本文主要是介绍【复现】【免费】基于多时间尺度滚动优化的多能源微网双层调度模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
主要内容
部分代码
结果一览
1.原文结果
2.程序运行结果
下载链接
主要内容
该模型参考《Collaborative Autonomous Optimization of Interconnected Multi-Energy Systems with Two-Stage Transactive Control Framework》,主要解决的是一个多能源微网的优化调度问题,首先对于下层多能源微网模型,考虑以其最小化运行成本为目标函数,通过多时间尺度滚动优化处理负荷和可再生能源随机性,并求解其最优调度策略;对于上层模型,考虑运营商以最小化运营成本为目标函数,同时考虑变压器过载等问题。最终构建了一个两阶段优化模型,采用次梯度法和二分法对模型进行优化求解,程序采用matlab编写,模块化编程,注释清晰。


部分代码
%次梯度法求解
% 用于日前预测或日内作为对比
global EH1 EH2 EH3 elePrice period couldExport minimumPower
delta_lambda_max = 1e-4;
maxIteration = 3000; %最大迭代次数
iterativeStep = 1;
ee = 0.001;
%%按照不同的输出场景,选择不同的约束
if couldExport == 1minimumPower = eleLimit_total(2);
elseminimumPower = 0;
end
if isDA%%获取不同IES的参数值EH1.predict(0);EH2.predict(0);EH3.predict(0);priceArray_record(:,1) = elePrice;prePrice = elePrice;temporal = 1;st = 1;
elsetemporal = 24* period;%%确定为24h的算例st = time;
end
for pt = st : temporalif isDA == 0%%获取不同IES的参数值EH1.predict(pt);EH2.predict(pt);EH3.predict(pt);endnumber = 1; k = 1;lamda_old = -10 * ones(24 * period - pt + 1, 1);lamda_new = zeros(24 * period - pt + 1, 1); %取初始值:对预测电价没有偏差lamda_record = zeros(24 * period - pt + 1 , maxIteration + 1);lamda_record(: , number) = lamda_new;max_balance=zeros (1 , maxIteration + 1);%如果前后两次价格的偏差太大,则返回第1步while number <= 2 || max(abs(balanceDemand)) > 100% max(abs(lamda_new - lamda_old)) > ee || %| max(abs(clearDemand_new - clearDemand_old)) > 1e-4 %1e-6, 不能直接取0% 后一个条件是因为即使lamda收敛后,供需也不平衡,所以需要取一正一负两个点,来求零点% && || 的前一个为否,则后一个就不计算了% 要求至少迭代两次(number=1,2)% if number > maxIteration% error('超出最大迭代次数');% endif number > 1% number=2时才记录第一次clearDemand_old = clearDemand_new;end%%依次根据priceArray, gasPrice1, pt三个输入值计算优化结果以及响应结果[x1,f1,~,~,~] = EH1.handlePrice(priceArray, gasPrice1, pt);%根据priceArray, gasPrice1, pt三个输入值计算EH1优化结果以及响应结果clearDemand_EH1_new = x1(1: 24 * period - pt + 1);%根据priceArray, gasPrice1, pt三个输入值计算EH2优化结果以及响应结果[x2,f2,~,~,~] = EH2.handlePrice(priceArray, gasPrice1, pt);%根据priceArray, gasPrice1, pt三个输入值计算EH2优化结果以及响应结果clearDemand_EH2_new = x2(1: 24 * period - pt + 1);%根据priceArray, gasPrice1, pt三个输入值计算EH3优化结果以及响应结果[x3,f3,~,~,~] = EH3.handlePrice(priceArray, gasPrice1, pt);clearDemand_EH3_new = x3(1: 24 * period - pt + 1);
%%根据lamda_new(i)的取值,计算不同情况下的电网侧出清结果(上层)clearDemand_grid_new=zeros(24 * period - pt + 1 ,1);for i = 1: 24 * period - pt + 1if lamda_new(i) == 0
结果一览
1.原文结果


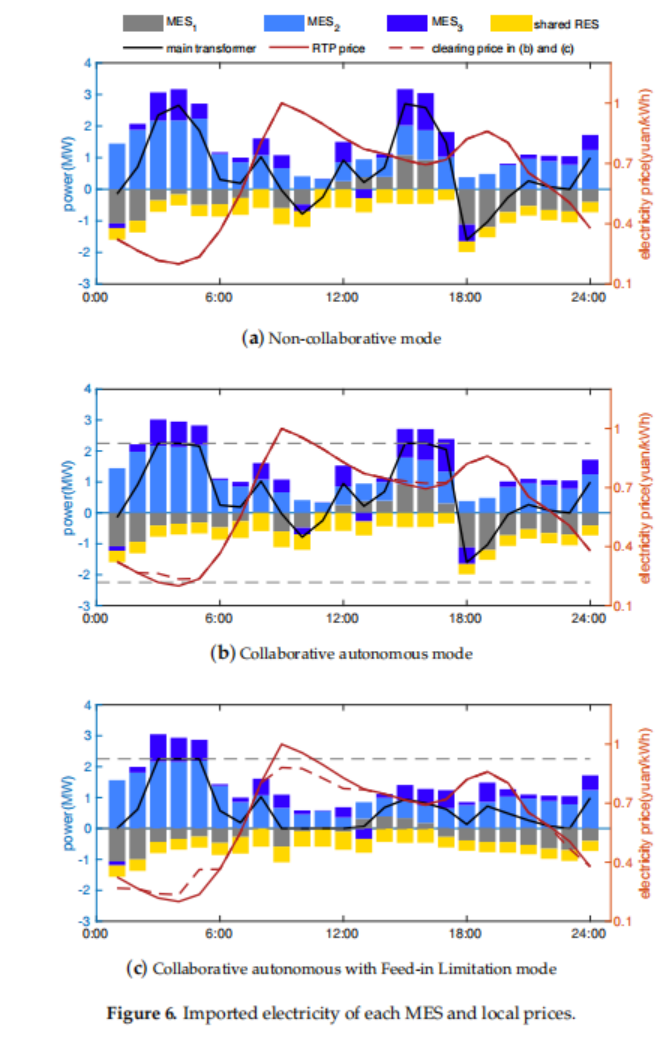
2.程序运行结果




下载链接
这篇关于【复现】【免费】基于多时间尺度滚动优化的多能源微网双层调度模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





