本文主要是介绍科研学习|论文解读——迈向发现支持系统:复制、重新审视和扩展斯旺森关于基于文献发现雷诺氏病和鱼油之间联系的工作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文标题
Toward Discovery Support Systems: A Replication, Re-Examination, and Extension of Swanson’s Work on Literature-Based Discovery of a Connection between Raynaud’s and Fish Oil
摘要
斯旺森利用已发表的医学文献作为发现的来源,开展了一项研究项目。我们试图复制他发现的雷诺氏病和食用鱼油之间的联系以及开发基于计算机的搜索方法,这些方法可以有效地支持基于文献的发现。我们成功地复制了斯旺森的发现,并开发了一种基于MEDLINE的发现支持方法。根据这些,我们基于“文献中标记出现的频率”和“包含各种标记的记录的数量”计算统计数据。我们讨论了这些统计数据的使用,表明“标记和记录频率”是与某些源文献相关的有益文献的良好指标,并且相对记录频率有助于区分可能包含发现的文献。
1.引言
以印刷和电子方式获取的信息量令人震惊,但如果能够揭示已知信息之间的联系,这些信息只可能是可用信息的一小部分。例如,想象一下,如果已经知道的东西能够被充分应用到新的问题上,那么医学研究可能会采取的方向:通过整合临床医生、药理学家、流行病学家和其他医学科学家的无限发表的文献,以提出新的原因、治疗方法或更有效的疾病治疗方法。
尽管这些发现看起来不太可能,但它们已经开始出现。斯旺森,一位信息科学家描述了三项基于文献的调查,这些调查产生了新知识。第一个假设是食用鱼油有助于治疗雷诺氏病。第二个预测镁对偏头痛的重要性。最后指出精氨酸与 生长激素C 的关系。
斯旺森认为,尽管只包含微弱的线索,但医学文献可以挖掘出隐含的、未被注意的联系,而且有一种逻辑可以帮助发掘它们。更重要的是,在已发表的文章中,潜在联系的数量与已发表的文章数量相比简直是爆炸性的增长。信息科学所面临的挑战是制定策略,利用人类和机器的优势来发现这些未被注意到的联系,并像斯旺森(1993)所说的那样,将信息爆炸变成 “机会爆炸”。
在我们这里报告的工作中,我们试图通过批判性地检查和扩展斯旺森关于基于文献的发现的工作来推动机会爆炸。
2.背景与目标
在斯旺森对雷诺氏病的发现中,涉及的大部分内容是阅读和理解有关雷诺氏病的医学文献,然后运用良好的判断力探索相关主题,直到最终发现鱼油。当然,科学的进步必须建立在对以前工作的复制、扩展甚至否定的基础上。鉴于斯旺森的作品具有独创性、探索性和非系统性,因此尤其需要进行这种重新审视。然而,尽管斯旺森的发现具有重要的科学和社会意义,但没有其他研究者报告进行基于文献的发现实验来证实、否定或以任何方式扩展斯旺森的工作。
因此,重新研究斯旺森发现的雷诺鱼油似乎是明智的。我们这么做的首要目标是:
l 研究并尝试复制从雷诺氏症到鱼油的发现路径;l 帮助调查基于计算机的工具的使用情况,以支持基于文献的发现;l 扩展斯旺森的发现;
3.基于文献的发现逻辑
在许多科学中,研究人员可以控制环境并观察相关效果。例如,一种新的药物在降低高血压方面的有效性可以通过在受试者服用该药物之前和之后的血压读数进行测试。研究人员在解释结果时可能会将成功的治疗归因于血量减少或动脉壁弹性增加。在基于文献的发现中,缺乏直接操纵环境的能力。相反,研究人员必须从逻辑上将一些以前从未尝试过的难题拼凑起来。继续以血压为例,研究人员可能会说,一种能增加动脉壁弹性的物质可能对高血压有帮助。因此,改善动脉弹性的物质是对血压课题的补充。当然,由于研究者试图有所发现,这种特定的物质不能是已经使用或测试过的与血压有关的物质:它必须与血压不相干。
那么,人们如何才能发现互补但互不相干的文献呢?直接研究血压的文献只能揭示已知的关系。这些不可能是新的发现。一种方法是从源头(血压)开始学习和探索与之相关的思想之一的文献(例如,动脉壁弹性)。这就是斯旺森用来发现雷诺氏病和鱼油之间联系的方法。显然,由于这种方法没有计算机的帮助,它需要极大的勤奋和巨大的智力努力。
图2显示了代表这种推理方式的过程,尽管该图中只显示了两条 “路径”。要遍历这个结构,有两个问题占主导地位:第一,应该遵循哪条路径?第二:多远?
