本文主要是介绍淘客消费者行为,深入分析。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.引言
1.1.目标
1.2.流程
1.3.数据解释
2.数据清洗(1.2.流程的第一步)
2.数据可视化及数据分析(1.2.流程的第二步)
2.1.计算UV及PV值及可视化
2.2.计算购买浏览的值及可视化
2.3.按日计算PV及UV值及可视化
2.4计算PV及UV的同比并可视化
2.5计算平均访问深度并可视化
2.6.按小时计算PV及UV并可视化
2.7.计算转化率并可视化漏斗模型
3.建议(1.2.流程的第三步)
3.1.多举办类似与双十二的活动
3.2.按流量安排人手。
3.3.流量投放-价格歧视
4.总结
1.引言
1.1.目标
此报告会使用Panda,Matplotlip,复购率,转化率等概念进行数据分析,并找出有趣及有价值的趋势及特点,为淘宝公司或淘宝客户带来正面的好处。
1.2.流程
第一步:清洗数据,将空值及相关数据特征进行删除或者替换。提高数据的准确性及方便后续的分析。
第二步:数据探究及可视化。
第三步,根据可视化的图进行数据分析,并找出独特及有趣的数据特征。
1.3.数据解释
阿里云 天池数据集https://tianchi.aliyun.com/dataset/dataDetail?dataId=46
阿里巴巴提供的移动端淘宝用户的行为数据集,包含2014-11-18至2014-12-18共计一千多万条数据。
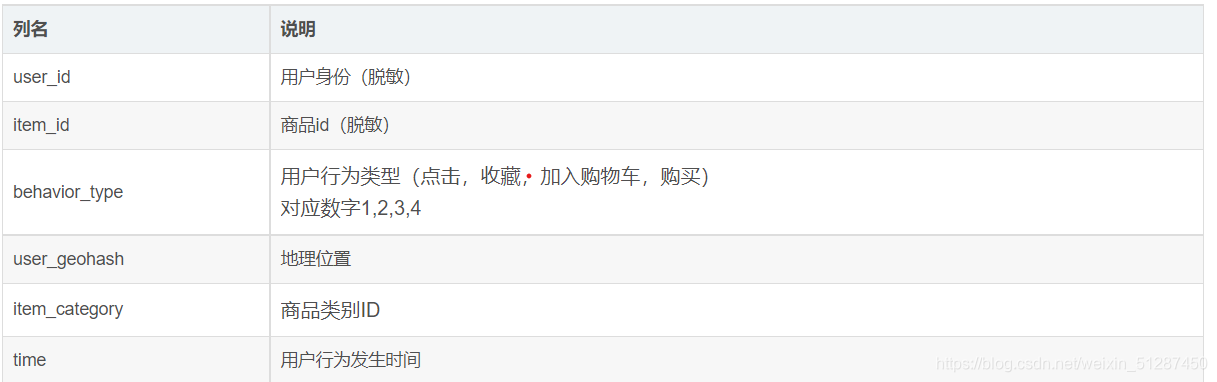
数据集的每一列描述如下:
2.数据清洗(1.2.流程的第一步)
import pandas as pd
import numpy as np
import matplotlib as pltdata = pd.read_csv("C:\\Users\\DA21\\TaoBao\\Data\\TaoBao.csv")data.head()
data.isnull().sum()
数据的user_geohash缺失值十分严重,因此会将数据去除。
data.drop(columns = "user_geohash", inplace = True )data["date"] = data["time"].str.split(" ").str[0]data["hour"] = data["time"].str.split(" ").str[1]
将数据拆分为date 及 hour,以便后续的分析
data.dtypes
查看数据类型,以便将数据格式转换成自己需要的格式。可以看到,time,date,hour都要进行转换,方便后续的分析。
#转换数据类型
data["time"] = pd.to_datetime(data["time"])
data["date"] = pd.to_datetime(data["date"])
data["hour"] = (data["hour"]).astype(int)转换相关的数据类型
#calculate the pv。只show user_id 的数量,reset_index可以将index变成 0 1 2 而不是由date座位iindex
pv_daily = data.groupby(["date"])["user_id"].count().reset_index()
pv_daily.rename(columns = {"user_id":"pv"}, inplace = True)
pv_daily

计算pv的值,并将pv写入DataFrame
2.数据可视化及数据分析(1.2.流程的第二步)
2.1.计算UV及PV值及可视化
#计算uv的值
uv_daily = data.groupby(["date"])["user_id"].apply(lambda x: x.drop_duplicates().count())
pv_uv_daily = pd.merge(pv_daily,uv_daily,on='date').rename(columns={'user_id':'uv'})
pv_uv_daily
# PV、UV 可视化处理(按日绘制)
import matplotlib.pyplot as plt
plt.style.use('ggplot')x = pd.date_range(data.date.min(),data.date.max())
pv = pv_uv_daily["pv"]
uv = pv_uv_daily["uv"]
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,pv,color='yellow')
line2, = ax2.plot(x,uv,color='red')ax1.set_xlabel("date",fontsize = 20)
ax1.set_ylabel("pv_count",fontsize = 15)
