本文主要是介绍从 MongoDB 迁移到 TDengine 后,成本显著下降,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者:喻东 东莞中融数字
小 T 导读:当下我国养殖企业普遍采用传统塑料耳标+人工定期分析+兽医现场诊断来做牲畜异常预防,虽然市面上有固定摄像头、滑轨追踪摄像头、电信 NB 卡等方案,但这种方式依旧会存在牲畜识别错误、高延迟等问题,无法做到实时监控每一头牲畜。基于此,我们利用新兴技术打造了牲畜“特征采集+AI 分析”的 AIoT 平台,来实现牲畜异常的早发现、早报警、早预防。
具体场景如下:使用 APP 提前录入采集器编号,再将采集器固定在牲畜身上(耳朵、颈部、腿部等),采集器每分钟会采集 20 次特征数据,采集数据种类包括温度、流汗情况、经纬度、运动、脉搏、环境温湿度等。将采集到的数据进行边缘计算,再将汇总结果通过 4G 网络发送至云端服务器,之后云端会根据经纬度等要求获取到所对应的天气、风量等变量,结合采集器数据,AI 会综合评估出牲畜当前的健康情况,例如是否有食欲不振、瘫坐不动、发烧趋势等。
一、 架构和具体实现
与传统物联网项目一样,本平台对数据的写入性能有较高的要求,同时也有一定的聚合查询需求,具体操作上写多读少,是典型的高并发写入场景。我们之前采用的是 MongoDB 的方案,还做了月份分表,但是进行聚合查询的效率并不高,而且也不便利,之后我们又尝试引入 Cassandra,但使用上依旧不够便利。
偶然的机会下,我们了解到 InfluxDB 和 TDengine,在搭建测试环境后对两者分别进行了测试,最终敲定 TDengine。除了两者直接的性能差距外,TDengine 提供的表数据 TTL 机制、数据压缩、流式计算等功能也让我们更加青睐于它。
基于超级表的设计原理,我们将牲畜的业务关联信息作为 tag,方便关联 MySQL,同时一个采集器就作为一个子表存在,采集器测点作为子表的列。
表结构分别如下图所示:图一为牲畜所佩戴的采集器表,也可以认为是牲畜表,其与采集器一一绑定,图二与图三则为安装在养殖场固定位置的环境温湿度表,此外还有存储原始报文数据的表等,就不在此一一列举了。
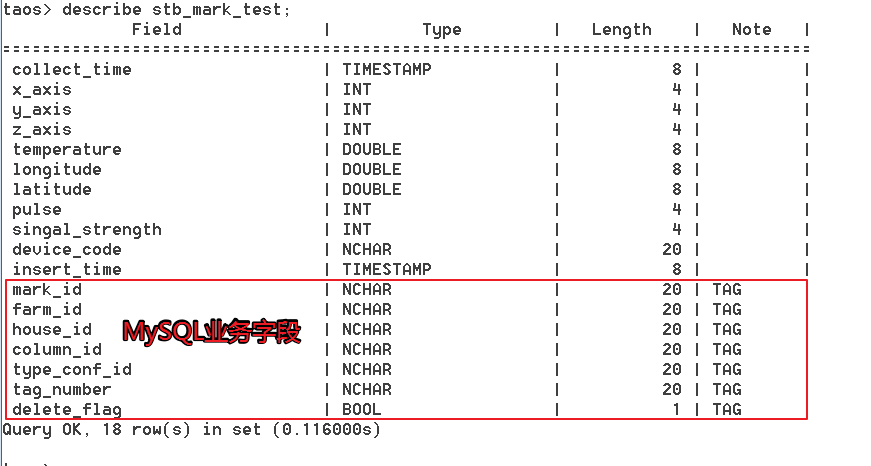
图 1
