本文主要是介绍五分钟掌握CloudCanal的数据校验与数据订正,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简述
CloudCanal除了提供最核心的数据迁移和同步能力以外,还提供数据校验和数据订正两种非常实用的能力。这两种功能为用户保障数据迁移同步链路的数据质量提供了非常大的便利性。例如对端数据库因为各种原因产生一些异常写入导致的数据不一致或者丢失,用户均可以使用CloudCanal提供的数据校验和数据订正能力来基于同步链路的源端数据来恢复数据,使得对端数据库中相比源端丢失或者不一致的数据得到恢复。
技术点
基于校验结果的针对性订正
执行完CloudCanal的校验任务后,在运行任务的机器上会生成一个文件compre_rs.log用于记录校验的结果信息。日志路径为~/logs/cloudcanal/tasks/${taskName}/compare_rs.log,其格式如下:
{库表名称,结果类型,主键信息}
{"tableUnit":"test15.test_huasheng1","type":"DIFF","pkColMap":{"id":"9"}}
{"tableUnit":"test15.test_huasheng1","type":"LOSS","pkColMap":{"id":"12"}}
结果类型分为两种:
- DIFF:对端相比源端不一致的行,例如上面例子中,源端主键id=9的行和对端存在不一致。
- LOSS:在源端表中存在,但是在对端表中不存在的行。上面例子中源端主键id=12的行,在对端不存在
主键信息记录的是源端的,支持联合主键。
