本文主要是介绍程序猿必备福利之二下篇!!!简易使用Nodejs实现从美图网爬取清晰脱俗的美图??,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从程序猿必备福利之二上篇我们知道了将请求到的数据写入文件和对请求地址进行安全判断,然而请求到数据都是一整块的text/HTML网页文件格式的数据,这时我们要对数据进行筛选,则需要用一个到第三方模块cheerio可查看了解一下使用方法
当然这里还是要先爆一波福利,本章节加上 程序猿必备福利之二上篇 点击查看 你学会了,你就会这波福利了,嘿嘿嘿嘿嘿!!! 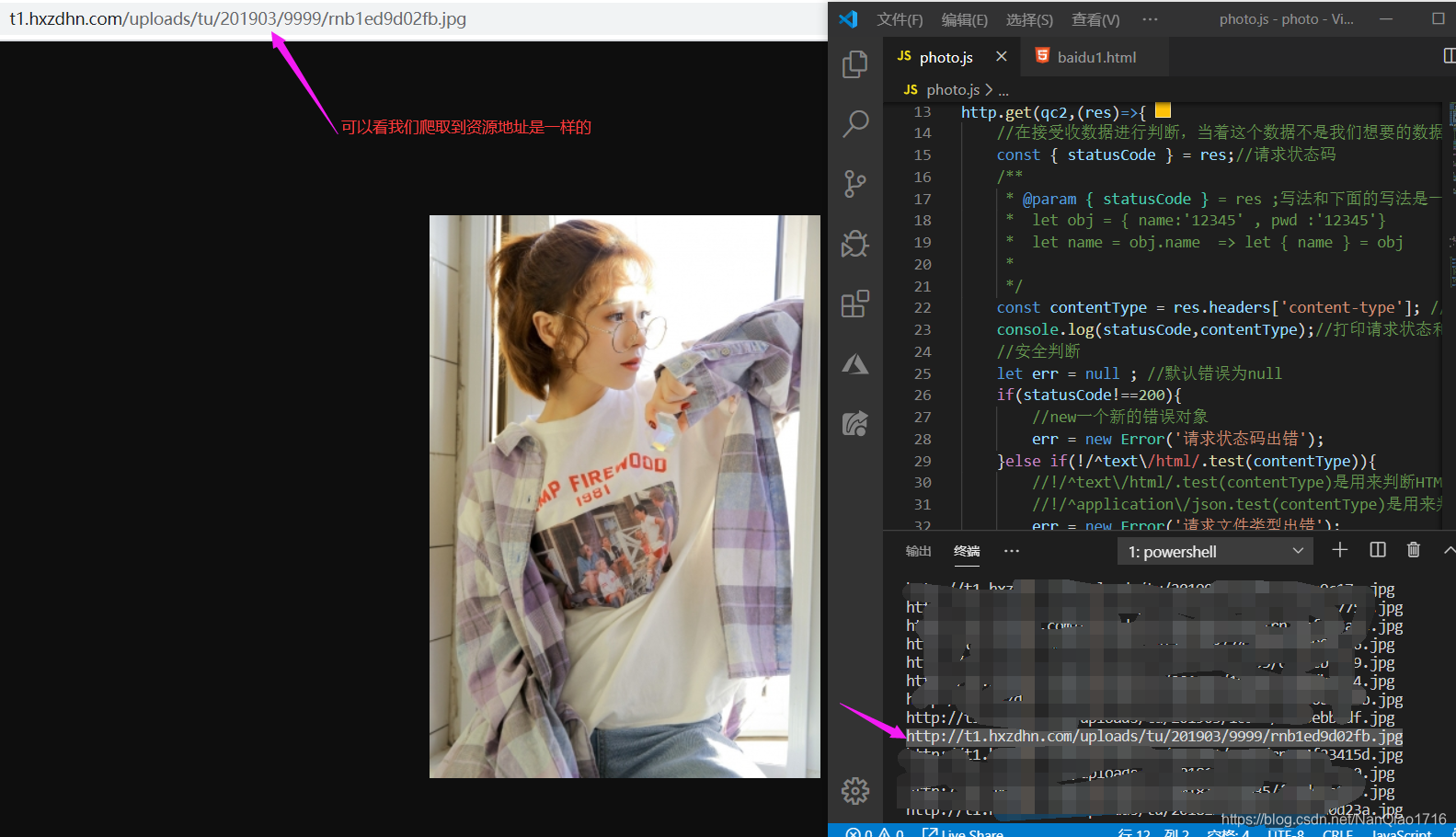
1.这里还是要重复一遍如对nodejs有什么不懂可以查看下面相关内容,浅学易懂 ,知晓nodejs的可以略过
- 推荐的相关资料,内容都是满满的干货
- i.小白如对nodejs是什么,以及nodejs npm配置源是什么不知可查看nodejs简介 以及配置nodejs的环境变量
- ii.如不知nodejs简单的对文件与文件夹的curd请查看文件的curd或查看node文件的读写判断以及Nodejs对内置模块fs的进阶使用方法技巧nodejs进阶