ax2.set_ylabel("uv_count",fontsize = 15)plt.grid(True,alpha=0.4)
ax1.set_title('PV及UV的分布.',fontsize= 30,color='black')
fig.autofmt_xdate(rotation=45 ) plt.legend((line1,line2),('pv','uv'),fontsize=20)
plt.show() 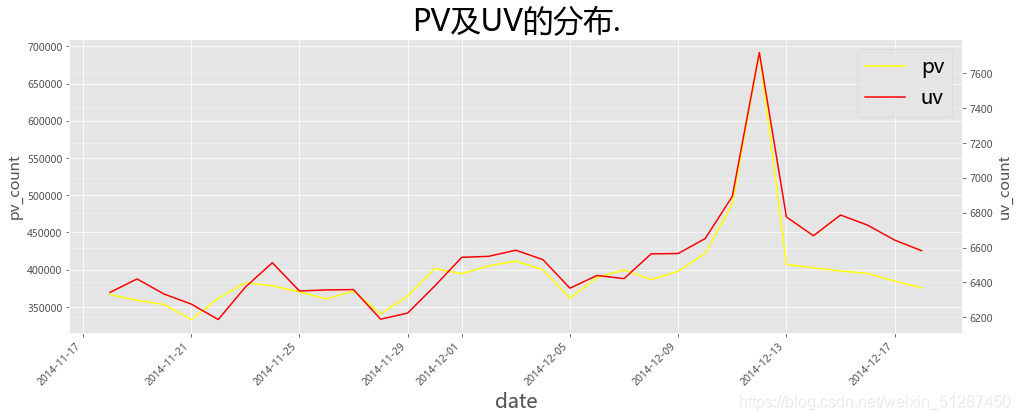
数据解释:PV及UV从2014-11-17的360,000 及6,500反复上升至2014-12-09的420,000及6,600,保持正常的流量波动。从2014-12-09,PV及UV数值从420,000及6,600,高速上升到2014-12-12日的700,000及7,600上升了0.67倍。
2.2.计算购买浏览的值及可视化
#behavior——type转换成确切的文字
data["behavior_type"] = data["behavior_type"].replace(1,"浏览")
data["behavior_type"] = data["behavior_type"].replace(2,"收藏")
data["behavior_type"] = data["behavior_type"].replace(3,"加购")
data["behavior_type"] = data["behavior_type"].replace(4,"购买")#计算unique的购买人数
data_purchase = data[data["behavior_type"].isin(["购买"])].drop_duplicates().reset_index()
data_purchase = data_purchase.groupby(["date"])["behavior_type"].count().reset_index().rename(columns={'behavior_type':'购买'})#计算unique的收藏人数
data_favor = data[data["behavior_type"].isin(["收藏"])].drop_duplicates().reset_index()
data_favor = data_favor.groupby(["date"])["behavior_type"].count().reset_index().rename(columns={'behavior_type':'收藏'})#计算unique的浏览人数
data_browse = data[data["behavior_type"].isin(["浏览"])].drop_duplicates().reset_index()
data_browse = data_browse.groupby(["date"])["behavior_type"].count().reset_index().rename(columns={'behavior_type':'浏览'})#计算unique的加购人数
data_repurchase = data[data["behavior_type"].isin(["加购"])].drop_duplicates().reset_index()
data_repurchase = data_repurchase.groupby(["date"])["behavior_type"].count().reset_index().rename(columns={'behavior_type':'加购'})
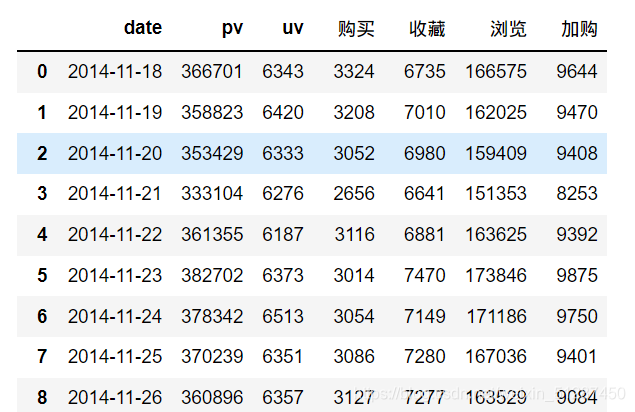
# PV、behavior type 可视化处理(按日绘制)
import matplotlib.pyplot as plt
# plt.style.use('ggplot')x = pd.date_range(data.date.min(),data.date.max())
behavior_purchase = data_uv_information["购买"]
uv = pv_uv_daily["uv"]
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,behavior_purchase,color='yellow')
line2, = ax2.plot(x,uv,color='red')ax1.set_xlabel("date",fontsize = 20)
ax1.set_ylabel("puchase_count",fontsize = 15)
ax2.set_ylabel("uv_count",fontsize = 15)plt.grid(True,alpha=0.4)plt.legend((line1,line2),('puchase_count','uv'),fontsize=20)
