本文主要是介绍论文笔记(七):DFS--Learning of Image Dehazing Models for Segmentation Tasks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Abstract
为了评估它们的性能,现有的除雾方法通常依赖于所产生的距离测量形象及其相应的基本事实。尽管能够产生视觉上良好的图像,但是使用基于像素或甚至感知的度量通常不能保证所产生的图像适合用作诸如分割的低级计算机视觉任务的输入。为了克服这个弱点,我们提出了一种新颖的端到端图像去雾方法,适合用作图像分割程序的输入,同时保持生成图像的视觉质量。受Generative Adversarial Networks(GAN)成功的启发,我们建议通过引入鉴别器网络和评估去噪图像的分割质量的损失函数来优化发生器。此外,我们利用补充损失函数来验证所生成图像的视觉和感知质量是否在朦胧条件下得以保留。使用所提出的技术获得的结果是吸引人的,当考虑在模糊图像上的分割算法的性能时,与现有技术方法的有利比较。
Introduce
用于分割的图像经常遭受恶劣天气条件,包括雾,雪和雨。如今,深度学习(DL)技术广泛用于执行分段任务。它们需要大量的训练数据来覆盖不同的情况,包括噪声图像,以便正确地推广分割任务。然而,目前可用的数据集不能保证其训练数据中具有足够的代表性或甚至存在某些气象条件(例如,hazy)。因此,使用模糊图像测试模型可能会妨碍低级计算机视觉算法(如分割[1])的性能,即使已知该算法在各种情况下都很强大。因此,在haze条件下从退化观察中恢复图像是一种有用的预处理步骤,可以提高分割效果。在文献中已经广泛研究了几种去雾技术,其中大多数是基于图像退化的物理模型,该问题被简化为估计透射图[2]。通过使用模型(例如,暗信道先验[3])或通过一些学习方法(例如,dehazenet [4])来进行这种估计。其他方法不假设物理模型并且尝试基于生成模型(即,GAN)构建用于雾霾去除的端到端系统,并且直接从模糊的模式恢复原始图像(例如,[5,6])。
通常,仅根据一些经验测量来评估除雾的性能。例如,我们注意到结构相似性指数(SSIM)和峰值信噪比(PSNR)[7]是文献中用于评估去噪方法有效性的最广泛使用的测量方法。 SSIM测量两个图像之间的相似性,同时考虑边缘的相似性。 PSNR是信息传输质量的指标。然而,尽管DL算法在SSIM和PSNR方面的去雾方面表现不错,但无法保证它们能够产生适合用作分割方法输入的图像[8]。该问题仅在文献中发现的少数论文中得到解决,这些论文旨在降低雾度以提高分割质量。在Li等人 [9],进行单朦胧图像的去雾算法,然后使用Fast-RCNN进行微调以进行检测,并对生成的图像上的检测精度进行了改进。Sakaridis等人[10]提出了一种用于分割模糊场景的端到端系统,仅对雾模型数据集进行训练,结果表明该模型能够很好地对朦胧图像进行分割。所提出的模型与Li等人不同。 [9]通过在训练过程中增加分段损失,而不仅仅是对分段进行微调,而且与Sakaridis等人不同。 [10]作为清晰图像分割的预处理步骤,而不是模糊图像的端到端分割技术。最近,刘等人 [11]提出了一种深度神经网络解决方案,它将图像去噪与计算机视觉任务相匹配,并使用联合损耗通过反向传播仅更新去噪网络。然而,它假设在训练期间仅将具有零均值的独立且相同分布的高斯噪声添加到原始图像作为噪声输入图像,这不反映我们在现实世界问题中发现的通常噪声。在本文中,我们的目标是学习如何处理与自然伪影(即雾霾)相关的图像形式。
本文的主要贡献是一种新的基于DL的去雾系统,旨在考虑训练期间的分割性能,提高性能。在报告实验和结果(第3节)之前,我们继续详细说明所提出的方法(第2节),验证所提出的技术对图像有效去雾的能力,可用于图像分割。
网络架构
We are proposing a model derived from the Pix2Pix architecture [13] for dehazing images, with the generator part of the CGAN composed of a downsampling, a residual, and an upsampling block structure inspired from Johnson et al. [14]. The loss function of the generator for single image dehazing is:
L generator = + λ 1
+ λ 2
其中,
和
本身是任务特定元素的损失函数,
在线性组合中加权相对影响。
是Isola等人的损失函数。 [13]用于生成虚假图像。 L像素是基于其各个像素值的去雾(例如真实图像)和伪去雾图像的地面实况之间的重建损失,允许网络产生更清晰的图像。
是用于在发生器的输出中保留图像的重要语义元素的感知损失。 实际上,[5,6,14]显示,感知损失的使用依赖于神经网络的高级表示特征(这里使用了冻结的VGG-16 [15])来提高输出质量。在真实图像和假的去除之间进行比较。值得一提的是,保留了Pix2Pix原始公式中提出的相同GAN鉴别器损失函数。
分割的质量取决于输入质量,输入质量不仅取决于采集设备,还取决于雾霾或其他天气条件等环境条件。 因此,从输入图像中去除这些伪像(例如,通过去雾)可以对分割质量产生影响。 通过使用以下损失函数来训练CGAN生成器来执行用于分割目的的去雾方法(在本文中称为DFS):
L generator = + λ 1
+ λ 2
+ λ 3 L seg
与Eq1相比。 在图1中,它增加了一个新的损耗分量Lseg,它评估了除雾对分割性能的影响。所用DFS模型的结构如图1所示。发生器网络接收带有雾度作为输入的图像并给出 作为输出的去雾图像的候选者。与单图像去雾模型类似,通过LGAN,L像素和L感知计算发生器损耗(等式2)。通过将生成器的输出(即,去雾图像)放入分割网络来计算分割损失Lseg。然后使用L2损失将所获得的分割图与地面实况分割图进行比较。基本上,该模型同时尝试在保留甚至提高分割性能的同时尽可能地去除雾霾。

与文献相比,纽约大学深度雾化数据集上的去雾模型的结果。 DCP代表暗通道先前[3],彩色衰减前置CAP [18],非局部彩色先前[19],多尺度CNN的MSCN [20],DehazeNet的DN [4],CycleGan的CG [21],DDN for Disentangled Dehazing Network [6],而Hazy是原始的模糊图像。 在我们的实验中已经产生了用星号(*)标记的结果,而杨等人报道了其他未标记的结果。[6]。
3 Experiments and Results
3.1 Single Image Dehazing
3.1.1 Dehazing Dataset
D-Hazy数据集用于我们的实验[16]。D-Hazy包含1449对合成模糊图像,基于NYU深度数据集[17],由室内图像及其相应的深度图组成。 使用物理模型从深度图计算雾度,提供真实的雾度。 数据集在训练和测试分区之间拆分80%/ 20%。
3.1.2 Results for single image dehazing
| batch size | optimization | epoch | img_size | λ1 | λ2 |
| 16 | Adam | 200 | 256x256 | 10 | 10 |
拟议的除雾模型使用batch size为16和Adam作为optimization进行了200个epoch的训练。每个图像的大小resize为256x256。对于发电机损耗函数(公式1),将λ1和λ2设置为10,遵循通过验证集上的网格搜索获得的结果,该结果是通过测试λ在1和50之间的10个值而得到的。所提出的技术实现了17.89 dB的PSNR,相比现有技术[15]为15.55 dB,SSIM为0.744,相对于0.77,光衰减为3.4%。表1显示了所提出的模型与多个除雾模型的结果,包括实际的最先进的解缠结的去雾网络[6]。因为我们论文中使用的测试集与Yang等人使用的测试集不同。 [6],我们需要用我们的测试集测试出现在[6]结果中的算法。根据表1中的结果,用我们的测试集(用*标记)获得的结果表明它与Yang等人使用的结果具有相似的难度,甚至可能更难。 [6],DCP和CycleGan在我们的测试装置上表现不佳。我们的结果还凭经验证明了所提出的模型从单个图像中去除雾度的能力。

3.2.1 Training methodology and parameters