- iii.如对这些都以知晓可查看nodejs如何使用第三模块express简单创建服务器查看
- vi.如何使用express框架搭建node服务,编写node脚本代码,并在浏览器请求服务,简单体验前后交互的流程,点击查看前后交互流程以及前后交互的js代码
2.现在开始进入我们的正题,从程序猿必备福利之二上篇知道我们请求的数据都是网页文件格式而且是一整块的,这个时候我们则需要引用第三方模块cheerio对文件进行筛选,刚开始的时候有提到过,进入官网查看cheerio使用方法
- i.在控制台输入npm install cheerio --save,安装cheerio
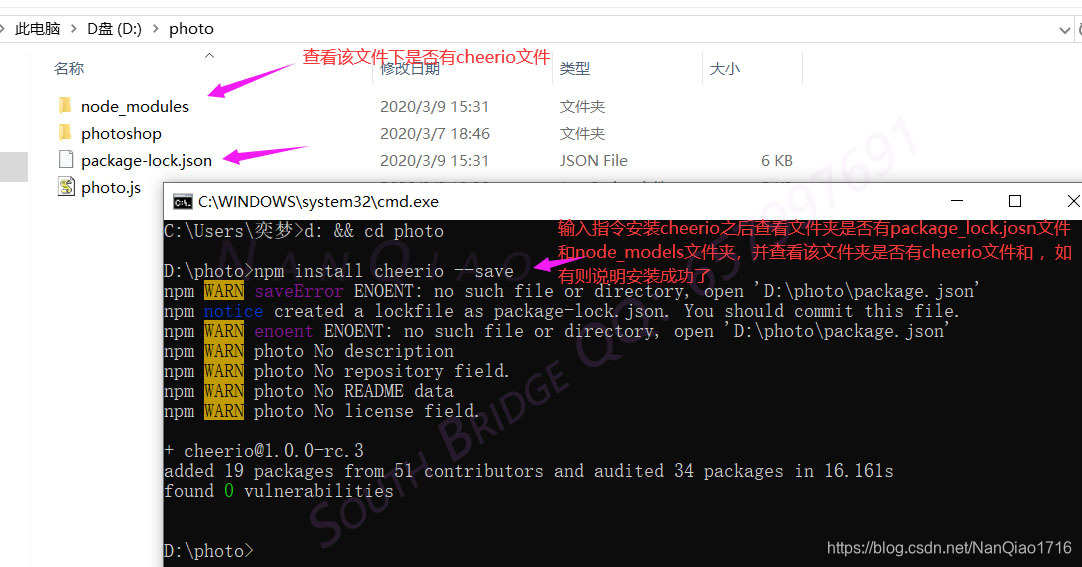
- ii.简单介绍一下cheerio的使用方法,如果你会jq(jquery)那么用起来就会很简单,这里我从官网粘贴了使用方法并解释其含义和稍微改动了一下使用方法,方便你们能更懂
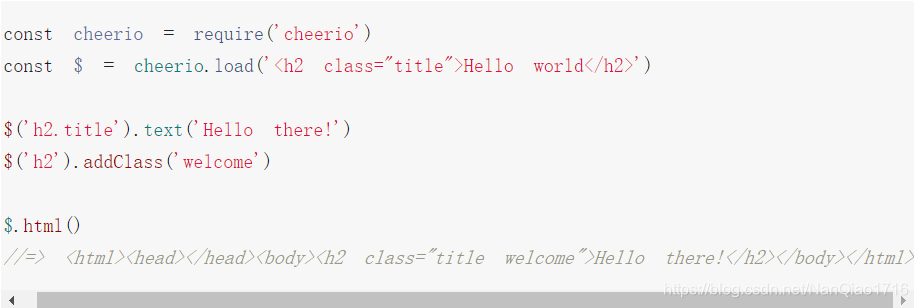
- 官网代码中使用方法及注释
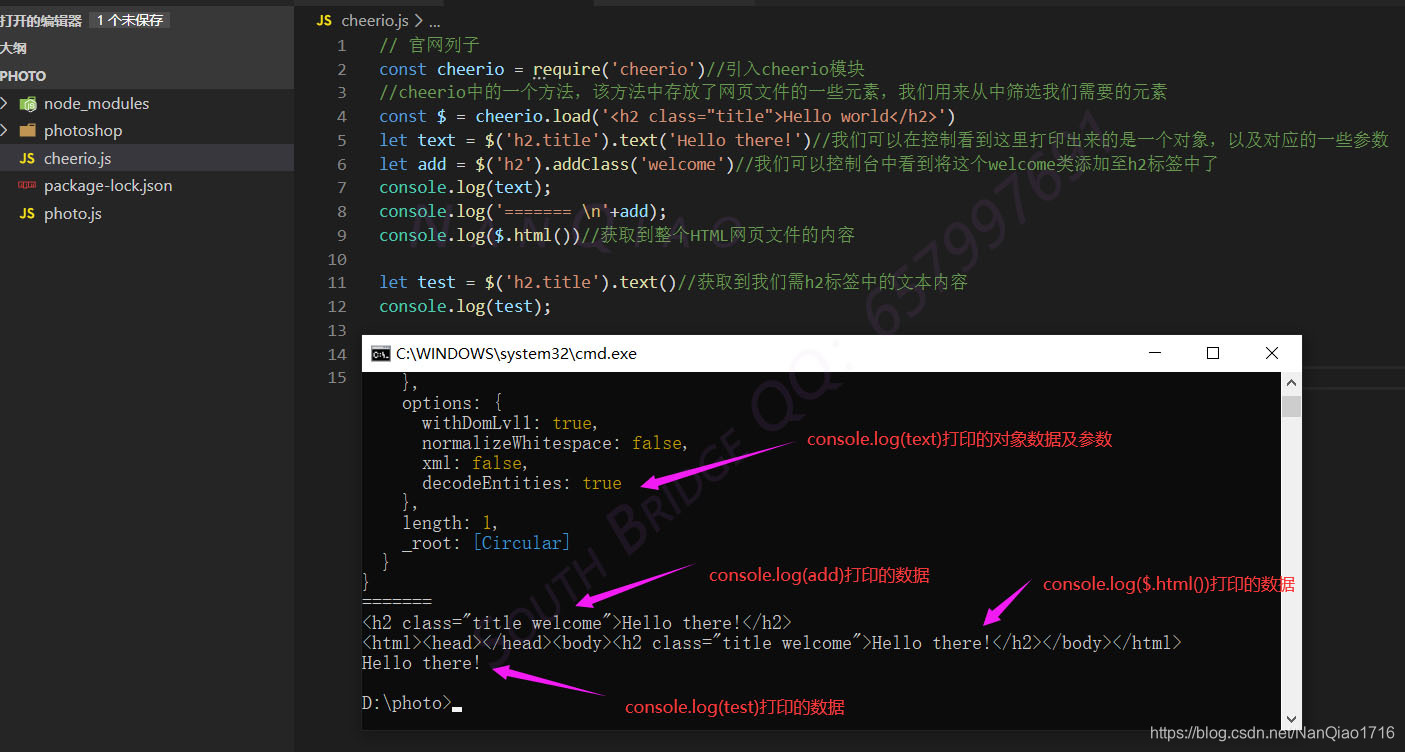
