文本、图像、动作输入,轻松应对多任务挑战,甚至跨界在机器人、游戏、医疗等领域展现强大实力。 注意:LangChain Agent主要增强基于语言的互动能力,而交互式代理基础模型寻求统一多模态输入,
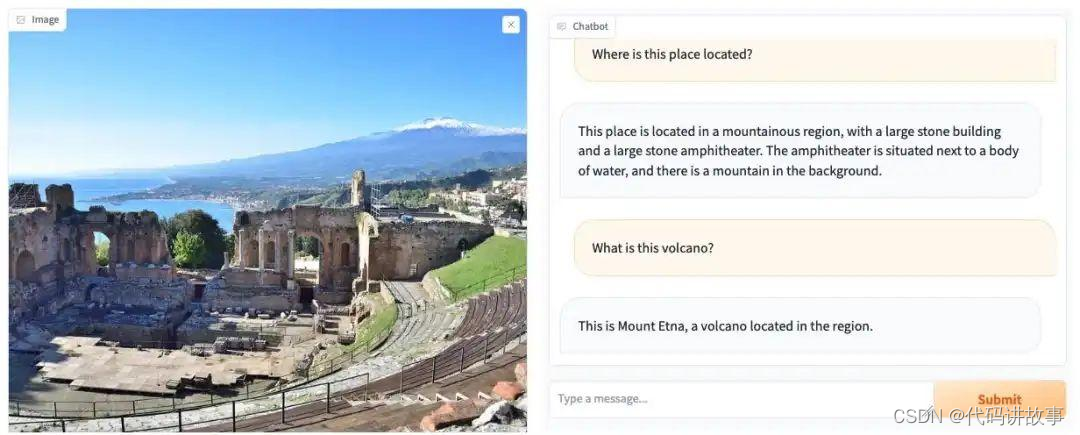
LLaVA:GPT-4V(ision) 的新开源替代品
LLaVA:GPT-4V(ision) 的新开源替代品。 LLaVA (https://llava-vl.github.io/,是 Large Language 和Visual A ssistant的缩写)。它是一种很有前景的开源生成式 AI 模型,它复制了 OpenAI GPT-4 在与图像对话方面的一些功能。 用户可以将图像添加到 LLaVA 聊天对话中,可以以聊天方式讨论这些图像的内
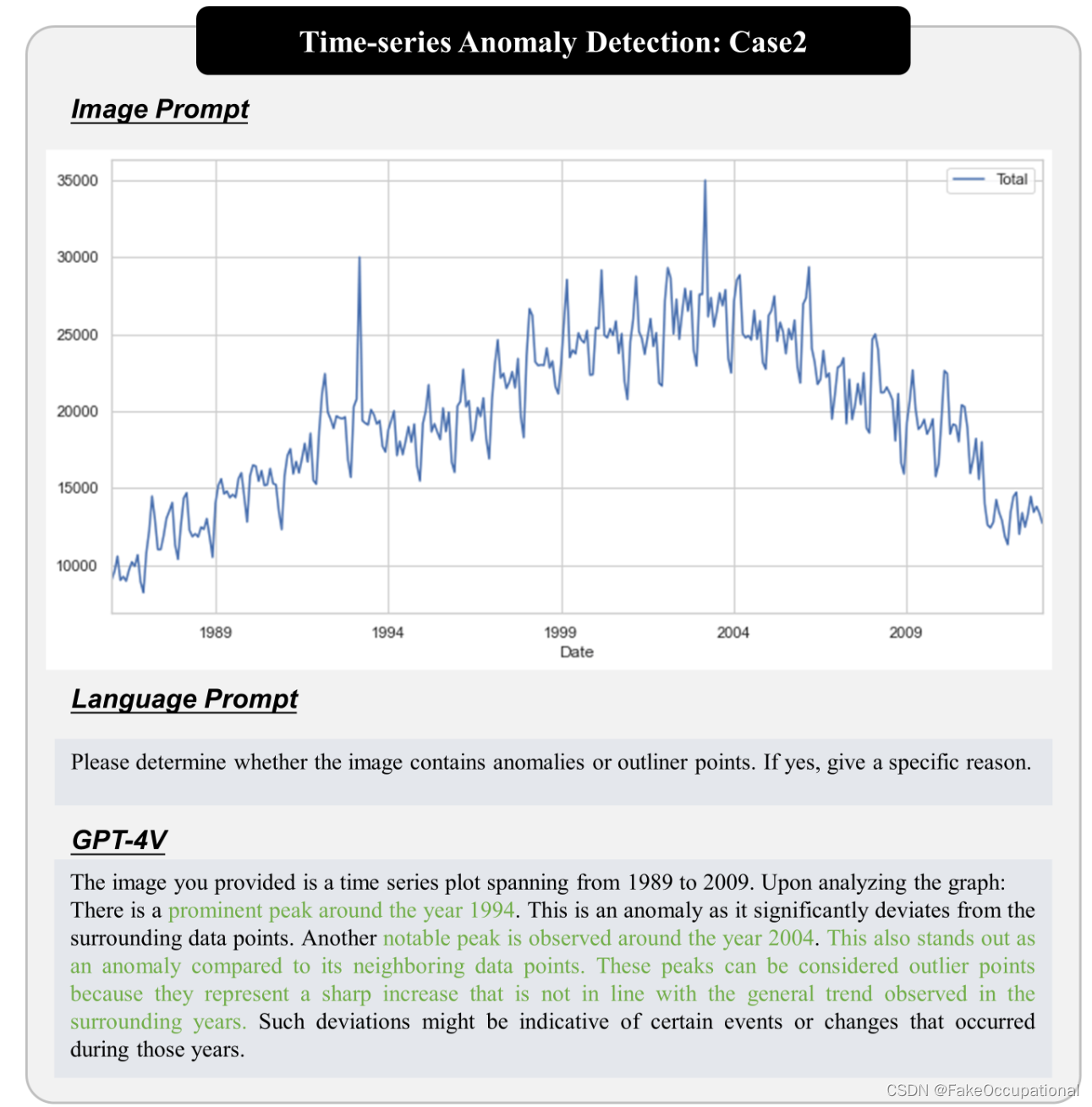
迈向通用异常检测和理解:大规模视觉语言模型(GPT-4V)率先推出
PAPERCODEhttps://arxiv.org/pdf/2311.02782.pdfhttps://github.com/caoyunkang/GPT4V-for-Generic-Anomaly-Detection 图1 GPT-4V在多模态多任务异常检测中的综合评估 在这项研究中,我们在多模态异常检测的背景下对GPT-4V进行了全面评估。