本文主要是介绍YARN(Yet Another Resource Negotiator),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
概述
YARN(Yet Another Resource Negotiator - 迄今另一个资源调度器),负责集群的任务管理和资源调度。YARN是Hadoop2.X开始出现的,也是Hadoop2.X中最重要的特性之一。也正是因为YARN的出现,导致Hadoop1.X和Hadoop2.X不兼容。
YARN产生的内部原因:
1)在Hadoop1.X中,没有YARN的说法,此时MapReduce分为主进程JobTracker和从进程TaskTracker。JobTracker只允许存在1个,容易出现单点故障。
2)JobTracker负责对外接收任务,接收到任务之后需要将任务拆分成子任务(MapTask和ReduceTask)。JobTracker拆分完任务之后,将子任务分配给从进程TaskTracker。JobTracker会监控每一个TaskTracker的执行情况。在官方文档中指出,每一个JobTracker最多能够管理4000个TaskTracker。如果TaskTracker数量过多,导致JobTracker的效率成别下降,甚至于导致JobTracker的崩溃。
YARN产生的外部原因:
1)在Hadoop产生的时候,市面上并没有太多的大数据框架,因此Hadoop在刚开始涉及的时候,只考虑MapReduce的资源调度问题。
2)后来随着大数据的发展,产生了越来越多的计算框架,很大一部分的框架都是围绕着Hadoop使用,因为Hadoop没有考虑其他框架的资源调度问题,所以这些计算框架就产生了资源调度冲突。
YARN的结构
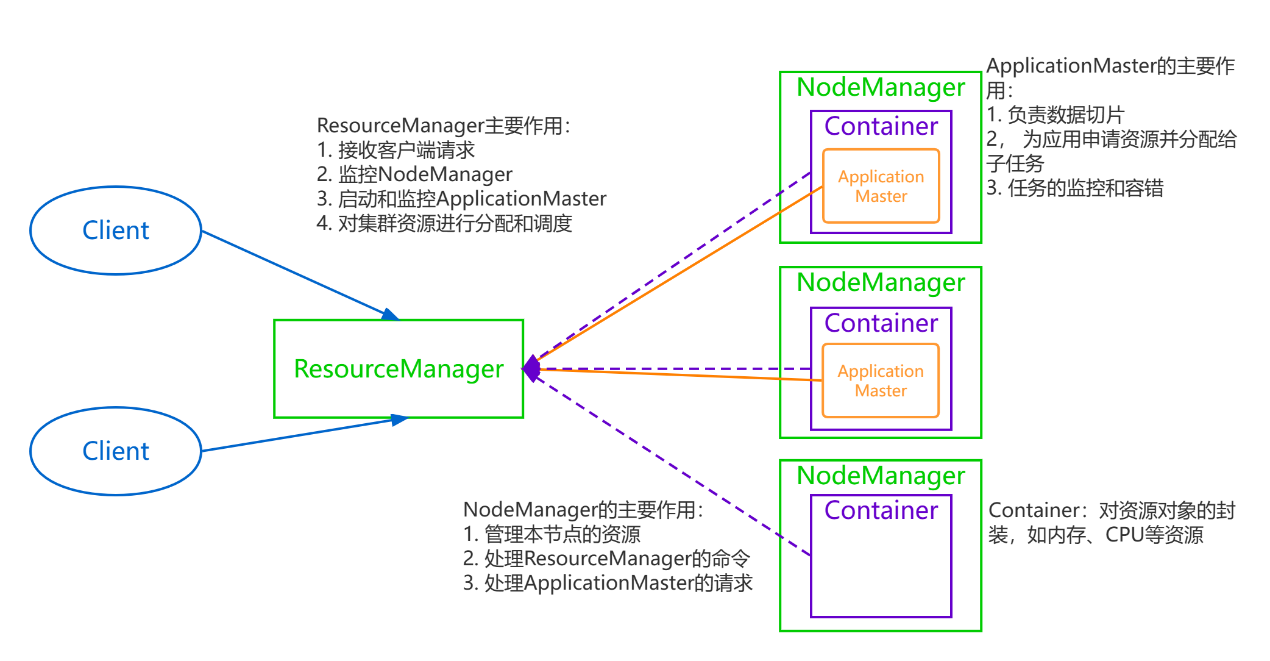
图-1 YARN的结构
YARN中主要包含两类进程:ResourceManager和NodeManager。其中主进程ResourceMAnager负责对外接受请求以及管理NodeManager和ApplicationManster,从进程NodeManager负责执行任务以及管理本节点上的资源。
YARN原理
YARN工作流程(简)
1)MapReduce程序提交到客户端所在的节点,YarnRunner(本质就是job.waitForCompletion)向ResourceManager申请一个Application;
2)ResourceManager收到请求之后,将该Application的资源路径返回给客户端;
3)客户端收到路径之后,将运行该程序所需资源提交到指定路径上;资源提交完毕后,客户端向ResourceManager申请运行MRAppMaster;
4)ResourceManager收到请求之后,将该用户的请求初始化成一个Task,等待NodeManager领取任务;
5)某一个NodeManager领取到Task任务之后,会创建容器Container,并产生MRAppmaster;之后Container从指定路径中拷贝资源到本地;
6)拷贝完成之后,MRAppmaster向ResourceManager申请运行MapTask的资源;
7)ResourceManager收到请求之后,将运行MapTask任务分配给集群中的NodeManager,其他NodeManager分别领取任务并创建容器;
8)MRAppMaster向接收到任务的NodeManager发送程序启动脚本,其他NodeManager分别启动MapTask,MapTask对数据进行处理;
9)MRAppMaster等待所有MapTask运行完毕后,再次向ResourceManager发起请求申请容器用于运行ReduceTask;
10)ResourceManager收到请求之后,ResourceManager返回允许
