本文主要是介绍Propose-and-Refine: A Two-Stage Set Prediction Network forNested Named Entity Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:
https://www.ijcai.org/proceedings/2022/0613.pdf\
IJCAI 2022
介绍
问题
作者认为基于span的模型存在以下问题:1)忽略了span和其他实体短语之间的关系,span的表征往往只有内部的信息,看不见全局的信息,就会导致一些实体被分类错误。(不是很站得住脚哈 因为一般基于span的方法都会加入一些其他信息 比如句子的cls 或者span前后的一些token信息);2)基于span的模型由于存在最长枚举长度的限制,在处理长实体上存在限制。
IDEA
因此,作者提出了一个用于嵌套实体的两阶段集合预测网络Propose-and-Refine Network(PnRNet),在propose阶段,使用一个基于span的预测器来生成coarse entity作为entity proposals;在refine阶段,将这些proposals进行交互,丰富proposal的表征,再次对实体边界和类别进行预测。
方法
该模型整体结构如下:
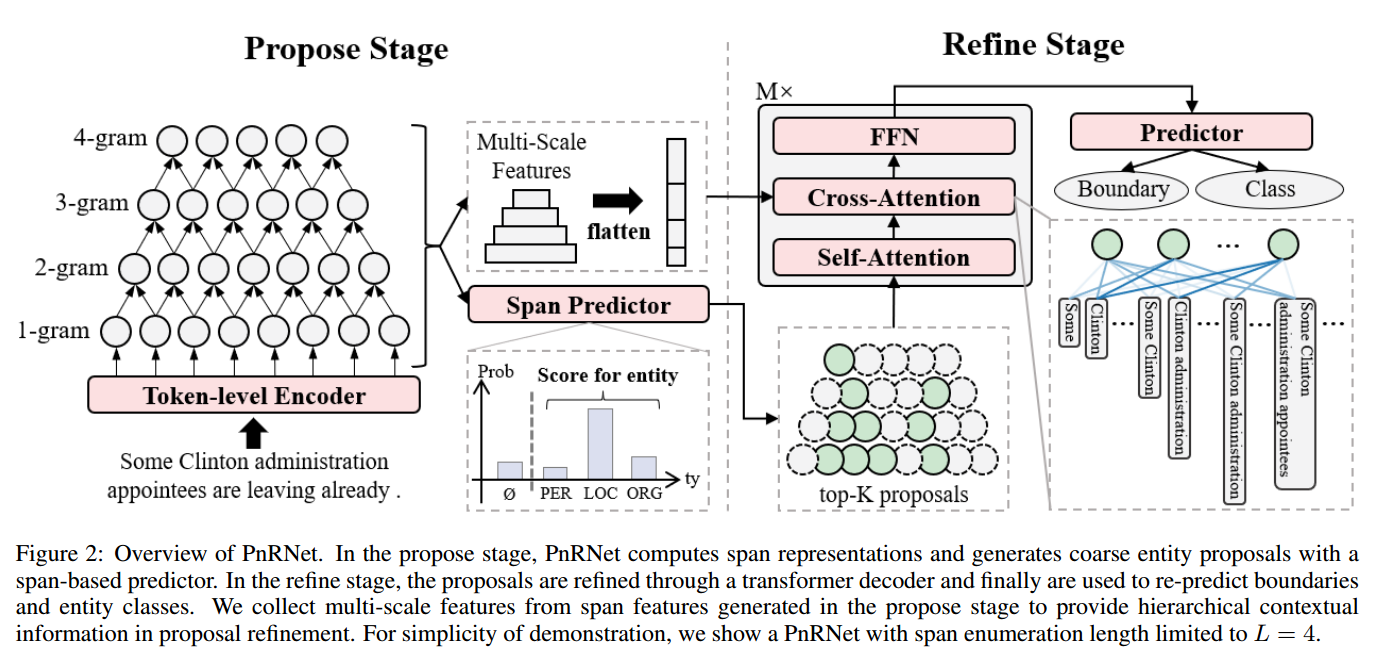
Stage I:Propose
该模块可以理解为对span的筛选模块,对枚举出的所有span进行预测,筛选出可能是实体的span,作为proposal。
给定一个长为N的句子X,将每个token的上下文embedding、word embedding、POS embedding、character embedding进行concate后,经过一个BiLSTM得到每个token的表征:
![]()
以自下而上的方式生成span表征, 表示长度为l且起点是第i个token的span:
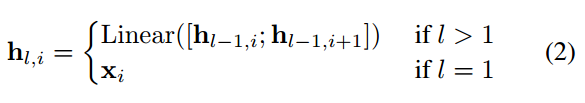
然后对每个span进行分类,P表示span(l,i)是实体类别的可能性,
表示句子中的所有实体:
![]()
![]()
对span按其属于每个实体类别的总分数降序排序,将top-k作为proposal 实体 Q,送入下一个模块进行细化。
