本文主要是介绍加密流量分类-论文3:FS-Net: A Flow Sequence Network For Encrypted Traffic Classification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
加密流量分类-论文3:FS-Net: A Flow Sequence Network For Encrypted Traffic Classification
- 0、摘要
- 1、问题引入
- 2、问题定义
- 3、模型结构
- 3.1总览
- 3.2 嵌入层
- 3.3 编码层
- 3.4 解码层
- 3.5 分类器
- 4、实验
- 5、总结与思考
0、摘要
FS-Net是一个端到端的分类模型,它从原始流中学习代表性特征,然后在一个统一的框架中对它们进行分类。采用多层编码器-解码器结构,可以深入挖掘流的潜在序列特征,并引入重构机制,提高特征的有效性。
1、问题引入
传统的基于统计特征加上机器学习的流量分类,太依赖与专业经验,即人类的特征工程,特征工程的好坏直接影响分类性能。以往的基于DL的流量分类方法如Deep Packet:,只使用了网络流量的有效载荷进行分类,没有考虑到流量中的其他信息。因此提出基于DL的端到端的分类模型,尝试设计一种新的适合流序列特征的神经网络结构,可以直接从原始输入中学习特征,学习到的特征以真实标签为指导,从而提高性能。因此,它可以节省设计和验证功能的人力。
2、问题定义
- FS-Net是基于网络流量的应用分类,即应用识别。
- 一个原始流量可以表示为不同的类型序列,如消息类型序列或者包长度序列,本文将一个原始流量看作包长度序列。具体的,Xp表示第p个样本的序列表示:
X p = [ L 1 p , L 2 p , . . . , L n p ) ] X_p=[L_1^p,L_2^p,...,L_n^p)] Xp=[L1p,L2p,...,Lnp)]
其中n是Xp的长度,Lip是时间步长i的数据包值。
3、模型结构
3.1总览
类似于AE半监督的思想,模型由五大块组成
- 嵌入层
- 编码层
- 解码层
- 重构层
- 分类器

3.2 嵌入层
- 任务:将L1到Ln的序列信息转化为e1到en的向量表示。如果有K个数据,且嵌入向量的维度为d,那么K个数据经过嵌入层将转化为一个矩阵EK*d,矩阵E是可以在模型训练过程中训练出来的,矩阵的每一个行向量都对应着一个数据样本的嵌入向量表示。
- 使用嵌入向量的优点:
- 一些非数值(如消息类型)可以很容易地表示为数值进行计算。
- 向量表示丰富了一个序列中每个元素保存的信息。嵌入向量的每个维度都是影响流生成的潜在特征。同一元素在不同的序列中可能有不同的含义和方面。
- 模型可以学习每个元素的嵌入向量的面向任务的较优秀的向量表示,从而提高分类性能。
3.3 编码层
- 输入为嵌入向量,输出压缩后的特征
- 编码采用的是堆叠的Bi-GRU神经网络模型。低层的编码器学习到局部特征,高层的编码器学习到相对全局的特征,最后将所有层的最终前向与后向的隐藏状态串联Ze作为编码器压缩后的特征。此时,Ze就包含了整个编码流程序列的双向上下文信息,将会作为分类器的输入的一部分。(既有局部的,又有全局的)
3.4 解码层
- 解码器的结构如同编码器一样,为折叠的Bi-GRU网络结构。
- 输入为Ze,输出由两个部分组成
1.第一部分类似于编码器的输出,为解码器所有层的前向状态与后向状态的拼接,称之为,Zd这部分输出将会作用与最终的分类器输出的一部分。
2.第二部分则是最后一层解码器的自身输出,这部分将会送入重构层,进行重构,重构目标是还原起初的模型输入。
3.5 分类器
- 分类器之前,设置了Dense层对分类器的输入(即Ze与Zd向量的拼接)进行压缩,得到新的特征向量z.