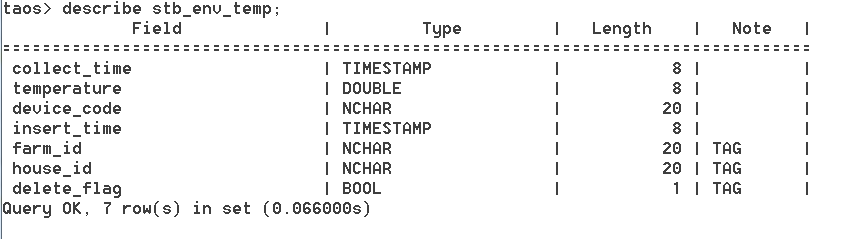
图 2
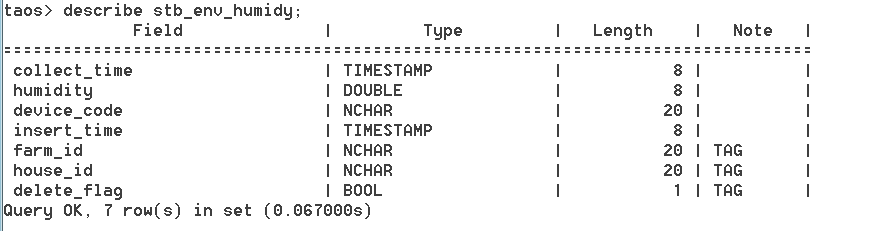
图 3
目前我司的所有物联网数据表都是基于 TDengine 超级表设计的,针对核心的牲畜超级表,其关联的 tag 会比其他表更多一些。需要注意的是,为了保证 TDengine 中 tag 与 MySQL 一致,每当业务中修改了牲畜的基本属性,也需要同步执行 tag 修改操作。
这种表设计方便我们追溯可能出现的处理延时等问题,表中的 collect_time 为采集时间,insert_time 为数据落盘时间,如果两者的时间差较大,则可能就出现了网络差、采集器故障、服务端吞吐量不够等问题,此时就需要排查下原因了。
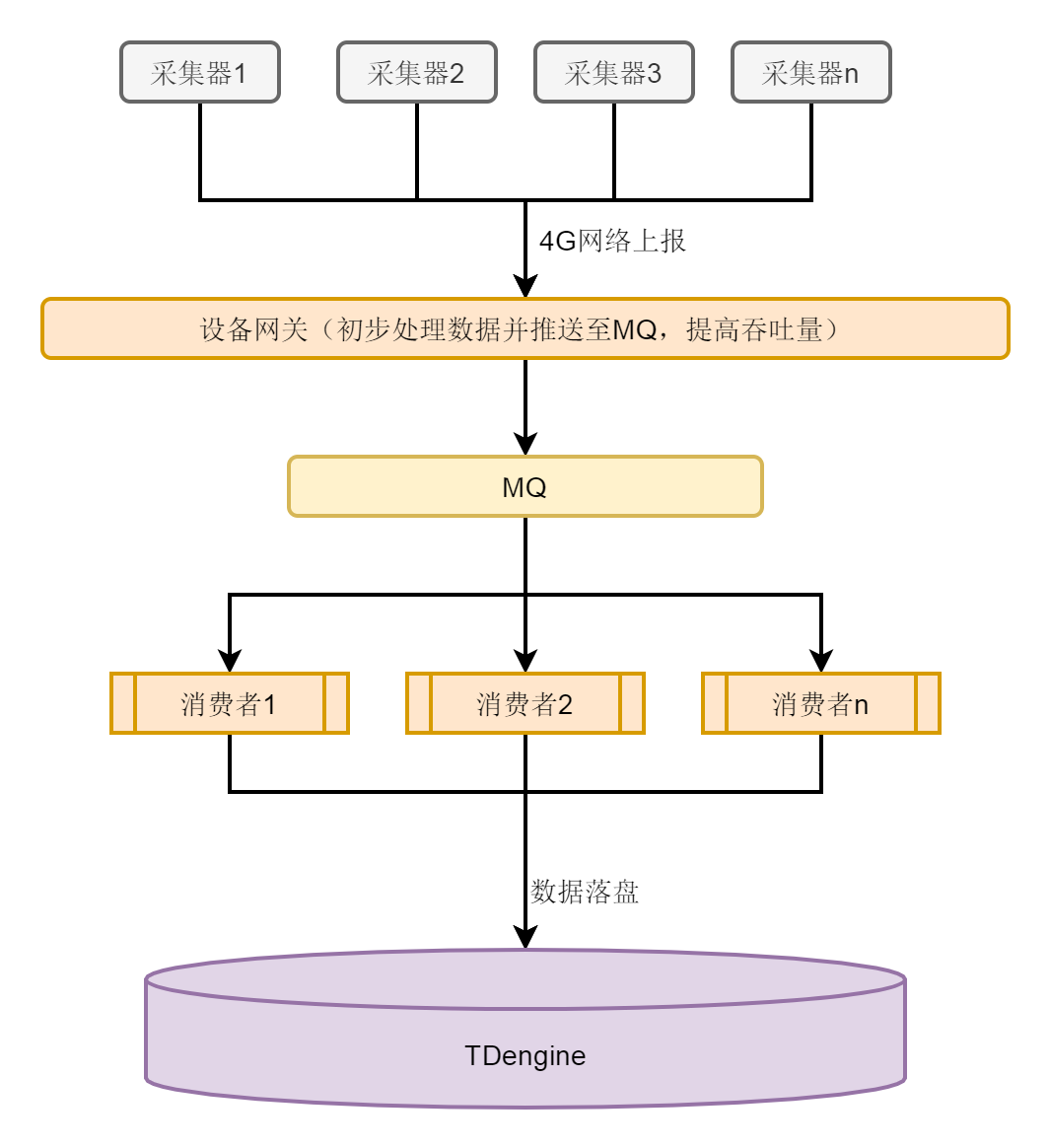
牲畜数据采集到数据落盘的全流程如下图所示,通过采集器采集到的数据经过 4G 网络上报,由设备网关初步处理数据并推送至 MQ,提升吞吐量,之后传输给消费者,最终落盘到 TDengine。
二、数据迁移和实际效果
因为我们之前使用的是其他数据库,更换新的数据库时会产生数据迁移的操作,具体迁移步骤如下:
-
新产生的采集器数据分别写入 MongoDB 和 TDengine,即一份数据写两份,旧数据查 MongoDB,新数据查 TDengine,以便出现问题后能及时挽救;
-
逐步将历史数据格式化导入到 TDengine;
-
AI 分析的数据源由 MySQL 数仓改为 TDengine。
在迁移过程中我们也遇到了一些小问题,主要有两点:
-
由于此前使用的是 MySQL+MongoDB 的方案,所有 MongoDB 的语句都得改写为 TDengine 的 SQL,而 TDengine 的语法虽然接近 SQL,但细节部分区别却不少,不过也并不是大问题,适应之后就好了。
-
由于我司的服务比较多,起初我有考虑做一个中间件来提供给系统内的其他服务做数据查询,但由于 TDengine 是一个较新的开源项目,因此最终还是使用传统的方式:涉及到了物联网数据调用的服务全部自行连接 taos,在迁移运行稳定后再做整合。
迁移之后的效果也非常明显,我们在使用 MongoDB 时,自建集群是使用了 6 台 4 核 32G 机器,迁移到 TDengine 之后,自建集群仅使用了 2 台 8 核 32G 机器,在成本上有显著下降。