为了指导路径的选择,我们使用了与信息检索相关的统计方法来分析与适当文献相关的完整MEDLINE记录。一般的方法是考虑频繁出现的术语(或短语)——或与MEDLINE基准率相关的频繁出现的术语——以作为后续探索的良好候选者。我们在一开始就没有对我们正在寻找的发现的性质做任何假设(例如,它会是饮食)。为了确定一条路径要走多远,我们使用了斯旺森对他的搜索过程的描述(Swanson. 1989c, 1991)。

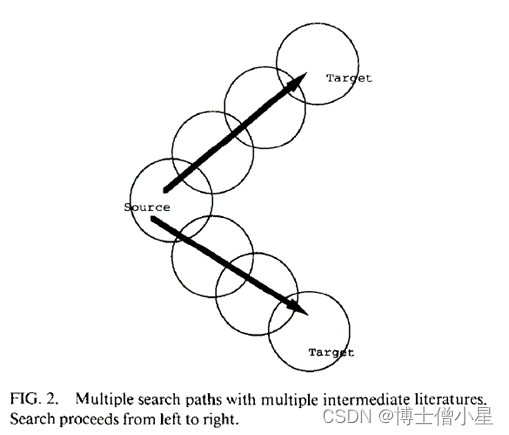
4.斯旺森 雷诺氏病/鱼油 联系的复制
尽管斯旺森对雷诺氏病/鱼油联系的发现是基于反复试验,但回想起来,该过程可以如表1所示:
l 骤 1 和 2 ,选择了一个感兴趣的问题并下载了其文献;l 步骤 3 ,对该文献的检查表明,研究与雷诺氏病有关的血液可能是有利可图的;l 步骤 4 ,下载这些文献的交集(雷诺 ∩ 血液);l 步骤 5 ,揭示两个突出的概念“血液粘度”和“红细胞硬度”;l 步骤 6 ,下载解决血液粘度或红细胞硬度的文献(不一定提到雷诺氏病);l 步骤 7 ,对文献进行检查,揭示鱼油的概念;l 步骤 8 ,搜索与鱼油有关的文献;l 步骤 9 ,检查鱼油和雷诺氏病的文献是否不相关;l 步骤 10 ,试图建立医学基础,认为它们之间存在有意义的关联;

由于我们的工作探索了这种方法的某些方面机械化的可能性,我们想看看基于计算机的辅助是否会有帮助,以及如何帮助。更具体地说,我们想要:
l 表明在研究雷诺氏病时检查血液因子是很自然的 (step 3) ;l 当这件事完成时,你的注意力将转向血液粘度和红细胞硬度 (step 5) ;l 当探索与这些概念相关的文献时,人们会被引向鱼油 (step 7) ;l 显示雷诺和鱼油的不相关 (step 9) ,可用 MEDLINE 和科学引文搜索的组合机械地完成;l 虽然对建立医学发现至关重要 (step 10) ,但属于医学研究的范畴(我们试图支持发现,而不是使之自动化,把医学推理留给那些受过训练的人去做)。相比之下,我们的努力应该被看作是试图给医学研究者提供他们可以使用的文献发现工具,从而将压倒性的、未被注意到的、可以想象到的重要文献之间的联系减少到他们可以利用自己的才能去探索的少数文献。
5.用于文本分析的信息检索
基于文献发现的一个参考学科是IR(Information Retrieval)。在这两种活动中,文献都是感兴趣的有形的对象,两种活动都涉及某种搜索,以满足信息需求。但也有重要的区别:
IRl 是识别与某种信息需求相关的文件集合。 这个集合并不是事先就知道的 ,所以它的特征(比如它所包含的文本标记的统计分布)也是不知道的。相反,这些特征必须通过抽样来猜测或近似。l 一个人对信息的需求往往是明确和不变的 ,即使它作为计算机可处理查询的表达方式会根据新证据发生变化。最后,正常的行动过程是从信息需求的“源”到满足它的单一 “目标”(相关文件集)。基于文献的发现l 与 IR 不同, 其一开始就有一套相关文件 。在雷诺的案例中,我们可以获得关于这个主题的大量、相当完整的文档来开始我们的搜索。l 我们可以提取相关文档的特征,构建类似于在 IR 中构建的查询。但其目的不同: 文献发现者心中没有明确的目标 ,甚至可能无法识别有价值的内容。每一个被发现的连续文献都提供了另一个雷诺(或其他来源)和某个未知目标之间的中途站,两个或多个逻辑跳跃距离。

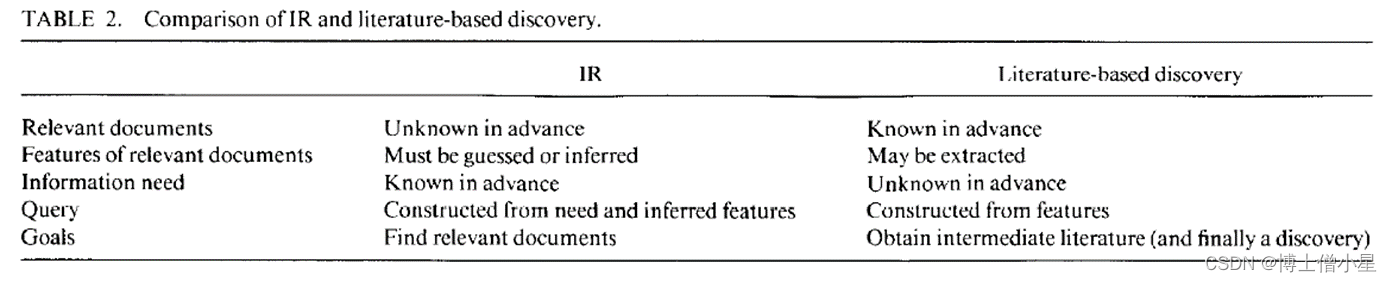
