本文主要是介绍MLC-LLM框架的安卓应用部署实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这几天根据官网教程把MLC-LLM在安卓端部署了一下,中间遇到了不少问题,也搜集了不少解决方案,同时也结合了别人的实践经历,现分享总结如下。
感谢博主tao_spyker的文章基于MLC LLM将Llama2-7B模型部署至Android手机运行,虽然有些方法因MLC-LLM框架的改动已经失效,但是有许多库和依赖的安装对我很有帮助!十分感谢!
话不多说,直接开始实战吧!
文章目录
- MLC-LLM框架的安卓应用实战
- MLC Android 中文文档
- 开始使用
- MLC介绍
- Linux环境安装
- 环境配置
- Anaconda
- Rust
- Android Studio
- JAVA
- TVM Unity runtime
- TVM Unity compiler
- 编译模型
- 下载模型
- Cloning MLC LLM from GitHub
- 编译支持安卓的模型
- 用编译后的模型构建安卓工程
- 构建安卓应用
- 注入权重
- From the ashes of bugs,we built android version of MLC-LLM!
MLC-LLM框架的安卓应用实战
MLC Android 中文文档
开始使用
参考自MLC使用文档
MLC介绍
这里稍微讲解了一些MLC的基本概念,以帮助我们使用和了解 MLC LLM。

MLC-LLM 由三个不同的子模块组成:模型定义、模型编译和模型运行。
MLC LLM 的三个独立子模块
➀ Python 中的模型定义。MLC 提供各种预定义架构,例如 Llama(例如 Llama2、Vicuna、OpenLlama、Wizard)、GPT-NeoX(例如 RedPajama、Dolly)、RNN(例如 RWKV)和 GPT-J(例如MOSS)。开发人员可以仅使用纯 Python 定义模型,而无需接触编码。
➁ Python 中的模型编译。模型由TVM Unity编译器编译,其中编译配置为纯 Python。MLC LLM 将基于 Python 的模型量化导出到模型库并量化模型权重。可以用纯 Python 开发量化和优化算法,以针对特定用例压缩和加速 LLM。
➂ 不同平台的模型运行。每个平台上都提供了 MLCChat 的变体:用于命令行的C++ 、用于 Web 的Javascript 、用于 iOS 的Swift 和用于 Android 的Java,可通过 JSON 进行配置。开发人员只需熟悉平台即可将 MLC 编译的 LLM 集成到他们的项目中。
MLC相关术语
MLC中有一些自己定义的术语,我们通过了解这些基本术语,对后面的使用会提供很大的帮助。
modelweights:模型权重是一个文件夹,其中包含语言模型的量化神经网络权重以及分词器配置。model lib:模型库是指能够执行特定模型架构的可执行库。在 Linux 上,这些库文件的后缀为 .so,在 macOS 上,后缀为.dylib,在 Windows 上,后缀为.dll,在WebGPU上,后缀是.wasm。chat config:推理配置,包含允许的自定义参数(例如Temperature 和system prompt)的设置。推理配置与模型权重默认位于同一个目录中。推理配置还包含下面两个在多种模型设置中都支持使用的元数据字段。local_id,应用程序中模型的唯一标识model_lib,指定要使用哪个模型库。
MLC运行流程图