Stage II: Refine
使用transformer decoder对proposal 实体进行细化,Um表示第m层的输出,U0=Q
具体的,在自注意力层,proposal 实体通过多头注意力机制进行相互融合:
![]()
为了对proposal句子中的其他短语的关系进行建模。proposal实体与句子表征通过交叉注意力来丰富其上下文信息:
![]()
考虑到文本的层次性,使用多尺度句子表征来为嵌套ner提供层次上下文信息,即将propsal阶段生成的span表征来形成分层金字塔状的多尺度句子表征:
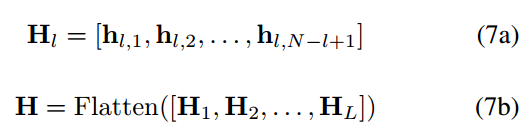
是长度为l的span list,H是包括了所有span特征的list,由于H包含了不同长度span的特征,可以看作是输入句子的多尺度表示。
作者认为有了多尺度特征,proposal表征能够直接与相关span的特征相关联,与token级的特征比,在交叉注意力中使用多尺度特征作为key和value可以更有效的聚合层次上下文信息。
最后经过一个前馈层,得到当前解码器的输出:
![]()
将最后一层transformer的输出用来对实体的边界和类型再次进行预测:
![]()
边界检测部分,将细化后的entity proposal和所有1-gram跨度特征融合后进行分类,得到每个token是左右边界的概率:
![]()
![]()
Training Objective
proposal阶段的loss是gt实体和枚举出的所有span之间的交叉熵损失:
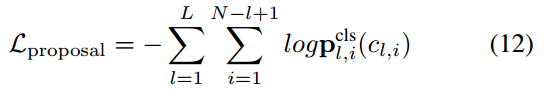
refine阶段的loss由分类损失和边界预测损失组成(由于模型预测的结果可以看作是一堆实体的集合,因此需要计算预测出的实体与golden entity之间的匹配代价,使用匈牙利算法选择匹配代价最小的golden entity label作为预测实体的真实标签),这里作者提到为了快速的收敛模型,使用每个解码器层的输出来预测实体,并将所有层的loss相加。
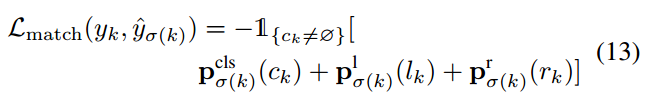
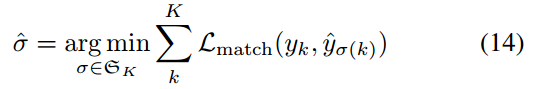
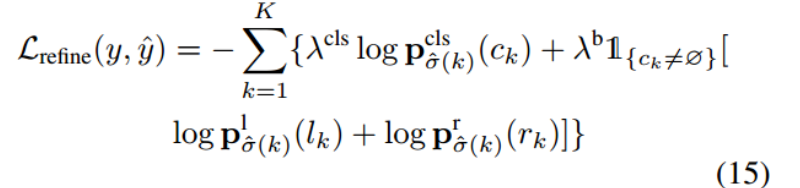
实验