除了其去雾能力之外,所提出的DFS模型包含使用分割模型(称为SEG-NET)计算的分割损失。除了分割损失之外,该模型基于与单个图像去雾模型相同的体系结构。为了训练SEG-NET,我们使用不用于训练去雾算法的Cityscape数据集的子集。培训时间为40个epoch,batch size为16,Adam为优化器。使用batch size为8和Adam作为优化器训练DFS模型100个epoch。此处所有图像(大小为2048x1024)都被裁剪为两个正方形(1024x1024)并调整为256x256,需要进行裁剪以保持图像的最大信息量和结构,然后再将其调整为适合此网络的大小和形状。通过使用与单图像去雾相同的逻辑应用网格搜索,将方程2的参数λ1,λ2和λ3分别设置为10,10和5,这次仅在λ3上λ1和λ2都与单图像去雾相同。在DFS模型的训练期间,SEG-NET被冻结(即,不通过梯度下降更新)

3.2.3 Testing methodology
在测试期间,分割结果报告在用于训练DFS模型的相同SEG-NET上,以及在Cityscape,DeepLabv3 [23]上训练的另一个最先进的分割模型上。 DeepLabv3模型不用于培训或验证,仅用于此处报告的最终测试。在使用模拟有和没有分割损失的模型进行去雾后,使用模糊图像并与基础事实非模糊图像进行比较之后,在分割性能之间进行了比较。使用完全相同的训练参数训练DFS模型和单个图像去雾模型。
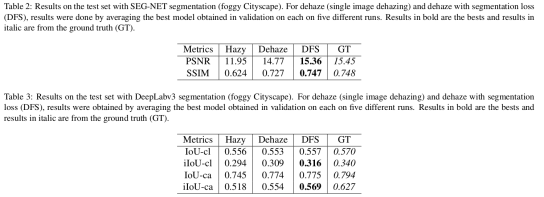
表2显示了PSNR,SSIM和MSE(均方误差)与朦胧图像,去雾图像,具有分割损失的去雾图像和地面真实图像,没有雾度的结果,全部使用SEG-NET分割。表3显示了DeepLabv3的结果,IoU是交集联合度量,ca用于类别,cl用于类,iIoU是指实例级交叉联合度量。根据Cordts等人的说法。 [22],IoU度量偏向于覆盖大图像区域的对象实例。在街景中,可能存在强烈的规模变化,这可能会有问题,特别是对于交通参与者。为了解决这个问题,已经建议使用iIoU度量,其中每个像素的贡献通过类平均实例大小与相应地面实例的大小的比率加权,仅包括具有实例注释的类。措施(类:人,骑手,汽车,卡车,公共汽车,火车,摩托车和自行车,类别:人和车辆)。
3.2.4 Discussion of results
根据SEG-NET和DeepLabv3分割网络获得的结果,似乎在去雾网络中增加分割损失显着提高了后续分割的准确性。
使用SEG-NET和DeepLabv3,与使用没有分段丢失训练的去雾模型相比,使用DFS输出时结果总是更好。平均而言,SEG-NET(PSNR / SSIM)从朦胧到去雾的分割增加约为20%,而从去雾到DFS,实现了3.5%的增长。使用DeepLabv3时,IoU度量差异对于即使有和没有雾度的类别也不重要(0.556对0.570),但IoU有一个很好的改进,从朦胧到除雾(增加3.9%),而有点增益(0.13)从dehaze到DFS观察到%)。然而,使用具有iIoU度量的分段丢失的DeepLabv3观察到显着改善,使用从朦胧到去雾的iIoU的类的分段增强为5.1%,而从去雾到DFS的增益为2.3%。使用iIoU从朦胧到去雾的类别细分的提升为7%,对于去除到DFS的类别,它达到2.7%。
参见图2,图10,11,14,15,26,27,30和31,对于远离场景的感兴趣目标,可以感知到显着的改进,特别是对于汽车和行人的分割,最大的 差异被圈出来。 模糊性(例如,图2.9)和两种去雾技术(例如,图2.10-11)之间的分割性能的差异很大,增加了分割损失,使得结果更加类似于基本事实(例如, ,图2.12)。 正常除雾和DFS之间的比较(例如,图2.22-23)显示出更相似的结果,DFS对于远离场景的目标看起来更好一些。 分段网络似乎对我们在查看图像时通常不会注意到的元素敏感。
4 .Conclusion
简而言之,本文证明了在深度学习模型的端到端训练中将分段丢失包括在去雾中的有用性。 基于学习的去雾模型不仅用于去噪指标,还用于实现对特定任务有用的事物的优化标准,并且与使用非制导方法获得的结果相比具有显着的性能改进。 此外,我们可以考虑直接使用IoU / iIoU梯度下降度量的近似来提高DFS的性能[24],这是比均方误差和类似的更好的优化度量。
conference
[1] Robby T Tan. Visibility in bad weather from a single image. In IEEE conference on Computer Vision and Pattern
Recognition (CVPR), pages 1–8. IEEE, 2008.
