本文主要是介绍【爬虫实战】使用Python获取花粉俱乐部中Mate60系列的用户发帖数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、Python编写爬虫的优势
二、实验过程
2.1明确目标
2.2抓包分析
2.3代码编写
三、总结
文末推荐
一、Python编写爬虫的优势
- 易学易用:Python的语法简单明了,易于理解和学习,使得编写爬虫变得简单容易。
- 强大的第三方库:Python有很多强大的第三方库,如requests、BeautifulSoup、Scrapy、Selenium等,可以帮助我们轻松实现网页的请求、解析和数据的提取等功能。
- 跨平台性:Python可运行于Windows、Linux、macOS等多个操作系统上,使得在多个平台上编写和运行爬虫变得简单容易。
- 处理文本信息方便:Python对文本处理非常方便,支持多种文本编码,可以轻松实现数据的清洗和去重。
- 丰富的数据处理和分析工具:Python拥有众多的数据处理和分析工具,如NumPy、Pandas、Matplotlib等,可以对爬取的数据进行深入的分析和处理。
- 自动化:Python可以轻松实现自动化,可以自动执行爬取任务,定时发送邮件等,大大提高工作效率。
- 反爬虫机制容易应对:Python可以通过设置User-Agent、Cookie等方式来模拟浏览器行为,避免被目标网站的反爬虫机制识别和封锁。
二、实验过程
2.1明确目标
本次实验我们的任务是获取华为社区(花粉俱乐部)中Mate60手机社区中的用户发帖数据
首先点击链接进入花粉俱乐部并找到Mete60系列https://cn.club.vmall.com/mhw/consumer/cn/community/mhwnews/allcirclehome/
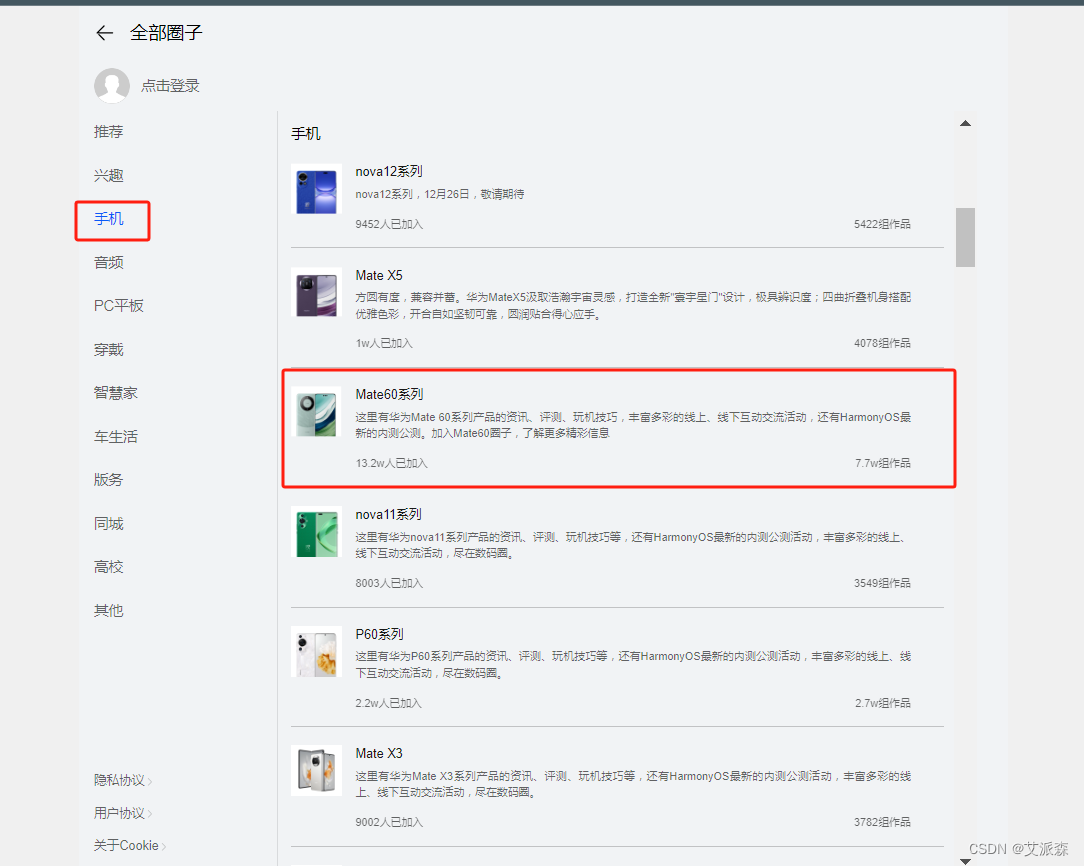
进入之后我们可以看到里面有很多用户的发帖数据,我们先获取热门下面的帖子数据
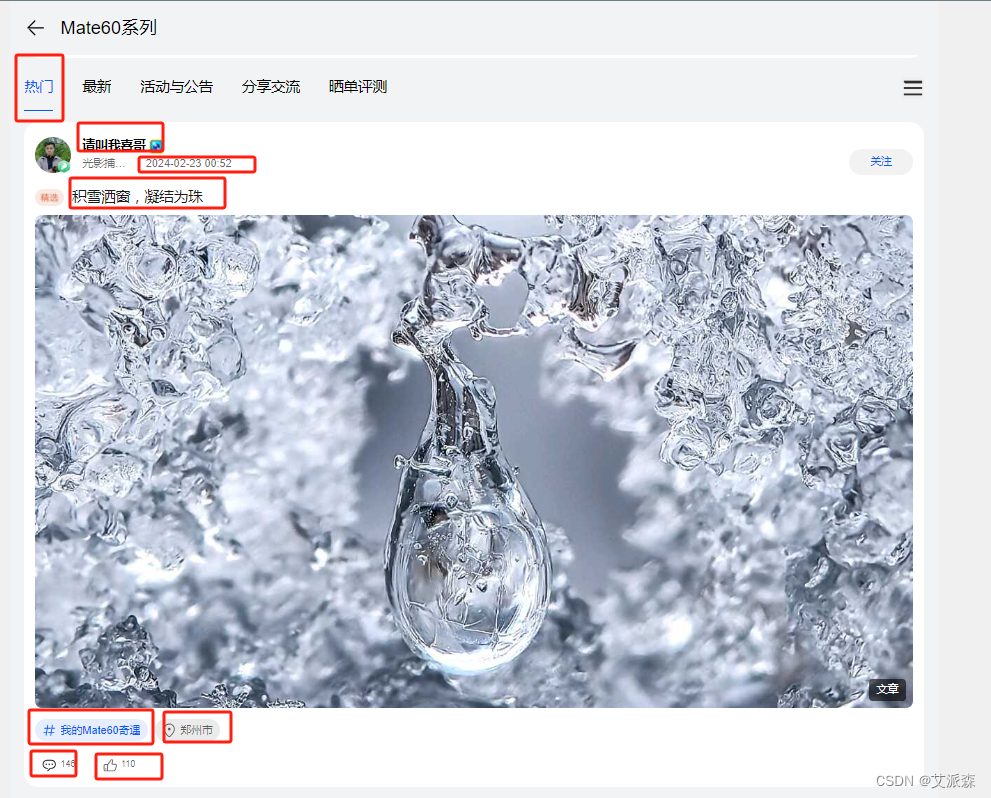