我们考虑了四种模式:图像、视频
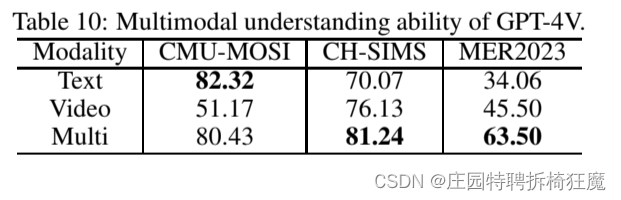
GPT-4V with Emotion:A Zero-shot Benchmark forMultimodal Emotion Understanding
GPT-4V with Emotion:A Zero-shot Benchmark forMultimodal Emotion Understanding GPT-4V情感:多模态情感理解的zero-shot基准 1.摘要 最近,GPT-4视觉系统(GPT-4V)在各种多模态任务中表现出非凡的性能。然而,它在情感识别方面的功效仍然是个问题。本文定量评估了GPT-4V在多通道情感理解方

GPT-4V 在机器人领域的应用
在科技的浩渺宇宙中,OpenAI如一颗璀璨的星辰,于2023年9月25日,以一种全新的方式,向世界揭示了其最新的人工智能力作——GPT-4V模型。这次升级,为其旗下的聊天机器人ChatGPT装配了语音和图像的新功能,使得用户们有了更为丰富和生动的交互方式,仿佛打开了一扇通向未来的大门。 据OpenAI的官方描述,这次的更新将使得ChatGPT为用户提供更为直接和生动的体验。在过去,人们与人工智能
