本文主要是介绍MySQL Geometry的使用 —— 任意多边形范围搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
地图相关服务选择的是四维图新
本文记录的是,地图上任意多边形搜索,后端逻辑和SQL(后端),前端相关接口服务可看 MineMap for 2D
地图上任意多边形搜索
- 一、搜索效果
- 二、搜索处理逻辑
- 三、SQL
- 四、Java代码中部分工具类
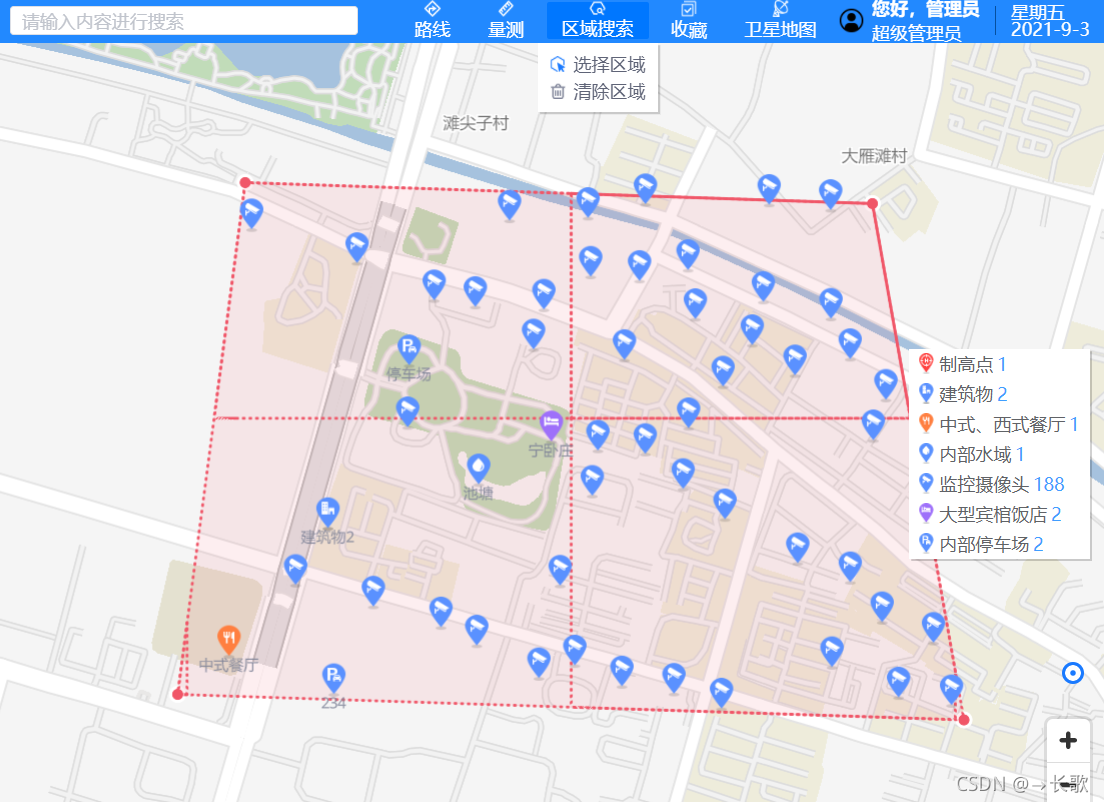
一、搜索效果
自定义选择多边形,搜索出范围内的数据
二、搜索处理逻辑
- 前端调用地图服务接口,获得多边形的点坐标数据,数据例如:[1 1,2 2,3 3,4 4,1 1]
- 后端获得范围坐标数据,同时取得范围坐标的2个极点(坐标最大最小,可先通过Double类型的经纬度大小判断,将搜索范围缩小),使用
Geometry包含函数ST_CONTAINS(),获得符合函数坐标的数据 - 将搜索结果返给前端
三、SQL
假设点坐标 (103,35)、(104,36)为多边形点坐标极点,即所有符合要求范围内的数据,必定在极点之内
select m.name, ST_AsGeoJSON(m.geometry) as geometry
FROM mapdata m
WHERE jd < 104 and jd > 103 and wd < 36 and wd > 35and ST_CONTAINS(ST_POLYGONFROMTEXT('POLYGON(103 35,104 35,104 36,103 36,103 35)'),m.geometry)
四、Java代码中部分工具类
String ssfwStr= net.sf.json.getJSONArray("搜索范围坐标,json格式");
List<List<Double>> maxPolygon = new getMaxPolygonDate().getMaxPolygonByJsonObject(ssfwStr)这篇关于MySQL Geometry的使用 —— 任意多边形范围搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