配置好模型权重、模型库和推理设置后,MLC提供了各种MLC 聊天程序帮助用户能直接使用模型,下图显示了 MLC 聊天程序的工作流程。
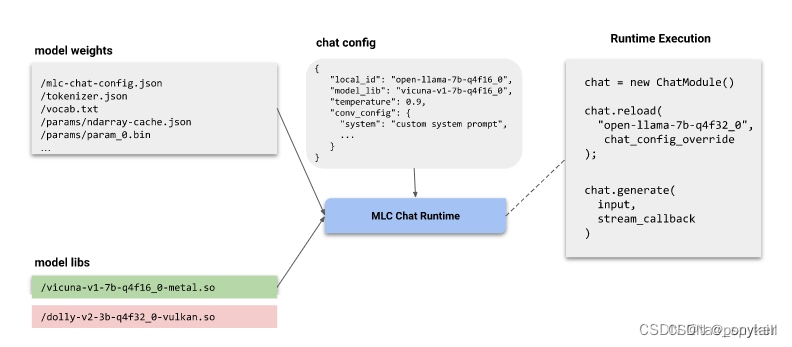
图右侧的伪代码,说明了聊天应用程序的结构。
ChatModule管理模型的类。
chat.reload模型加载,通过local_id来确定需要加载的模型,model_lib来确定需要加载的模型库,同时允许覆盖Temperature 和system prompt等设置
chat.generate结果生成,input为需要输入的内容,stream_callbace为多轮对话的轮数
所有的 MLC聊天程序 运行时(包括 iOS、Web、CLI 等)都会使用这三个元素。所以运行时读取的都是同一个模型权重文件夹。而模型库会根据编译时环境的选择而生成不同的文件。其中 CLI的模型库存储在 DLL 目录中。iOS 和 Android 由于动态加载限制,在应用程序中就预先打包好了模型库。WebLLM则是利用URL来访问本地文件或互联网的 WebAssembly (Wasm) 文件 。
以上拾人牙慧,下面开始我自己的工作。
请注意,本流程在MLC-LLM0.1.0版本可以正常跑通,后续版本更新请根据官网最新文档进行!
Linux环境安装
官网教程理论来说在Windows或者Linux平台上都能跑通,但是Windows平台我在实际测试的时候会在各种地方报各种各样的错误,因此我们选择Linux平台进行整个流程的运行,如果没有Linux系统的可以根据这篇博客:Ubuntu Linux的安装进行安装。
如果你的Linux环境和我一样是新装的,那么你有可能会遇到和我一样的问题:
-
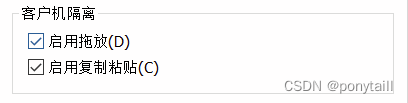
无法在主从机之间进行复制/粘贴。解决方法如下:下载VMware tools,并确保虚拟机设置里面客户机隔离选项勾选
-
虚拟机识别不了USB借口(这个在后面在手机上调试的时候很关键):参考我这篇博文:关于Ubuntu虚拟机识别不了USB设备的解决方案
-
虚拟机突然上不了网了:关于Ubuntu虚拟机突然上不了网的问题
-
Clash for Linux:如果要git clone需要,方案如下:使用文档
-
root密码不正确:这个问题一般是新机才会有,而且准确来说也不是bug,具体来说就是root密码会随着每次启动进行随机更新,只有自己设置了才能固定。
环境配置
这次需要的依赖还挺多的,没有关系我们一步一步来。
注意:因为我的系统是新系统,如果读者的电脑上已经安装了诸如此类的东西,我不敢保证结果和我显示一样,可能会有报错之类的问题,请自助查询资料,如果是新机流程和我一致。
Anaconda
Anaconda基本是必备的吧,可以避免各种包冲突,管理起来也方便,安装教程参考这篇博文:Linux安装anaconda
在MLC中需要使用的python最低版本在3.10以上。
# 创建一个 your-environment的虚拟环境,python版本为3.10
conda create -n your-environment python==3.10
# 进入虚拟环境
conda activate your-environment
注意:之后绝大部分的操作都要在你新建的这个虚拟环境下进行,否则会出现各种问题,例如找不到库。
Rust
来自官网的介绍:Rust (install) is needed to cross-compile HuggingFace tokenizers to Android. Make sure rustc, cargo, and rustup are available in $PATH.
