本文主要是介绍【Intel校企合作项目】预测淡水质量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、项目简介
问题描述
淡水是我们最重要和最稀缺的自然资源之一,仅占地球总水量的 3%。它几乎触及我们日常生活的方方面面,从饮用、游泳和沐浴到生产食物、电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱、污染和气温升高影响的周边生态系统的生存也至关重要。
预期解决方案:
通过参考英特尔的类似实现方案,预测淡水是否可以安全饮用和被依赖淡水的生态系统所使用,从而可以帮助全球水安全和环境可持续性发展。这里分类准确度和推理时间将作为评分的主要依据。
数据集:
你可以在此处![]() https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip下载数据集要求。
https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip下载数据集要求。
淡水资源的质量对于人类的生存和发展至关重要,因此准确预测淡水质量成为了一个亟待解决的问题。近年来,随着人工智能和机器学习技术的快速发展,利用这些技术来预测淡水质量已经成为一种趋势。其中,oneAPI作为一种跨平台、跨架构的编程接口,为淡水质量预测提供了强大的支持。本文将总结oneAPI在解决淡水质量预测问题中的应用,并探讨其优势和局限性。
二、解决方案
环境配置
在 Sklean 里,模型能即用的数据有两种形式:
Numpy 二维数组 (ndarray) 的稠密数据 (dense data),通常都是这种格式。
SciPy 矩阵 (scipy.sparse.matrix) 的稀疏数据 (sparse data),比如文本分析每个单词 (字典有 100000 个词) 做独热编码得到矩阵有很多 0,这时用 ndarray 就不合适了,太耗内存。
上述数据在机器学习中通常用符号 X 表示,是模型自变量。它的大小 = [样本数, 特征数],有监督学习除了需要特征 X 还需要标签 y,而 y 通常就是 Numpy 一维数组,无监督学习没有 y。
# 环境配置
import os
import modin.pandas as pd
from modin.config import Engine
from sklearnex import patch_sklearnos.environ["MODIN_ENGINE"] = "dask"
Engine.put("dask")
patch_sklearn()导入所需的库
这里导入的都是一些常见的机器学习有关的库,