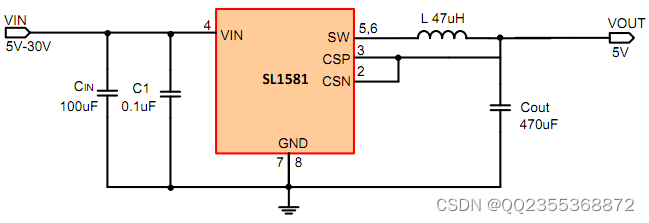
SL1581降压恒压 耐压4V-30V降压5V 2A电流 外围简单,四个元器件
SL1581是一款专为降压恒压应用而设计的芯片,具有耐压4V-30V、降压5V、2A电流输出等特点,外围电路简单,仅需四个元器件。 一、芯片介绍 SL1581是一款专为降压恒压应用而设计的芯片,它采用先进的PWM控制技术,具有高效率、低噪音、小体积、高可靠性等特点。该芯片可以适应4V-30V的输入电压范围,输出电压稳定在5V,最大输出电流为2A。此外,SL1581还具有过热保护和过流保护等功能,确
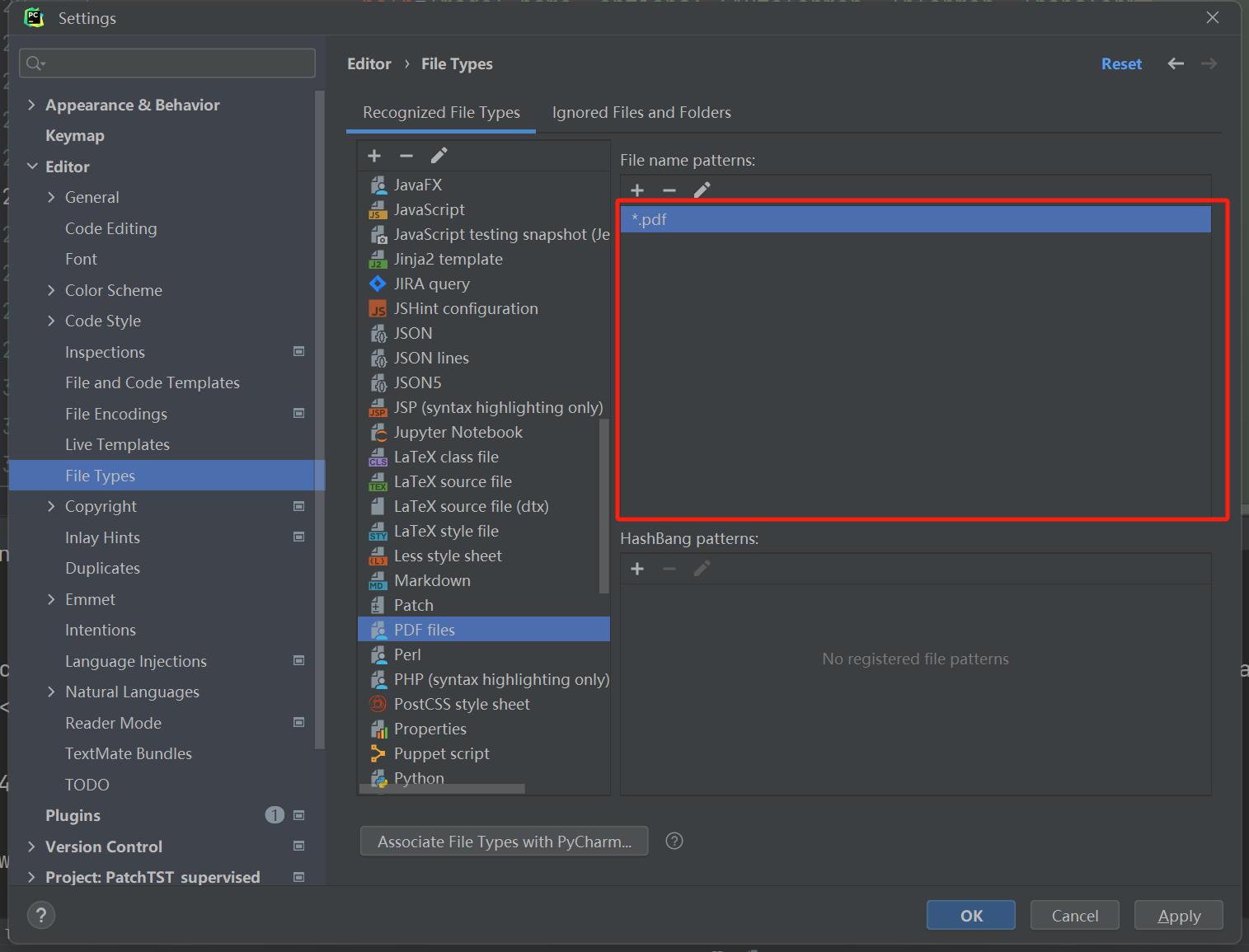
使用GPT-4V解决Pycharm设置问题
pycharm如何实现关联,用中文回答 在PyCharm中关联PDF文件类型,您可以按照以下步骤操作: 1. 打开PyCharm设置:点击菜单栏中的“File”(文件),然后选择“Settings”(设置)。 2. 在设置窗口中,导航到“Editor”(编辑器)部分。 3. 在“Editor”下面,找到并点击“File Types”(文件类型)。 4. 在“File Type