plt.show() 
数据解释:UV及购买次数从2014-11-17的3,800 及6,300反复上升至2014-12-09的6,000及6,600,保持正常的流量波动。从2014-12-09,PV及UV数值从6,000及6,600,,高速上升到2014-12-12日的13,000及7,600上升了1.12倍。
2.3.按日计算PV及UV值及可视化
# PV、behavior type 可视化处理(按日绘制)
import matplotlib.pyplot as plt
# plt.style.use('ggplot')x = pd.date_range(data.date.min(),data.date.max())
behavior_purchase = data_uv_information["收藏"]
uv = pv_uv_daily["uv"]
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,behavior_purchase,color='yellow')
line2, = ax2.plot(x,uv,color='red')ax1.set_xlabel("date",fontsize = 20)
ax1.set_ylabel("favor_count",fontsize = 15)
ax2.set_ylabel("uv_count",fontsize = 15)plt.grid(True,alpha=0.4)plt.legend((line1,line2),('favor_count','uv'),fontsize=20)
plt.show() 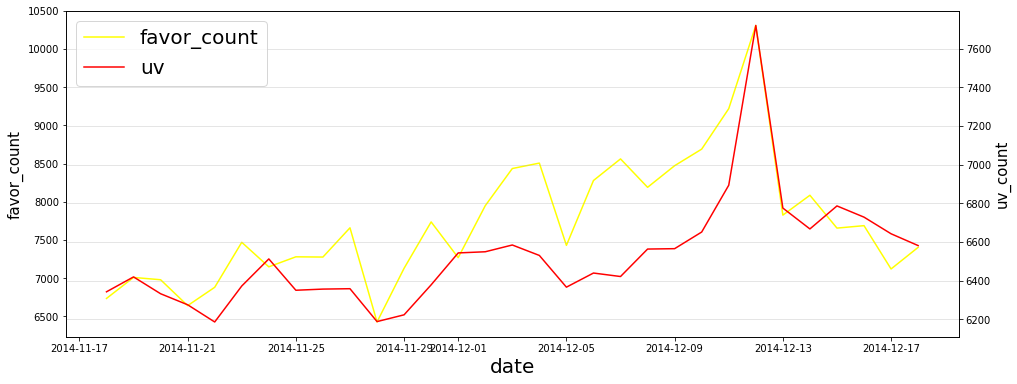
数据解释:UV及购买次数从2014-11-17的3,800 及6,300反复上升至2014-12-09的6,000及7,000,保持正常的流量波动。从2014-12-09,PV及UV数值从6,000及7,000,,高速上升到2014-12-12日的13,000及7,600上升了1.16倍。
#
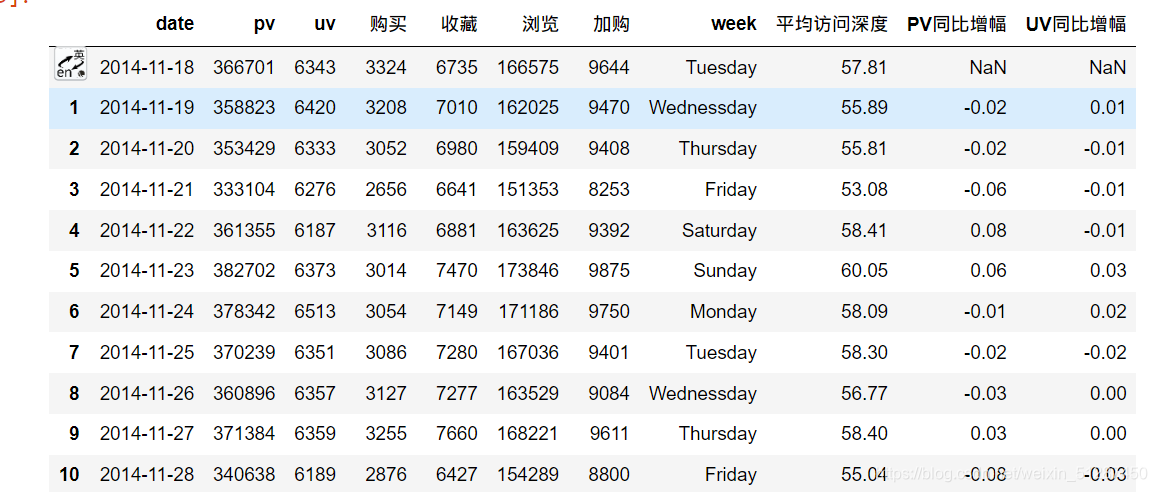
data_uv_information["week"] = data_uv_information['date'].dt.dayofweek#转化日期为礼拜
#但是转化完,是 0 1 2 3 4的形式,所以我会进行相关数值的转换
data_uv_information["week"] = data_uv_information["week"].replace(0,"Monday")
data_uv_information["week"] = data_uv_information["week"].replace(1,"Tuesday")
data_uv_information["week"] = data_uv_information["week"].replace(2,"Wednessday")
data_uv_information["week"] = data_uv_information["week"].replace(3,"Thursday")
data_uv_information["week"] = data_uv_information["week"].replace(4,"Friday")
data_uv_information["week"] = data_uv_information["week"].replace(5,"Saturday")
data_uv_information["week"] = data_uv_information["week"].replace(6,"Sunday")#计算平均访问深度,按月份
data_uv_information["平均访问深度"] = round(data_uv_information["pv"]/data_uv_information["uv"],2)
data_uv_information#计算PV同比增幅
pv_yesterday = data_uv_information["pv"].shift(1)
data_uv_information["PV同比增幅"] = round((data_uv_information["pv"] - pv_yesterday)/pv_yesterday,2)#计算UV同比增幅
uv_yesterday = data_uv_information["uv"].shift(1)
data_uv_information["UV同比增幅"] = round((data_uv_information["uv"] - uv_yesterday)/uv_yesterday,2)
