本文主要是介绍ResNet目标检测算法实现交通灯分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
红绿灯识别方案:https://zhuanlan.zhihu.com/p/674791906
目录
- 一、制作数据集
- 二、ResNet算法
- 三、pytorch转onnx文件
- 四、onnx推理测试
- 五、onnx转mnn
一、制作数据集
1、数据集划分
将红绿灯数据集大文件夹中不同类别的小文件夹中的图片按照9:1进行划分,拆分后分别保存到train和val的文件中
import os
import shutil
import randomdef split_dataset(source_folder, destination_folder, split_ratio=0.9):# 创建目标文件夹train_folder = os.path.join(destination_folder, 'train')val_folder = os.path.join(destination_folder, 'val')os.makedirs(train_folder, exist_ok=True)os.makedirs(val_folder, exist_ok=True)# 遍历每个类别的文件夹for class_folder in os.listdir(source_folder):class_path = os.path.join(source_folder, class_folder)# 创建类别的train和val子文件夹train_class_path = os.path.join(train_folder, class_folder)val_class_path = os.path.join(val_folder, class_folder)os.makedirs(train_class_path, exist_ok=True)os.makedirs(val_class_path, exist_ok=True)# 获取类别文件夹下的所有图片文件images = [f for f in os.listdir(class_path) if f.endswith('.jpg')]# 计算划分的索引split_index = int(len(images) * split_ratio)# 随机打乱图片列表random.shuffle(images)# 将图片拷贝到train文件夹for image in images[:split_index]:src_path = os.path.join(class_path, image)dst_path = os.path.join(train_class_path, image)shutil.copy(src_path, dst_path)# 将图片拷贝到val文件夹for image in images[split_index:]:src_path = os.path.join(class_path, image)dst_path = os.path.join(val_class_path, image)shutil.copy(src_path, dst_path)if __name__ == "__main__":source_folder = "traffic_light"destination_folder = "dataset"split_dataset(source_folder, destination_folder)二、ResNet算法
1、ResNet网络模型
model.py
import torch.nn as nn
import torch# 定义ResNet18/34的残差结构,为2个3x3的卷积
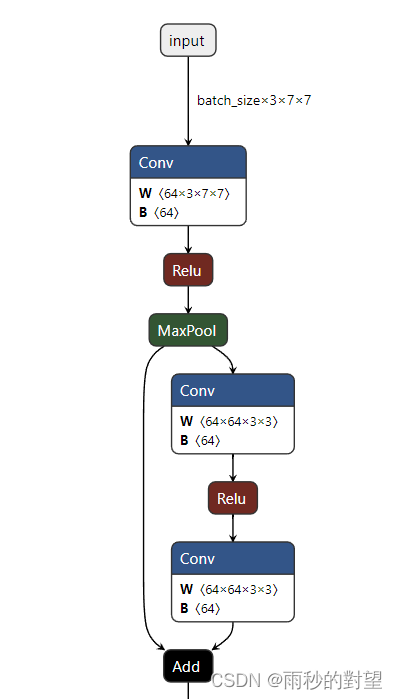
class BasicBlock(nn.Module):# 判断残差结构中,主分支的卷积核个数是否发生变化,不变则为1expansion = 1# init():进行初始化,申明模型中各层的定义# downsample=None对应实线残差结构,否则为虚线残差结构def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,kernel_size=3, stride=stride, padding=1, bias=False)# 使用批量归一化self.bn1 = nn.BatchNorm2d(out_channel)# 使用ReLU作为激活函数self.relu = nn.ReLU()self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channel)self.downsample = downsample# forward():定义前向传播过程,描述了各层之间的连接关系def forward(self, x):# 残差块保留原始输入identity = x# 如果是虚线残差结构,则进行下采样if self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)# -----------------------------------------out = self.conv2(out)out = self.bn2(out)# 主分支与shortcut分支数据相加out += identityout = self.relu(out)return out# 定义ResNet50/101/152的残差结构,为1x1+3x3+1x1的卷积
class Bottleneck(nn.Module):# expansion是指在每个小残差块内,减小尺度增加维度的倍数,如64*4=256# Bottleneck层输出通道是输入的4倍expansion = 4# init():进行初始化,申明模型中各层的定义# downsample=None对应实线残差结构,否则为虚线残差结构,专门用来改变x的通道数def __init__(self, in_channel, out_channel, stride=1, downsample=None,groups=1, width_per_group=64):super(Bottleneck, self).__init__()width = int(out_channel * (width_per_group / 64.)) * groupsself.