新王加冕,GPT-4V 屠榜视觉问答
当前,多模态大型模型(Multi-modal Large Language Model, MLLM)在视觉问答(VQA)领域展现了卓越的能力。然而,真正的挑战在于知识密集型 VQA 任务,这要求不仅要识别视觉元素,还需要结合知识库来深入理解视觉信息。 本文对 MLLM,尤其是近期提出的 GPT-4V,从理解、推理和解释等方面进行了综合评估。结果表明,当前开源 MLLM 的视觉理解能力在很大程度上
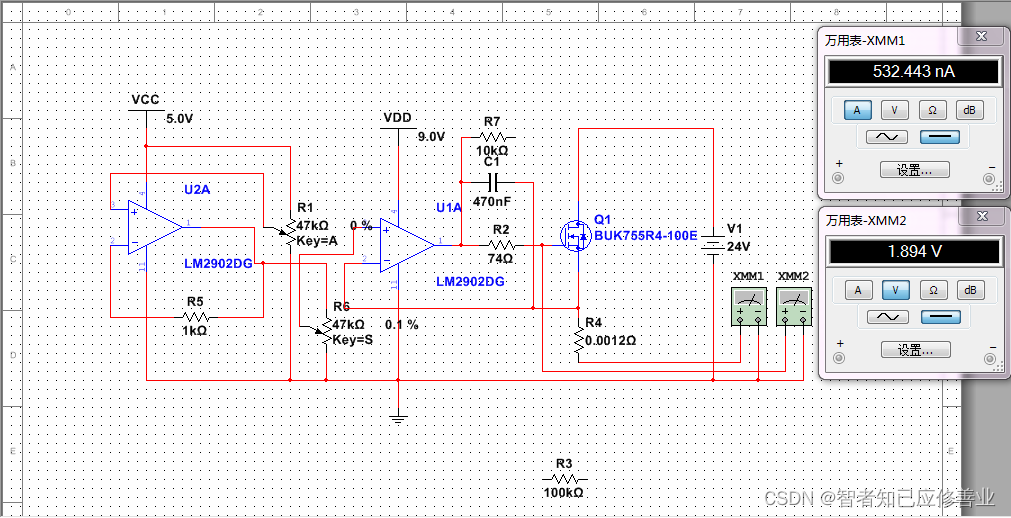
【用运算放大器设计恒流电流源电压4V-74V适应范围 】2021-11-29
缘由用运算放大器设计恒流电流源-编程语言-CSDN问答直流恒流源设计,要求用到运算放大器-硬件开发-CSDN问答求助恒流驱动电路,运放端口电压的问题? - 电路设计论坛 - 电子技术论坛 - 广受欢迎的专业电子论坛!(不能实现恒流坏的电路设计反面例子) 缘由 有关运放输出问题,求解答 - 电路设计论坛 - 电子技术论坛 - 广受欢迎的专业电子论坛!