如此安装:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
安装完成后,可以在命令行输入一下命令检验是否安装成功,如果没有结果,则表示安装失败,可以尝试重新安装rust。
rustc --version
Android Studio
进行apk的打包,需要使用Android Studio。
要使用Android Studio就需要安装 SDK、NDK、CMake和JAVA。
其中Android Studio可以在官网中去下载,windows直接执行安装程序,按照默认设置安装即可,linux则是将tar.gz文件解压到对应的目录即可。运行以下命令即可开始使用android studio(需要图形化界面)
./bin/studio.sh
在 Android Studio 单击“File → Settings → Languages & Frameworks → Android SDK → SDK Tools”,选择安装NDK、CMake和Android SDK Platform-Tools。安装完成后,需要在环境变量中去对NDK等进行配置才可使用。

下面是安装完毕之后需要配置的环境变量,具体操作就是 vim ~/.bashrc 打开之后在最下面粘贴即可:(小白注意:里面的路径需要和自己安装的路径一致)
export ANDROID_NDK=/home/User/Android/Sdk/ndk/26.1.10909125
export ANDROID_HOME=/home/User/Android/Sdk
export PATH=$PATH:/home/User/Android/Sdk/cmake/3.22.1/bin
export PATH=$PATH:/home/User/Android/Sdk/platform-tools
export TVM_NDK_CC=$ANDROID_NDK/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android24-clang
export TVM_HOME=/home/User/mlc-llm/3rdparty/tvm
export TVM_HOME=$TVM_HOME/include/tvm/runtime
source $HOME/.cargo/env # RustJAVA
Android Studio需要安装openjdk,官方要求的版本是>17。
# 更新update
sudo apt update
# 安装openjdk17
sudo apt install openjdk-17-jdk
# 查看jdk17的安装路径
sudo update-alternatives --list java
# 用上面命令获取的路径,编入到bashrc文件的最后一行中
vi ~/.bashrc
# 将下面的命令,编入到bashrc文件的最后一行中
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64/bin/java
# 更新环境变量
source ~/.bashrc
TVM Unity runtime
这个就在我们接下来要git clone的包里,在 3rdparty/tvm里面,所以不需要额外下载,只需要在上面环境配置中路径写对即可。
TVM Unity compiler
这个必须要安装,我们需要用这个来对模型进行编译,(官网说如果用prebuilt的话则不用安装,但是我没找到prebuilt在哪,有知道的小伙伴可以提醒我一下)
conda activate your-environment
python -m pip install --pre -U -f https://mlc.ai/wheels mlc-ai-nightly
注意:由于mlc-ai-nigtly这个包不在国内的pip源中,需要在mlc.ai网站的wheels中去进行下载,如果你没有像我一样安装Clash for linux,则根据这篇博文进行安装MLC-LLM
TVM的安装验证:以下命令可以帮助确认 TVM 是否已正确安装为 python 包并提供 TVM python 包的位置
>>> python -c "import tvm; print(tvm.__file__)"
/some-path/lib/python3.10/site-packages/tvm/__init__.py
编译模型
下载模型
好,现在前置环境配置的工作终于完成了,现在可以进行模型的编译了,由于从huggingface上下载模型太慢,这里采用别人提供的国内云盘上的模型:
Llama2模型下载地址
Llama2-7B Hugging Face版本:https://pan.xunlei.com/s/VN_t0dUikZqOwt-5DZWHuMvqA1?pwd=66ep
Llama2-7B-Chat Hugging Face版本:https://pan.xunlei.com/s/VN_oaV4BpKFgKLto4KgOhBcaA1?pwd=ufir
Llama2-13B Hugging Face版本:https://pan.xunlei.com/s/VN_yT_9G8xNOz0SDWQ7Mb_GZA1?pwd=yvgf
Llama2-13B-Chat Hugging Face版本:https://pan.xunlei.com/s/VN_yA-9G34NGL9B79b3OQZZGA1?pwd=xqrg
Llama2-70B-Chat Hugging Face版本:https://pan.xunlei.com/s/VNa_vCGzCy3h3N7oeFXs2W1hA1?pwd=uhxh#
下载好了之后放到虚拟机里面备用,虚拟机务必留出足够的空间!我下载的是Llama2-7B-Chat Hugging Face版本。
Cloning MLC LLM from GitHub
git clone --recursive https://github.com/mlc-ai/mlc-llm/^^^^^^^^^^^
cd ./mlc-llm/
没啥好说的,如果显示没有git命令就安装好了,注意–recursive是必须加的。
编译支持安卓的模型
终于到了最关键的一步!