data_uv_information2.4计算PV及UV的同比并可视化
# PV、behavior type 可视化处理(按日绘制)import matplotlib.pyplot as plt
# plt.style.use('ggplot')x = pd.date_range(data.date.min(),data.date.max())
pv = data_uv_information["pv"]
PV_increase = data_uv_information["PV同比增幅"]
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,pv,color='yellow')line2, = ax2.plot(x,PV_increase,color='red')ax1.set_xlabel("date",fontsize = 20)
ax1.set_ylabel("PV",fontsize = 15)
ax2.set_ylabel("PV_increase",fontsize = 15)plt.grid(True,alpha=0.4)
ax1.set_title('PV的增高比率',fontsize= 30,color='black')
fig.autofmt_xdate(rotation=45 ) plt.legend((line1,line2),('PV_Increase','uv'),fontsize=20)
plt.show() 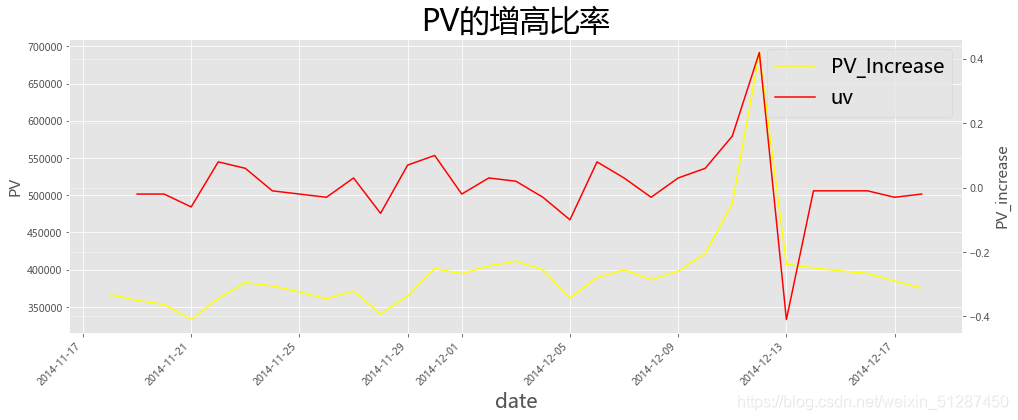
数据解释:PV的增幅从2014-11-17至2014-12-09都是维持在 -1% 到 1%的正常波动。但,从2014-12-09,PV的增幅从0%持续上升至2014-12-12的3%,上升了2倍左右,属于高增幅。
# PV、behavior type 可视化处理(按日绘制)
1# 创建子视图对象import matplotlib.pyplot as plt
# plt.style.use('ggplot')x = pd.date_range(data.date.min(),data.date.max())
uv = data_uv_information["uv"]
uv_increase = data_uv_information["UV同比增幅"]
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,uv,color='yellow')line2, = ax2.plot(x,uv_increase,color='red')ax1.set_xlabel("date",fontsize = 20)
ax1.set_ylabel("PV",fontsize = 15)
ax2.set_ylabel("uv_increase",fontsize = 15)plt.grid(True,alpha=0.4)
ax1.set_title('UV的提高比率',fontsize= 30,color='black')
fig.autofmt_xdate(rotation=45 )
plt.legend((line1,line2),('UV','UV_Increase'),fontsize=20)
plt.show()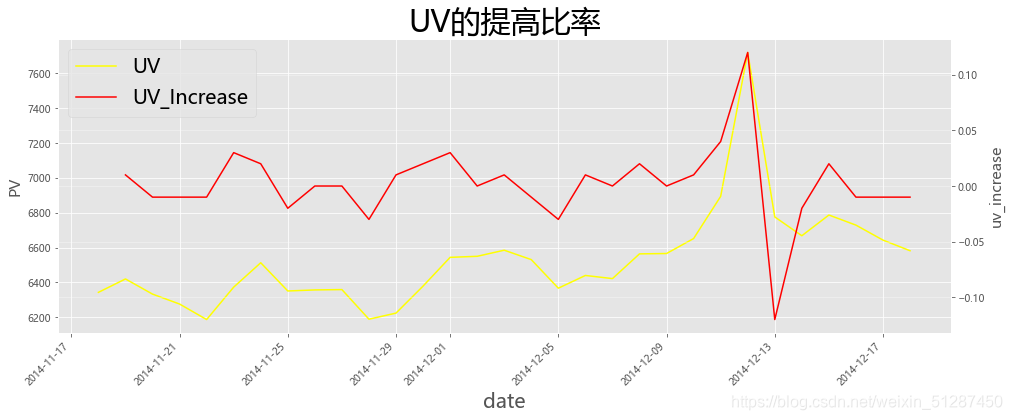
数据解释:PV的增幅从2014-11-17至2014-12-09都是维持在 -0.07% 到 -0.05%的正常波动。但,从2014-12-09,PV的增幅从-0.05%持续上升至2014-12-12的1%,上升了1倍左右,属于高增幅。可见,在此期间,更多的人用户使用淘宝的网购平台。
2.5计算平均访问深度并可视化
#平均访问深度按月日计算
import matplotlib as mpl
mpl.rcParams['font.family']='Microsoft YaHei'
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.style.use('ggplot')
x = pd.date_range(data.date.min(),data.date.max())
y = data_uv_information["平均访问深度"]plt.plot(x,y)
plt.xticks(rotation = 90)
plt.xlabel("date")
plt.ylabel("adverage visit depth")
plt.title("平均访问深度",fontsize=20)
数据解释:平均访问深度从2014-12-07的60,持续上升至从2014-12-12的90,增长了0.5倍,可见用户更愿意花时间在购物平台上,而不是打开淘宝,看一眼就走。当平均访问深度提高,代表顾客对淘宝公司的服务及商品都有较大的满意度及吸引度,更加容易提升顾客的购买几率。