我们的结论是:第一,IR和基于文献发现是不同的过程;但是,第二,由于在基于文献发现方面做得很少,IR似乎提供了一个合适的基础;第三,相对公认的IR方法是最初探索如何使发现更自动一些的最好工具。
在概念上和操作上,确定一个文件是关于什么或与什么有关是IR中最棘手的问题之一。然而,自Luhn(1957)以来,解决这些问题的方法一直是通过计数来分析文本。所以,在我们的调查中,我们对一个术语(或短语)进行了四项计算:(1)标记频率;(2)记录频率;(3)它的乘积,标记频率*对数(逆全局记录频率);(4)它在被研究文献中与整个MEDLINE相比的相对频率。
6.软件
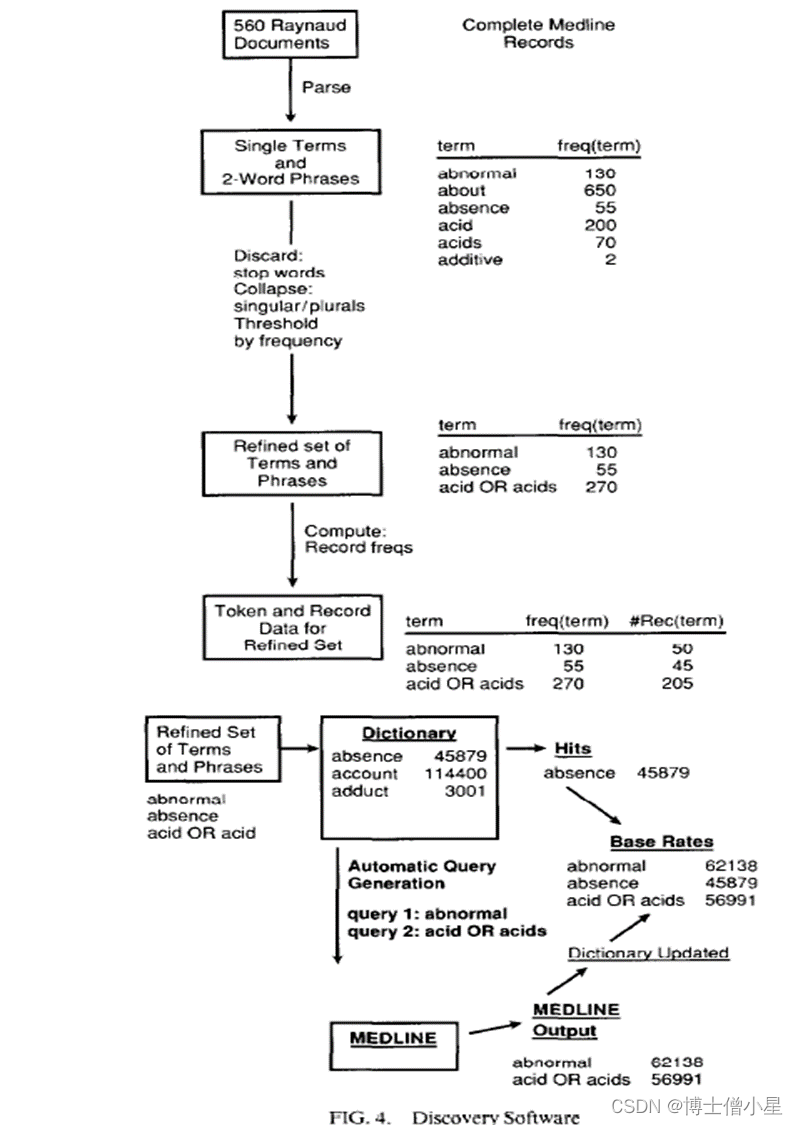
基于文献的发现支持软件的想法是允许医学研究者在搜索可能的联系时方便地检查医学文献。我们已经开发了一套集成的软件模块,在Macintosh电脑上运行,以直观、简洁的方式提供菜单和鼠标驱动的控制(图4中以雷诺氏病作为描述的起点):
l 发现者下载所有 MEDLINE 雷诺文章的完整记录,并进行相关系统设置(应该被检查的 MEDLINE 记录 (record) 字段:标题、作者、引文、摘要等字段;停用词);l 文档解析(分词),并对解析结果进行预处理(去停用词、词干提取、频率阈值过滤、泛指 / 专指的合并等);l 计算单个词( term )的相关频率;l 执行这些操作后剩下的是“我们考虑了两个单词短语,因为它们是术语(或短语)及其标记和记录频率的更精确列表。(先查有没有?没有,则对基于 Medline 生成的 dictionary 进行更新,并计算频率)
7.复制的结果
简而言之,我们的结果证实了斯旺森的论点,即雷诺/鱼油联系没有记录,但可以在医学文献中发现。自然地,在开始研究雷诺的文献并遵循一系列统计线索时,不会直接发现鱼油。但是,只要付出合理的努力,就可以建立这种联系。