# 导入库
import time
import warnings
import pandas
import numpy as np
import seaborn as sns # 可视化库
import matplotlib.colors
import matplotlib.pyplot as plt
import plotly.io as pio
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import daal4py as d4p # 机器学习相关库
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV, RandomizedSearchCV
from sklearn.metrics import roc_auc_score, roc_curve, auc, accuracy_score, f1_score # 模型评估
from sklearn.metrics import precision_recall_curve, average_precision_score
from sklearn.metrics import confusion_matrix, precision_score, recall_scorewarnings.filterwarnings('ignore')
pio.renderers.default = 'notebook'
intel_pal, color = ['#0071C5', '#FCBB13'], ['#7AB5E1', '#FCE7B2']
temp = dict(layout=go.Layout(font=dict(family="Franklin Gothic", size=12), height=500, width=1000))数据读取
读取数据并输出数据规模
# 数据读取
data = pd.read_csv('./data/dataset.csv')
print('数据规模:{}\n'.format(data.shape))
display(data.head())![]()
数据集结构
以下是对数据集中各特征的的提取以及划分:输出离散量和连续量
# 数据整体信息
label_counts = data['Target'].value_counts()# 划分各特征(离散量、连续量)
cols = data.columns
discrete_cols, continuous_cols = [], []
for col in cols: # 特征值数量统计if data[col].value_counts().count() < 15: # 离散量discrete_cols.append(col)else: # 连续量continuous_cols.append(col)print("离散量:", discrete_cols)
print("连续量:", continuous_cols)
从图可以看出,数据集中存在着一些比较特殊的特征,所以需要将其转化,并对数据集中的数据进行下一步操作。
数据集内容的分析和处理
提取各特征的缺失量和重复量
淡水质量预测涉及大量的数据,包括水质指标、环境因素、地理信息等。oneAPI提供了统一的数据访问和处理接口,使得不同来源、不同格式的数据可以方便地进行集成和处理,为后续的分析和预测提供基础。
# 各特征缺失量、重复量
missing = data.isna().sum().sum()
duplicates = data.duplicated().sum()display(data.isna().sum())
print("\n数据集中存在{:,.0f}项缺失值.".format(missing))
print("数据集中存在{:,.0f}项重复值.".format(duplicates))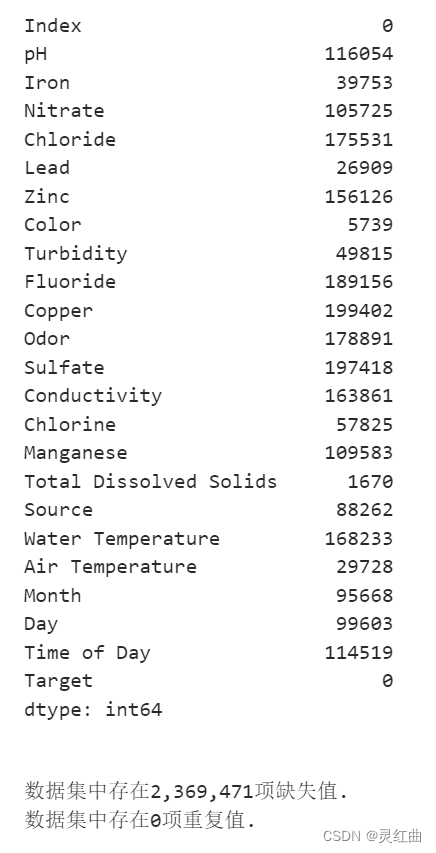
并对上述量进行可视化输出
#数据可视化
#通过饼状图直观反映数量对比。
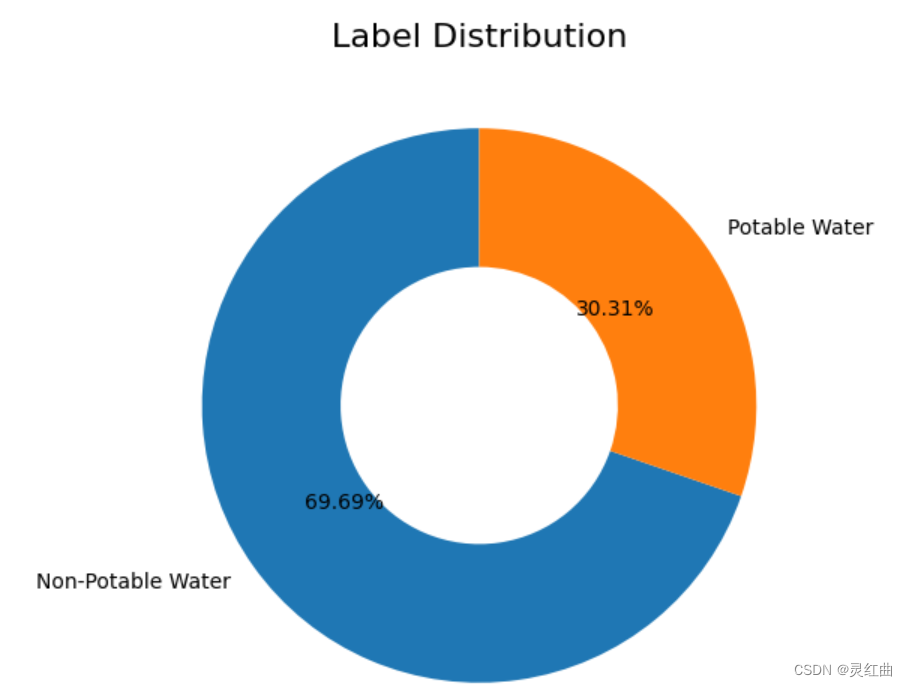
import matplotlib.pyplot as pltdef plot_target(target_col):tmp=data[target_col].value_counts(normalize=True)target = tmp.rename(index={1:'Target 1',0:'Target 0'})wedgeprops = {'width':0.5, 'linewidth':10}plt.figure(figsize=(6,6))plt.pie(list(tmp), labels=target.index,startangle=90, autopct='%1.1f%%',wedgeprops=wedgeprops)plt.title('Label Distribution', fontsize=16)plt.show() plot_target(target_col='Target')