2.2抓包分析
在明确了目标之后,我们将需要对网页的页面结构进行分析,找出目标数据的来源接口,然后模拟客户端想服务端发送请求即可。
①打开开发者工具(按F12或鼠标右键) ②刷新页面并复制一小段评论内容 ③点击搜索框 ④将复制的内容粘贴进行并确定⑤点击出现的第一个接口 ⑥在名称列表找到该接口(有灰色背景阴影的) ⑦点击预览然后一直点击小三角展开,你就会发现我们要找到数据来源就是这个接口,并且该接口返回的是json格式的数据

接着分析该接口需要的参数,经过简单的测试分析后,我们会发现pageindex参数控制的是页码数,一页有20条数据

2.3代码编写
前面我们已经分析了数据的来源接口以及参数,接着就需要编写代码。
首先我们右键点击接口-复制-以cURL(bash)格式复制
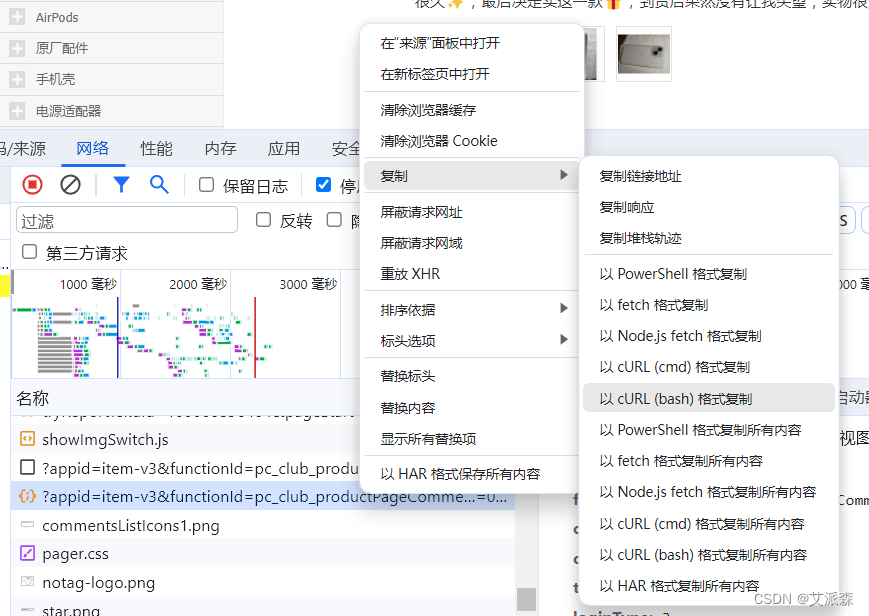
复制好后,我们借助一个接口解析工具,Convert curl commands to code
将复制的内容粘贴进对话框内
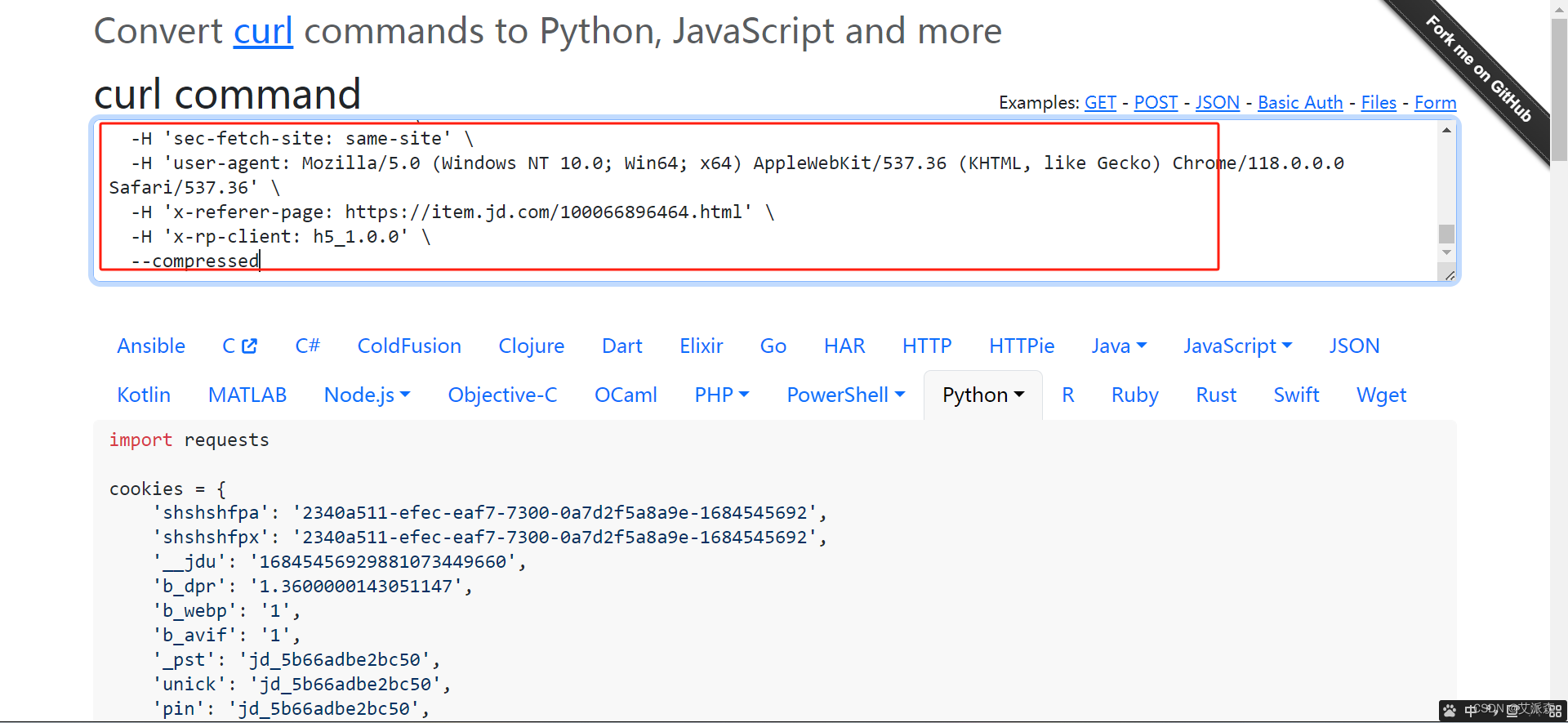
然后往下滑,点击Copy to clipboard,就是复制它已经解析好的代码
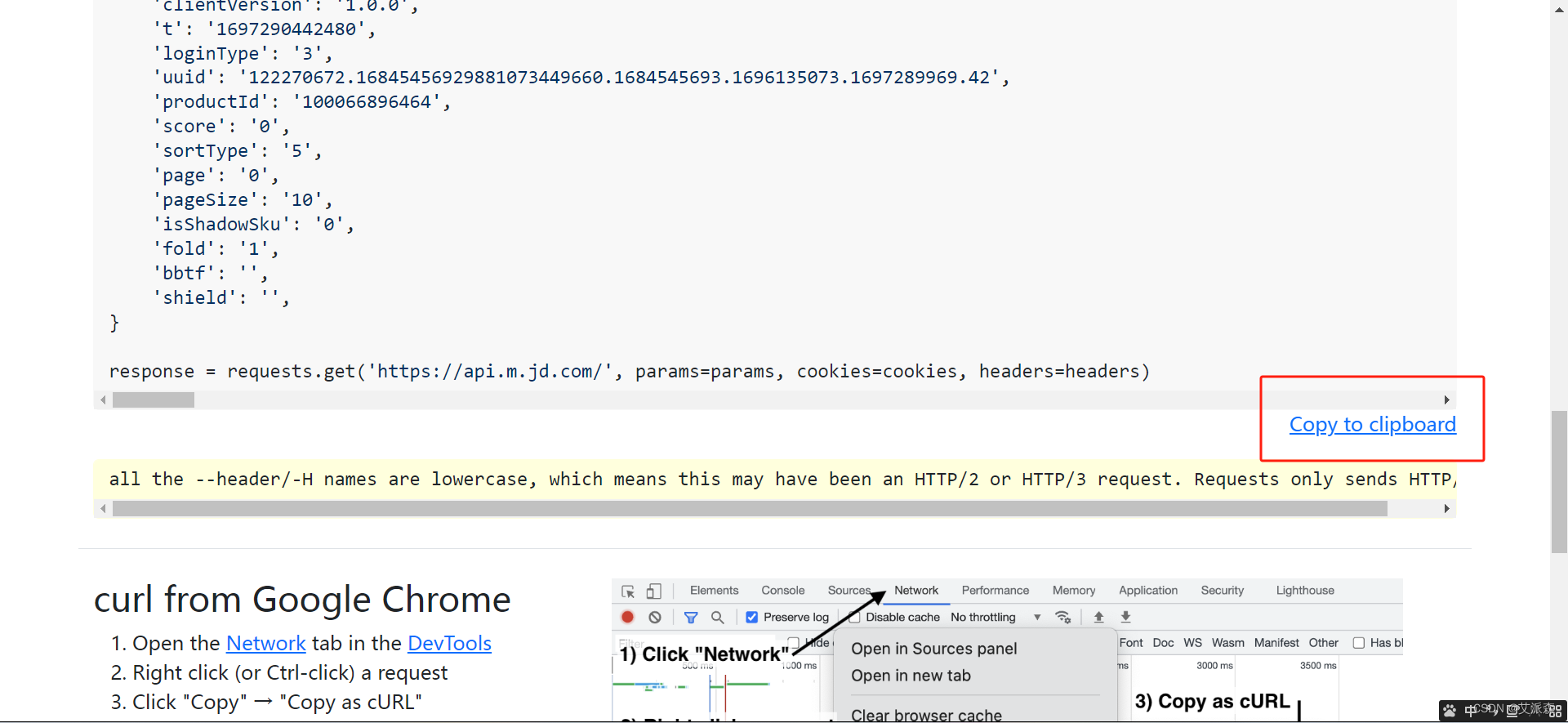