血液在这些数据中很突出。(1983年至1985年560篇雷诺文章的分析结果见表4和表5)
l 在单术语数据中(表 4 ),按标记或记录频率,它是排名 第二 的术语,按标记 f * igf ,排名 第十三 ;l 在检查双术语短语时(表 5 ),血流按记录频率 排名最高 ,按标记频率排名 第三 ,按标记 f * igf 排名 第四 。血液粘度和区域血液也占据了较高的位置。由此推断,血液是值得进一步研究的与雷诺有关的主题之一。根据表4和表5中的数据,我们可以选择几个主题中的任何一个(包括血液)作为我们的中间文献来研究。
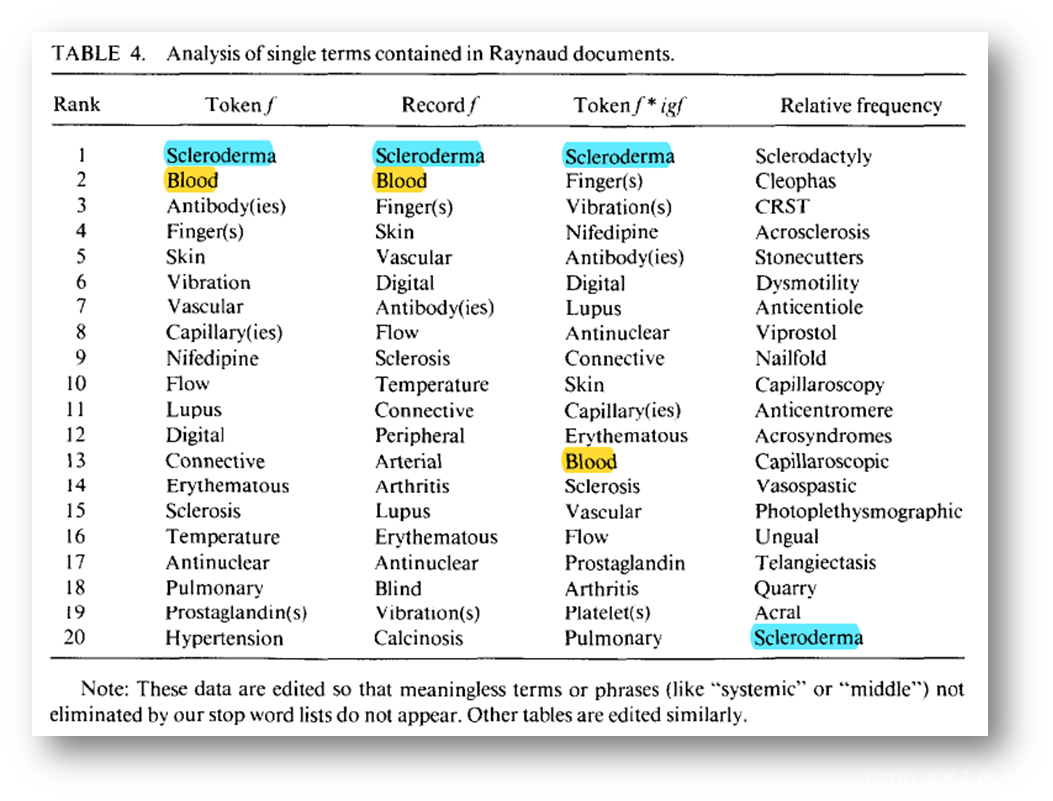
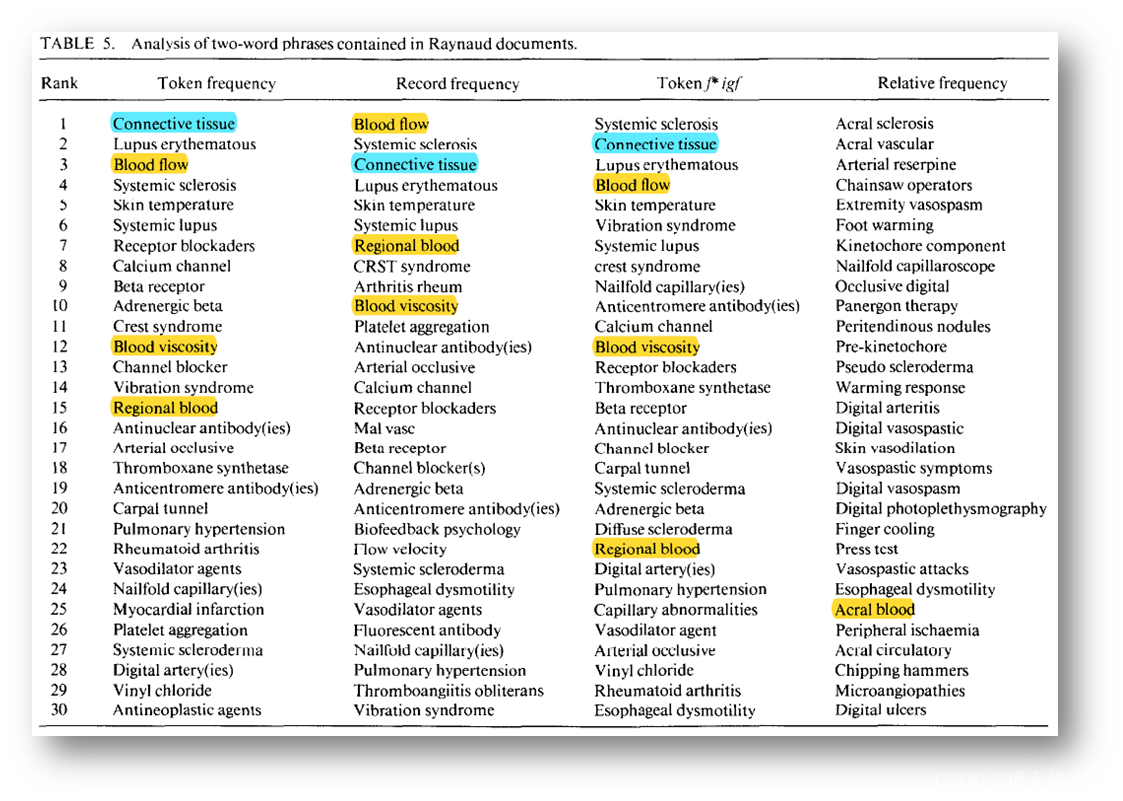
由于我们的目标是复制斯旺森的工作(Table1的Step3),所以我们进行了如下论证:让我们得出“血液对理解雷诺氏病有重要的研究意义”的结论。具体步骤如下:
l 将 4 列中的所有与血液有关的两字短语放在一起,研究它们与雷诺氏症的关系 ;从这 4 列中,形成了与血液有关的双字短语的集合:血液有关的短语 ={ 血液流动 (blood flood) 、血液粘度 (blood viscosity) 、局部血流 (regional blood) 、动脉闭塞性血小板聚集 (arterial occlusive platelet aggregation) 、甲襞毛细血管 (nailfold capillaries) 、指动脉 (digital artery) 、毛细血管异常 (capillary abnormalities)} 。