# 不同标签数据占比
def plot_target(target_col):tmp = data[target_col].value_counts(normalize=True)target = tmp.rename(index={1: 'Potable Water', 0: 'Non-Potable Water'})wedgeprops = {'width': 0.5, 'linewidth': 10}plt.figure(figsize=(6, 6))plt.pie(list(tmp), labels=target.index,startangle=90, autopct='%1.2f%%', wedgeprops=wedgeprops)plt.title('Label Distribution', fontsize=16)plt.show()plot_target(target_col='Target')# 各特征数据分布
data[continuous_cols[1:]].hist(bins=50, figsize=(16, 12)) # 排除Index列
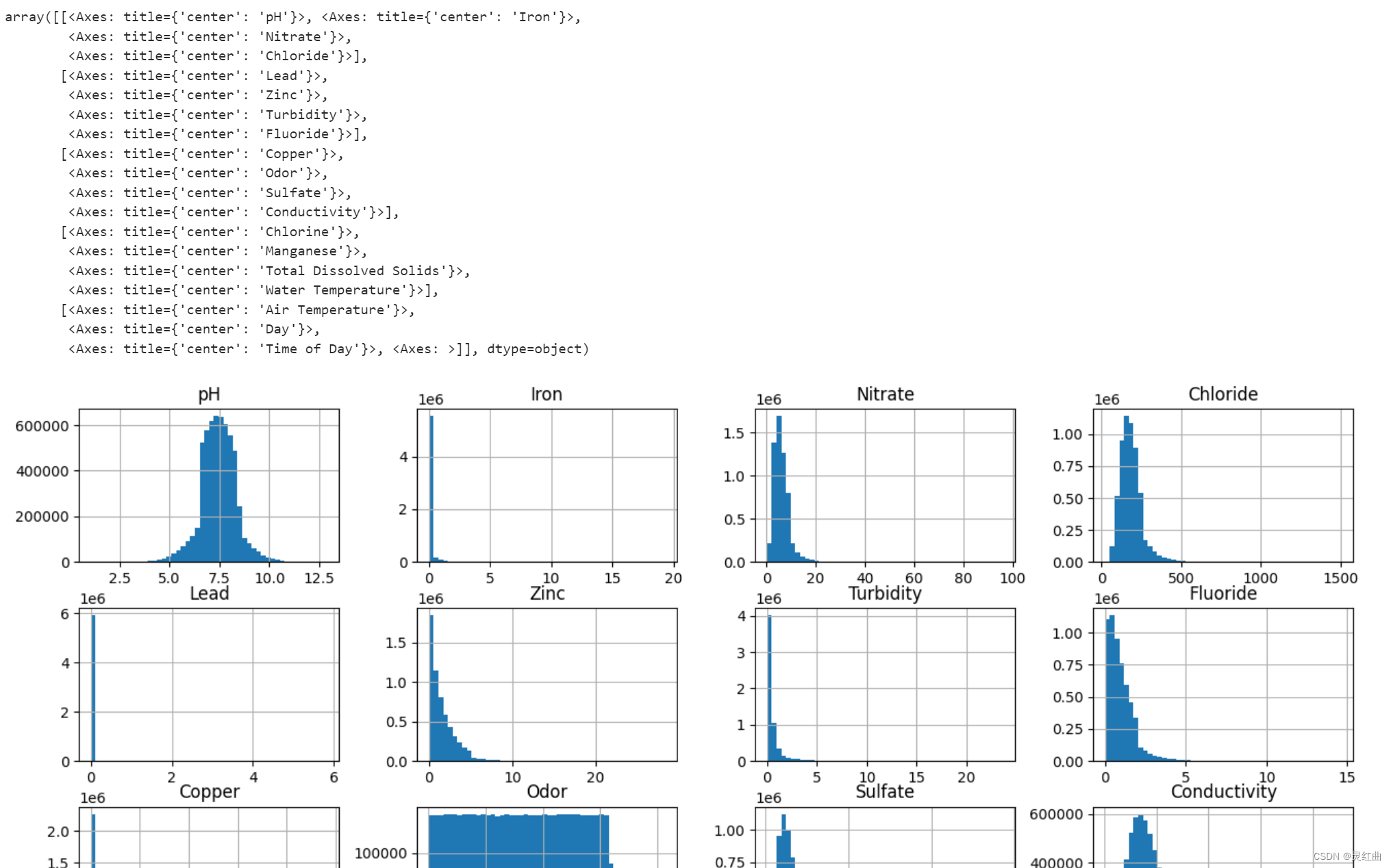
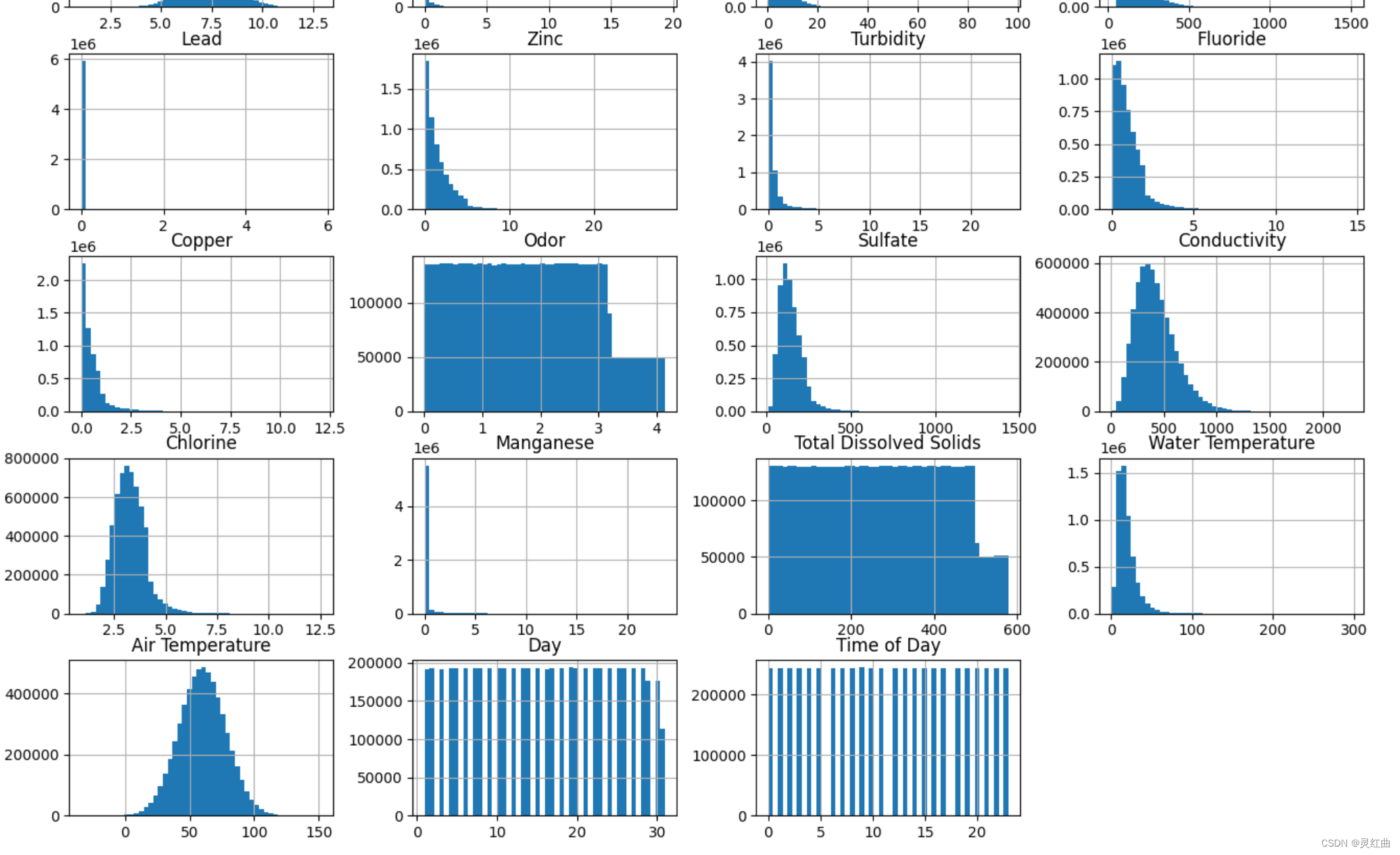
箱型图是一种用于可视化数据分布情况的统计图表。它能够展示数据的中位数、上下四分位数、最大值、最小值以及异常值等统计信息,有助于直观地了解数据的分布形态、离散程度以及异常值情况。
from scipy.stats import pearsonrvariables = data.columns
data = datavar = data.var()
numeric = data.columns
data = data.fillna(data.interpolate())
for i in range(0, len(var) - 1):if var[i] <= 0.1: # 方差大于10%print(variables[i])data = data.drop(numeric[i],axis=1)
variables = data.columnsfor i in range(0, len(variables)):x = data[variables[i]]y = data[variables[-1]]if pearsonr(x, y)[1] > 0.05:print(variables[i])data = data.drop(variables[i],axis=1)variables = data.columns
print(variables)
print(len(variables))
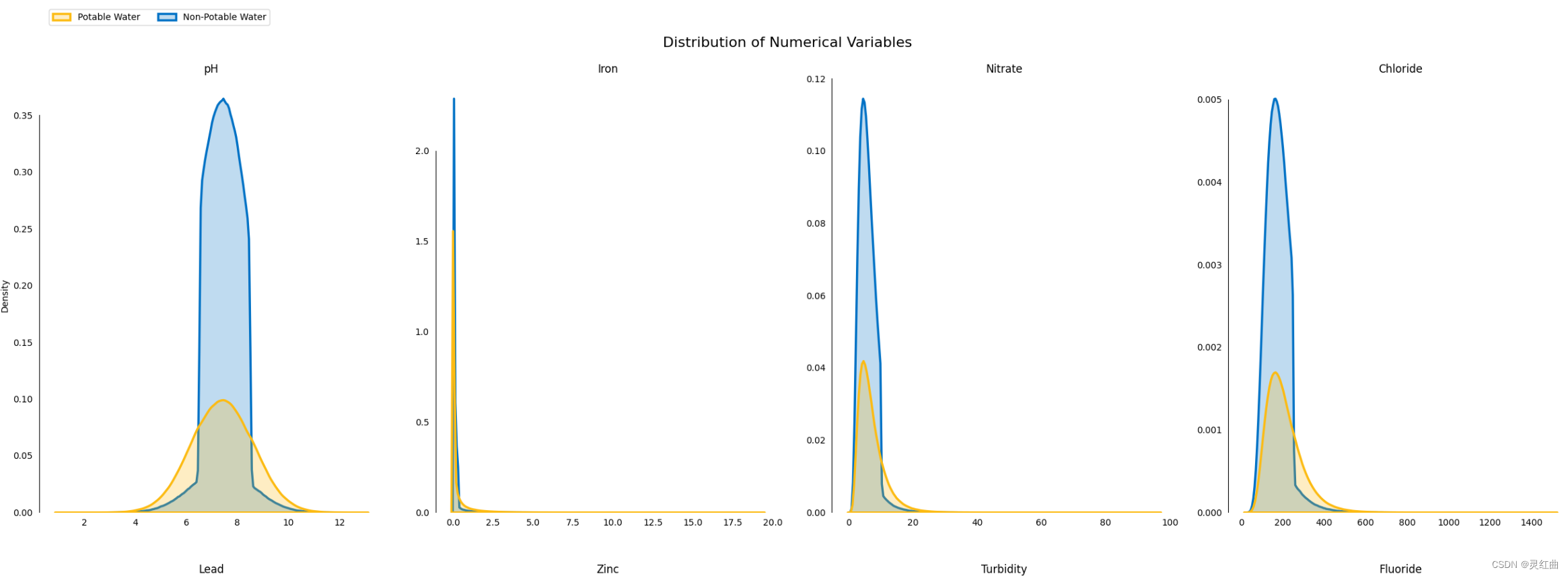
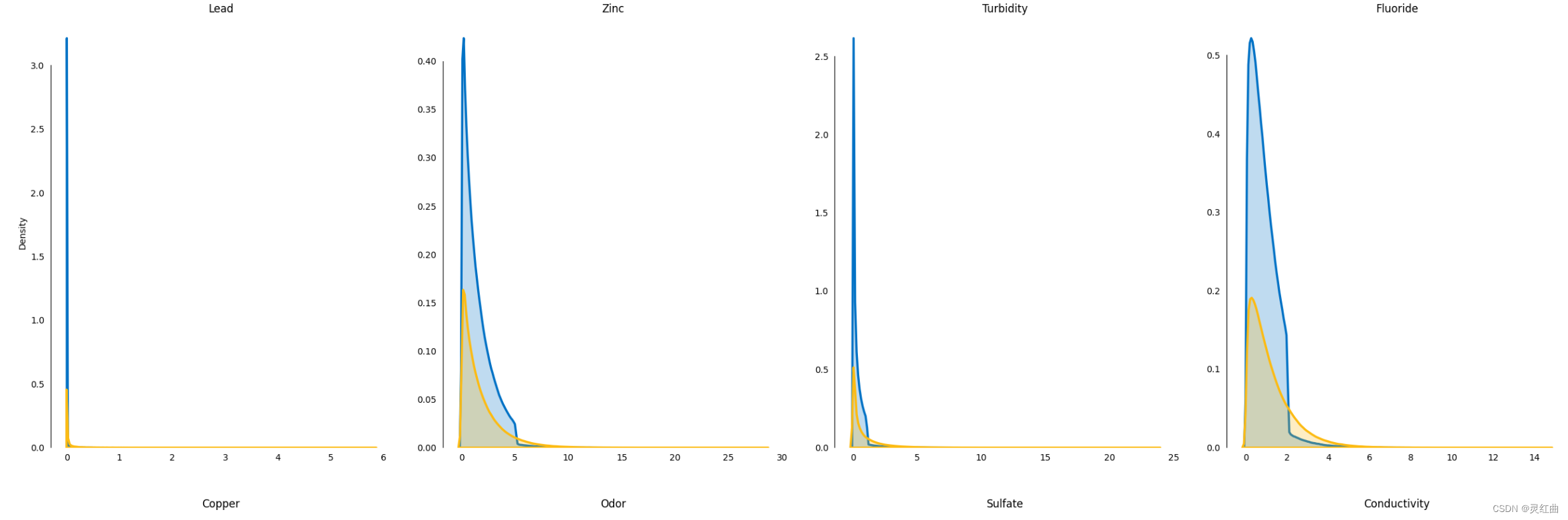
