本文主要是介绍【Transformer论文】简单并不容易:TextVQA 和 TextCaps 的简单强基线,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 文献题目:Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps
摘要
- OCR(光学字符识别)工具可以识别的日常场景中出现的文本包含重要信息,例如街道名称、产品品牌和价格。两项任务——基于文本的视觉问答和基于文本的图像字幕,以及来自现有视觉语言应用程序的文本扩展,正在迅速流行起来。为了解决这些问题,正在使用许多复杂的多模态编码框架(例如异构图结构)。在本文中,我们认为一个简单的注意力机制可以在没有任何花里胡哨的情况下完成相同甚至更好的工作。在这种机制下,我们简单地将 OCR 标记特征拆分为单独的视觉和语言注意分支,并将它们发送到流行的 Transformer 解码器以生成答案或标题。令人惊讶的是,我们发现这个简单的基线模型相当强大——它在两个流行的基准测试、TextVQA 和 ST VQA 的所有三个任务上始终优于最先进的 (SOTA) 模型,尽管这些 SOTA 模型使用了更多复杂的编码机制。将其转移到基于文本的图像字幕,我们还超越了 TextCaps Challenge 2020 的获胜者。我们希望这项工作能够为这两个与 OCR 文本相关的应用程序设置新的基线,并激发对多模态编码器设计的新思维。
引言
- 自动回答问题或生成需要场景文本理解和推理的图像描述在辅助驾驶和在线购物等商业应用中具有广阔的前景。配备这些能力的模型可以帮助司机决定到下一条街道的距离,或者帮助客户获得有关产品的更多详细信息。最近引入了两种专注于图像中文本的任务,即基于文本的视觉问题回答 (TextVQA) (Singh et al 2019; Biten et al 2019) 和基于文本的图像字幕 (TextCaps) (Sidorov)等人,2020)。例如,在图 1 中,模型需要通过阅读和推理文本“tellus mater inc”来回答问题或生成描述。在图像中。这两项任务对当前的 VQA 或图像字幕模型提出了挑战,因为它们明确需要了解一种新的模式——光学字符识别 (OCR)。模型必须有效地利用与文本相关的特征来解决这些问题。

- 图 1:TextVQA 和 TextCaps 任务的示例。 答案和描述由我们的模型生成。 我们的简单基线能够阅读文本并回答相关问题。 此外,它还可以观察图像并生成嵌入文本的描述。