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,kernel_size=1, stride=1, bias=False)# 使用批量归一化self.bn1 = nn.BatchNorm2d(width)# -----------------------------------------self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,kernel_size=3, stride=stride, bias=False, padding=1)self.bn2 = nn.BatchNorm2d(width)# -----------------------------------------self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel * self.expansion,kernel_size=1, stride=1, bias=False)self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)# 使用ReLU作为激活函数self.relu = nn.ReLU(inplace=True)self.downsample = downsample# forward():定义前向传播过程,描述了各层之间的连接关系def forward(self, x):# 残差块保留原始输入identity = x# 如果是虚线残差结构,则进行下采样if self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)# 主分支与shortcut分支数据相加out += identityout = self.relu(out)return out# 定义ResNet类
class ResNet(nn.Module):# 初始化函数def __init__(self,block,blocks_num,num_classes=28,include_top=True,groups=1,width_per_group=64):super(ResNet, self).__init__()self.include_top = include_top# maxpool的输出通道数为64,残差结构输入通道数为64self.in_channel = 64self.groups = groupsself.width_per_group = width_per_groupself.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,padding=3, bias=False)self.bn1 = nn.BatchNorm2d(self.in_channel)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 浅层的stride=1,深层的stride=2# block:定义的两种残差模块# block_num:模块中残差块的个数self.layer1 = self._make_layer(block, 64, blocks_num[0])self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)if self.include_top:# 自适应平均池化,指定输出(H,W),通道数不变self.avgpool = nn.AdaptiveAvgPool2d((1, 1))# 全连接层self.fc = nn.Linear(512 * block.expansion, num_classes)# 遍历网络中的每一层# 继承nn.Module类中的一个方法:self.modules(), 他会返回该网络中的所有modulesfor m in self.modules():# isinstance(object, type):如果指定对象是指定类型,则isinstance()函数返回True# 如果是卷积层if isinstance(m, nn.Conv2d):# kaiming正态分布初始化,使得Conv2d卷积层反向传播的输出的方差都为1# fan_in:权重是通过线性层(卷积或全连接)隐性确定# fan_out:通过创建随机矩阵显式创建权重nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')# 定义残差模块,由若干个残差块组成# block:定义的两种残差模块,channel:该模块中所有卷积层的基准通道数。block_num:模块中残差块的个数def _make_layer(self, block, channel, block_num, stride=1):downsample = None# 如果满足条件,则是虚线残差结构if stride != 1 or self.in_channel != channel * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(channel * block.expansion))layers = []layers.append(block(self.in_channel,channel,downsample=downsample,stride=stride,groups=self.groups,width_per_group=self.width_per_group))self.in_channel = channel * block.expansionfor _ in range(1, block_num):layers.append(block(self.in_channel,channel,groups=self.groups,width_per_group=self.width_per_group))# Sequential:自定义顺序连接成模型,生成网络结构return nn.Sequential(*layers)# forward():定义前向传播过程,描述了各层之间的连接关系def forward(self, x):# 无论哪种ResNet,都需要的静态层x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)# 动态层x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)if self.include_top:x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return x# ResNet()中block参数对应的位置是BasicBlock或Bottleneck