#按日进行计算
#计算pv,uv
data_week_pv = data_uv_information.groupby(["week"])["pv"].sum().reset_index()
data_week_uv = data_uv_information.groupby(["week"])["uv"].sum().reset_index()
# pv_uv_daily = pd.merge(pv_daily,uv_daily,on='date').rename(columns={'user_id':'uv'})#计算unique的购买人数
data_week_purchase = data_uv_information.groupby(["week"])["购买"].sum().reset_index()#计算unique的收藏人数
data_week_favor = data_uv_information.groupby(["week"])["收藏"].sum().reset_index()#计算unique的浏览人数
data_week_browse = data_uv_information.groupby(["week"])["浏览"].sum().reset_index()#计算unique的加购人数
data_week_repurchase = data_uv_information.groupby(["week"])["加购"].sum().reset_index()#计算平均访问深度from functools import reduce
#将多表进行合并。
df_1 = [data_week_pv,data_week_uv,data_week_purchase,data_week_favor,data_week_browse,data_week_repurchase]data_week_information= reduce(lambda left,right: pd.merge(left,right,on=['week']), df_1)#计算平均访问深度
data_week_information["平均访问深度"] = round(data_week_information["pv"]/data_week_information['uv'],2)
data_week_information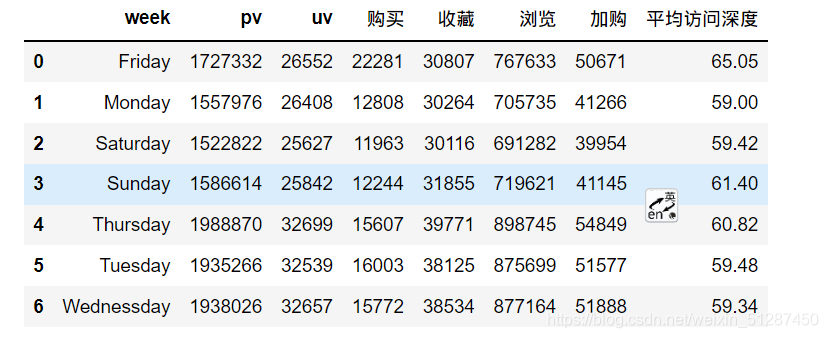
#按日计算相关的值浏览量,收藏车等,看看流量在那些天有所上升
import matplotlib as mpl
mpl.rcParams['font.family']='Microsoft YaHei'
fig,ax1=plt.subplots(figsize=(20,5))
x = np.arange(0,7)
week_browse = data_week_information["浏览"]
week_repurchase = data_week_information["加购"]
week_purchase = data_week_information["购买"]
week_favor = data_week_information["收藏"]
ax2 = ax1.twinx()
line1, = ax1.plot(x,week_purchase,color='steelblue')
line2, = ax2.plot(x,week_repurchase,color='red',alpha=0.8)
line3, = ax1.plot(x,week_browse,color='steelblue',alpha=0.6)
line4, = ax2.plot(x,week_favor,color='yellow',alpha=0.5)
plt.xticks(x,["Monday","Tuesday","Wednessday","Thursday","Friday","Saturday","Sunday"],fontsize=15)
plt.legend((line1,line2,line3,line4),('week_browse','repeated_purchase','week_purchase','Add To shopping_bag'),fontsize=15,loc= "lower left")
ax1.set_xlabel('weekday',fontsize=15)
ax1.set_ylabel('$',color='steelblue',fontsize=15)
ax1.set_title("每日的消费者行为",fontsize= 30,color='black')
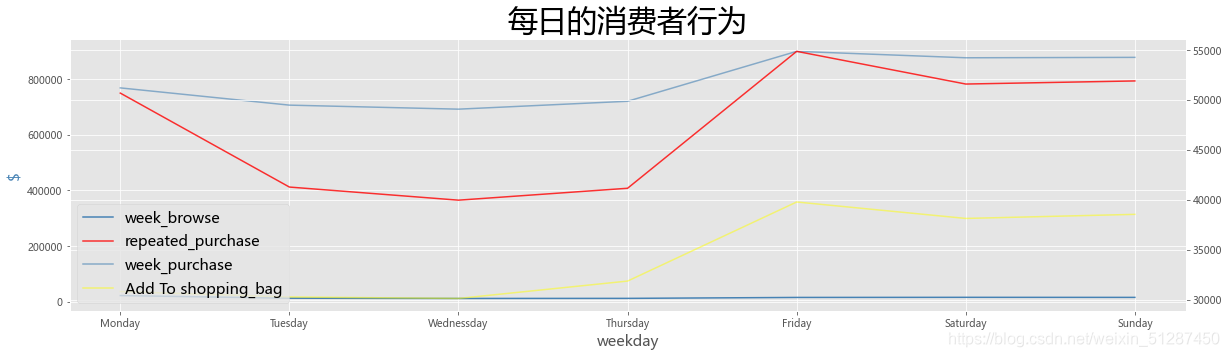
数据解释:从上图可见,每逢礼拜五,淘宝的浏览量,购买量以及重复购买量都属于最高点。说明顾客大多会在礼拜五使用淘宝的服务,并发生一系列的操作,比如购买行为。
