本文主要是介绍TDengine助力顺丰科技大数据监控改造,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:尹飞
小T导读:顺丰科技大数据集群每天需要采集海量监控数据,以确保集群稳定运行。之前虽然采用了OpenTSDB+HBase作为大数据监控平台全量监控数据的存储方案,但有不少痛点,必须对全量监控数据存储方案进行改造。通过对IoTDB、Druid、ClickHouse、TDengine等时序数据存储方案的调研,最终我们选择了TDengine。大数据监控平台采用TDengine后,在稳定性、写入性能、查询性能等方面都有较大的提升,并且存储成本降低为原有方案的1/10。
场景与痛点
顺丰科技致力于构建智慧大脑,建设智慧物流服务,持续深耕大数据及产品、人工智能及应用、综合物流解决方案等领域,在中国物流科技行业处于领先地位。为了保证各类大数据服务的平稳运行,我们围绕OpenFalcon搭建了大数据监控平台。由于OpenFalcon本身采用的是rrdtool作为数据存储,不适合做全量监控数据的存储,于是我们采用了OpenTSDB+HBase作为大数据监控平台全量监控数据的存储方案。
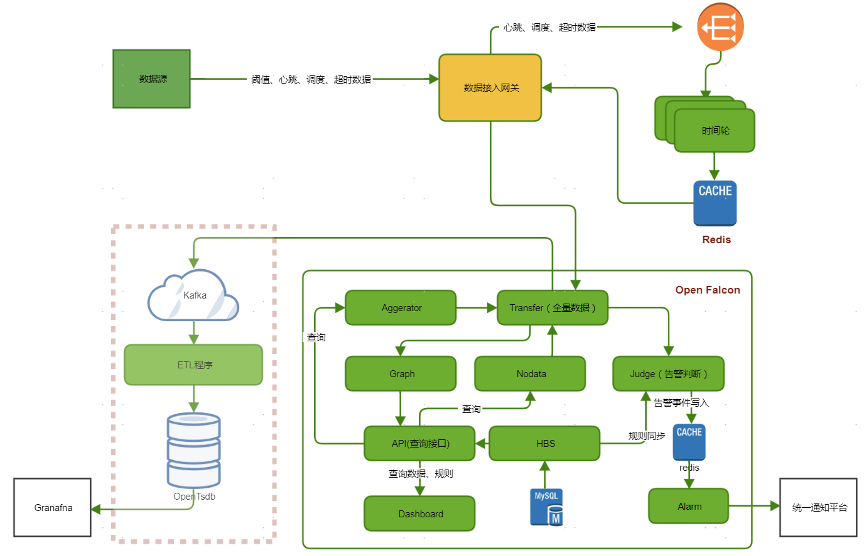
目前整个平台平均写入数十亿条/天。随着大数据监控平台接入的数据量越来越大,我们有很多痛点需要解决,包括依赖多、使用成本高和性能不能满足等问题。
-
依赖多,稳定性较差:作为底层大数据监控平台,在数据存储方面依赖Kafka、Spark和HBase等大数据组件。过长的数据处理链路会导致平台可靠性降低,同时由于平台依赖大数据组件,而大数据组件的监控又依赖监控平台,在大数据组件出现不可用问题时,无法及时通过监控平台对问题进行定位。
-
使用成本高:由于监控数据写入数据量巨大,且需要保存全量监控数据半年以上,用以追溯问题。所以依据容量规划,我们采用4节点OpenTSDB+21节点HBase作为全量监控数据存储集群。压缩后每天仍需要1.5T(3副本)左右空间存储,整体成本较高。
-
性能不能满足需求:OpenTSDB作为全量监控数据存储方案,在写入方面性能基本满足需求,但是在日常大跨度和高频次查询方面已无法满足要求。一方面,OpenTSDB查询返回结果慢,在时间跨度比较大的情况下,需要十几秒;另一方面,OpenTSDB支持的QPS较低,随着用户越来越多,OpenTSDB容易崩溃,导致整个服务不可用。
技术选型
为解决上述问题,我们有必要对全量监控数据存储方案进行升级。在数据库选型方面,我们对如下数据库做了预研和分析:
-
IoTDB:刚孵化的Apache顶级项目,由清华大学贡献,单机性能不错,但是我们在调研时发现不支持集群模式,单机模式在容灾和扩展方面,不能满足需求。
-
Druid:性能强大,可扩展的分布式系统,自修复、自平衡、易于操作,但是依赖ZooKeeper和Hadoop作为深度存储,整体复杂度较高。
-
ClickHouse:性能最好,但是运维成本太高,扩展特别复杂,使用的资源较多。
-
TDengine:性能、成本、运维难度都满足,支持横向扩展,且高可用。
通过综合对比,我们初步选定TDengine作为监控数据存储方案。TDengine支持多种数据导入方式,包括JDBC和HTTP模式,使用都比较方便。由于监控数据写入对性能要求比较高,我们最后采用了Go Connector,接入过程需要做如下操作:
-
数据清洗,剔除格式不对的数据;
-
数据格式化,将数据转化为实体对象;
-
SQL语句拼接,对数据进行判断,确定写入的SQL语句;
-
批量写入数据,为提高写入效率,单条数据完成SQL拼接后,按批次进行数据写入。
数据建模
TDengine在接入数据前需要根据数据的特性设计schema,以达到最好的性能表现。大数据监控平台数据特性如下:
-
数据格式固定,自带时间戳;
-
上传数据内容不可预测,新增节点或服务都会上传新的标签内容,这导致数据模型无法前期统一创建,需要根据数据实时创建;
-
数据标签列不多,但是标签内容变化较多;数据数值列比较固定,包括时间戳,监控数值和采样频率;
-
单条数据数据量较小,100字节左右;
-
每天数据量大,超过50亿;
-
保存6个月以上。
根据上述特点,我们构建了如下的数据模型。
按照TDengine建议的数据模型,每一种类型的数据采集点需要建立一个超级表,例如磁盘利用率,每个主机上的磁盘都可以采集到磁盘利用率,那么就可以将其抽象成为超级表。结合我们的数据特点和使用场景,创建数据模型如下:
-
以指标作为超级表,方便对同一类型的数据进行聚合分析计算;
-
监控数据本身包括标签信息,直接将标签信息作为超级表的标签列,相同的标签值组成一个子表。
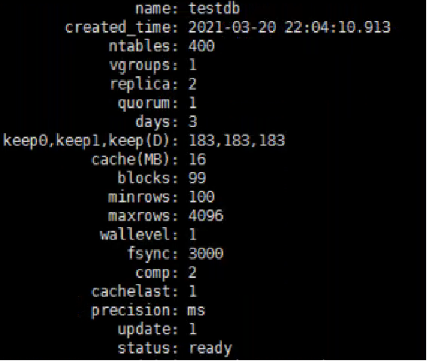
库结构如下:
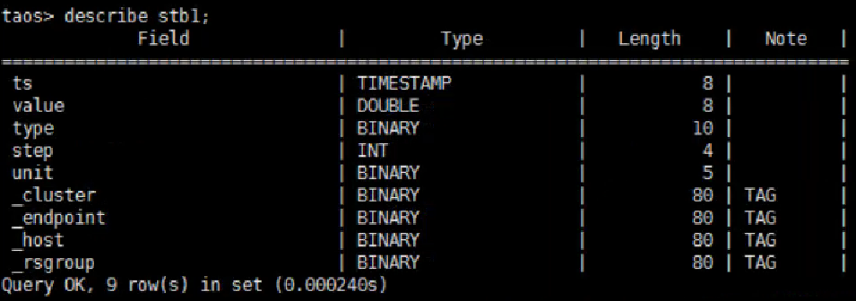
超级表结构如下:
落地实施
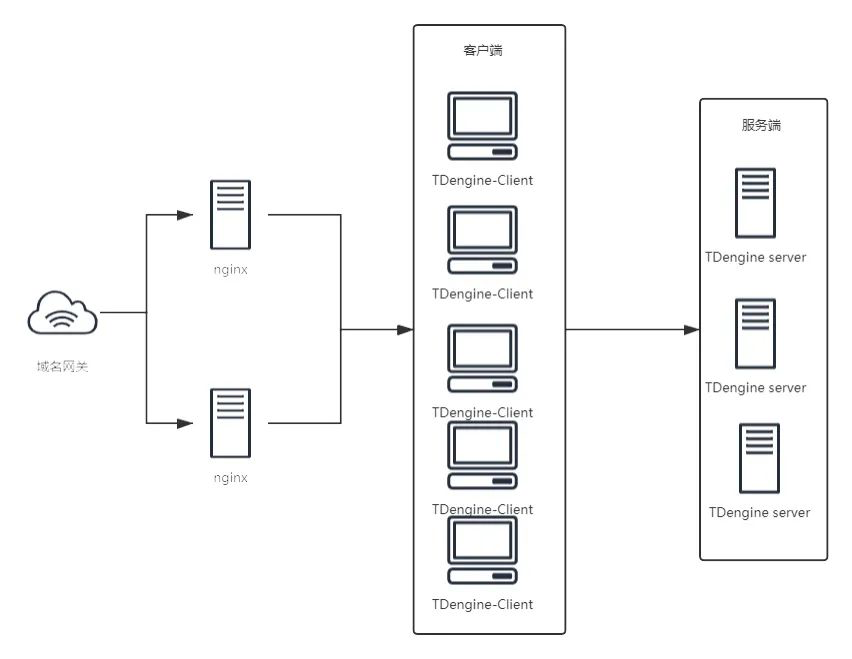