为了性能考虑,这里DIFF时不展示具体哪一列的数据不一致。如果需要查看这个信息,这个数据信息记录在~/logs/cloudcanal/tasks/${taskName}/diff.log中
利用数据库的upsert能力进行订正
针对支持upsert语义写入的数据源作为对端时,CloudCanal的订正可以正常工作。CloudCanal根据校验结果去源端反查数据后写入对端,如果对端不存在该主键的行,则直接INSERT写入,如果存在则自动转换为UPDATE进行更新。
使用in multi column处理联合主键的情况
针对实现SQL标准中in multi column语法的数据库作为源端时,CloudCanal支持对其进行数据订正。CloudCanal根据主键扫描源端表时,如遇联合主键的场景,会根据in multi column的语法来扫描源端的数据。不支持in multi column SQL语法的数据源CloudCanal不支持订正其数据。in multi column语法的使用例子可以参考如下:
-- works in PostgreSQL, Oracle, MySQL, DB2, HSQLDB
SELECT whatever
FROM t --- you missed the FROM
WHERE (col1, col2) --- parentheses hereIN ((val1a, val2a), (val1b, val2b), ...) ;
使用须知
- 以下源端、对端之间支持创建订正任务:
- 源端:Oracle、PostgreSQL、MySQL、OceanBase、PolarDBMySQL
- 对端: MySQL、PolarDBMySQL、Oracle、PostgreSQL、OceanBase