l 我们使用血液相关的术语重新检查雷诺文献 (Table1 的 Step4) ,向 MEDLINE 发出以下查询:雷诺和(血液或动脉 ! 或血小板或毛细血管 ! ),其中“ ! ”表示截断。这一策略试图扩大与血液有关的主题,包括我们确定的特定术语的词汇变化。(通过我们的方法,检索到 232 条记录。分析后的数据如表 6 和表 7 所示)
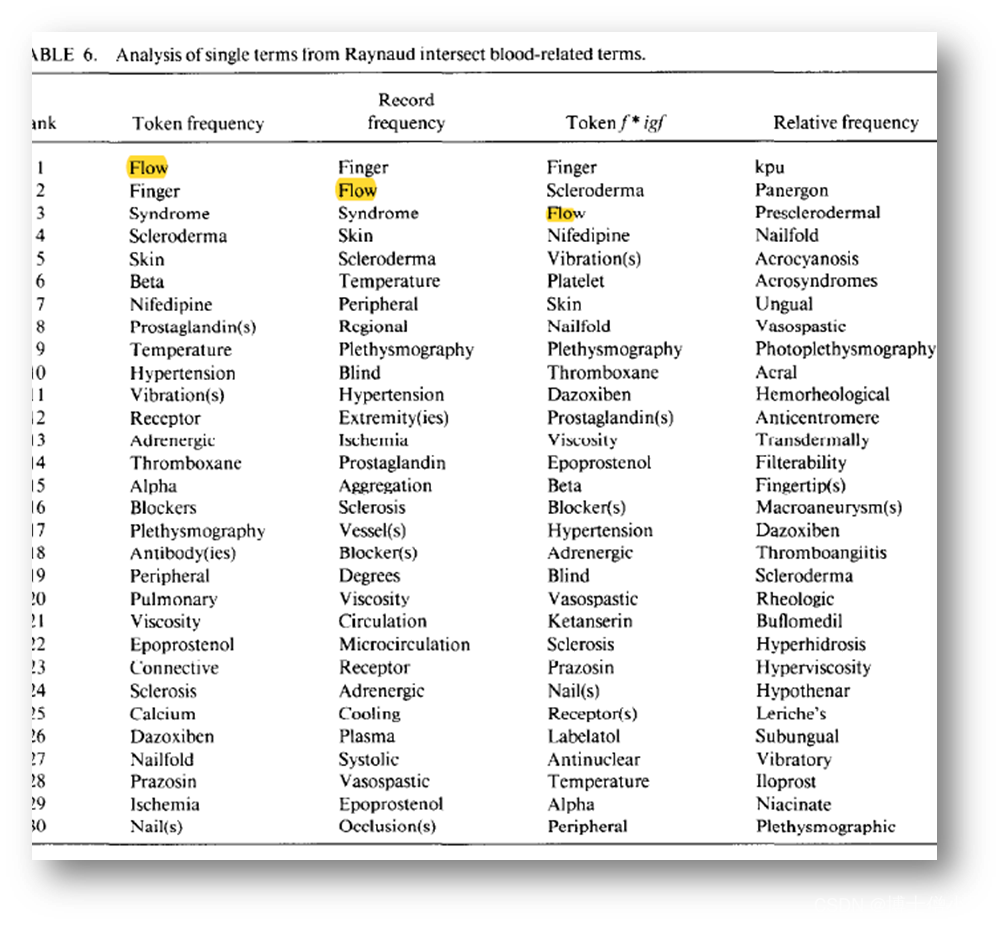

我们接着讨论如下:根据这些结果,血流对雷诺氏病显然很重要。血液粘度Blood viscosity(斯旺森认为这是雷诺病的一个重要血液相关概念)是(a)与血流明显相关,(b)血流受损的一个可能原因,以及(c)其本身在统计学上的显著性。因此,通过斯旺森得出结论,我们将发现血液粘度对雷诺氏病的重要性,并检查血液粘度文献(但不一定要讨论雷诺氏病)(Table1的Step5和Step6)。与斯旺森的研究结果(Table1的Step5)不同,我们发现没有统计支持表明红细胞刚性的重要性。
基于我们的结论,即血液粘度很重要,我们下载并检查了血液粘度文献,使用了已经应用过两次的相同方法。这给我们提供了4列表和另外4列两个词组的排名表。原则上说,没有理由不无限期地重复下载-分析的循环。但是,斯旺森的描述表明,在下载和检查血液粘度文献后,鱼油应该是明显的(Table1,Step7),所以我们试图证明鱼油(fish oil)是明显的。
换句话说,在该阶段,我们考虑的是我们认为与雷诺有关的终端的高级术语和短语——即可能的原因、治疗方法或疗法——而不是可能需要通过下载和统计分析进一步探索的项目。