11)MRAppMaster收到允许之后,创建容器,启动ReduceTask从MapTask处抓取相应分区的数据并处理;
12)程序运行完毕后,MRAppMaster会向RM申请注销自己。
任务提交全流程(详细)
作业提交阶段:
1)Client调用job.waitForCompletion方法,该方法内部封装了submit方法,用于创建JobCommiter对象,创建对象之后,调用submitJobInternal方法向整个集群提交MapReduce任务;
2)提交之后,JobCommiter会向ResourceManager申请一个Application ID,并且这期间,JobCommiter也会检查输出路径的情况以及计算输入分片;
3)ResourceManager收到请求之后,试图给该任务创建一个ID,创建成功之后会将该Application ID以及资源的提交路径(以ID命名的目录路径)返回;
4)JobCommiter收到ID之后,会将该MapReduce的jar包、配置文件和计算所得到的输入切片信息提交到指定的资源路径上;
5)JobCommiter提交完资源后,会通知ResourceManager调用submitApplication方法提交Application,申请运行MRAppMaster。
作业初始化阶段:
1)ResourceManager收到JobCommiter的请求后,调用submitApplication方法,然后通知YARN Scheduler(调度器),将该任务添加到调度器中;
2)某一个空闲的NodeManager从调度器中领取到该任务之后,创建Container,然后产生MRAppmaster进程;
3)启动MRAppMaster进程之后,NodeManager从指定路径下载资源到本地。
任务分配阶段:
1)下载资源之后,回味每一个切片创建MapTask以及指定数量的ReduceTask,之后MRAppMaster向ResourceManager申请运行MapTask任务资源;
2)ResourceManager将运行MapTask任务分配给集群中的NodeManager,其他NodeManager分别领取任务并创建容器。
任务运行阶段:
1)MRAppMaster向接收到MapTask的NodeManager发送资源(jar包,配置文件,缓存文件等),NodeManager分别启动YarnChild进程,执行MapTask对数据进行处理;
2)等所有MapTask运行完毕后,MRAppMaster向ResourceManager申请容器,用于运行ReduceTask;
3)同样,ResourceManager将ReduceTask分配给NodeManager,NodeManager领取到任务之后,启动YarnChild执行ReduceTask,ReduceTask会从MapTask处获取对应分区的数据并处理;
4)程序运行完毕后,MRAppMaster会向ResourceManager申请注销自己。
进度和状态更新:
在YARN中,每一个任务会将其进度和状态(包括counter)返回给应用管理器,客户端每秒(通过属性mapreduce.client.progressmonitor.pollinterval调节,默认为1s)向应用管理器请求进度更新并展示给用户。
作业完成:
除了向应用管理器请求作业进度外,客户端每5秒都会通过调用waitForCompletion方法来检查作业是否完成。时间间隔可以通过属性mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
常用参数
表-1 常用参数
| 参数 | 默认值 | 解释 |
| yarn.scheduler.minimun-allocation-mb | 1024 | 给Container分配的最小内存,单位:MB |
| yarn.scheduler.maximum-allocation-mb | 8192 | 给Container分配的最大内存,单位:MB |
