本文主要是介绍MPP数据架构设计的缺点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、MPP架构
二、批处理架构和MPP架构
三、MPP架构的OLAP引擎
一、MPP架构
随着分布式、并行化技术成熟应用,MPP引擎逐渐表现出强大的高吞吐、低延时计算能力,有很多采用MPP架构的引擎都能达到“亿级秒开”。例如Impala、ClickHouse、Druid、Doris等都是MPP架构。目前商用的服务器分类大体有三种:
-
SMP(对称多处理器结构)
即对称多处理器结构,就是指服务器的多个CPU对称工作,无主次或从属关系。SMP服务器的主要特征是共享,系统中的所有资源(如CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,即扩展能力非常有限。
-
NUMA(非一致存储访问结构)
即非一致存储访问结构。这种结构就是为了解决SMP扩展能力不足的问题,利用NUMA技术,可以把几十个CPU组合在一台服务器内。NUMA的基本特征是拥有多个CPU模块,节点之间可以通过互联模块进行连接和信息交互,所以,每个CPU可以访问整个系统的内存(这是与MPP系统的重要区别)。但是访问的速度是不一样的,因为CPU访问本地内存的速度远远高于系统内其他节点的内存速度,这也是非一致存储访问NUMA的由来。
这种结构也有一定的缺陷,由于访问异地内存的时延远远超过访问本地内存,因此,当CPU数量增加时,系统性能无法线性增加。
-
MPP(大规模并行处理结构)
即大规模并行处理结构。MPP的系统扩展和NUMA不同,MPP是由多台SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。每个节点只访问自己的资源,所以是一种完全无共享(Share Nothing)结构。
MPP结构扩展能力最强,理论可以无限扩展。由于MPP是多台SPM服务器连接的,每个节点的CPU不能访问另一个节点内存,所以不存在异地访问的问题。MPP架构图如下:

每个节点内的CPU不能访问另一个节点的内存,节点之间的信息交互是通过节点互联网络实现的,这个过程称为数据重分配。但是MPP服务器需要一种复杂的机制,来调度和平衡各个节点的负载和并行处理过程。
MPP架构特征:
- 任务并行执行;
- 数据分布式存储(本地化);
- 分布式计算;
- 高并发;
- 横向扩展,支持集群节点的扩容;
- Shared Nothing(完全无共享)架构
NUMA和MPP区别:
- 相似点:NUMA和MPP都是由多个节点组成的;其次每个节点都有自己的CPU、内存、I/O等;都可以都过节点互联机制进行信息交互。
- 区别:
- 节点互联机制不同:NUMA的节点互联是在同一台物理服务器内部实现的,MPP的节点互联是在不同的SMP服务器外部通过I/O实现的。
- 内存访问机制不同,在NUMA服务器内部,任何一个CPU都可以访问整个系统的内存,但异地内存访问的性能远远低于本地内存访问,因此,在开发应用程序时应该尽量避免异地内存访问。而在MPP服务器中,每个节点只访问本地内存,不存在异地内存访问的问题。
二、批处理架构和MPP架构
批处理架构(如 MapReduce)与MPP架构的异同点,以及它们各自的优缺点是什么呢?
(1)相同点:
批处理架构与MPP架构都是分布式并行处理,将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
(2)不同点:
批处理架构和MPP架构的不同点可以举例来说:我们执行一个任务,首先这个任务会被分成多个task执行,对于MapReduce来说,这些task被随机的分配在空闲的Executor上;而对于MPP架构的引擎来说,每个处理数据的task被绑定到持有该数据切片(tablet)的指定Executor上。
正是由于以上的不同,使得两种架构有各自优势也有各自缺陷:
(3)批处理的优势:
对于批处理架构来说,如果某个Executor执行过慢,那么这个Executor会慢慢分配到更少的task执行,批处理架构有个推测执行策略,推测出某个Executor执行过慢或者有故障,则在接下来分配task时就会较少的分配给它或者直接不分配,这样就不会因为某个节点出现问题而导致集群的性能受限。
(4)批处理的缺陷:
对于批处理而言,它的优势也造成了它的缺点,会将中间结果写入到磁盘中,这严重限制了处理数据的性能。
(5)MPP的优势:
MPP架构不需要将中间数据写入磁盘,因为一个单一的Executor只处理一个单一的task,因此可以直接将数据stream到下一个执行阶段。这个过程称为
pipelining,它提供了很大的性能提升。
(6)MPP的缺陷:
对于MPP架构来说,因为task和Executor是绑定的,如果某个Executor执行过慢或者故障,将会导致整个集群的性能会受限于这个故障节点的执行速度(所谓木桶的短板效应)所以MPP架构的最大缺陷就是——短板效应。
