本文主要是介绍十五、自回归(AutoRegressive)和自编码(AutoEncoding)语言模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考自回归语言模型(AR)和自编码语言模型(AE)
1 自回归语言模型( AR)
自回归语言模型(AR)就是根据上文内容(或下文内容)预测下一个(或前一个)可能跟随的单词,就是常说的自左向右(或自右向左)的语言模型任务,即通过前 t - 1(或后 t - 1 ) 个 tokens 来预测当前时刻 t 的 token,代表的自回归语言模型有 ELMO 和 GPT。
1.1 优点
在处理生成类自然语言处理任务时,就是从左向右的,比如文本摘要,机器翻译等,自回归语言模型天然匹配这个过程。
1.2 缺点
该模型是单向的,只能利用上文或者下文的信息,不能同时利用上文和下文的信息。
2 自编码语言模型(AE)
自动编码器的逻辑过程是指原始 input(设为 x)经过加权(W 和 b)、映射(Sigmoid)之后得到 y,再对 y 反向加权映射回来成为 z。通过反复迭代训练(W 和 b),使得误差函数 L(H) 最小,即尽可能保证 z 近似于 x ,即完美重构了 x。那么可以说正向权重(W 和 b)是成功的,很好的学习了 input 中的关键特征。
自动编码器过程图如下:参考自动编码器
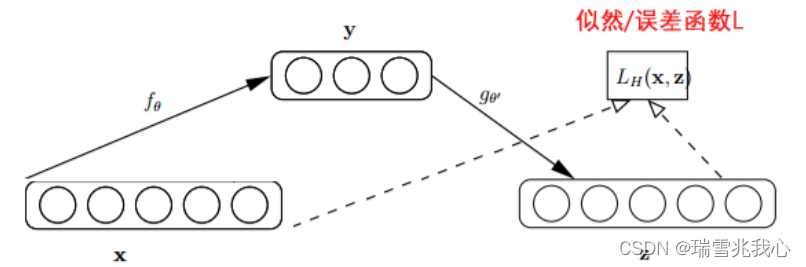
降噪自编码器(Denoising AutoEncoder, DAE)是指当采用无监督(不需要对训练样本进行标记)的方法分层预训练深度网络的权值时,为了学习到较鲁棒的特征,可以在数据的输入层引入随机噪声。
降噪自编码器过程图如下:
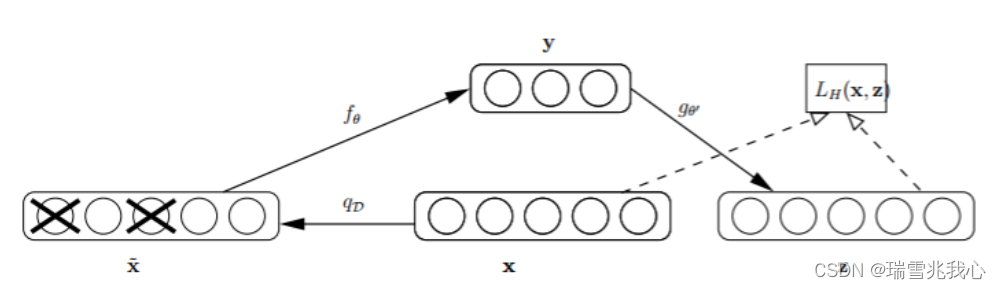
自编码语言模型的名称来自于降噪自编码器(DAE),是通过上下文单词来预测被 [Mask] 的 token(这些被 [Mask] 掉的单词其实就是在输入端加入的噪音,是典型的 的思路),通俗地被称为“完形填空”,代表的自编码语言模型有 Word2Vec(CBOW)和 BERT。
2.1 优点
泛化性强,无监督不需要数据标注,可以自然地融入上下文语义信息。
2.2 缺点
- 适用于“完形填空”式的训练策略,不适用于生成式的问题;
- 在预训练 Pre-Training 阶段,引入独立性假设,没有考虑预测 [MASK] 之间的相关性;
- 输入中引入 [Mask] 这一特殊标记对原始 Token 进行替换,而微调 Fine-Tuning 阶段是没有 [Mask] 标记的,导致预训练阶段和微调阶段的数据不一致。
这篇关于十五、自回归(AutoRegressive)和自编码(AutoEncoding)语言模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