然后直接粘贴进你的py代码中
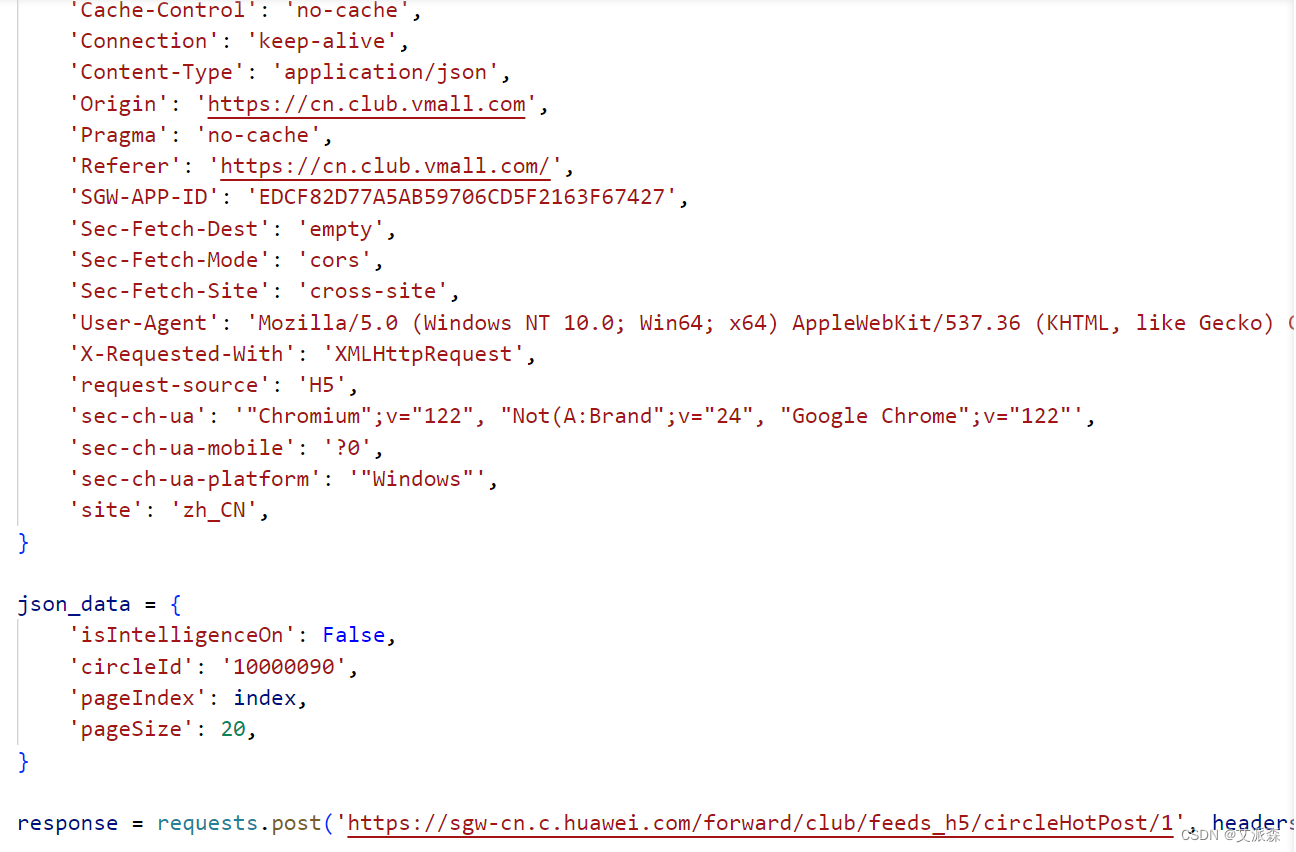
它已经帮我们把请求发生代码写好了,我们只需要对返回的数据进行解析即可。响应的数据是json格式,直接使用字典的取值方法即可。其中字段缺失的数据我们定义为Nan空,并将时间戳数据转化为时间类型,这里我们获取了用户名,用户ID,发帖时间,发帖内容,粉丝数,点赞数,评论数,阅读量等字段数据。
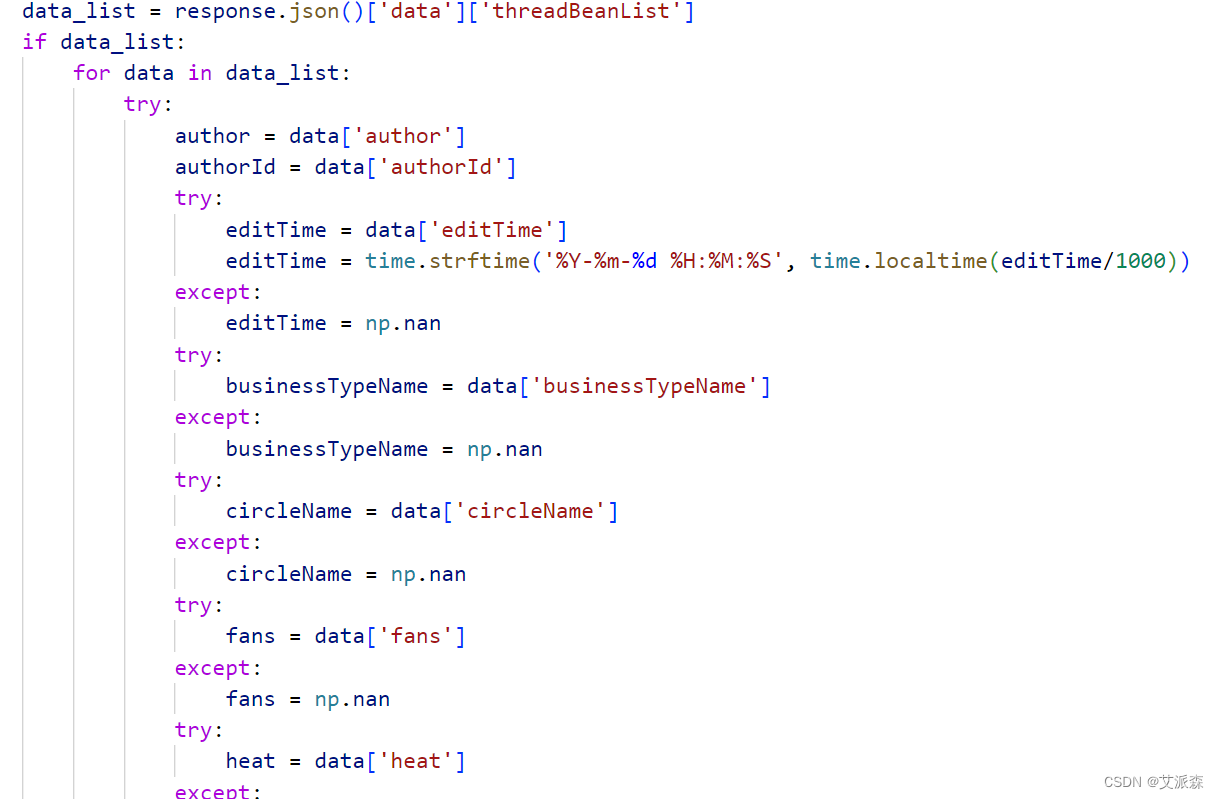
数据存储的话我们使用csv文件进行写入,最后再转化为excel文件

当检测到返回的数据为空时,也就是达到了网站爬取的最大上限时,我们停止爬取并保存文件。