#按日看看平均访问深度
import matplotlib as mpl
mpl.rcParams['font.family']='Microsoft YaHei'
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
x = range(0,7)
y = data_week_information["平均访问深度"]
plt.plot(x,y)
plt.xticks(x,["Monday","Tuesday","Wednessday","Thursday","Friday","Saturday","Sunday"])
plt.xlabel("week")
plt.ylabel("average_visit_depth")
plt.title("日平均访问深度",fontsize=20 ) 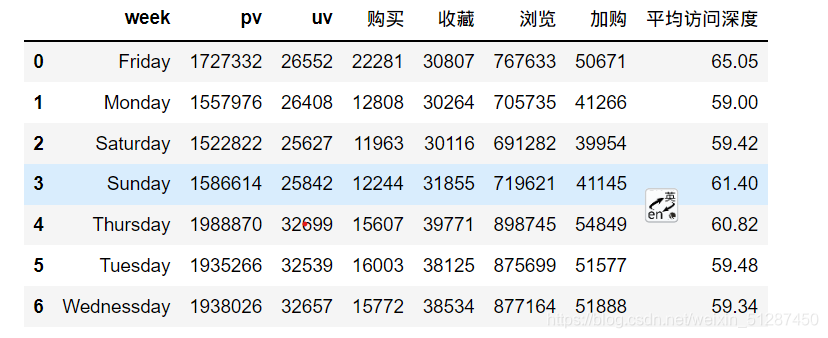
2.6.按小时计算PV及UV并可视化
x = data["hour"].unique()
#根据小时计算pv
pv_hour = data.groupby(["hour"])["user_id"].count().reset_index()
pv_hour.rename(columns = {"user_id":"pv"}, inplace = True)#根据小时计算uv
uv_hour = data.groupby(["hour"])["user_id"].apply(lambda x: x.drop_duplicates().count()).reset_index().rename(columns={"user_id":"uv"})#将uv 和 pv 合并在一个表格
pv_hour["uv"] = uv_hour["uv"]
information_pv_uv_hour = pv_hour
def change_hour_name(hour_int,name):information_pv_uv_hour["hour"] = information_pv_uv_hour["hour"].replace(hour_int,name)hour_name = ["十二点","一点","两点","三点","四点","五点","六点","七点","八点","九点","十点","十一点","十二点","十三点","十四点","十五点","十六点","十七点","十八点","十九点","二十点","二十一点","二十二点","二十三点"] for i in (range(0,24)):change_hour_name(i,hour_name[i])
information_pv_uv_hour
#按hour计算PV及UV的值,看看流量在那些天有所上升# PV、UV 可视化处理(按日绘制)
import matplotlib.pyplot as plt
# plt.style.use('ggplot')x = ["12am","1:am","2am","3am","4am","5am","6am","7am","8am","9am","10am","11am","12pm","1pm","2pm","3pm","4pm","5pm","6pm","7pm","8pm","9pm","10pm","11pm"]
pv_hour = information_pv_uv_hour["pv"]
uv_hour = information_pv_uv_hour["uv"]
fig, ax1 = plt.subplots(figsize=(16,6))
ax2 = ax1.twinx()
line1, = ax1.plot(x,pv_hour,color='yellow')
line2, = ax2.plot(x,uv_hour,color='red')ax1.set_xlabel("hour",fontsize = 20)
ax1.set_ylabel("pv_count",fontsize = 15)
ax2.set_ylabel("uv_count",fontsize = 15)plt.grid(True,alpha=0.4)
ax1.set_title('每小时的PV及UV分布',fontsize= 30,color='black')
# fig.autofmt_xdate(rotation=90 ) plt.legend((line1,line2),('pv','uv'),fontsize=20)
plt.show()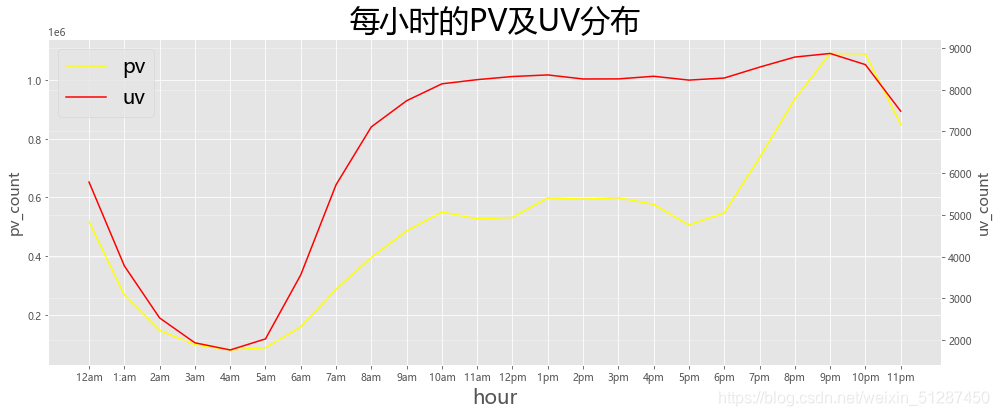
数据解释:可以看到淘宝12am的 到 5am的流量逐渐下降。反之,从5am开始从低位逐渐上升至10pm的顶点流量。这种现象,比较符合现代人的作息习惯,属于正常的现象。
2.7.计算转化率并可视化漏斗模型
data["behavior_type"].value_counts() 