[2] Raanan Fattal. Single image dehazing. ACM transactions on graphics (TOG), 27(3):72, 2008.
[3] Kaiming He, Jian Sun, and Xiaoou Tang. Single image haze removal using dark channel prior. IEEE transactions on
pattern analysis and machine intelligence, 33(12):2341–2353, 2011.
[4] Bolun Cai, Xiangmin Xu, Kui Jia, Chunmei Qing, and Dacheng Tao. Dehazenet: An end-to-end system for single
image haze removal. IEEE Transactions on Image Processing, 25(11):5187–5198, 2016.
[5] Runde Li, Jinshan Pan, Zechao Li, and Jinhui Tang. Single image dehazing via conditional generative adversarial
network. methods, 3:24, 2018.
[6] Xitong Yang, Zheng Xu, and Jiebo Luo. Towards perceptual image dehazing by physics-based disentanglement and
adversarial training. In Association for the Advancement of Artificial Intelligence (AAAI), 2018.
[7] Cosmin Ancuti, Codruta Orniana Ancuti, Radu Timofte, Luc Van Gool, Lei Zhang, Ming-Hsuan Yang, Vishal M Patel,
He Zhang, Vishwanath A Sindagi, Ruhao Zhao, et al. Ntire 2018 challenge on image dehazing: Methods and results.
2018.
[8] Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking
single-image dehazing and beyond. IEEE Transactions on Image Processing, 28(1):492–505, 2019.
[9] Boyi Li, Xiulian Peng, Zhangyang Wang, Jizheng Xu, and Dan Feng. Aod-net: All-in-one dehazing network. In IEEE
International Conference on Computer Vision (ICCV), pages 4770–4778, 2017.
[10] Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Semantic foggy scene understanding with synthetic data. Inter-
national Journal of Computer Vision, pages 1–20, 2018.
[11] Ding Liu, Bihan Wen, Xianming Liu, Zhangyang Wang, and Thomas Huang. When image denoising meets high-level
vision tasks: A deep learning approach. In International Joint Conference on Artificial Intelligence, IJCAI, pages
842–848. International Joint Conferences on Artificial Intelligence Organization, 2018.
12] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and
Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680,
2014.
[13] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial
networks. In IEEE conference on Computer Vision and Pattern Recognition (CVPR), pages 1125–1134, 2017.
[14] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In
European Conference on Computer Vision, pages 694–711. Springer, 2016.
[15] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv
preprint arXiv:1409.1556, 2014.
[16] Cosmin Ancuti, Codruta O Ancuti, and Christophe De Vleeschouwer. D-hazy: a dataset to evaluate quantitatively
dehazing algorithms. In IEEE International Conference on Image Processing (ICIP), pages 2226–2230. IEEE, 2016.
[17] Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from
rgbd images. In European Conference on Computer Vision (ECCV), pages 746–760. Springer, 2012.
[18] Qingsong Zhu, Jiaming Mai, Ling Shao, et al. A fast single image haze removal algorithm using color attenuation prior.
IEEE Trans. Image Processing, 24(11):3522–3533, 2015.
[19] Dana Berman, Shai Avidan, et al. Non-local image dehazing. In IEEE conference on Computer Vision and Pattern
Recognition (CVPR), pages 1674–1682, 2016.
[20] Wenqi Ren, Si Liu, Hua Zhang, Jinshan Pan, Xiaochun Cao, and Ming-Hsuan Yang. Single image dehazing via multi-
scale convolutional neural networks. In European conference on computer vision, pages 154–169. Springer, 2016.
[21] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-
consistent adversarial networks. In IEEE International Conference on Computer Vision (ICCV), pages 2223–2232,
2017.
[22] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In IEEE
conference on Computer Vision and Pattern Recognition (CVPR), pages 3213–3223, 2016.
[23] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for se-
mantic image segmentation. arXiv preprint arXiv:1706.05587, 2017.
[24] Maxim Berman, Amal Rannen Triki, and Matthew B Blaschko. The lovász-softmax loss: a tractable surrogate for the
optimization of the intersection-over-union measure in neural networks. In IEEE conference on Computer Vision and
Pattern Recognition (CVPR), pages 4413–4421, 2018.
这篇关于论文笔记(七):DFS--Learning of Image Dehazing Models for Segmentation Tasks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