然而,z的维度还是太高,使用两层带Selu的激活函数的MLP对z进行降维得到Zc,降维过后能有效避免过拟合问题。

公式中的W1,b1,b2都是可以学习的参数。 - 输入为Zc,经过softmax分类器,得到预测标签A-,与真实标签A之间构造一个交叉熵损失LC
- 在重构器后面,解码器中的Bi-GRU经过重构,输出的Li^与原始的输入特征Li之间可以构造另外一个交叉熵损失LR
- 因此,最终的损失函数
L = L C + α L R L=L_C+αL_R L=LC+αLR
α是超参数。
4、实验
-
实验设置:以报文长度序列作为FS-Net的输出,嵌入向量维度d设置为128,GRU的隐藏状态维度也是128,α设置为1,dropout设置为0.3,Adam优化器的lr设置为0.0005
-
与其他模型结果实验对比的结论:加密流分类任务中,报文长度比消息类型更具有代表性。主要原因可能是[11]发现的不同应用程序的消息类型序列高度重叠。有更多的信息蕴含在包长度集合中而不是消息类型的集合中。
-
对FS-Net的一些分析:
- 摒弃解码器层、重构层和重构损失,即只将基于编码器的特征向量Ze传递到密集层进行分类。该变体称为FS-ND.此时FS-Net与其变体FS-ND的默认输入仍旧为包长度序列(The packet length sequence)。
个人感觉这种变体特别像BERT,BERT就是只使用了Transformer的编码器结构,经历预训练后,在诸多下游任务中均获得了不错的效果。当然,BERT是有MLM与NSP的预训练任务的,而此处的FS-ND貌似并没有提及,只是单纯砍掉了解码器与重构器那一部分。
- 因为传统的消息类型马尔可夫方法(FoSM、SOCRT、SOB)以**消息类型序列(The message type sequences)**作为输入。为了便于比较,FS-Net和FS-ND也结合消息类型序列进行测试,对应的方法记为FS-Net- s和FS-ND- s。
- 采用多属性序列(消息类型序列和报文长度序列)来提高性能。即同时关注包长度序列(The packet length sequence)与消息类型序列(The message type sequences),这两种不同的模型被称为FS-Net-SL和FS-ND-SL。
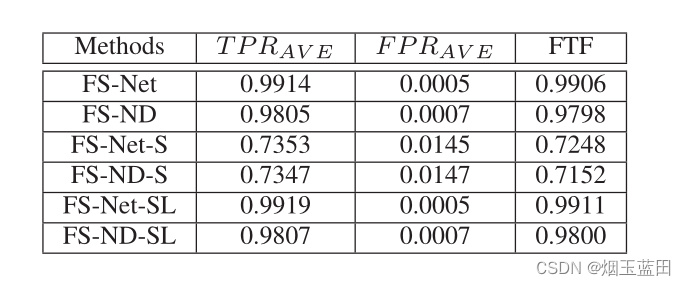
- 结果分析:
- 重构机制(即包含解码层、重构层)有用,提高分类性能。与不同序列比较,FS-Net的FTF性能始终优于FS-ND,提高了0.01左右。利用重构机制,引导从编码器学习到的特征存储更丰富的信息。
- 重构机制有用,但是对比FS-ND提示不大,并且加了那么多结构,有点不太划算。变体模型FS-ND也优于现有的模型,而且FS-Net和FS-ND之间的性能差距不大。然而,FS-ND模型比FS-Net需要更少的层,可以更快地训练。
- 报文长度序列的信息比消息类型序列的信息更丰富。消息类型序列的信息几乎被合并到包长度序列中。从FS-Net到FS-Net- sl的改进不显著(如FTF为0.0005)。FSND和FS-ND-SL之间也存在类似的现象。
-
调参分析:
- GRU的隐藏状态维度:太大,模型冗余,过拟合的同时容易从噪声中学习无用信息;太小,不足以提取数据的隐藏特征。研究中设置为128。
- 超参数α:建议α值设为[0.125,2]。
5、总结与思考
- 模型结构,类似与NLP中的Seq2Seq结构,可否在中间的编码器与解码器之间照葫芦画瓢加上Attention机制来进一步优化捏?
- 去除解码器与重构器,模型复杂度减少,并且实验证明在数据集上的表现FS-ND也跟FS-Net差之无几,能否在FS-ND上做出改进,使之效率与复杂度要比现在的模型好。
这篇关于加密流量分类-论文3:FS-Net: A Flow Sequence Network For Encrypted Traffic Classification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