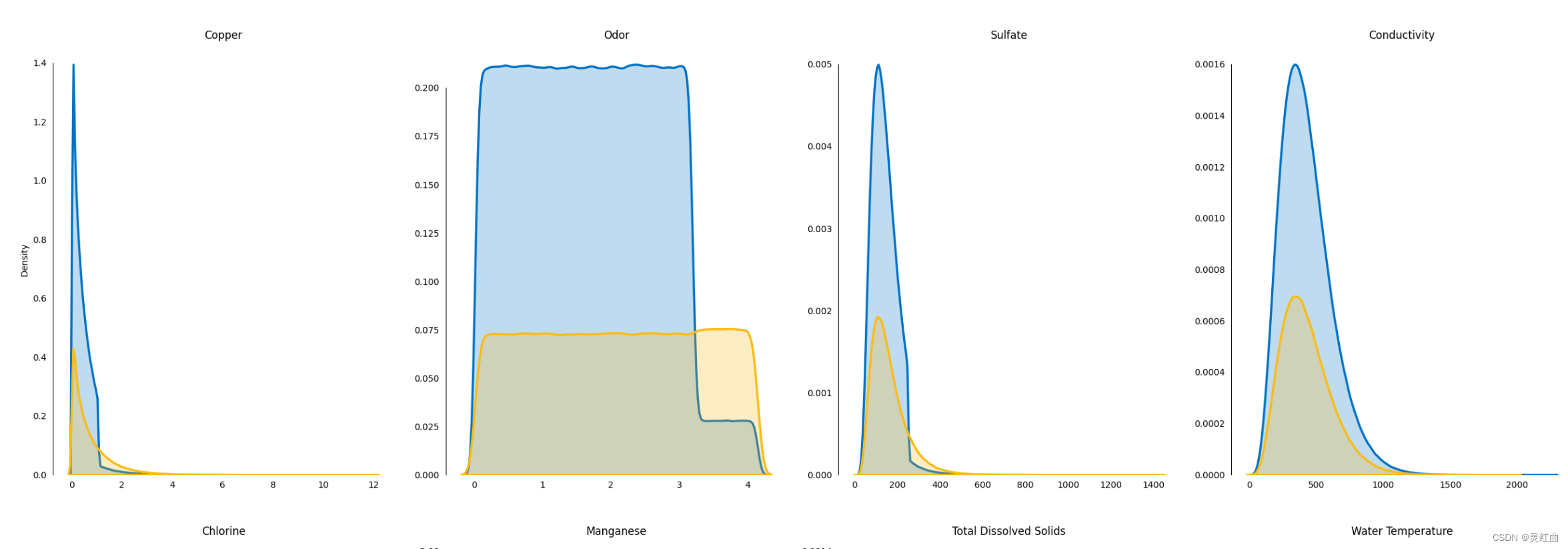
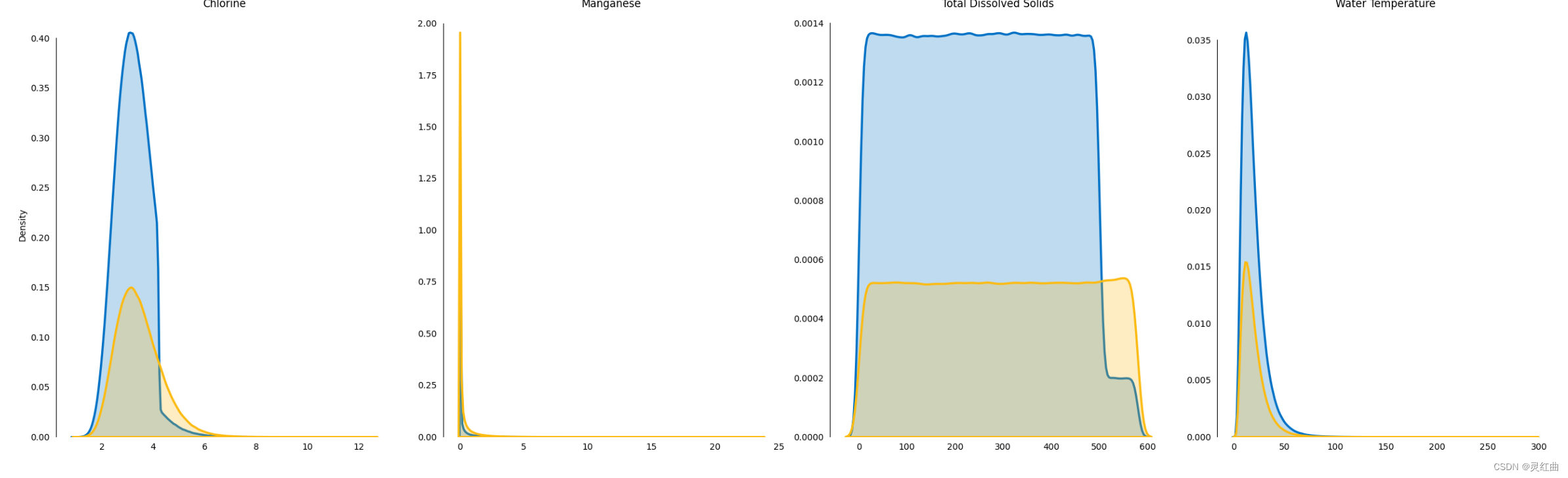
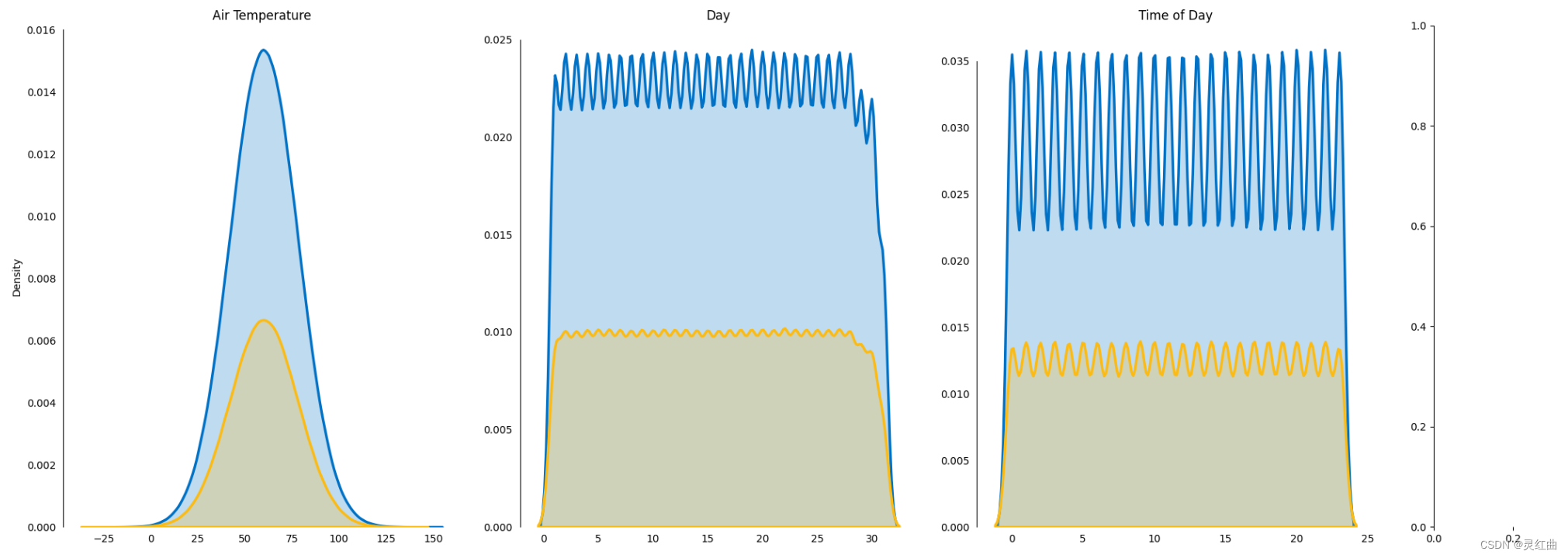
# 数据预处理
import numpy as np
log_col = ['Iron', 'Zinc', 'Turbidity', 'Copper', 'Manganese']
show_col = []
for col in log_col:data[col + '_log'] = np.log(data[col])show_col.append(col + '_log')data[show_col].hist(bins=50,figsize=(16,12))pretreat(data)基于处理后的数据,可以利用机器学习算法构建淡水质量预测模型。oneAPI支持多种编程语言和框架,使得开发者可以根据自己的需求和习惯选择合适的工具和库来构建模型。同时,oneAPI还提供了优化的计算库和底层硬件支持,使得模型的训练过程更加高效。
df.hist(bins=50,figsize=(16,12))
# 针对不规则分布的变量进行非线性变换,一般进行log
log_col = ['Iron', 'Zinc', 'Turbidity', 'Copper', 'Manganese']
show_col = []
for col in log_col:df[col + '_log'] = np.log(df[col])show_col.append(col + '_log')df[show_col].hist(bins=50,figsize=(16,12))查看各属性与类别相关性
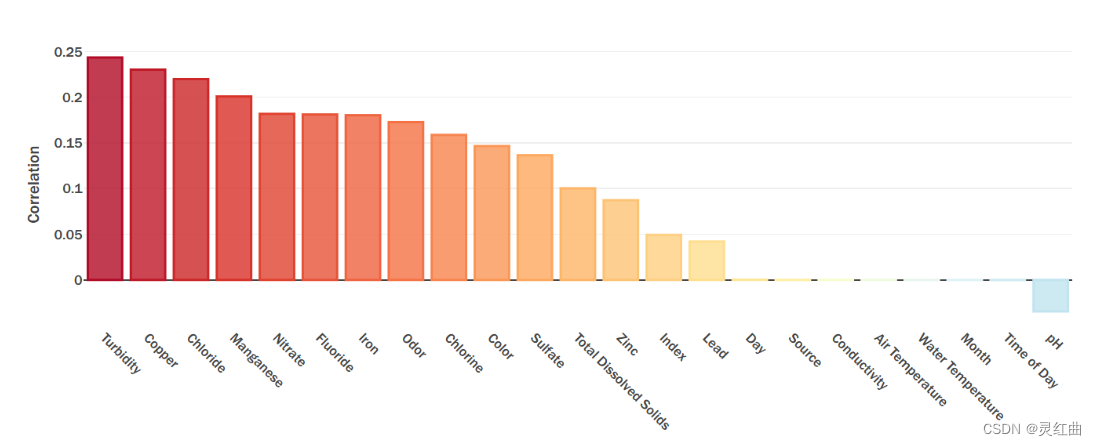
模型训练
稳健标准化(RobustScaler)
使用具有鲁棒性的统计量缩放带有异常值(离群值)的数据
处理方法:该缩放器删除中位数,并根据百分位数范围(默认值为IQR:四分位间距)缩放数据;
IQR:是第1个四分位数(25%)和第3个四分位数(75%)之间的范围;
适用性:适用于包含许多异常值的数据;
Outlier 的影响:RobustScaler 利用IQR进行缩放来弱化 outlier 的影响。
参数包括:with_centering, with_scaling, quantile_range, copy
with_centering:布尔值,默认为 True,表示在缩放之前将数据居中。若使用稀疏矩阵时,这将导致转换引发异常,因为将它们居中需要建立一个密集的矩阵,在通常的使用情况下,该矩阵可能太大而无法容纳在内存中;