首先,找到我们放模型的目录,打开终端,运行下面的命令:
我先解释一下:MODEL_NAME这个变量就是你放模型的目录名,QUANTIZATION就是默认的q4f16_1,后面的dist/MODEL_NAME-QUANTIZATION-MLC/就是保存编译之后的文件目录名,建议严格根据官网教程来,除非你知道你在做什么。
MODEL_NAME=Llama-2-7b-chat-hf
QUANTIZATION=q4f16_1
# convert weights
mlc_llm convert_weight ./dist/models/$MODEL_NAME/ --quantization $QUANTIZATION -o dist/$MODEL_NAME-$QUANTIZATION-MLC/# create mlc-chat-config.json
mlc_llm gen_config ./dist/models/$MODEL_NAME/ --quantization $QUANTIZATION \--conv-template llama-2 --context-window-size 768 -o dist/${MODEL_NAME}-${QUANTIZATION}-MLC/# 2. compile: compile model library with specification in mlc-chat-config.json
mlc_llm compile ./dist/${MODEL_NAME}-${QUANTIZATION}-MLC/mlc-chat-config.json \--device android -o ./dist/${MODEL_NAME}-${QUANTIZATION}-MLC/${MODEL_NAME}-${QUANTIZATION}-android.tar
运行完成之后我们就在./dist/ M O D E L N A M E − MODEL_NAME- MODELNAME−QUANTIZATION-MLC这个目录下得到了我们所需的编译后文件,组成如下:
-
Runtime configuration: It configures conversation templates including
system prompts, repetition penalty, sampling including temperature
and top-p probability, maximum sequence length, etc. It is usually
named as mlc-chat-config.json alongside with tokenizer
configurations. -
Model lib: The compiled library that uses mobile GPU. It is usually
named as M O D E L N A M E − {MODEL_NAME}- MODELNAME−{QUANTIZATION}-android.tar, for example,
Llama-2-7b-chat-hf-q4f16_1-android.tar. -
Model weights: the model weights are sharded as params_shard_*.bin
and the metadata is stored in ndarray-cache.json
用编译后的模型构建安卓工程
先进入目录,打开应用设置文件:
cd ./android/library
vim ./src/main/assets/app-config.json
你会看到有两个属性:model_list和model_lib_path_for_prepare_libs,model_lib_path_for_prepare_libs这个属性是用来获取模型对应的Model lib,也就是使用移动的GPU的编译库,对应的是我们刚刚获得android.tar的那个位置。model list里面的属性根据官网介绍理解:
- model_url (Required) URL to the repo containing the weights.
- model_id (Required) Unique local identifier to identify the model.
- model_lib(Required) Matches the system-lib-prefix, generally set during mlc_llm compile which can be specified using --system-lib-prefix argument. By default, it is set to “{model_type}_{quantization}” e.g. gpt_neox_q4f16_1 for the RedPajama-INCITE-Chat-3B-v1 model. If the --system-lib-prefix argument is manually specified during mlc_llm compile, the model_lib field should be updated accordingly.
- estimated_vram_bytes (Optional) Estimated requirements of VRAM to run the model.
