本文主要是介绍【工作流前进之路】Activiti 权限之用户组-数据查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用户组这个概念在权限系统中,出现的频率可以说是最高的,在百度百科中,对用户组的定义是这样的:在整个网路中,各个访问网络的用户的权限可能是各不相同的,可用将相同权限的用户划分为一组. 使用用户组管理,可以减少网络管理员的负担.
用户组作为流程中的基础数据,Activiti提供了一套控制用户组的API,通过这些API可以对流程的基础数据进行管理.Activiti中用户组对应的表为ACT_ID_GROUP,对应的对象是Group对象,Group是Activiti对外提供的一个接口,一个Group实例表示一条用户组数据.Group接口只提供了相应字段的get和set方法,Activiti中Group有一个实现类GroupEntity,与对象映射关系,普遍应用于各个ORM框架中.
一.创建用户组
IdentityService 提供saveGroup方法,将Group 数据保存到数据库中.具体代码如下:
/*** 保存用户组* @author huan**/
@SuppressWarnings("unused")
public classSaveGroup {
// 将用户组数据保存到数据库中publicstatic void createGroup(IdentityService identityService, String id,
Stringname, String type) {
// 调用newGroup方法创建Group实例
Groupgroup = identityService.newGroup(id);
group.setName(name);
group.setType(type);
identityService.saveGroup(group);
}
}
二.List方法
Query 接口list方法将查询对象应用的实体数据已集合形式返回,对返回的集合需要指定元素类型,如果没有查询条件,则会将表中全部的数据查出,默认按照主键升序排序.
/*** list方法,封装查询结果,返回相应类型的集合* @author huan**/
public classListData {
publicstatic void main(String[] args) {//创建流程引擎
ProcessEngineengine = ProcessEngines.getDefaultProcessEngine();//得到身份服务组件实例
IdentityServiceidentityService = engine.getIdentityService();
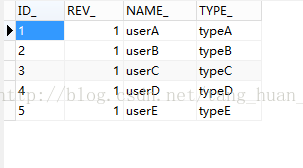
//写入5条用户组数据
SaveGroup.createGroup(identityService,"1","userA","typeA");
SaveGroup.createGroup(identityService,"2","userB","typeB");
SaveGroup.createGroup(identityService,"3","userC","typeC");
SaveGroup.createGroup(identityService,"4","userD","typeD");
SaveGroup.createGroup(identityService,"5","userE","typeE");
//使用List方法查询全部的部署数据
List<Group>datas=identityService.createGroupQuery().list();
for(Groupdata:datas){
System.out.println(data.getId()+"-----"+data.getName()+"");
}}}
三.listpage 方法
listpage方法和list 方法效果相似,唯一不同的就是listpage把查询结果分页了.
/*** listPage 处理查询数据分页问题* @author huan**/
public classlistPage {
publicstatic void main(String[] args) {
// 创建工作流引擎
ProcessEngineengine = ProcessEngines.getDefaultProcessEngine();
// 得到身份服务组件实现
IdentityServiceidentityService = engine.getIdentityService();
// 调用ListPage方法,从索引为3的记录开始,查询2条记录
List<Group>datas = identityService.createGroupQuery().listPage(3, 2);
for(Groupdata:datas){
System.out.println(data.getId()+ "------" + data.getName() + " ");
}
}
}四.count方法
该方法用于计算查询结果的数据量,类似SQL 中的select count语句.
/*** count ,计算查询结果的数据量* @author huan**/
public class count {
publicstatic void main(String[] args) {
//创建流程引擎
ProcessEngineengine=ProcessEngines.getDefaultProcessEngine();
//扥到身份服务组件实例
IdentityService identityService=engine.getIdentityService();
//使用list方法查询全部的部署数据
longcountSize=identityService.createGroupQuery().count();
System.out.println(countSize);
}
}五总结
从代码中我们可以看出,不管是保存还是查询,查询用的是list,listpage 还是count ,这些都和我们学习ORM框架中的方法是一致的,学习是融会贯通的.
这篇关于【工作流前进之路】Activiti 权限之用户组-数据查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