- 支持该特性的CloudCanal版本:v2.2.6.8(商业版)
- 订正是以源端数据为准:校验结果中会记录对端相比源端缺失、不一致的行的源端主键信息。订正则会基于该源端主键进行订正。假设对端多出了一些源端不存在的主键,在订正的时候CloudCanal是不会去删除这些行的请知悉。
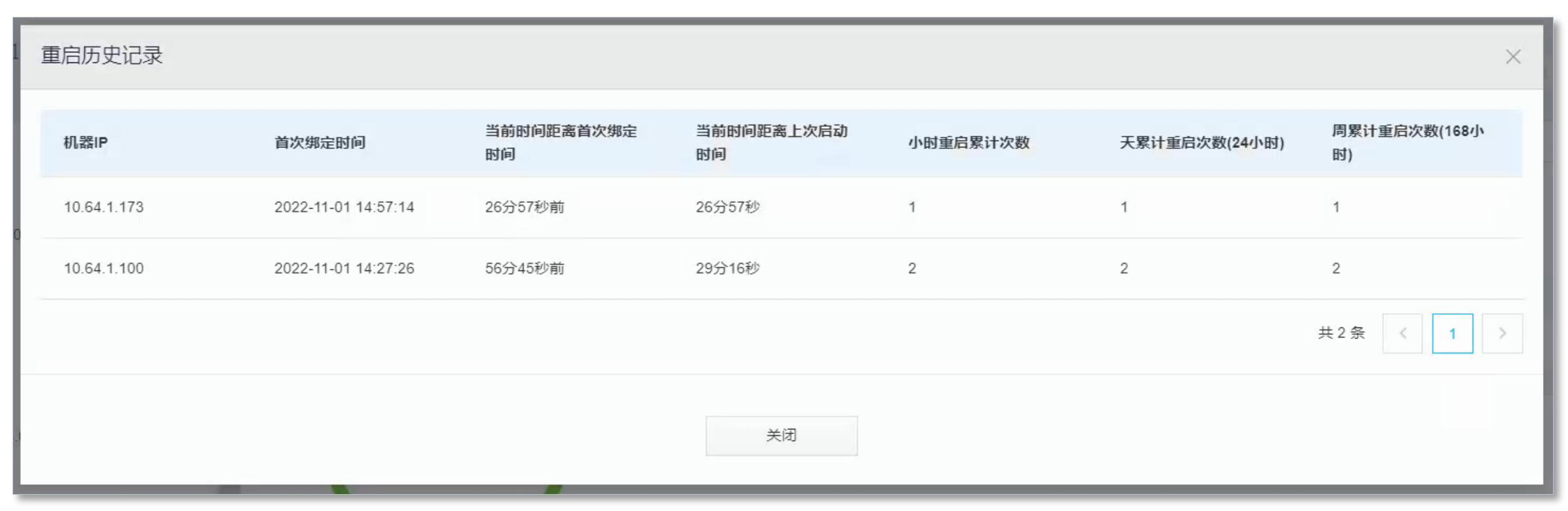
- 基于校验结果的订正依赖校验任务的校验结果文件,因此当关联的校验任务在不同机器上执行过的话,则无法基于该校验任务创建订正任务。在校验任务详情,点击功能列表->重启历史记录 可以查看校验任务是否在多台机器上运行过。
操作说明
前置条件
- 登入 CloudCanal SaaS版或者申请CloudCanal商业版试用,使用参见快速上手文档