在性能的具体表现上,我模拟了 6000 多个采集器的数据,表数据合计约三亿条。我司大部分查询都是基于子表,仅部分业务需要查看聚合操作。对超级表做 group by+last_row(*)查询时,能在 1.5s 内返回数据,对子表做查询在 0.1 秒左右(select * from son_table limit 10),可以满足业务要求。
三、写在最后
随着物联网、人工智能等新兴科技的发展,AIot 已经是个不可忽视的大趋势,而计算环节往往少不了数仓,但在需求不复杂的产品中或许可以节省掉这一步,某种意义上,TDengine 提供的流式计算和高性能的查询,也帮助我们在一定程度上省掉了不少中间步骤,达到了降本增效的结果。
现在 TDengine 在成本管控和性能提升方面所带来的效果已经很突出,如果其能够在未来某个版本支持与模型之间的调用并直接输出结果,那可就太完美了!
✨想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。✨
GitHub - taosdata/TDengine: An open-source big data platform designed and optimized for the Internet of Things (IoT).An open-source big data platform designed and optimized for the Internet of Things (IoT). - GitHub - taosdata/TDengine: An open-source big data platform designed and optimized for the Internet of Things (IoT). https://github.com/taosdata/TDengine
https://github.com/taosdata/TDengine
这篇关于从 MongoDB 迁移到 TDengine 后,成本显著下降的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