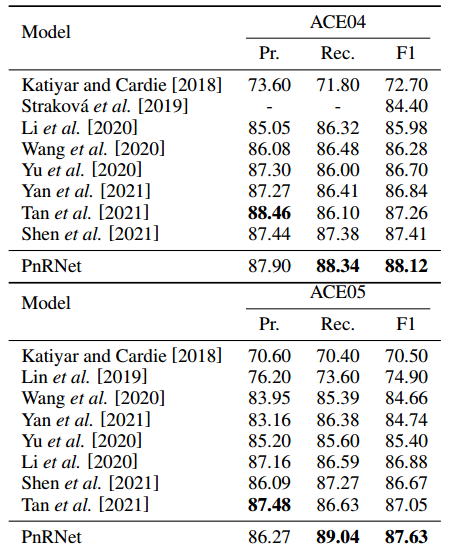
对比实验
作者在多个nest 和 flat数据集上进行实验,结果如下所示:

消融实验
在ACE04和GENIA数据集上进行了消融实验,结果如下所示:

Entity Proposal:使用随机初始化可学习的向量代替proposal的特征
Proposal refinement:去掉proposal refinement阶段,直接对poposali阶段生成的span进行分类预测
Multi-scale:使用一个sequence encoder的输出代替作者提出的多尺度特征
基于proposal阶段生成的entity proposal与PnRNet的最终实体在不同长度实体上的表现:
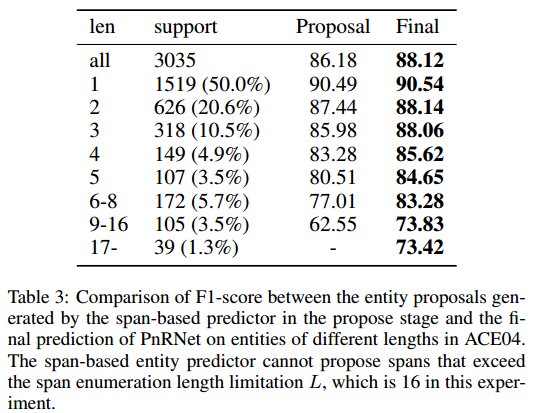
可以看出作者提出的模型,在长实体上性能优于基于span的模型。
分析
作者对PnRNet最后一层的交叉注意力map进行了可视化,如下所示:
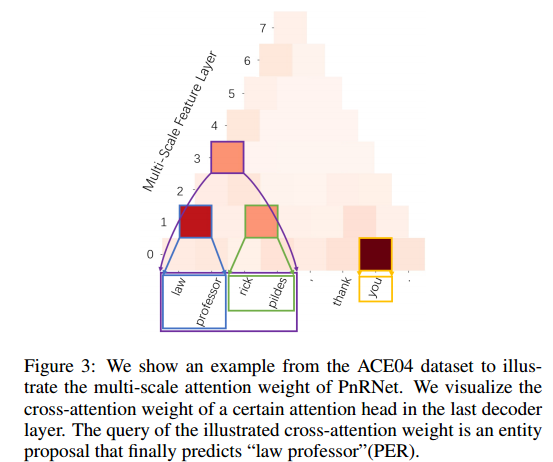
可以看出通过多尺度特征,proposal 实体 可以直接关注与自身高度相关的跨度特征,从而实现交叉关注。
case study,红色表示coarse proposal,蓝色表示模型最终的预测,绿色表示ground truth:

可以看出模型能够通过proposal refine来消除proposal中的错误。
总结
这个确实是Two-Stage,第一个阶段过滤掉非实体的span,第二阶段中将这些span通过交叉注意力机制进行交互,来更新每个span的表征,然后再对这些span进行分类和边界确定。这里的边界确定,是通过这个span的表征与其他每个token之间的融合后通过一个softmax,来确定左右边界,感觉这里的公式没有很懂。最后实验结果其实也不是很高,但你说它是sota吧也是,不过作者这样叠加模型和注意力块,计算量是远高于其他模型的吧?不过span之间的交互,真的有用吗?试试!
但是这篇论文没有代码!又是一篇没有代码的!
这篇关于Propose-and-Refine: A Two-Stage Set Prediction Network forNested Named Entity Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