把相关数值进行相加,以便后续计算漏斗模型用
#建立浏览量为主的表格,并为之后计算漏斗作准备
conversion_detail = pd.DataFrame(columns = {"行为类型"})
behavior_type = ["uv","浏览","加购","收藏","购买"]
value = [202324,11550581,343564,242556,120205]
for i in range(len(behavior_type)):conversion_detail.loc[i,"行为类型"] = behavior_type[i]conversion_detail.loc[i,"数量"] = value[i]
# conversion_detail.loc[0,"PV"] = 12256906
# conversion_detail["浏览"] = 11550581
# conversion_detail["加购"] = 343564
# conversion_detail["收藏"] = 242556
# conversion_detail["购买"] = 120205
for i in range(1,5):conversion_detail.loc[i,"转化率"] = (conversion_detail.loc[i,"数量"]/ conversion_detail.loc[1,"数量"])conversion_detail.index =["PV","浏览","加入购物车","收藏","购买"]
# data_week_information["uv"].sum()
conversion_detail 
计算转化率
#可视化,点击的漏斗模型
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType
import numpy as np
conversion_detail_modify = conversion_detail.drop(["PV"]).reset_index()
conversion_detail_modify["转化率-百分比"] = conversion_detail_modify["转化率"].apply(lambda x: format(x, ".0%"))
conversion_detail_modify["行为类型"] = conversion_detail_modify["行为类型"] + ":" + conversion_detail_modify["转化率-百分比"]# funnel1 = Funnel("总体转化漏斗图一",width=800, height=400, title_pos='center')c = (Funnel(init_opts=opts.InitOpts(width="900px", height="600px",theme = ThemeType.PURPLE_PASSION )).add("商品",conversion_detail_modify[["行为类型","转化率"]].values,sort_="descending",label_opts=opts.LabelOpts(position="inside"),).set_global_opts(title_opts=opts.TitleOpts(title="淘宝整体转化率", pos_bottom = "90%", pos_right = "17%"))
)
c.render_notebook()
数据解释:淘宝整体的购买及浏览的转化率为1%,属于正常水平。而加购及收藏的转化率均维持在2%至3%,属于较为良好的水平。
#看看双十二那天的转化率如何
double_twelve = data[data["date"] == "2014-12-12"].reset_index()
double_twelve_information = double_twelve["behavior_type"].value_counts()conversion_detail_twelve = pd.DataFrame(columns = {"行为类型"})
behavior_type_1 = ["浏览","加购","收藏","购买"]
value_1 = [641507,24508,15251,10446]
for i in range(len(behavior_type_1)):conversion_detail_twelve.loc[i,"行为类型"] = behavior_type_1[i]conversion_detail_twelve.loc[i,"数量"] = value_1[i]for i in range(4):conversion_detail_twelve.loc[i,"转化率"] = (conversion_detail_twelve.loc[i,"数量"]/ conversion_detail_twelve.loc[0,"数量"])conversion_detail_twelve.index =["浏览","加入购物车","收藏","购买"]