- 我们需要用到img的方法使用及详解
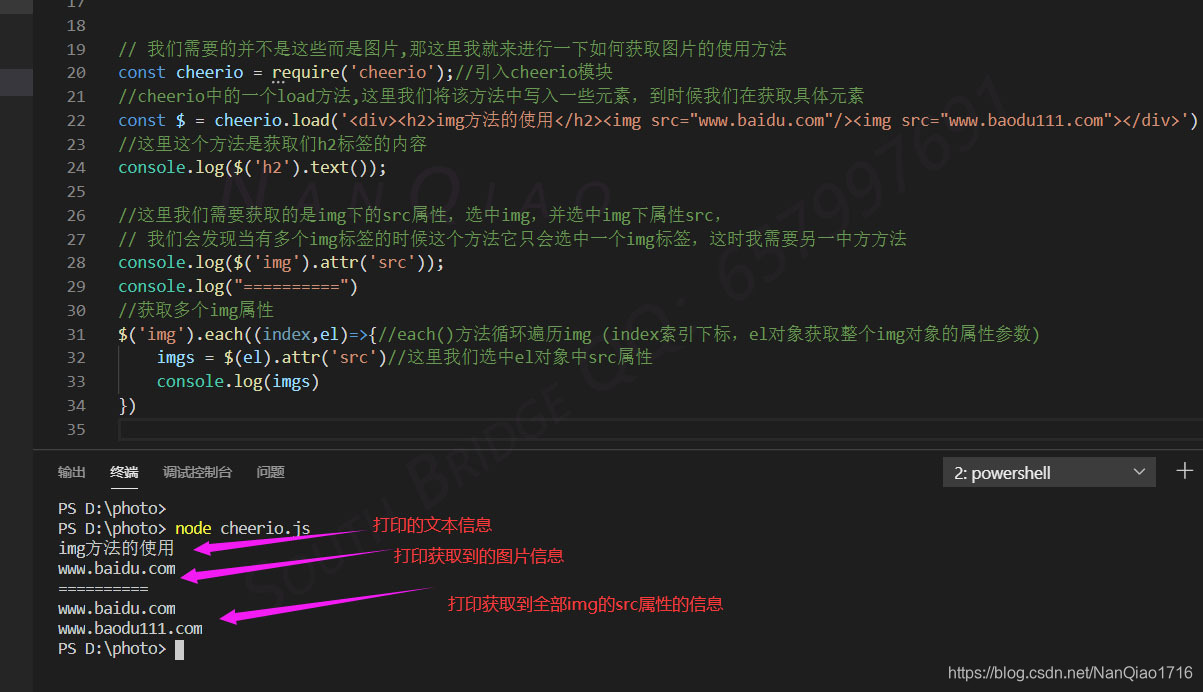
- 官网代码中使用方法及注释
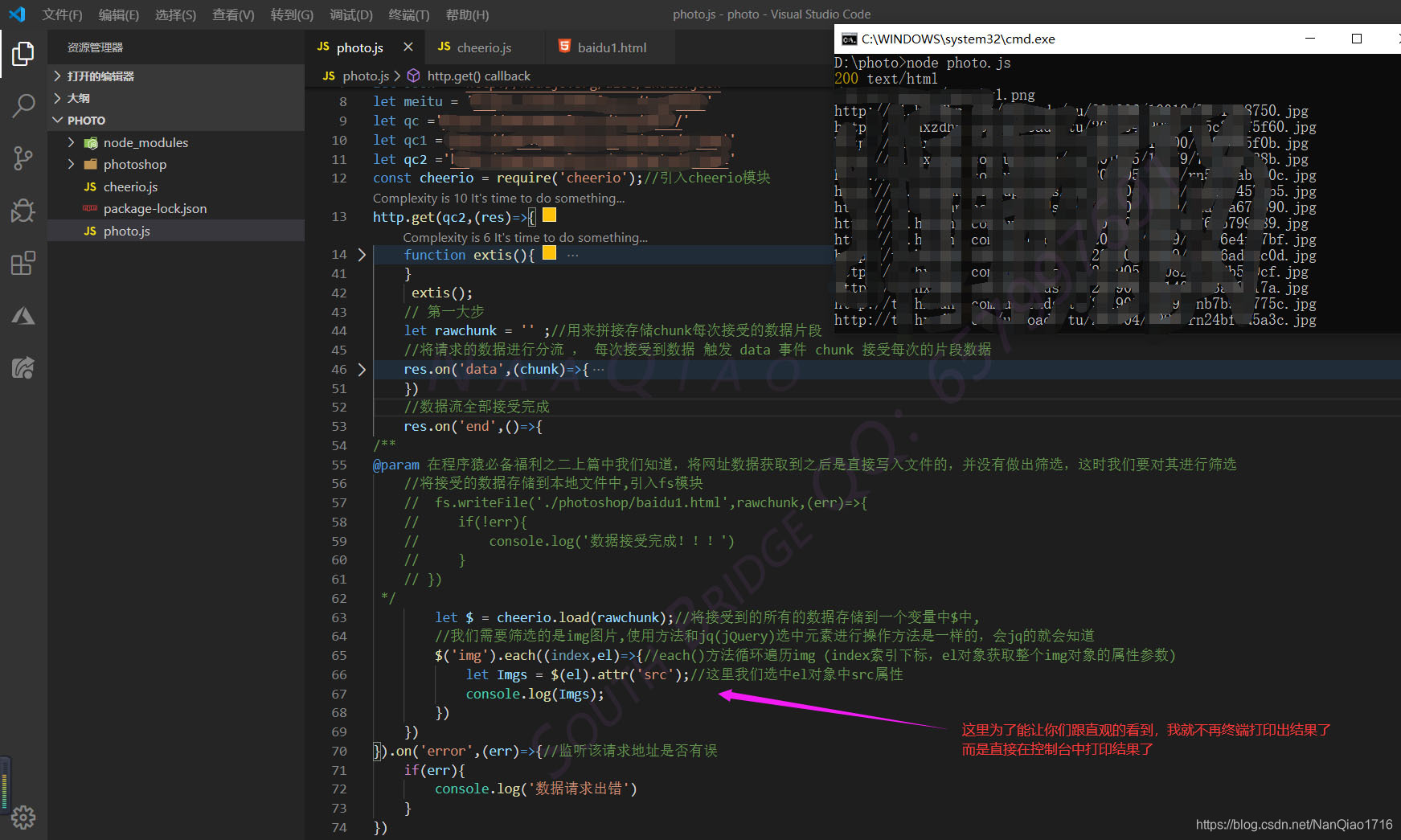
3.我们知道cheerio的使用方法之后,那么就在开始来筛选我们从整个网址中获取的img图片信息,在程序猿必备福利之二上篇中我们知道,将网址数据获取到之后是直接写入文件的,并没有做出筛选,这时我们要对其进行筛选
- i.对请求的数据进行筛选