大数据监控平台是上层大数据平台稳定运行的底座,需要确保整个系统的高可用性;随着业务量增加,监控数据量持续增长,要保证存储系统能方便的进行横向扩展。基于以上两点,TDengine落地总体架构如下:
为保证整个系统的高可用和可扩展性,我们前端采用nginx集群进行负载均衡,保证高可用性;单独分离出客户端层,方便根据流量需求进行扩容缩容。
实施难点如下。
-
数据写入:由于监控指标的上传接口是开放型的,只会对格式进行校验,对于写入的数据指标不确定,不能预先创建好超级表和子表。这样对于每条数据都要检查判断是否需要创建新的超级表。如果每次判断都需要访问TDengine的话,会导致写入速度急剧下降,完全无法达到要求。为了解决这个问题,在本地建立缓存,这样只需要查询一次TDengine,后续相关指标的写入数据直接走批量写入即可,大大提升了写入速度。另外,2.0.10.0之前的版本批量创建表的速度非常慢,为了保证写入速度,需要按照创建表和插入数据分批插入,需要缓存子表的数据信息,后面的版本优化了子表创建功能,速度有了大幅提升,也简化了数据插入流程。
-
查询问题:1. 查询bug。监控平台数据主要是通过Grafana进行数据展示,但是在使用过程中,我们发现官方提供的插件不支持参数设置,根据我们的自身需求,对其进行了改造,并提供给社区使用。另外在使用过程中,触发了一个比较严重的查询bug:在设置较多看板时,刷新页面会导致服务端崩溃。后经排查,发现是由于Grafana中一个dashboard刷新时会同时发起多个查询请求,处理并发查询导致的,后经官方修复。2. 查询单点问题。TDengine原生HTTP查询是直接查询特定服务端完成的。这个在生产环境是存在风险的。首先,所有的查询都集中在一台服务端,容易导致单台机器过载;另外,无法保证查询服务的高可用。基于以上两点,我们在TDengine集群前端使用Nginx集群作反向代理,将查询请求均匀分布在各个节点,理论上可以无限扩展查询性能。
-
容量规划:数据类型,数据规模对TDengine性能影响比较大,每个场景最好根据自己的特性进行容量规划,影响因素包括表数量,数据长度,副本数,表活跃度等。根据这些因素调整配置参数,确保最佳性能,例如blocks,caches,ratioOfQueryCores等。根据与涛思工程师沟通,确定了TDengine的容量规划计算模型。TDengine容量规划的难点在于内存的规划,一般情况下,三节点256G内存集群最多支持2000w左右的子表数目,如果继续增加的话,会导致写入速度下降,且需要预留一部分的内存空间作为查询缓存使用,一般保留10G左右。如果子表数量超过2000w,则可以选择扩展新节点来分担压力。
