本文主要是介绍网易考拉商品列表数据接口丨网易考拉商品数据采集丨关键词搜索网易考拉数据接口丨网易考拉API接口文档,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
网易考拉的商品列表数据接口可以通过以下方法进行调用:
-
查询指定分类下的商品列表: 请求参数:categoryID(分类ID)、orderType(排序类型,可选值为0(综合排序)、1(价格从低到高)、2(价格从高到低))、page(页码,默认为1) 返回结果:返回指定分类下的商品列表数据
-
查询指定关键词的商品列表: 请求参数:keyword(关键词)、orderType(排序类型,可选值为0(综合排序)、1(价格从低到高)、2(价格从高到低))、page(页码,默认为1) 返回结果:返回包含指定关键词的商品列表数据
-
查询指定品牌的商品列表: 请求参数:brandID(品牌ID)、orderType(排序类型,可选值为0(综合排序)、1(价格从低到高)、2(价格从高到低))、page(页码,默认为1) 返回结果:返回指定品牌的商品列表数据
kaola.item_search-获取关键词搜索网易考拉商品列表数据接口返回值说明
1.请求方式:HTTP POST GET;复制Taobaoapi2014获取APISDK文件。
2.请求URL:c0b.cc/R4rbK2
3.请求参数:
请求参数:q=连衣裙&start_price=0&end_price=0&page=1&cat=0&discount_only=&sort=&page_size=&seller_info=&nick=&ppath=&imgid=&filter=merge:1;pid:1;cid:0;bid:0;floor:0;color:0;size:0;service:0,0,0,0;style:0
参数说明:q:关键词,没有其他参数
4.请求示例
# coding:utf-8
"""
Compatible for python2.x and python3.x
requirement: pip install requests
"""
from __future__ import print_function
import requests
# 请求示例 url 默认请求参数已经做URL编码
url = "api-gw.xxx.cn/kaola/item_search/?key=<您自己的apiKey>&secret=<您自己的apiSecret>&q=连衣裙&start_price=0&end_price=0&page=1&cat=0&discount_only=&sort=&page_size=&seller_info=&nick=&ppath=&imgid=&filter=merge:1;pid:1;cid:0;bid:0;floor:0;color:0;size:0;service:0,0,0,0;style:0"
headers = {"Accept-Encoding": "gzip","Connection": "close"
}
if __name__ == "__main__":r = requests.get(url, headers=headers)json_obj = r.json()print(json_obj)5.返回结果
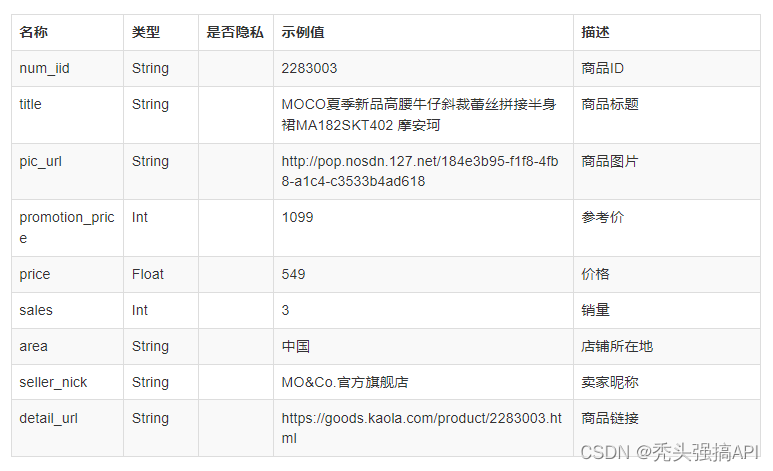
以上是网易考拉商品列表数据接口的一些例子,具体可根据需求选择合适的接口进行调用。
这篇关于网易考拉商品列表数据接口丨网易考拉商品数据采集丨关键词搜索网易考拉数据接口丨网易考拉API接口文档的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