- 准备两个支持数据订正的数据库,一个作为源端,一个作为对端。本次例子采用的源对端数据源类型为阿里云的PolarDBMySQL
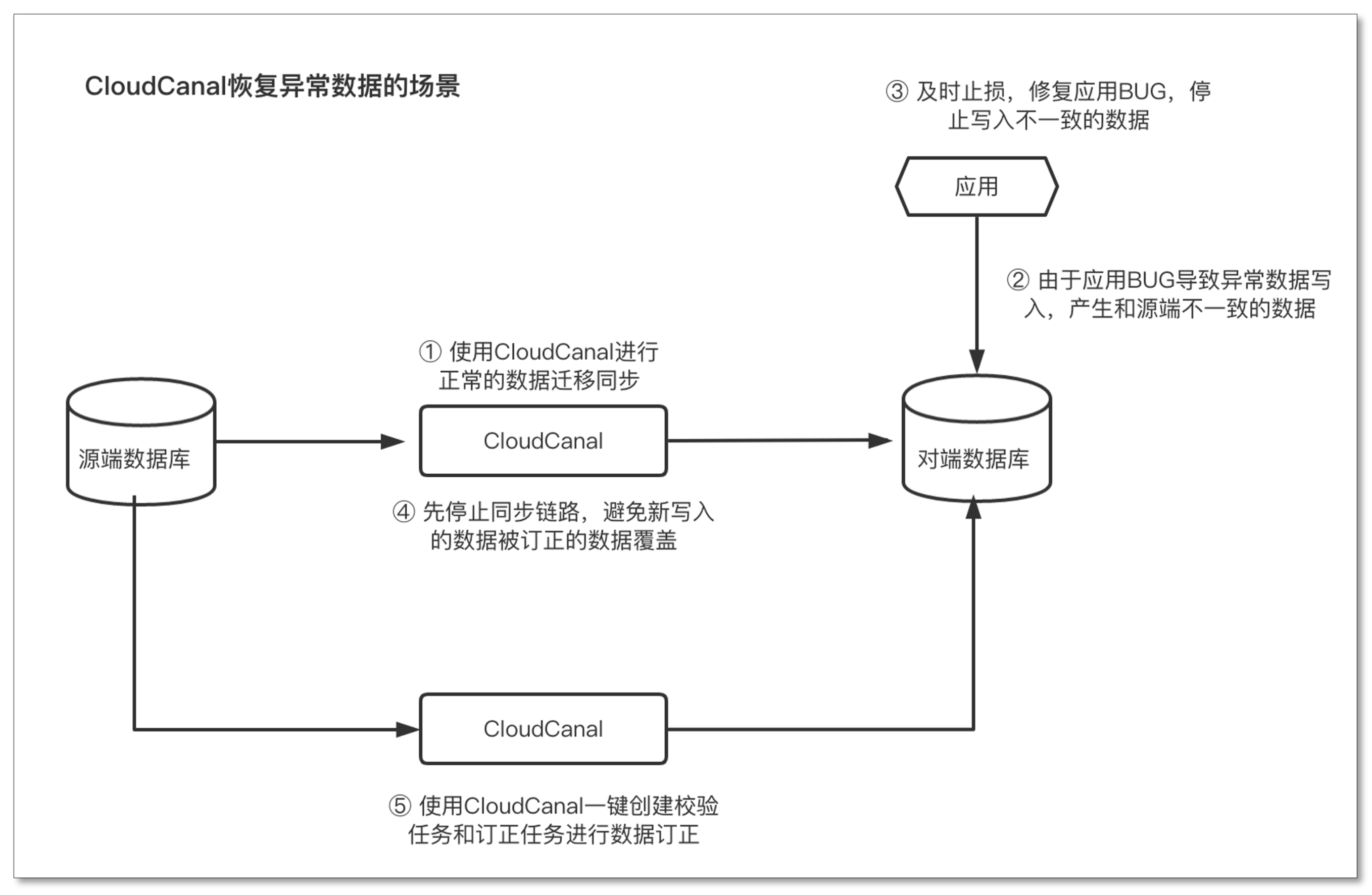
校验订正的基本流程
使用CloudCanal的校验订正能力恢复异常数据的典型流程如下图所示。
数据校验
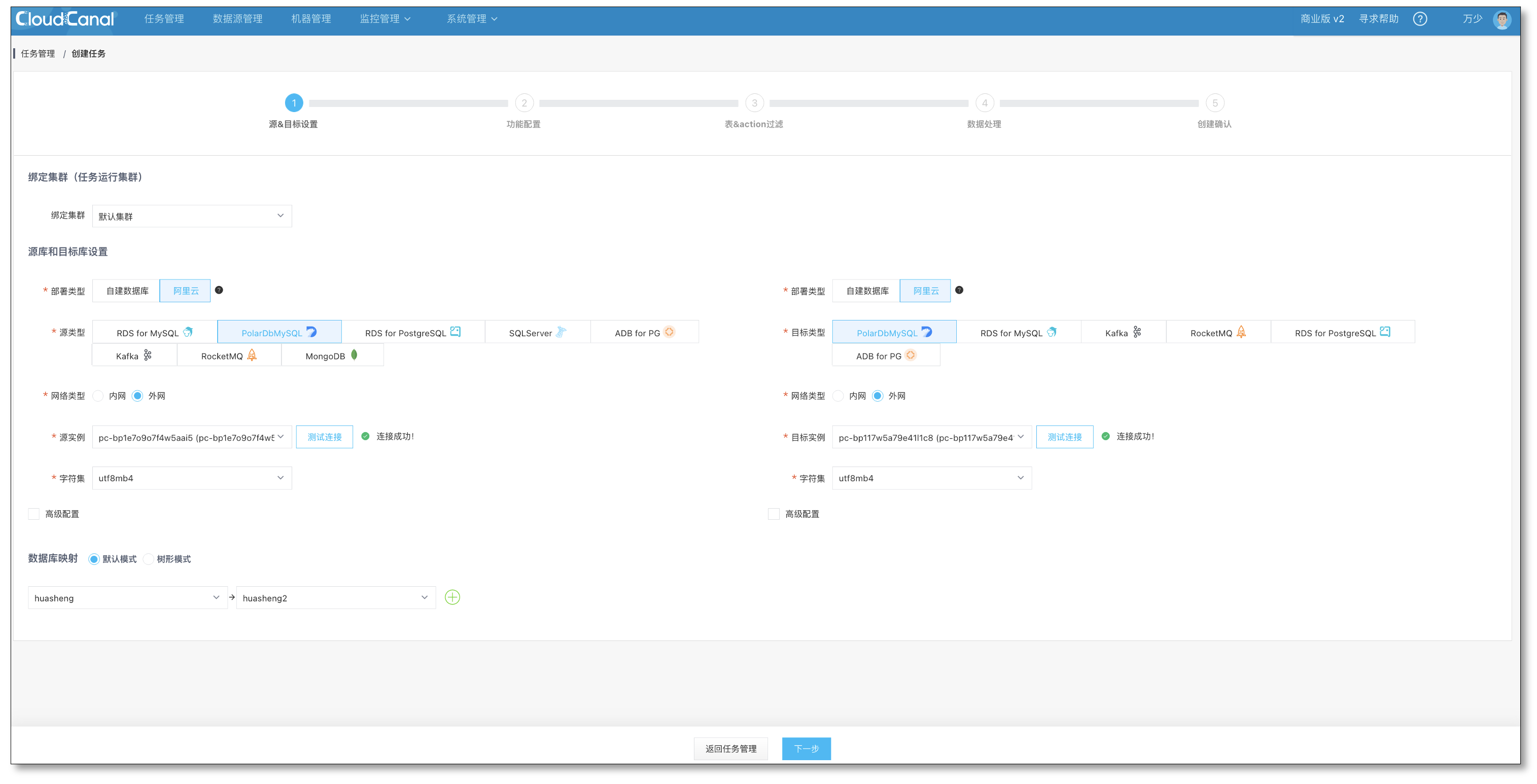
- 在任务管理页点击创建任务,进入创建任务的第一步,配置源对端的数据库并且选择需要订阅的库。
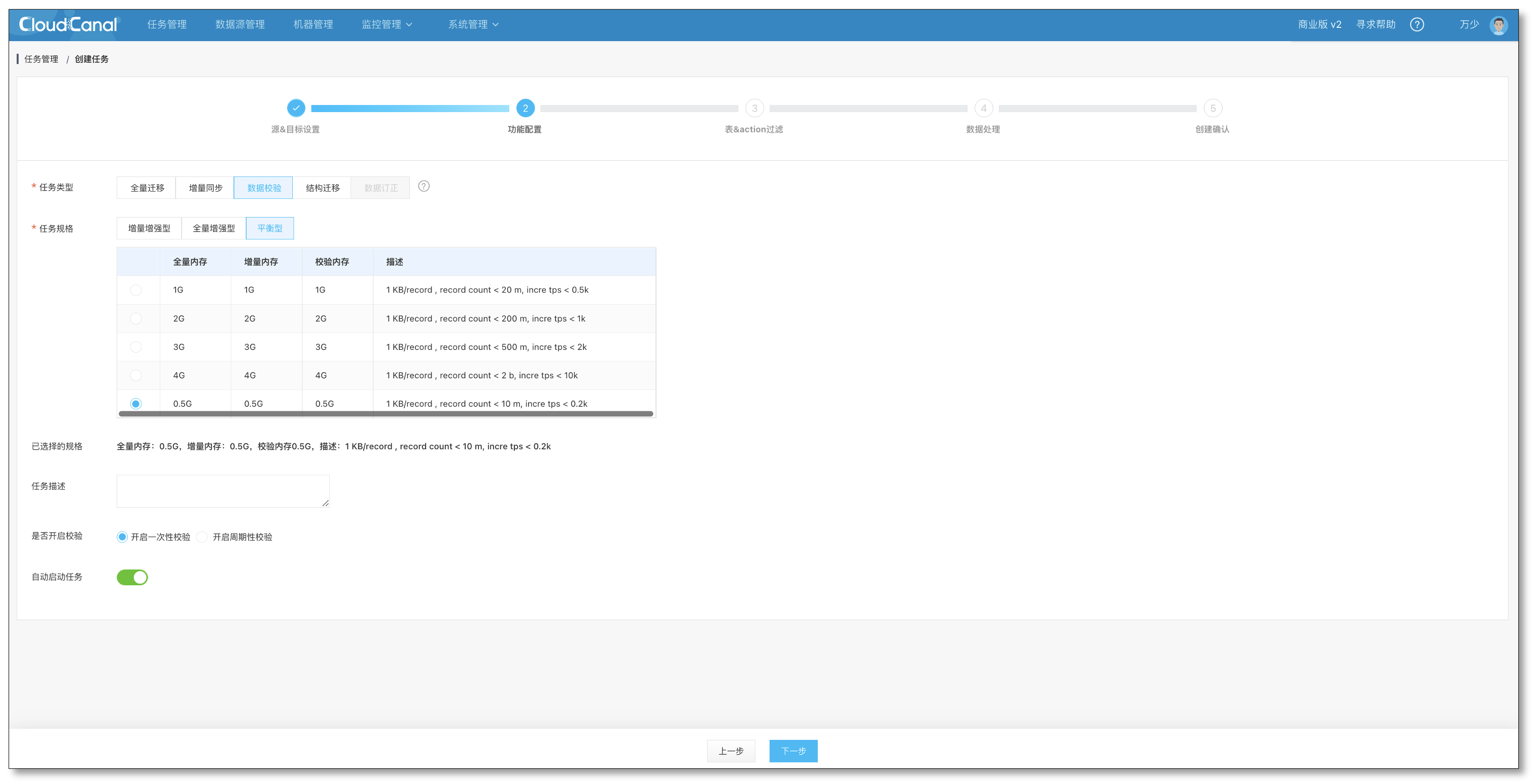
- 选择任务类型为校验,开启一次性校验,设置自动启动。
- 选择需要进行校验的表。
- 选择需要进行校验的列,支持映射和裁剪。裁剪的列将不参与校验。
- 确认任务整体配置情况,无误后点击创建