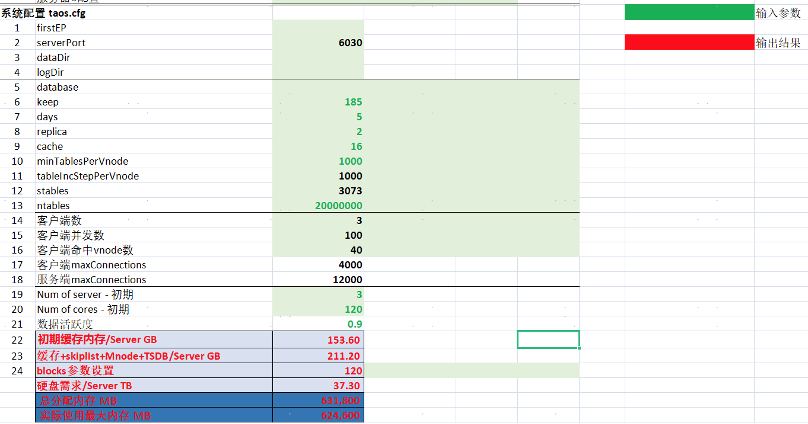
改造效果
完成改造后,TDengine集群轻松扛住了全量监控数据写入,目前运行稳定。改造后架构图如下:
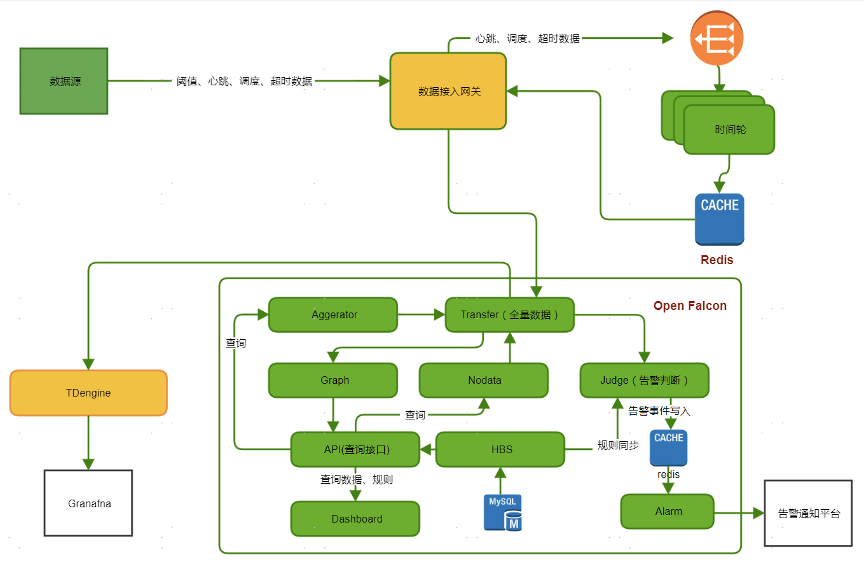
-
稳定性方面:完成改造后,大数据监控平台摆脱了对大数据组件的依赖,有效缩短了数据处理链路。自上线以来,一直运行稳定,后续我们也将持续观察。
-
写入性能:TDengine的写入性能跟写入数据有较大关系,在根据容量规划完成相关参数调整后,在理想情况下,集群写入速度最高达到90w条/s的写入速度。在通常情况下(存在新建表,混合插入),写入速度在20w条/s。
-
查询性能:在查询性能方面,在使用预计算函数情况下,查询p99都在0.7秒以内,已经能够满足我们日常绝大部分查询需求;在做大跨度(6个月)非预计算查询情况下,首次查询耗时在十秒左右,后续类似查询耗时会有大幅下降(2-3s),主要原因是TDengine会缓存最近查询结果,类似查询先读取已有缓存数据,再结合新增数据做聚合。
-
成本方面:服务端物理机由21台降至3台,每日所需存储空间为93G(2副本),同等副本下仅为OpenTSDB+HBase的约1/10,在降低成本方面相对通用性大数据平台有非常大的优势。
总结
目前从大数据监控这个场景看,TDengine在成本,性能和使用便利性方面都有非常大的优势,尤其是在成本方面带来很大惊喜。在预研和项目落地过程中,涛思的工程师提供了专业、及时的帮助,在此表示感谢。希望TDengine能够不断提升性能和稳定性,开发新特性,我们也会根据自身需求进行二次开发,向社区贡献代码。祝TDengine越来越好。对于TDengine,我们也有一些期待改进的功能点:
-
对表名支持更友好;
-
对其他大数据平台的支持,联合查询需求;
-
支持更加丰富的SQL语句;
-
灰度平滑升级;
-
子表自动清理功能;
-
集群异常停机恢复速度。
后续我们也将在顺丰科技的更多场景中尝试应用TDengine,包括:
-
物联网平台,作为底层物联网数据存储引擎构建顺丰科技大数据物联网平台;
-
Hive on TDengine,通过Hive on TDengine实现与现有其他数据源数据联合查询,使其能平滑的与现有系统使用,降低接入门槛。
这篇关于TDengine助力顺丰科技大数据监控改造的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