这里会给出很多个模型的预设,我们全部删掉,只重新填写自己编译的模型信息即可,如果你不知道该怎么写诸如model_lib什么的,可以去github的issue部分查看或者保留预设。
完成之后,运行:
./prepare_libs.sh
会生成两个文件:
>>> find ./build/output -type f
./build/output/arm64-v8a/libtvm4j_runtime_packed.so
./build/output/tvm4j_core.jar
构建安卓应用
启动Android Studio:将./android文件作为Android studio 项目打开。
首先要将Android设备连接到虚拟机。如果连接成功的话你可以在这里看到你的设备:
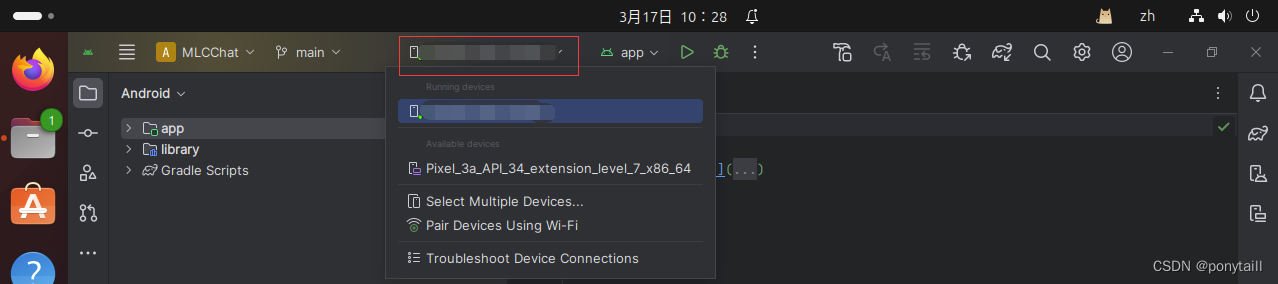 在Android Studio的菜单栏中,单击“Build → Make Project”。构建完成后,单击“Run → Run ‘app’”,这时候你的手机应该会自动安装MLCChat这个软件,但是先不要安装。
在Android Studio的菜单栏中,单击“Build → Make Project”。构建完成后,单击“Run → Run ‘app’”,这时候你的手机应该会自动安装MLCChat这个软件,但是先不要安装。
完成测试之后,生成 APK:点击“Build→Generate Signed Bundle/APK”构建APK进行发布。如果是第一次生成APK,则需要根据Android官方指南创建密钥。此 APK 将放置在android/MLCChat/app/release/app-release.apk.
安装ADB和USB调试:在手机设置的开发者模式中启用“USB 调试”。运行以下命令,如果ADB安装正确,手机将显示为设备:(这里用到的adb 是上面在安装Android studio时安装好的Android SDK Platform-Tools,并且环境已配置好,如果adb不可用,考虑检查环境配置和重新安装)
adb devices
注入权重
刚刚的操作,如果你都完成的话其实已经可以应用了,不过在手机上需要从huggingface上下载权重之后才能运行,并且国内无法访问。
那么我们如何给手机安装软件的同时上传权重以便直接使用呢?教程如下:
运行以下命令,将{MODEL_NAME}和替换{QUANTIZATION}为实际模型名称(例如 Llama-2-7b-chat-hf)和量化格式(例如 q4f16_1)。
# 将apk安装进你的android手机
adb install android/MLCChat/app/release/app-release.apk
# 将模型权重文件上传至android手机的临时文件夹
adb push dist/${MODEL_NAME}-${QUANTIZATION}/params /data/local/tmp/${MODEL_NAME}-${QUANTIZATION}/
# 在android手机上创建apk读取本地模型的文件夹路径
adb shell "mkdir -p /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/"
# 将模型拷贝至apk读取文件夹路径
adb shell "mv /data/local/tmp/${MODEL_NAME}-${QUANTIZATION} /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/"
如果你在最后一步注入权重不成功,手机上还是要联网下载的话,你一定是和我犯了一样的错误,请仔细检查你的模型命名和文件夹命名,可以使用如下的命令来查看权重应该放在具体哪个目录下。
adb shell "ls /storage/emulated/0/Android/data/ai.mlc.mlcchat/files/"
From the ashes of bugs,we built android version of MLC-LLM!
恭喜,如果你排除了所有错误,那么你将在可以手机上成功地运行模型了!
TODO:
- 多跑几个不同大小的模型,结合手机内存,看看上限是几亿的模型。
这篇关于MLC-LLM框架的安卓应用部署实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