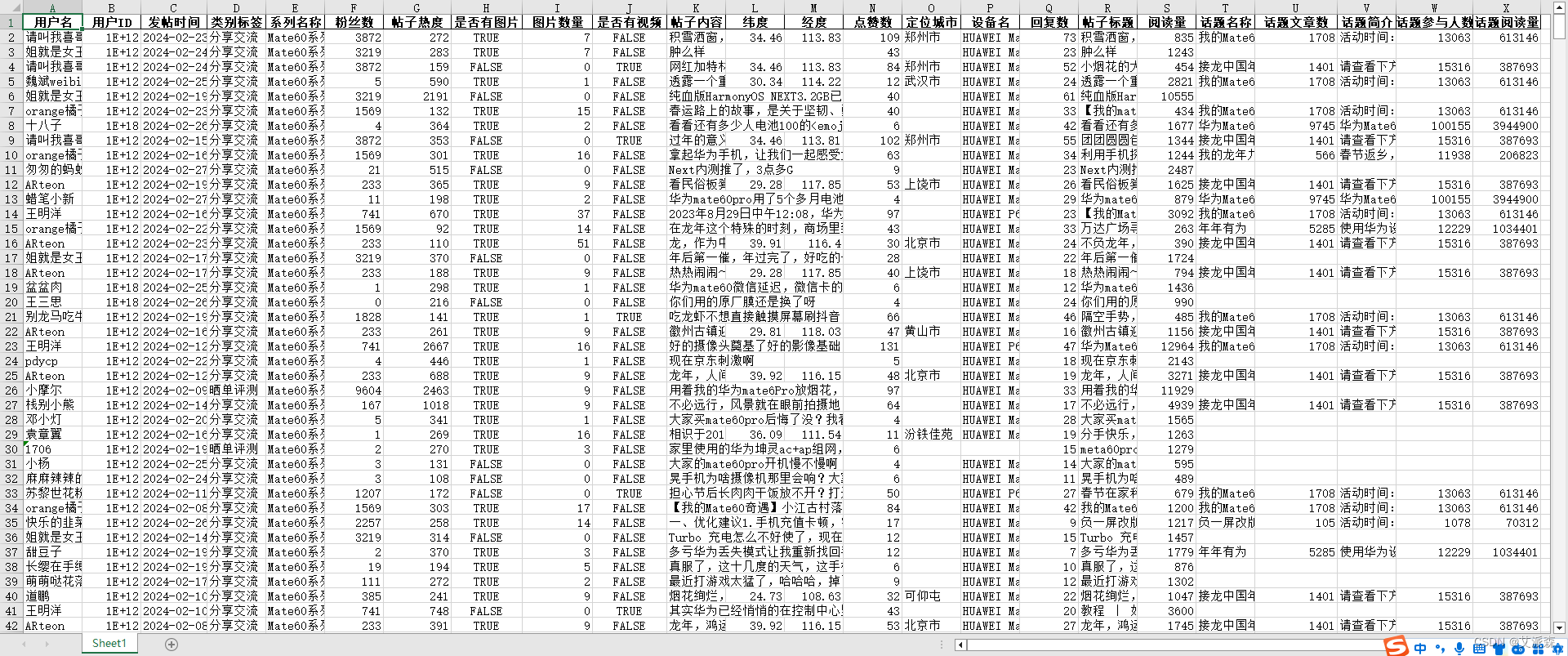
运行结果如下:

三、总结
本次实验我们使用python爬虫获取了花粉俱乐部中Mate60系列的用户发帖数据,并保存在本地,后续便可进行各样的分析与研究。感兴趣的小伙伴可以关注文末公众号并加入粉丝群领取完整代码或交流讨论。
文末推荐

资料获取,更多粉丝福利,关注下方公众号获取

这篇关于【爬虫实战】使用Python获取花粉俱乐部中Mate60系列的用户发帖数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