我们的调查还发现了其他可能有助于雷诺氏病的物质。自1986年1月1日以来,除了鱼油和二十碳四烯酸之外,我们确定的不相干的终端没有一个在MEDLINE记录中与雷诺氏症一起被提及。因此,我们不能确定我们的任何可能的发现对治疗雷诺氏病有合法的效用。然而,我们的方法所揭示的三种物质——多贝斯酸钙、六苯丁和西塞罗——可能被证明是有效的雷诺治疗方法。例如,通过研究有关多贝斯酸钙的文献,我们了解到它可以降低全血和血浆的粘度,具有抗血小板的作用,并增加微循环,以及其他作用。它已被用于治疗静脉功能不全和某些缺血性疾病(血流被阻断的地方),但据我们所知,并没有用于雷诺氏症。
我们还发现了1986年以前与雷诺氏病有关的物质,今天可能值得进一步研究。
最后,在我们最后阶段的检查中,所选择的终端是治疗雷诺氏症的已知疗法和实验测试的药剂--包括“斯塔诺唑”和“硝苯地平”。尽管这些并不符合发现的条件,但它们出现在潜在的终端名单上的事实证明,我们的方法对于发现真正具有医疗效果的物质是有用的。
8.讨论
这说明了什么?当然不是说发现可以完全自动化,但它加强了软件可以帮助支持基于文献的发现这一说法。有一天,我们可能会想象科学家能够在医学文献中寻找新知识。虽然适当的科学背景和阅读医学文献仍然是发现的关键,但发现支持工具可以帮助发现者在科学文献中制定一个更有效的路线。
在本研究中,我们已经试验了四种统计方法,将我们从起点雷诺氏病引向目标——鱼油。尝试四种不同的统计数据,而不仅仅是一种,使我们能够探索统计学的替代方法,因为我们没有先验的理由相信一种统计学可能优于另一种。它还允许我们通过提供收敛性和鉴别性的迹象,更好地考虑任何一个统计学的有效性。换句话说,如果两个统计数据产生了相同的结果,那么使用这两个统计数据就是多余的。另一方面,如果它们的结果是(象征性的)正交的,那么我们可以断定它们是在测量不同的东西。我们发现,三个统计——标记频率、记录频率和标记f*igf——非常相似;第四个统计,相对频率,与其他三个数据的相似性要小得多。