with_scaling : 布尔值,默认为True,表示将数据缩放到四分位数范围;
quantile_range : 元组,默认值为(25.0, 75.0)即 IQR,表示用于计算 scale_的分位数范围;
copy : 布尔值,默认为True,可选参数,表示拷贝一份数据以避免在原数据上进行操作,若设置为 False 执行插入行规范化并避免复制。
属性包括:center_, scale_
center_ :训练集中每个属性的中位数;
scale_ :训练集中每个属性的四分位间距。
refit_score = "f1_score"start_time = datetime.datetime.now()
print(start_time)
rd_search = RandomizedSearchCV(xgb, param_grid, n_iter=10, cv=3, refit=refit_score, scoring=scorers, verbose=10, return_train_score=True)
rd_search.fit(X_train, y_train)
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
print(datetime.datetime.now() - start_time)网格搜索 (GridSearchCV)
1.在网格空间中搜索
用法:先选择模型,再将参数转化为字典,然后对GridSearchCV进行示例化,接下来就是日常操作——训练模型,求测评分数。
随机搜索 (RandomizedSearchCV)
当探索相对较少的组合时,就像前面的例子,网格搜索还可以。但是当超参数的搜索空间很大时,最好使用RandomizedSearchCV 。这个类的使用方法和类 GridSearchCV 很相似,但它不是尝试所有可能的组合,而是通过选择每个超参数的一个随机值的特定数量的随机组合。
## 训练集与测试集划分 ##
print("划分训练集与测试集中...")
input_train, input_test, label_train, label_test = prepare_train_test_data(data=data, target_col='Target', test_size=0.30)## RandomForestClassifier模型初始化 ##
parameters = {'random_state': 21}
rf = RandomForestClassifier(**parameters)## 超参调优 ##
print("\n超参调优中...")