【用运算放大器设计恒流电流源电压4V-74V适应范围 】2021-11-29
缘由用运算放大器设计恒流电流源-编程语言-CSDN问答直流恒流源设计,要求用到运算放大器-硬件开发-CSDN问答求助恒流驱动电路,运放端口电压的问题? - 电路设计论坛 - 电子技术论坛 - 广受欢迎的专业电子论坛!(不能实现恒流坏的电路设计反面例子) 缘由 有关运放输出问题,求解答 - 电路设计论坛 - 电子技术论坛 - 广受欢迎的专业电子论坛!
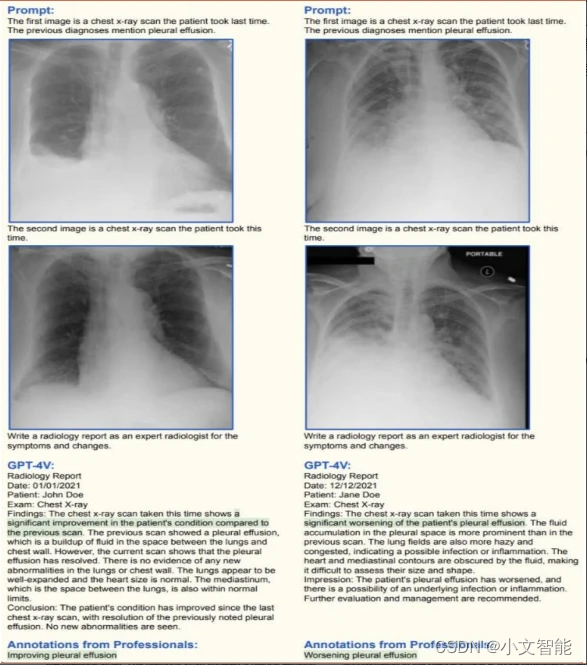
GPT-4V:AI在医疗领域的应用
OpenAI最新发布的GPT-4V模型为ChatGPT增添了语音和图像功能,为用户提供了更多在日常生活中使用ChatGPT的方式。这次更新将为用户带来更加便捷、直观的交互体验,用户可以直接通过拍照上传图片,并提出相关问题。OpenAI的最终目标是构建一个安全、有益的人工通用智能(AGI),因此他们将逐步推出语音和图像功能,并随着时间的推移不断改进和完善系统的风险。 GPT-4V模型在医疗领域的
An Early Evaluation of GPT-4V(ision)
本文是LLM系列文章,针对《An Early Evaluation of GPT-4V(ision)》的翻译。 GPT-4V的早期评估 摘要1 引言2 视觉理解3 语言理解4 视觉谜题解决5 对其他模态的理解6 结论 摘要 在本文中,我们评估了GPT-4V的不同能力,包括视觉理解、语言理解、视觉解谜以及对深度、热、视频和音频等其他模式的理解。为了评估GPT-4V的性能,我们手动构

别再吹 GPT-4V 了!连北京烤鸭都不认识,你敢信??
夕小瑶科技说 原创 作者 | 智商掉了一地、ZenMoore GPT-4 被吹的神乎其神,作为具备视觉能力的 GPT-4 版本——GPT-4V,也被大众寄于了厚望。但如果告诉你,GPT-4V 连图片上的“北京烤鸭”和“广西烤鸭”都分不清楚,你是否觉得大跌眼镜?? 有图有证据!! Prompt 是:图片中是否有“北京烤鸭”? 结果 GPT-4V 和 LLaVa-1.5 都面向