尽管一个单一的实验(发现雷诺/鱼油的联系)对于是否以及如何有效地使用这些统计量没有定论,但对它们如何帮助我们进行调查可能是有启发的。首先,重要的是要牢记这些统计量必须完成的两项工作:第一,它们必须提供雷诺氏症和其他一些主题之间的逻辑联系。第二,这种联系必须是以前未知的。
总结一下,寻求基于文献的发现的合理做法是:首先,通过使用标记计数(以及其他密切相关的统计数据)找到与源文献(例如雷诺的)“相关”的主题;其次,通过计算相对频率来寻找与这些中间主题之一不相交但相关的文献。
9.未来研究
基于文献的发现支持可能有许多应用。仅举一个例子,想想人类基因组计划和相关的分子生物学活动,它们正在以极高的速度产生新信息。在这些领域,研究人员希望获得任何可能为他们的调查提供意想不到线索的信息。例如,这些可能存在于有关核苷酸、基因序列和蛋白质的知识之间的联系。
美国国家生物技术信息中心(NCBI)实现这一目标的方法是为50多个数据库中包含的分子生物学信息提供预编码链接,其中许多数据库是“专家”数据库,主要为一小部分研究人员所知。基因组上的交叉参考信息包括事实之间的联系(例如,关于核苷酸和蛋白质序列)以及事实和已发表文献之间的联系。然而,由于已发表的文章之间的潜在联系的数量比已发表的文章总数的增长速度要快得多,建立明确的交叉引用的索引方案可能无法识别任何东西,只能识别其中很小的一部分。因此,像我们一直在探索的方法是有希望的--不是作为交叉引用的替代品,而是为了更灵活地搜索被掩盖的关系。
这篇关于科研学习|论文解读——迈向发现支持系统:复制、重新审视和扩展斯旺森关于基于文献发现雷诺氏病和鱼油之间联系的工作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