strat_kfold = StratifiedKFold(n_splits=3, shuffle=True, random_state=21) # k折交叉验证
grid = {'n_estimators': range(10, 200, 10),'max_depth': range(1, 10),'min_samples_split': range(2, 10)
}
grid_search = RandomizedSearchCV(rf, param_distributions=grid,cv=strat_kfold, n_iter=10, scoring='f1',verbose=1, n_jobs=-1, random_state=21) # 随机搜索以实现超参数调优
start_time = time.time()
grid_search.fit(input_train, label_train)
end_time = time.time()
used_time = end_time - start_timeprint("Done!\n模型拟合时间:%.3f seconds" % used_time)
print("最佳超参数:", grid_search.best_params_)
print("最大AUC面积: %.5f" % grid_search.best_score_)## 模型预测 ##
rf = grid_search.best_estimator_
prob = rf.predict_proba(input_test)[:, 1]
pred = pd.Series(rf.predict(input_test), name='Target')## 模型评估并输出 ##
prc = precision_score(label_test, pred)
rec = recall_score(label_test, pred)
auc = roc_auc_score(label_test, prob)
f1 = f1_score(label_test, pred)print("训练结果的混淆矩阵:")
print(pd.DataFrame(confusion_matrix(label_test, pred),columns=['预测假', '预测真'], index=['假', '真']))
print()
print("查准率:%.6f" % prc) # 查准率 = 真阳/(真阳 + 假阳)
print("召回率:%.6f" % rec) # 召回率 = 真阳/(真阳 + 假阴)
print("准确率:%.6f" % auc) # 准确率 = (真阳 + 真阴)/(真阳 + 真阴+ 假阳+ 假阴)
print("F1值 :%.6f" % f1) # F1值 = 2 x (查准率 x 召回率) / (查准率 + 召回率)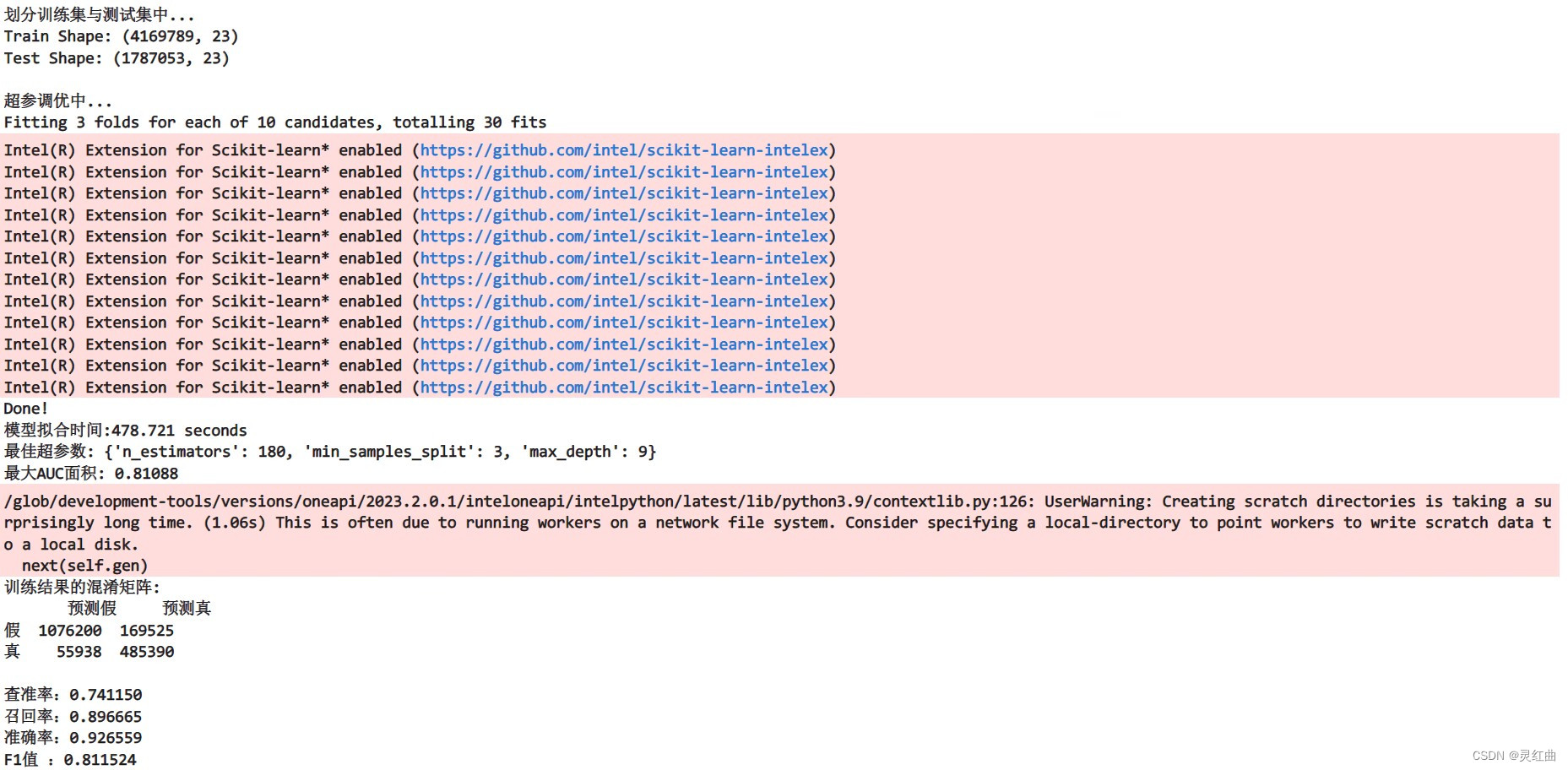
# 数据读取
test = pandas.read_csv('./_Test/test_data.csv')# 缺失值处理
pretreat(test)# 划分特征与标签并归一化
input1, input2, label1, label2 = prepare_train_test_data(data=test, target_col='Target', test_size=0.30)
inputs = np.append(input1, input2, axis=0)
labels = np.append(label1, label2, axis=0)构建好的模型需要部署到实际环境中进行推理预测。oneAPI支持多种部署方式,包括云端、边缘端等,可以根据实际需求进行选择。此外,oneAPI还提供了性能优化和安全性保障等功能,确保模型在实际运行中的稳定性和准确性。