# ResNet()中blocks_num[0-3]对应[3, 4, 6, 3],表示残差模块中的残差数
# 34层的resnet
def resnet34(num_classes=28, include_top=True):# https://download.pytorch.org/models/resnet34-333f7ec4.pthreturn ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)# 50层的resnet
def resnet50(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnet50-19c8e357.pthreturn ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)# 101层的resnet
def resnet101(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnet101-5d3b4d8f.pthreturn ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
2、数据集加载与训练
train.py
import os
import sys
import jsonimport torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
# 训练resnet34
from model import resnet34def main():# 如果有NVIDA显卡,转到GPU训练,否则用CPUdevice = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {# 训练# Compose():将多个transforms的操作整合在一起"train": transforms.Compose([# RandomResizedCrop(224):将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为给定大小transforms.RandomResizedCrop(224),# RandomVerticalFlip():以0.5的概率竖直翻转给定的PIL图像transforms.RandomHorizontalFlip(),# ToTensor():数据转化为Tensor格式transforms.ToTensor(),# Normalize():将图像的像素值归一化到[-1,1]之间,使模型更容易收敛transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),# 验证"val": transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# abspath():获取文件当前目录的绝对路径# join():用于拼接文件路径,可以传入多个路径# getcwd():该函数不需要传递参数,获得当前所运行脚本的路径data_root = os.path.abspath(os.getcwd())# 得到数据集的路径image_path = os.path.join(data_root, "data")# exists():判断括号里的文件是否存在,可以是文件路径# 如果image_path不存在,序会抛出AssertionError错误,报错为参数内容“ ”assert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])# 训练集长度train_num = len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}# class_to_idx:获取分类名称对应索引flower_list = train_dataset.class_to_idx# dict():创建一个新的字典# 循环遍历数组索引并交换val和key的值重新赋值给数组,这样模型预测的直接就是value类别值cla_dict = dict((val, key) for key, val in flower_list.items())# 把字典编码成json格式json_str = json.dumps(cla_dict, indent=4)# 把字典类别索引写入json文件with open('class_indices.json', 'w') as json_file:json_file.write(json_str)# 一次训练载入512张图像batch_size = 512# 确定进程数# min():返回给定参数的最小值,参数可以为序列# cpu_count():返回一个整数值,表示系统中的CPU数量,如果不确定CPU的数量,则不返回任何内容nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])print('Using {} dataloader workers every process'.format(nw))# DataLoader:将读取的数据按照batch size大小封装给训练集# dataset (Dataset):输入的数据集# batch_size (int, optional):每个batch加载多少个样本,默认: 1# shuffle (bool, optional):设置为True时会在每个epoch重新打乱数据,默认: False# num_workers(int, optional): 决定了有几个进程来处理,默认为0意味着所有的数据都会被load进主进程train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)# 加载测试数据集validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])# 测试集长度val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# 模型实例化net = resnet34()net.to(device)# 加载预训练模型权重# model_weight_path = "./resnet34-pre.pth"# exists():判断括号里的文件是否存在,可以是文件路径# assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)# net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))# 输入通道数# in_channel = net.fc.in_features# 全连接层# net.fc = nn.Linear(in_channel, 5)# 定义损失函数(交叉熵损失)loss_function = nn.CrossEntropyLoss()# 抽取模型参数params = [p for p in net.parameters() if p.requires_grad]# 定义adam优化器# params(iterable):要训练的参数,一般传入的是model.parameters()# lr(float):learning_rate学习率,也就是步长,默认:1e-3optimizer = optim.Adam(params, lr=0.0001)# 迭代次数(训练次数)epochs = 100# 用于判断最佳模型best_acc = 0.0# 最佳模型保存地址save_path = './resNet34.pth'train_steps = len(train_loader)for epoch in range(epochs):# 训练net.train()running_loss = 0.0# tqdm:进度条显示train_bar = tqdm(train_loader, file=sys.stdout)# train_bar: 传入数据(数据包括:训练数据和标签)# enumerate():将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中# enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签)# x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型)for step, data in enumerate(train_bar):# 前向传播images, labels = data# 计算训练值logits = net(images.to(device))# 计算损失loss = loss_function(logits, labels.to(device))# 反向传播# 清空过往梯度optimizer.zero_grad()# 反向传播,计算当前梯度loss.backward()optimizer.step()# item():得到元素张量的元素值running_loss += loss.item()# 进度条的前缀# .3f:表示浮点数的精度为3(小数位保留3位)train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# 测试# eval():如果模型中有Batch Normalization和Dropout,则不启用,以防改变权值net.eval()acc = 0.0# 清空历史梯度,与训练最大的区别是测试过程中取消了反向传播with torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))# torch.max(input, dim)函数# input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出# 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引predict_y = torch.max(outputs, dim=1)[1]# 对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False# .sum()对输入的tensor数据的某一维度求和acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,epochs)val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))# 保存最好的模型权重if val_accurate > best_acc:best_acc = val_accurate# torch.save(state, dir)保存模型等相关参数,dir表示保存文件的路径+保存文件名# model.state_dict():返回的是一个OrderedDict,存储了网络结构的名字和对应的参数torch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
- 效果:

- 生成的pth权重文件

3、数据集分类测试
根据训练生成的pth权重文件预测
test.py
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import resnet34def main():# 如果有NVIDA显卡,转到GPU训练,否则用CPUdevice = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")# 将多个transforms的操作整合在一起data_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 加载图片img_path = "./ResNet/data/test/composite/_17479_0.jpg"# 确定图片存在,否则反馈错误assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)# imshow():对图像进行处理并显示其格式,show()则是将imshow()处理后的函数显示出来plt.imshow(img)# [C, H, W],转换图像格式img = data_transform(img)# [N, C, H, W],增加一个维度Nimg = torch.unsqueeze(img, dim=0)plt.show()# 获取结果类型json_path = './ResNet/class_indices.json'# 确定路径存在,否则反馈错误assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)# 读取内容with open(json_path, "r") as f:class_indict = json.load(f)# 模型实例化,将模型转到device,结果类型有28种model = resnet34(num_classes=28).to(device)# 载入模型权重weights_path = "./ResNet/resNet34.pth"# 确定模型存在,否则反馈错误assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)# 加载训练好的模型参数model.load_state_dict(torch.load(weights_path, map_location=device))# 进入验证阶段model.eval()with torch.no_grad():# 预测类别# squeeze():维度压缩,返回一个tensor(张量),其中input中大小为1的所有维都已删除output = torch.squeeze(model(img.to(device))).cpu()# softmax:归一化指数函数,将预测结果输入进行非负性和归一化处理,最后将某一维度值处理为0-1之内的分类概率predict = torch.softmax(output, dim=0)# argmax(input):返回指定维度最大值的序号# .numpy():把tensor转换成numpy的格式predict_cla = torch.argmax(predict).numpy()# 输出的预测值与真实值print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())# 图片标题plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()可视化展示:
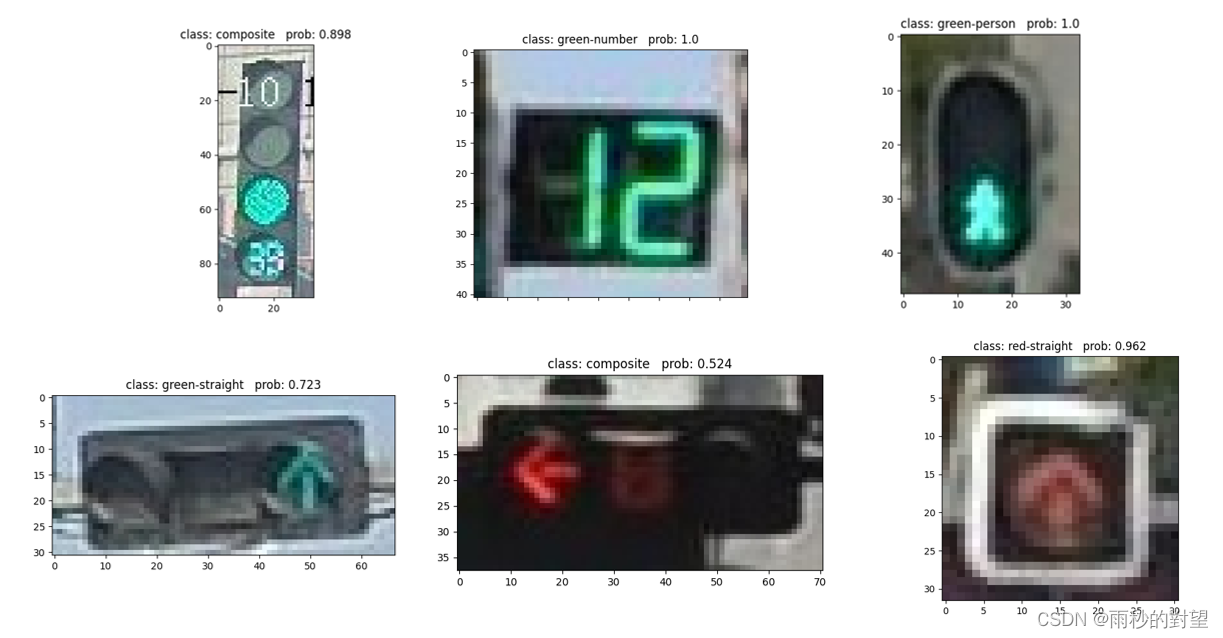
三、pytorch转onnx文件
将model模型中的resnet34导入其中:
import torch
import torchvision
from model import * # 引入模型torch.set_grad_enabled(False)
torch_model = resnet34() # 初始化网络
torch_model.load_state_dict(torch.load('./ResNet/resNet34.pth'), False) # 加载训练好的pth模型
batch_size = 1 # 批处理大小
input_shape = (3, 224, 224) # 输入数据,我这里是灰度训练所以1代表是单通道,RGB训练是3,224是图像输入网络的尺寸# set the model to inference mode
torch_model.eval().cpu() # cpu推理x = torch.randn(batch_size, *input_shape).cpu() # 生成张量
export_onnx_file = "resnet34_314.onnx" # 要生成的ONNX文件名
torch.onnx.export(torch_model,x,export_onnx_file,opset_version=10,do_constant_folding=True, # 是否执行常量折叠优化input_names=["input"], # 输入名output_names=["output"], # 输出名dynamic_axes={"input": {0: "batch_size"}, # 批处理变量"output": {0: "batch_size"}})- 生成的onnx权重文件
四、onnx推理测试
import onnx
import onnxruntime as ort
import numpy as np
import cv2
def preprocess(img_data):mean_vec = np.array([0.485, 0.456, 0.406])stddev_vec = np.array([0.229, 0.224, 0.225])norm_img_data = np.zeros(img_data.shape).astype('float32')for i in range(img_data.shape[0]):# for each pixel in each channel, divide the value by 255 to get value between [0, 1] and then normalizenorm_img_data[i,:,:] = (img_data[i,:,:]/255 - mean_vec[i]) / stddev_vec[i]return norm_img_datadef softmax(x):e_x = np.exp(x - np.max(x))return e_x / e_x.sum()img = cv2.imread("./data/test/composite/00000136_0.jpg")
img = cv2.resize(img, (224,224), interpolation=cv2.INTER_AREA)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
input_data = np.transpose(img, (2, 0, 1))
input_data = preprocess(input_data)
input_data = input_data.reshape([1, 3, 224, 224])
sess = ort.InferenceSession("./ResNet/resnet34wsy.onnx")
input_name = sess.get_inputs()[0].name
result = sess.run([], {input_name: input_data})
result = np.reshape(result, [1, -1])
result_s = softmax(result)
index = np.argmax(result_s)
print("max index:", index)
五、onnx转mnn
方法一:
1、mnn下载地址
git clone https://github.com/alibaba/MNN
2、编译
cd MNN
./schema/generate.sh
mkdir build
cd build
camke .. -DMNN_BUILD_CONVERTER=true
make -j8
3、运行
根据自己的文件夹路径
./MNNConvert -f ONNX --modelFile XXX.onnx --MNNModel XXX.mnn --bizCode MNN./MNNConvert -f ONNX --modelFile /home/mengwen/ResNet/traffic_light.onnx --MNNModel /home/mengwen/ResNet/traffic_light.mnn --bizCode MNN
方法二:
一键转换
地址:https://convertmodel.com/

2、
参考:
1、MNN框架学习(一):编译及使用
2、pytorch模型部署 pth转onnx
3、CNN经典网络模型(五):ResNet简介及代码实现(PyTorch超详细注释版)
4、ONNX格式模型转MNN格式模型
这篇关于ResNet目标检测算法实现交通灯分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