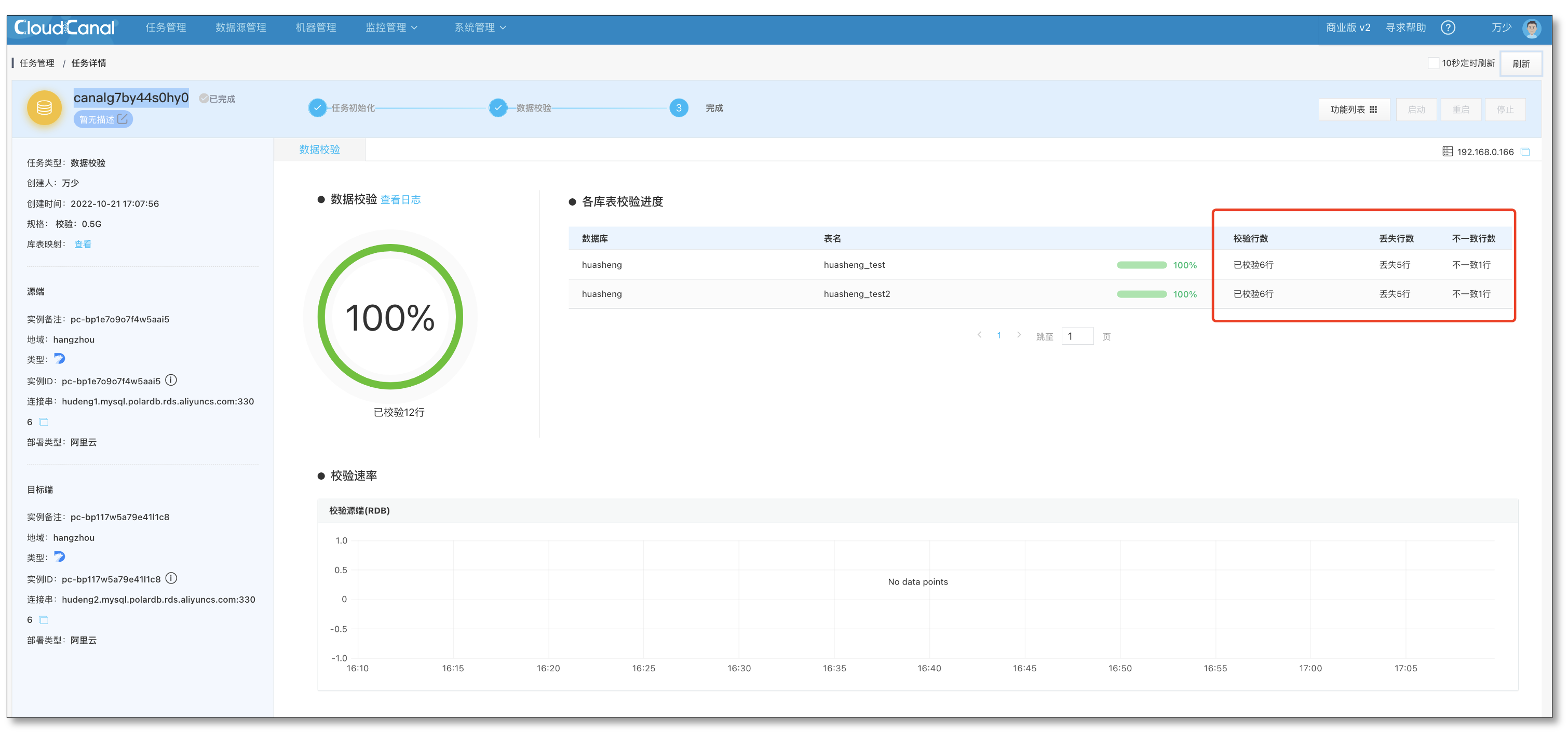
- 校验完成后可以查看具体每张表相比源端缺失或者不一致的数据。
数据订正
- 从校验任务的详情页,点击功能列表中的创建订正任务可以直接基于该次校验的结果,创建对应表的订正任务。
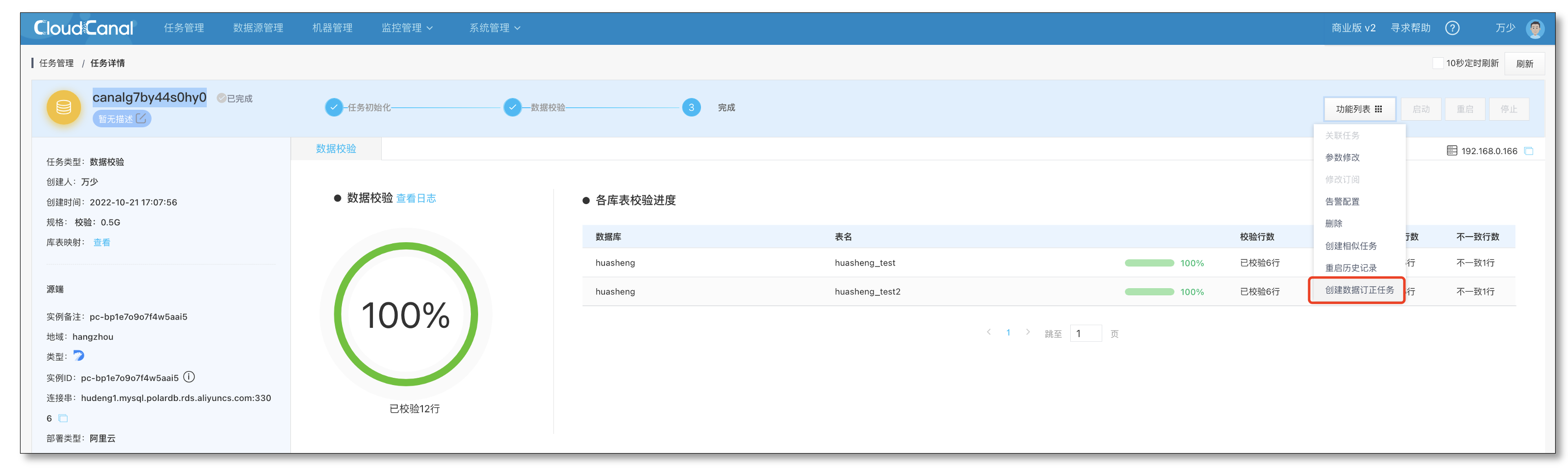
- 订正任务的源对端信息和订阅的库信息与之前的校验任务保持一致,此处源对端测试连接成功后可直接点击下一步。
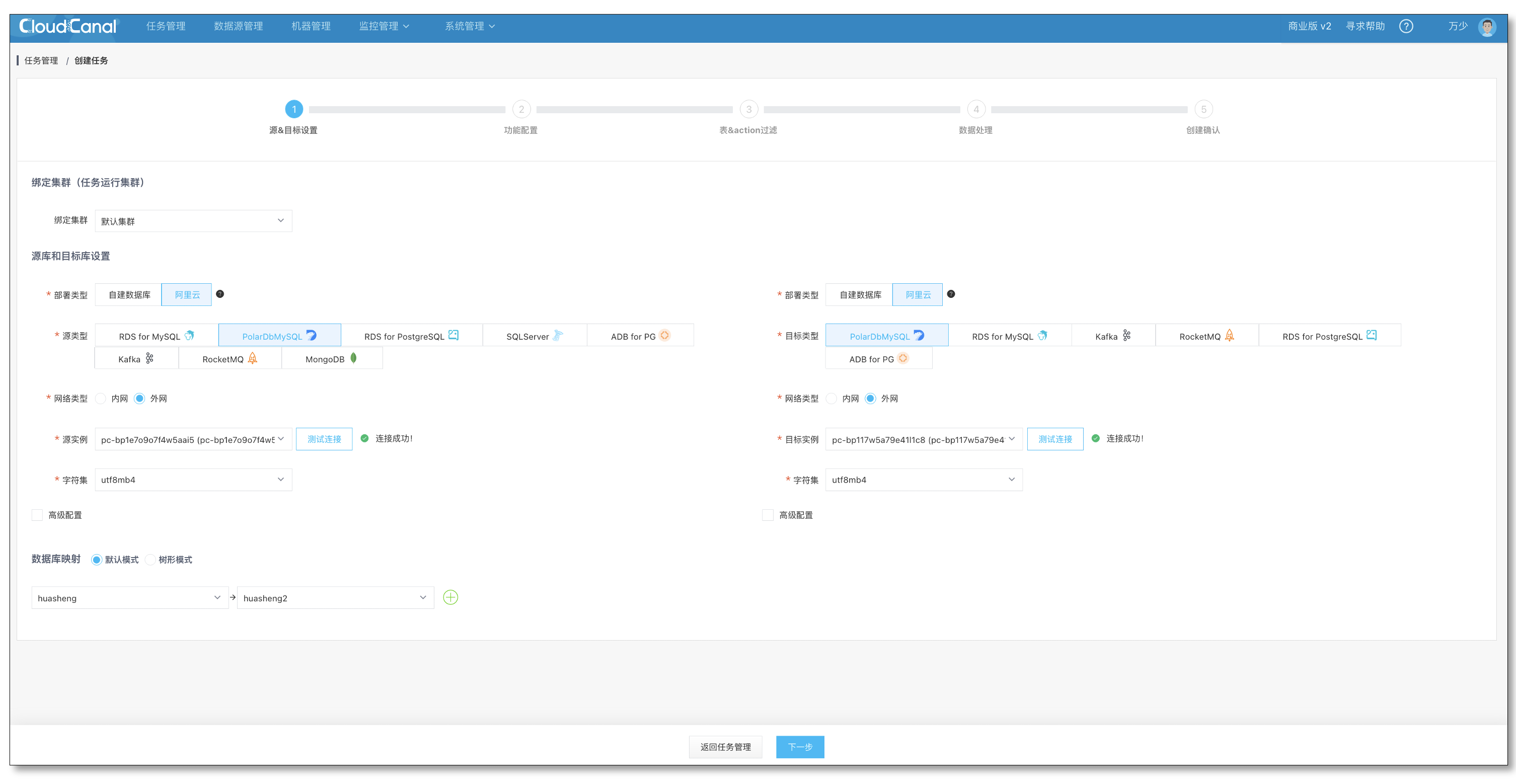
- 规格与校验任务保持一致,可以直接下一步
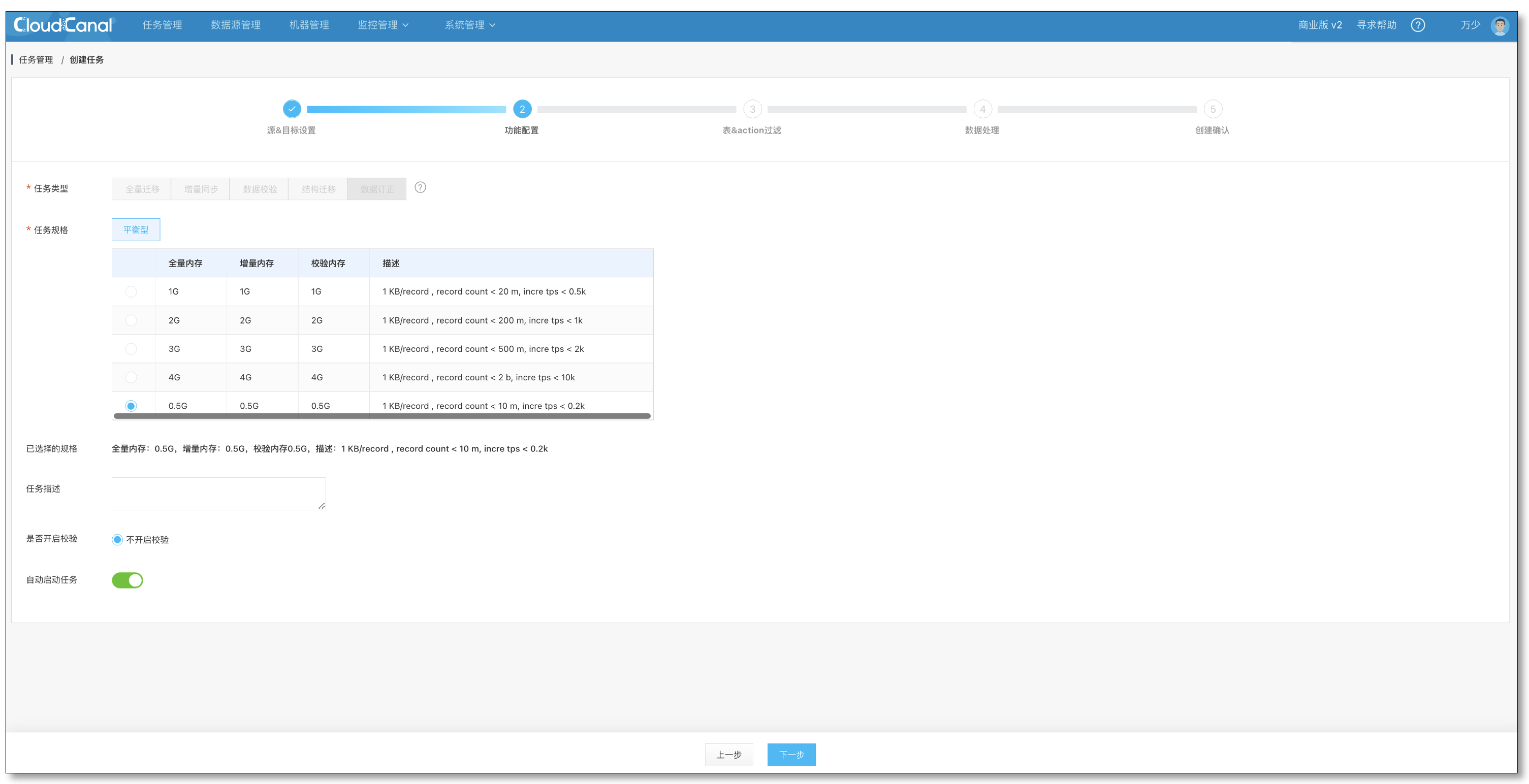
- 订阅信息仅供确认,无法修改,与校验任务保持一致,直接点击下一步