| yarn.scheduler.minimum-allocation-vcores | 1 | 给Container分配的最小核数 |
| yarn.scheduler.maximum-allocation-vcores | 32 | 给Container分配的最大核数 |
| yarn.nodemanager.resource.memory-mb | 8192 | NodeManager能够给Container提供的最大物理内存,单位:MB |
YARN调度器和调度算法
概述
对于YARN Scheduler而言,目前支持三种调度器:FIFO Scheduler(先进先出调度器)、Capacity Scheduler(容量调度器)和Fair Scheduler(公平调度器)。在Hadoop3.2.4中,默认使用的是Capacity Scheduler。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
FIFO Scheduler
FIFO调度器(First In First Out Scheduler,先进先出调度器)是一个单队列调度器,即调度器中只有一个队列,根据任务提交的先后顺序(入队顺序)来依次处理,先提交的任务先处理。如果前边的任务将资源全部占用,那么后续的任务就会被阻塞。
FIFO调度器的优点是简单易懂,缺点是不支持多队列,紧急任务无法先处理,因此生产环境很少使用。
Capacity Scheduler
容量调度器是由Yahoo!开发的一个支持多用户的调度器。
容量调度器支持用户设置多个队列,每一个队列都维系FIFO的规则,用户需要给每一个队列分别设置资源使用的下限和上限。假设有4个队列,那么可以给队列1设置最多占用集群资源的20%,队列2最多占用集群资源的30%,队列3最多占用集群资源的10%,队列4最多占用集群资源的40%。
在容量调度器中,对于每一个队列中的任务,如果队列前边的任务将资源全部占用,那么这个队列后续的任务就会被阻塞。
如果一个队列中的资源暂时剩余,那么可以共享给其他的需要资源的队列,但是一旦该队列需要资源的时候,其他队列需要归还借调的资源给该队列。假设,现在队列1可以占用集群20%的资源,但是队列1中所有任务只占用了10%的资源,剩余10%的资源,而队列2因为资源不足导致还有任务被阻塞无法执行,那么此时队列1可以将剩余的10%的资源借给队列2,供队列2中的任务执行。然而如果此时用户向队列1中提交了新任务,新任务需要使用5%的资源,那么队列2就需要将5%的资源还给队列1,以供队列1中的新任务来执行。
如果不想某队列的资源全部借调出去,那么可以给该队列设置资源的保留比例(资源的下限)。例如设置3%,那么这个队列中无论是否有任务执行,这3%的资源都不会借调出去。
如果同一个用户提交了多个任务,那么该调度器会对同一用户提交的作业所占的资源进行限定。例如队列1最多占用20%的资源,A用户向队列1提交了4个任务,每一个任务需要占用5%的资源,B用户向队列1提交了2个任务,每一个任务也同样要占用5%的资源,那么此时队列1会将10%的资源分给A用户,将10%的资源分给B用户。
需要注意的是,对于容量调度器而言,如果不配置,那么容量调度器中默认只维系一个default队列,没有其他队列。如果需要使用多队列,那么需要用户自己进行配置。
容量调度器的资源分配策略:
1)从整体上(队列间)而言,从root开始,使用深度优先算法,先分配给资源占用较少的队列。例如队列1占用30%,队列2占用20%,队列3占用50%,那么资源的分配就先给队列2,然后是队列1,最后是队列3。注意,不是队列1和3不分配资源!可以这么理解:假设将全部资源(100%)看作是100份食物,一队需要30份,二队需要20份,三队需要50份,那么就先数出20份给二队,然后数出30份给一队,再将最后的50份给三队。