conversion_detail_twelve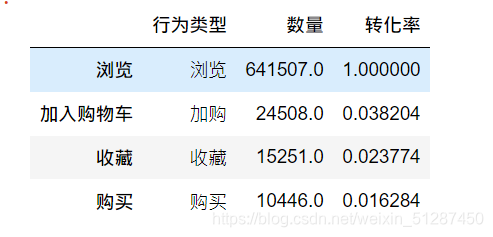
计算转化率
#可视化漏斗模型
#可视化,点击的漏斗模型
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType
import numpy as np
# conversion_detail_modify = conversion_detail.drop(["PV"]).reset_index()
conversion_detail_twelve["转化率-百分比"] = conversion_detail_twelve["转化率"].apply(lambda x: format(x, ".0%"))
conversion_detail_twelve["行为类型"] = conversion_detail_twelve["行为类型"] + ":" + conversion_detail_twelve["转化率-百分比"]# funnel1 = Funnel("总体转化漏斗图一",width=800, height=400, title_pos='center')c = (Funnel(init_opts=opts.InitOpts(width="900px", height="600px",theme = ThemeType.PURPLE_PASSION )).add("商品",conversion_detail_twelve[["行为类型","转化率"]].values,sort_="descending",label_opts=opts.LabelOpts(position="inside"),).set_global_opts(title_opts=opts.TitleOpts(title="淘宝双十二的整体转化率", pos_bottom = "90%", pos_right = "17%"))
)
c.render_notebook()
数据解释:淘宝双十二的购买及浏览的转化率为2%,较整体的转化率高一倍,属于较高水平。而加购及收藏的转化率均维持在4%至2%.而加入购物车的行为较整体的加购2%高一倍,属于较高水平。可以看到双十二的生意额较以往翻了一倍。
3.建议(1.2.流程的第三步)
3.1.多举办类似与双十二的活动
从数据可视化及数据分析部分可以得出,双十二活动前的一个礼拜,流量及购买率都维持高幅度的增长的趋势。从实际的购买及浏览的转化率中可以得知,转化率提高了一倍,这意味这销售额也提高了一倍左右,这对淘宝的相关利益者有极大的好处,比如商家增加了收益,在长远而言,因为良好的流量及良好的宣传策略,这无疑会吸引商家进驻淘宝店。
因此,淘宝公司可以多举办与双十二差不多的活动,透过相关的活动,这能提高淘宝公司争取更多的流量机会,也能削减竞争对手如拼多多等的流量。例如说,在奶茶行业,他们进行了大量的宣传,比如在微信朋友圈分析"秋天的第一杯奶茶",借此营造出秋天第一天喝奶茶是一件十分美好的事情,特别是另一半送给女方,更具有特殊意义。而透过这种社交网络的方式,能更有效的形成病毒效应,令该活动最终获得成功。淘宝可以模仿此宣传创意,可以拟定"秋天第一份礼物"的想法,吸引顾客在淘宝购买礼物,并送给其他人,期望能教育消费者,在每一年的立秋之日,送一份礼物给另一半,从而获取更多的流量及转化率。
3.2.按流量安排人手。
从数据可视化及分析部分可以得出,9am 到 10am 属于流量较高的时段,反之10pm以后,流量逐渐减少,淘宝可以出一份指引,建议商户可以在9am 到 10pm 维持良好的人手,以维持良好的回复速度,提高顾客的满意度及顾客价值,提高转化率。但,如若人手不足,淘宝客服无法处理大量的咨询,会令顾客失去耐心,并降低顾客的满意度,从而转化率会降低。此外,该指引,应在10pm以后缩减人手,但又能应付相关的流量。这能缩减人手方面的开支,提高淘宝商家的净收入。
3.3.流量投放-价格歧视
从数据可视化及分析部分可以得出,6pm 到 10pm属于高流量的时段,其中9pm-10pm是黄金流量的一小时。顺带一提,每逢礼拜五六日,流量都会较其他的日子高,因此,淘宝公司可以在6pm - 9pm之间,订立较高的价格,赚取更多的收入。此外,9pm-10pm属于顶峰,淘宝也可以收取更高的费用。反之其他时段则收取较低的费用。利用价格歧视,能令淘宝的定价策略更为合理,更能吸引其他商家使用淘宝的服务。
4.总结
淘宝公司总的来说,PV,UV及转化率均维持在较高的水平。以及淘宝的双十二策略也较为成功,能令消费额翻倍。
这篇关于淘客消费者行为,深入分析。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!