另一种算法
## 模型预测 ##
start_time = time.time()
prob = rf.predict_proba(inputs)[:, 1]
pred = pd.Series(rf.predict(inputs), name='Target')
end_time = time.time()
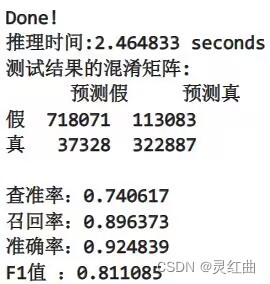
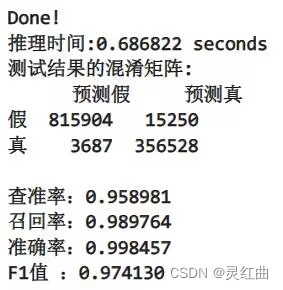
used_time = end_time - start_timeprint("Done!\n推理时间:%.6f seconds" % used_time)## 模型评估并输出 ##
prc = precision_score(labels, pred)
rec = recall_score(labels, pred)
auc = roc_auc_score(labels, prob)
f1 = f1_score(labels, pred)print("测试结果的混淆矩阵:")
print(pd.DataFrame(confusion_matrix(labels, pred),columns=['预测假', '预测真'], index=['假', '真']))
print()
print("查准率:%.6f" % prc) # 查准率 = 真阳/(真阳 + 假阳)
print("召回率:%.6f" % rec) # 召回率 = 真阳/(真阳 + 假阴)
print("准确率:%.6f" % auc) # 准确率 = (真阳 + 真阴)/(真阳 + 真阴+ 假阳+ 假阴)
print("F1值 :%.6f" % f1) # F1值 = 2 x (查准率 x 召回率) / (查准率 + 召回率)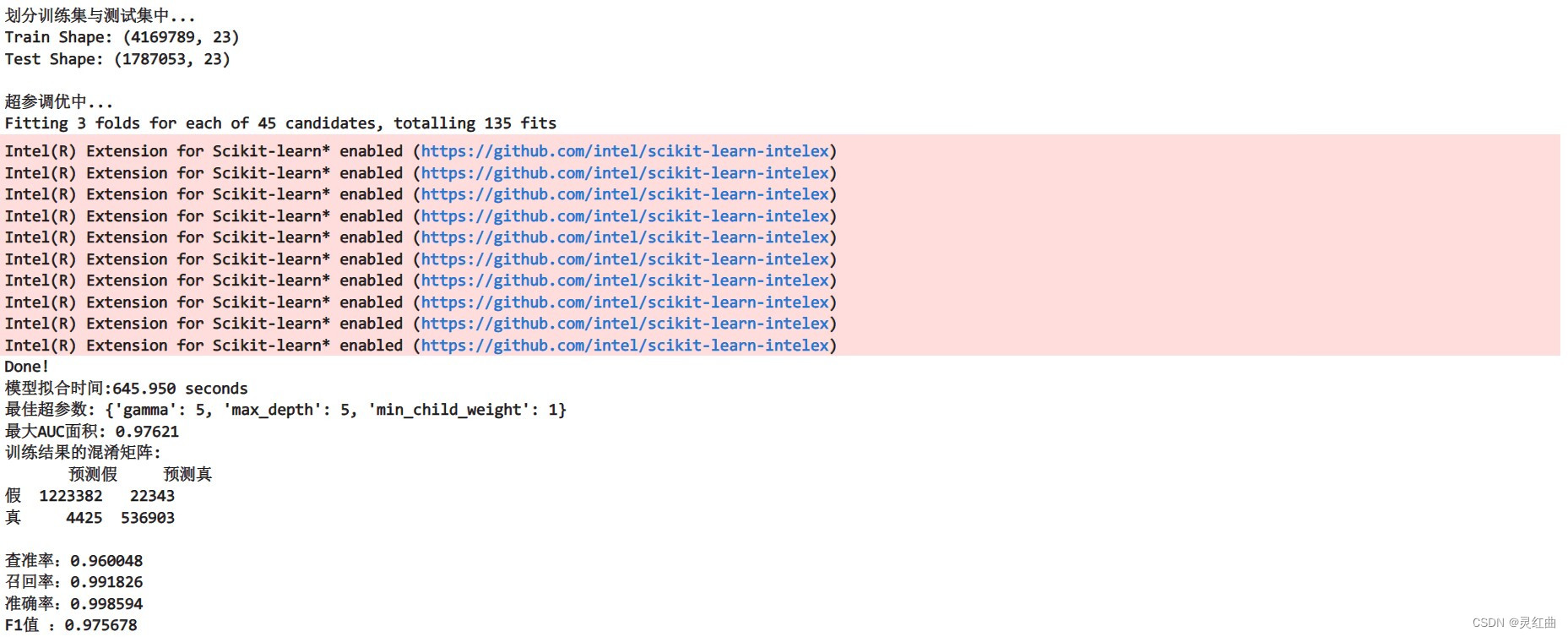
- 优势
(1)跨平台性:oneAPI支持多种操作系统和硬件架构,使得开发者可以在不同平台上进行开发和部署,提高了开发的灵活性和便利性。
(2)高效性:oneAPI提供了优化的计算库和底层硬件支持,可以充分利用硬件资源,提高模型的训练和推理速度。
(3)易用性:oneAPI提供了统一的编程接口和丰富的工具链,降低了开发难度和学习成本,使得开发者可以更加专注于业务逻辑的实现。
- 局限性
(1)技术门槛:虽然oneAPI提供了统一的编程接口,但对于初学者来说仍然需要一定的学习成本。同时,对于复杂的淡水质量预测问题,还需要具备深厚的机器学习和数据处理知识。
(2)数据依赖:淡水质量预测的准确性在很大程度上取决于数据的质量和数量。如果数据不足或者质量不高,可能会影响模型的预测效果。
总结
oneAPI作为一种跨平台、跨架构的编程接口,在淡水质量预测问题中发挥了重要作用。它提供了高效的数据处理、模型构建和部署等功能,为淡水质量的准确预测提供了有力支持。然而,也需要注意到oneAPI在技术门槛和数据依赖方面的局限性。未来,随着技术的不断进步和数据的不断积累,相信oneAPI在淡水质量预测领域的应用将会更加广泛和深入。
同时,我们也应该关注到淡水质量预测问题的复杂性和多样性。在实际应用中,可能需要结合多种技术和方法来进行综合分析和预测。因此,未来的研究和实践应该更加注重跨领域合作和创新,以推动淡水质量预测技术的不断发展和完善。
这篇关于【Intel校企合作项目】预测淡水质量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