2)每一个队列在获取到资源之后,会给队列内的任务来分配资源。按照任务的优先级、提交时间以及任务id的顺序来分配。队列会先将资源分配给优先级高的任务,如果优先级一致,那么则先将资源分配给提交时间早的任务,如果提交时间一致,则先将资源提交给任务id小的任务。
3)每一个任务在接收到资源之后,会先将资源分配给优先级高的子任务,如果优先级一致,则首先考虑分配个满足数据本地化的任务。
Fair Scheduler
公平调度器是由FaceBook开发的一个支持多队列的资源调度器。
同容量调度器一样,公平调度器也支持多队列、资源配置以及资源共享,不同的地方是:在容量调度器中,假设队列1能占用20%的资源,而队列1中现在有4个任务,如果任务1和任务2需要占用10%的资源,那么队列1的资源就会被耗尽,任务3和任务4就会被阻塞;在公平调度器中,假设队列1能占用20%的资源,同样队列1中有4个任务,那么这4个任务都会参与分配这20%的资源。
在公平调度器中,会优先为缺额大的任务分配资源。例如现在队列中有4个任务执行,此时客户端提交了新的任务,注意,此时公平调度器不会重新分配资源,而是会先给这个新任务分配一点资源(例如先给这个任务分配1%的资源),那么此时分配的资源和任务实际执行需要的资源之间就形成了差额,随着运行时间的延长,会逐步补齐这个差额。
公平调度器的资源分配策略:
1)从整体上而言,还是先给队列之间分配。不过需要注意的是,刚开始是均分,然后逐步调整。例如现在有4个队列,队列1需要的资源为20份,队列2为30份,队列3为15份,队列4为35份。分配过程为:
表-2 分配过程
| 分配 | 计算 | 队列1资源 | 队列2资源 | 队列3资源 | 队列4资源 |
| 第一次 | 100/4=25% | 25,多出5 | 25,缺少5 | 25,多出10 | 25,缺少15 |
| 第二次 | (5+10)/2=7.5 | 20 | 25+7.5=32.5,多出2.5 | 15 | 25+7.5=32.5,缺少2.5 |
| 第三次 | 2.5/1=2.5 | 20 | 30 | 15 | 32.5+2.5=35 |
经过分配之后,各个队列都获取到了自己需要的资源数量。
2)各个队列获取到资源之后,再采用相同的方式,为每一个任务分配资源。不过需要注意,此次分配需要考虑任务是否有加权。假设现在队列有25份资源,队列中有4个任务。
如果没有权重的情况下,任务1需要5份资源,任务2需要10份资源,任务3需要4份资源,任务4需要6份资源。分配过程为:
表-3 分配过程
| 分配 | 计算 | 队列1资源 | 队列2资源 | 队列3资源 | 队列4资源 |
| 第一次 | 25/4=6.25 | 6.25,多出1.25 | 6.25,缺少3.75 | 6.25,多出2.25 | 6.25,多出0.25 |
| 第二次 | (1.25+2.25+0.25)/1=3.75 | 5 | 6.25+3.75=10 | 4 | 6 |
如果有权重的情况下,任务1需要5份资源,权重为6,任务2需要10份资源,权重为4,任务3需要4份资源,权重为8,任务4需要6份资源,权重为2,分配过程为:
表-4 分配过程
| 分配 | 计算 | 队列1资源 | 队列2资源 | 队列3资源 | 队列4资源 |
| 第一次 | 25/(6+4+8+2)=1.25 | 1.25*6=7.5,多出2.% | 1.25*4=5,缺少5 | 1.25*8=10,多出6 | 1.25*2=2.5,缺少3.5 |
| 第二次 | (2.5+6)/(4+2)=1.416667 | 5 | 5+1.416667*4=10.667,多出0.667 | 4 | 2.5+1.41667*2=5.333,缺少0.667 |
| 第三次 | 0.667/2=0.3335 | 5 | 10 | 4 | 5.333+0.3335*2=6 |
这篇关于YARN(Yet Another Resource Negotiator)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







