本文主要是介绍2002-2022年各地区出口技术复杂度数据(含原始数据+计算代码+结果),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2002-2022年各地区出口技术复杂度数据(含原始数据+计算代码+结果)
1、时间:2002-2022年
2、来源:原始数据整理自国研网、海关总署、国家统计局
3、范围:30省
4、指标:
进出口原始数据:时间、流向名称、商品编码、商品名称、伙伴编码、伙伴名称、主体编码、主体名称、方式编码、方式名称、第一计量单位、第一数量、第二计量单位、第二数量、金额(美元)
汇率、人均GDP、出口复杂度
5、指标解释:
出口技术复杂度是一个衡量出口产品中包含的技术和知识产权价值,以及这些技术和知识产权在国际市场上的竞争力的重要指标。高的出口技术复杂度往往意味着较高的产品附加值和技术含量,这与产业的高度创新和高端定位密切相关。
6、用途:出口技术复杂度是反映一个国家或地区出口产品的技术水平高低的重要指标。高的出口技术复杂度往往意味着较高的产品附加值和技术含量,这与产业的高度创新和高端定位密切相关。可用于揭示了各省在全球价值链中的具体位置。
7、方法说明:依据Hausmann的方法,对30个省份进行了出口技术复杂度的测算
8、参考文献:
What You Export Matters (Hausmann)
9、相关研究:
人力资本扩张与中国城市制造业出口升级_来自高校扩招的证据_周茂
城市中心性能促进城市出口结构升级吗_来自中国城市和城市群的证据_孙楚仁
贸易技术复杂度与中国城市生产率_张默涵
10、下载链接:
2002-2022年各省出口技术复杂度数据(原始数据+计算代码+结果)![]() https://download.csdn.net/download/m0_71334485/88975534
https://download.csdn.net/download/m0_71334485/88975534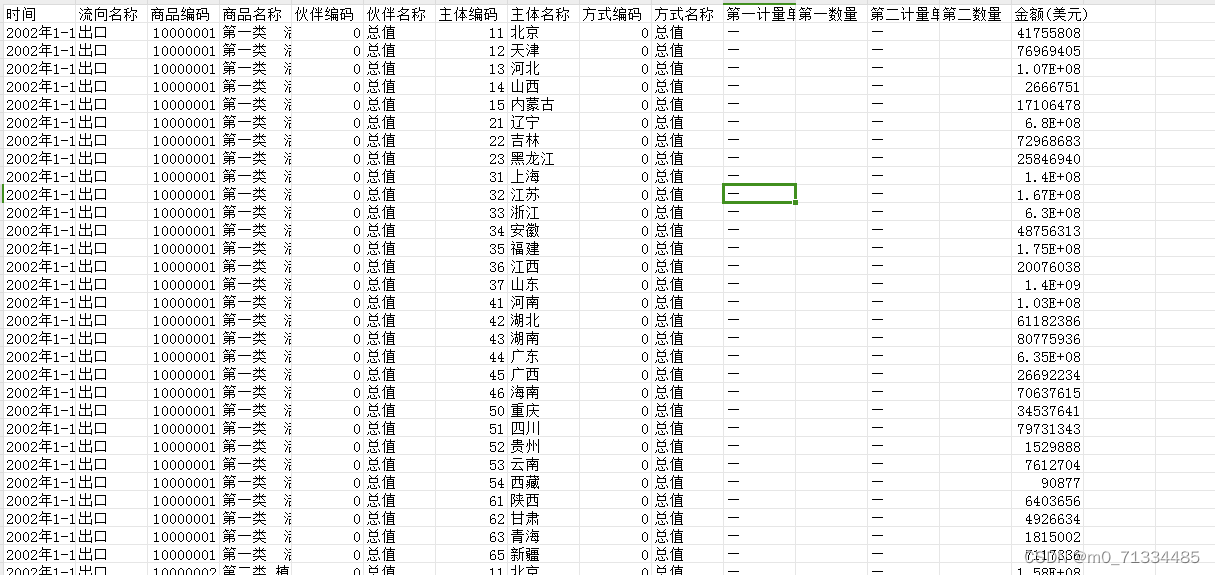

这篇关于2002-2022年各地区出口技术复杂度数据(含原始数据+计算代码+结果)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