- ii.查看筛选后的结果
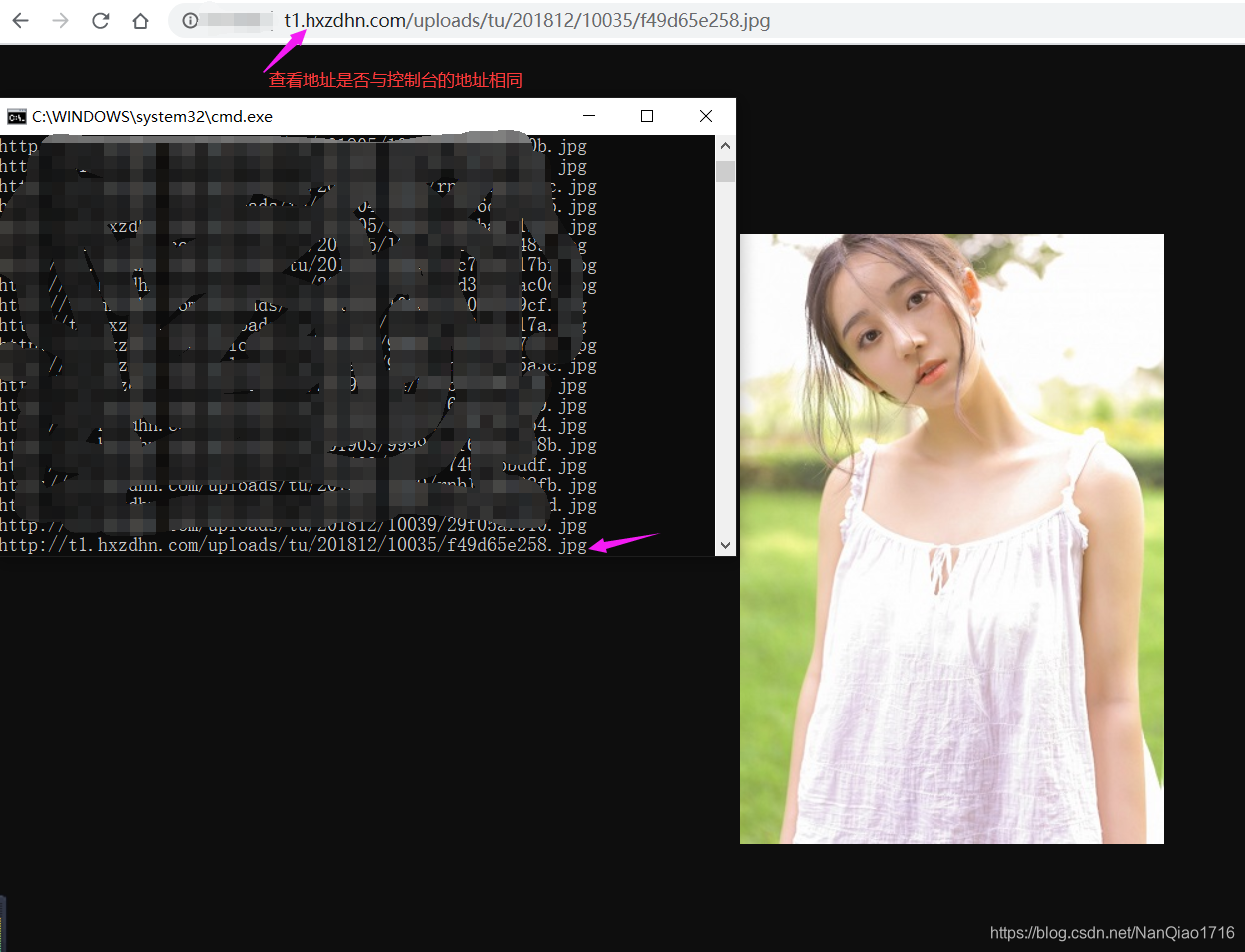
4.如何从美图网爬取美图,程序猿必备福利之二下篇就说到这里了!!! 下期分享如何将美图存储到本地或者是如何将美图发送之邮箱亦或者是如何爬取美国高清大片这三者之一,关注下期见其分晓每期分享不同的干货哦
这篇关于程序猿必备福利之二下篇!!!简易使用Nodejs实现从美图网爬取清晰脱俗的美图??的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