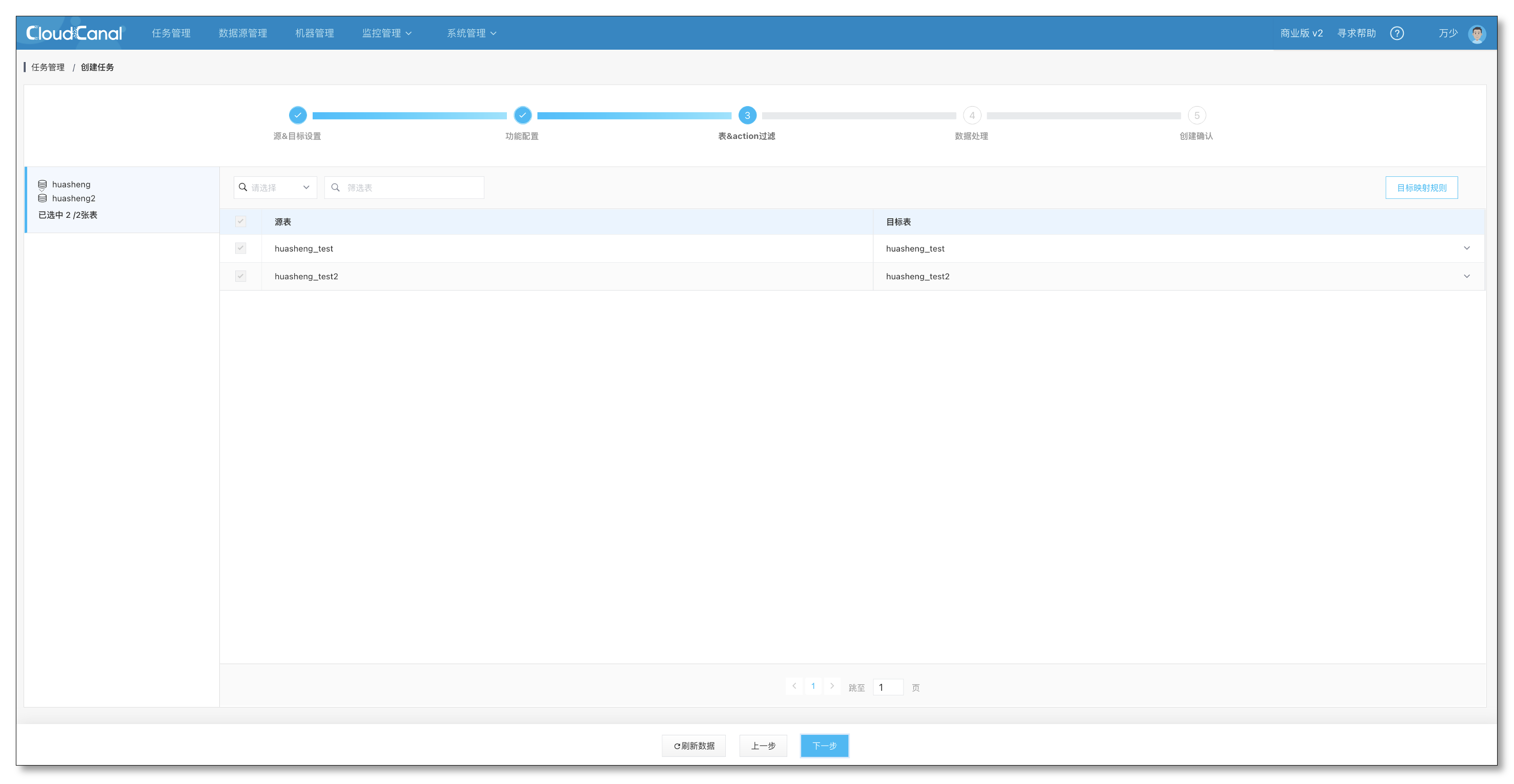
- 确认列的映射、裁剪信息,无法修改,与校验任务保持一致,直接点击下一步
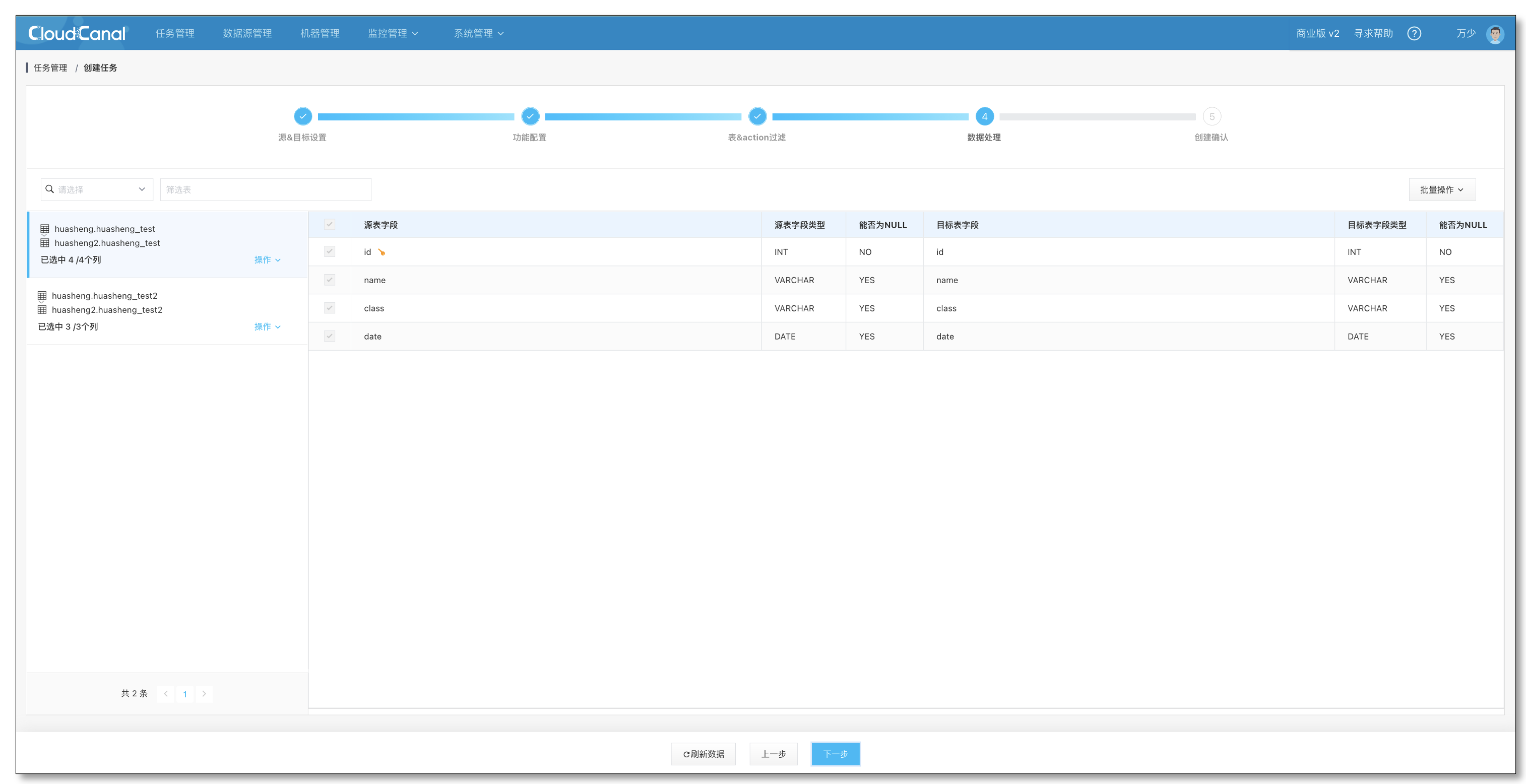
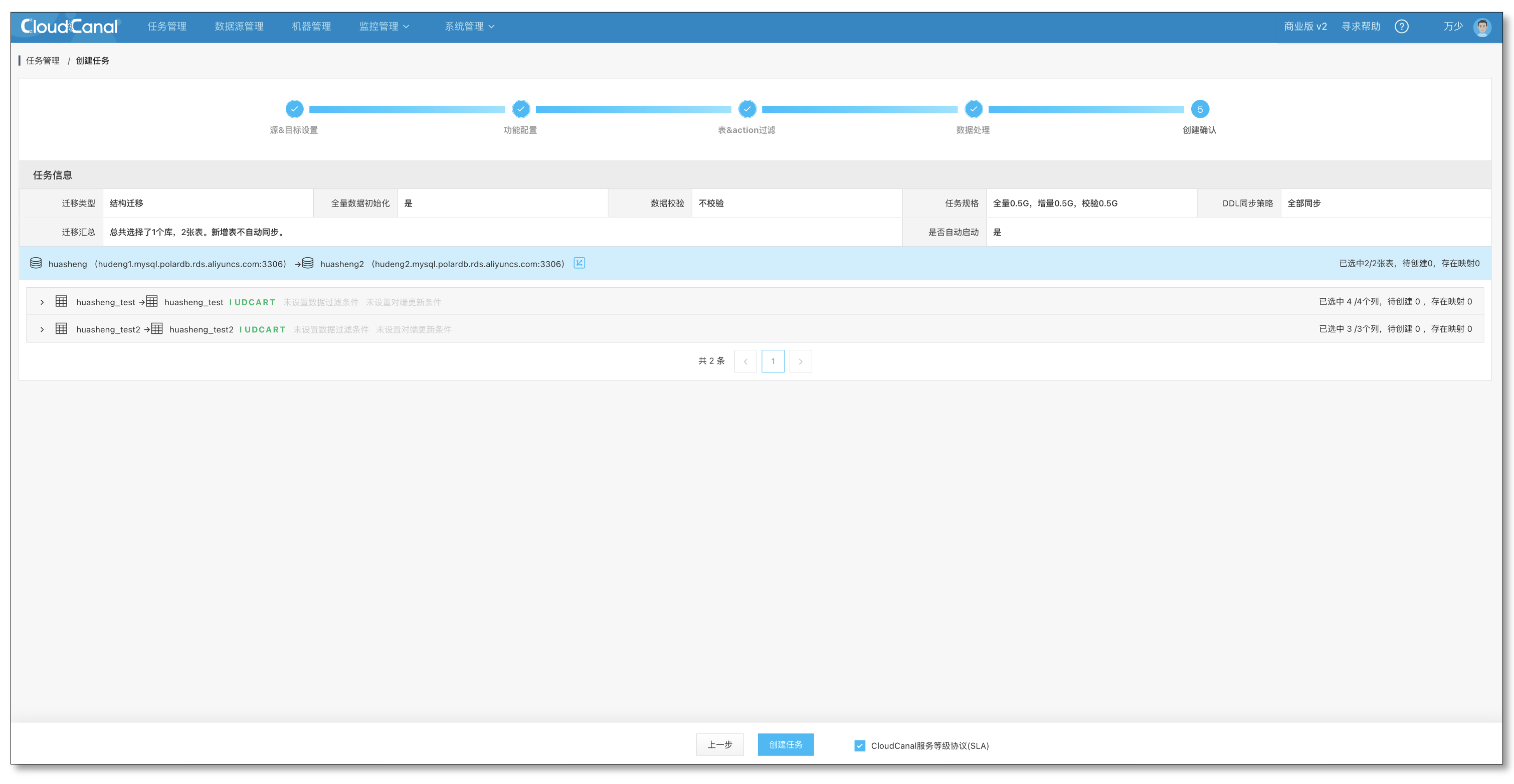
- 确认订正任务的配置无误后点击创建任务
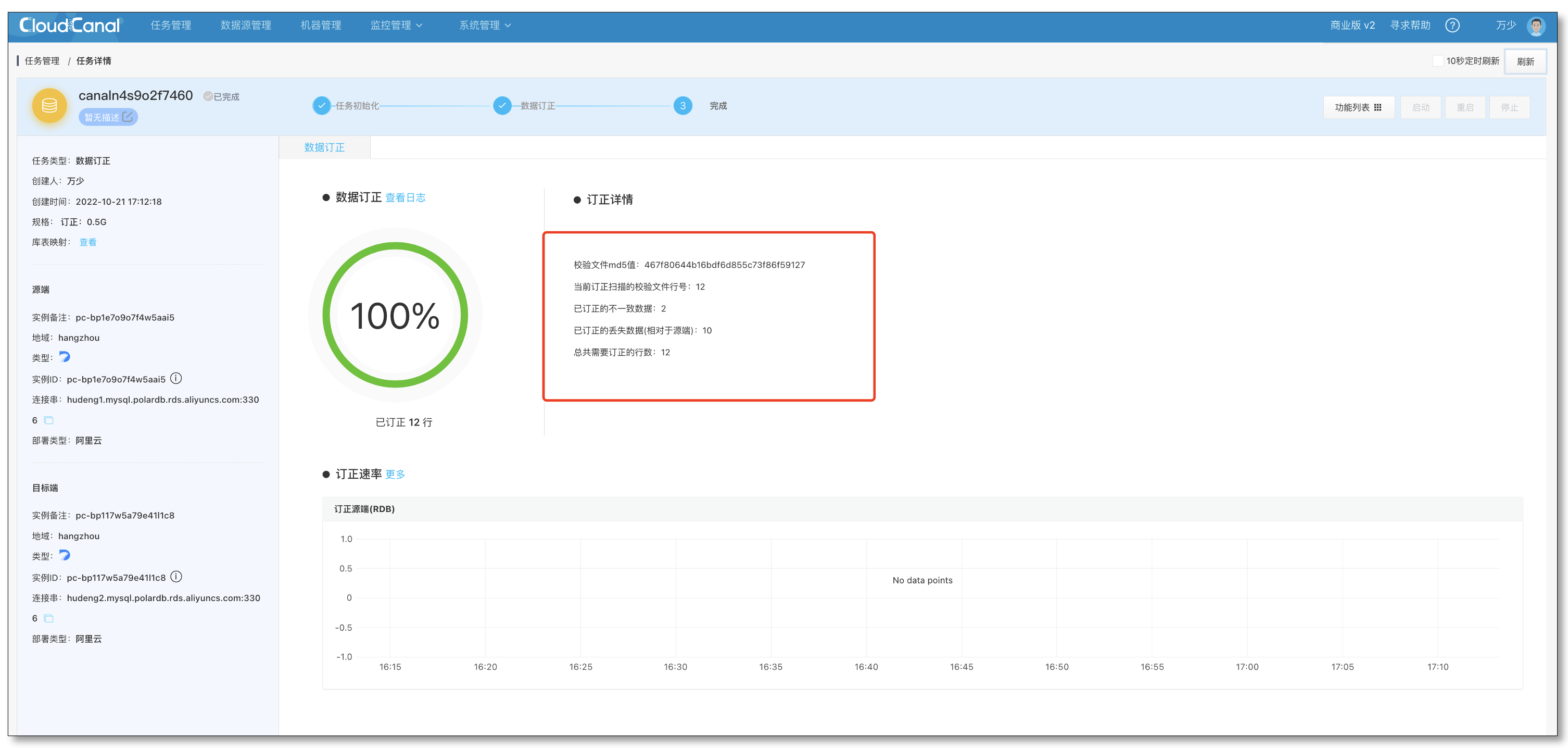
- 校验完成后可以看到具体订正的统计信息
总结
本文介绍了如何利用CloudCanal的校验订正能力来快速恢复数据,如果对您有帮助的话,欢迎点赞转发。
这篇关于五分钟掌握CloudCanal的数据校验与数据订正的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