另一点,集群中的节点越多,则某个节点出现问题的概率越大,而一旦有节点出现问题,对于MPP架构来说,将导致整个集群性能受限,所以一般实际生产中MPP架构的集群节点不易过多。
(7)批处理和MPP举例:
举个例子来说下两种架构的数据落盘:要实现两个大表的join操作,对于批处理而言,如Spark将会写磁盘三次(第一次写入:表1根据
join key进行shuffle;第二次写入:表2根据join key进行shuffle;第三次写入:Hash表写入磁盘),而MPP只需要一次写入(Hash表写入),这是因为MPP将mapper和reducer同时运行,而MapReduce将它们分成有依赖关系的tasks(DAG),而这些task是异步执行的,因此必须通过写入中间数据,共享内存来解决数据的依赖。
(8)批处理架构和MPP架构融合:
两个架构的优势和缺陷都很明显,并且它们有互补关系,目前批处理和MPP也确实正在逐渐走向融合。
三、MPP架构的OLAP引擎
采用MPP架构的OLAP引擎分为两类,一类是自身不存储数据,只负责计算的引擎;一类是自身既存储数据,也负责计算的引擎。
(1)只负责计算,不负责存储的引擎
-
Impala
Apache Impala是采用MPP架构的查询引擎,本身不存储任何数据,直接使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。Impala经常搭配存储引擎Kudu一起提供服务,这么做最大的优势是查询比较快,并且支持数据的Update和Delete。
-
Presto
Presto是一个分布式的采用MPP架构的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP的工具,擅长对海量数据进行复杂的分析;Presto是一个低延迟高并发的内存计算引擎。需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等。
(2)既负责计算,又负责存储的引擎
-
ClickHouse
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。它自包含了存储和计算能力,完全自主实现了高可用,而且支持完整的SQL语法包括JOIN等,技术上有着明显优势。ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。 ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
-
Doris
Doris是百度主导的,根据Google Mesa论文和Impala项目改写的一个大数据分析引擎,Doris可以实现海量存储,线性伸缩、平滑扩容,自动容错、故障转移,高并发,且运维成本低。
-
Druid
Druid是一个开源、分布式、面向列式存储的实时分析数据存储系统。Druid的关键特性如下:
- 亚秒级的OLAP查询分析:采用了列式存储、倒排索引、位图索引等关键技术;
- 在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作;
- 实时流数据分析:Druid提供了实时流数据分析,以及高效实时写入;
- 实时数据在亚秒级内的可视化;
- 丰富的数据分析功能:Druid提供了友好的可视化界面;
- SQL查询语言;
- 高可用性与高可拓展性:
- Druid工作节点功能单一,不相互依赖;
- Druid集群在管理、容错、灾备、扩容都很容易;
-
TiDB
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持OLTP与OLAP的融合型分布式数据库产品。TiDB 兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP 、OLAP 、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
-
Greenplum
Greenplum 是在开源的 PostgreSQL 的基础上采用了MPP架构的性能非常强大的关系型分布式数据库。为了兼容Hadoop生态,又推出了HAWQ,分析引擎保留了Greenplum的高性能引擎,下层存储不再采用本地硬盘而改用HDFS,规避本地硬盘可靠性差的问题,同时融入Hadoop生态。
(3)常用的引擎对比
一张图总结下常用的OLAP引擎对比:
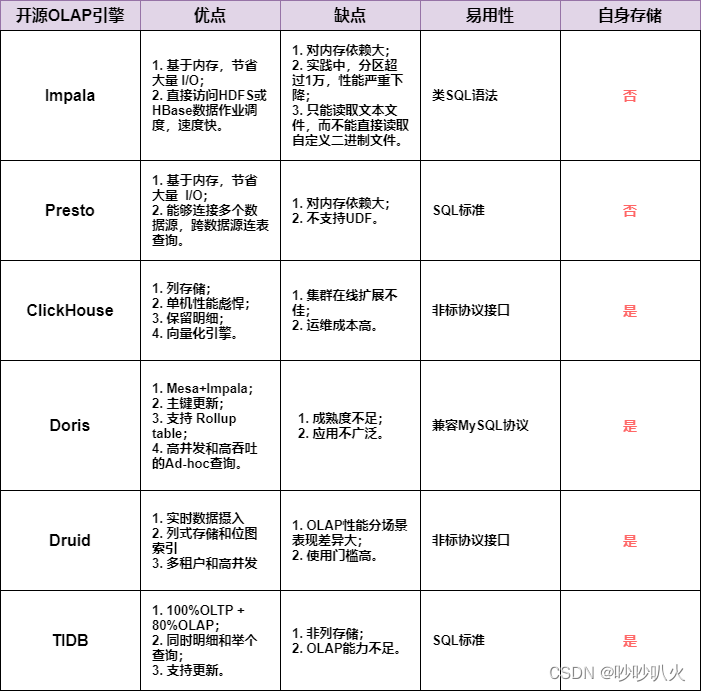
参考文章:
ClickHouse、Doris、 Impala等MPP架构详解
这篇关于MPP数据架构设计的缺点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