- 对于 TextVQA 任务,当前最先进的模型 M4C(Hu et al 2019)在联合嵌入空间上处理所有模态(问题、视觉对象和 OCR 标记)。 虽然这种同构方法易于实现、训练速度快并且取得了很大进展,但它认为文本和视觉对象对这个问题的贡献是不分青红皂白的,并且将文本特征作为一个整体来使用。 对于 TextCaps 问题,唯一的区别是它只有两种形式:视觉对象和 OCR 标记。 然而,这些限制仍然存在。
- 其他一些工作提出了更复杂的结构来编码和融合该任务的多模态特征,即问题、OCR 标记和图像。 例如,SMA (Gao et al. 2020b) 使用异构图对图像中的对象-对象、对象-文本和文本-文本关系进行编码,然后设计一个图注意力网络对其进行推理。 MM-GNN (Gao et al. 2020c) 将图像表示为三个图,并引入了三个聚合器来引导消息从一个图传递到另一个图。
- 在本文中,我们使用 vanilla香草注意机制来融合成对模式。在这种机制下,我们进一步使用更合理的方法来利用文本特征,从而获得更高的性能,即将文本特征分成两个功能不同的部分,即流入相应注意力分支的语言部分和视觉部分。然后将编码的特征发送到常用的基于 Transformer 的解码器以生成答案或标题。与上述 M4C 模型(如图 2a 所示)将每种模态的每个实例都放入变换器层相比,我们的模型(如图 2d 所示)首先使用三个注意力块来过滤不相关或冗余的特征,并将它们单独聚合成六个 -功能载体。与 M4C 中的数百个特征向量相比,这六个向量消耗的计算量要少得多。此外,将文本特征分组为视觉和语言部分更合理。与基于图的多模态编码器如 MM-GNN(图 2b)和 SMA(图 2c)相比,我们的基线在设计上非常简单,并且大大降低了空间和时间复杂度。
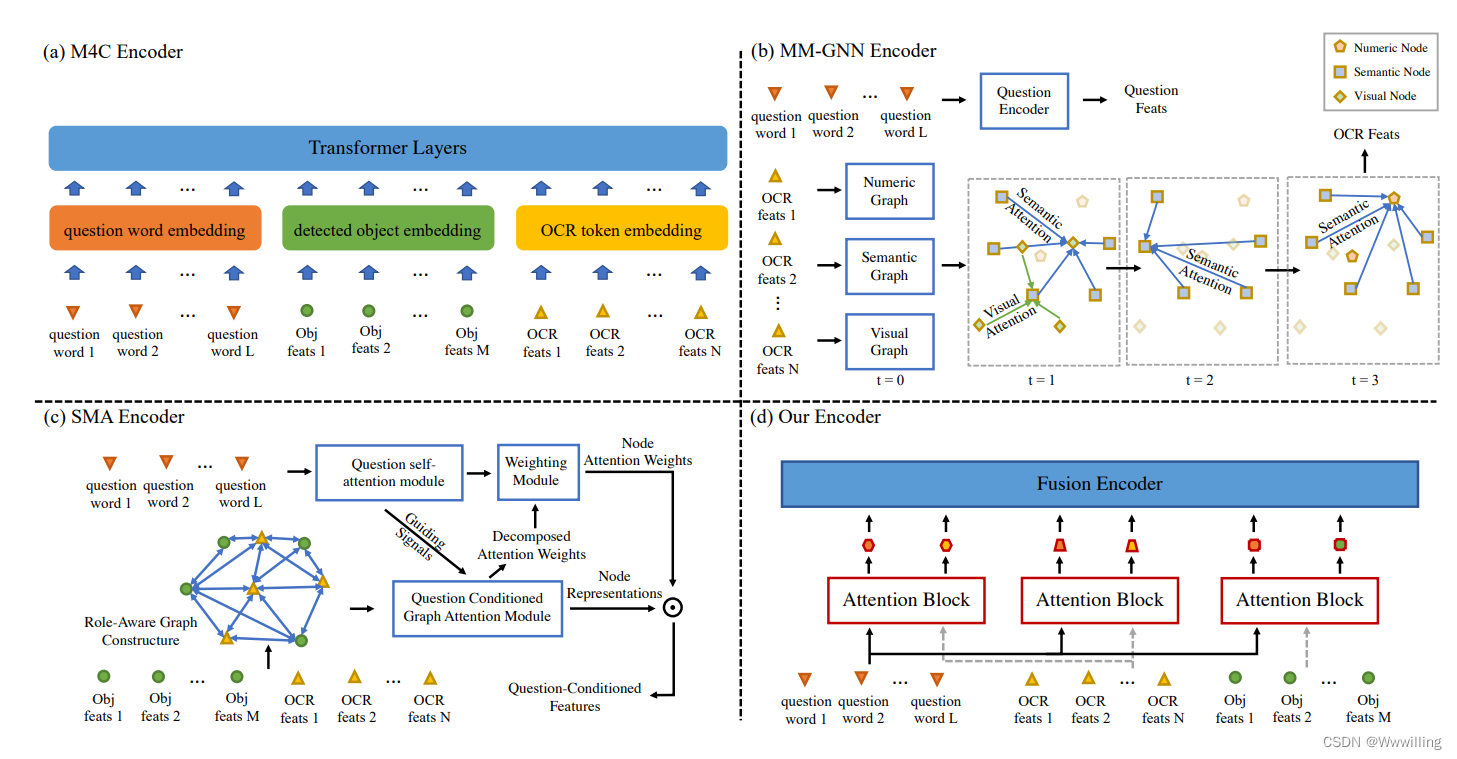
- 图 2:不同型号的编码器。 (a) TextVQA 任务上当前最先进的模型 M4C 将所有模态的每个特征向量不加选择地转发到转换器层,这会消耗大量计算。 (b) MM-GNN 手工制作三个图来表示图像,并逐步应用三个聚合器在图之间传递消息。 © SMA 引入异构图并考虑对象-对象、对象-文本和文本-文本关系,然后使用图注意力网络对它们进行推理。 (d) 我们的基线使用三个普通注意力块来突出最相关的特征,并将它们组合成六个独立功能的向量,然后将其发送到基于转换器的融合编码器中。 六个向量的参数相当少,节省了计算量。
- 此外,我们第一次提出这样一个问题:与其他模态(对象和场景等视觉内容)相比,OCR 在多大程度上有助于 TextVQA 的最终性能? 观察到一个有趣的现象,即 OCR 在这个特殊问题中几乎起着关键作用,而视觉内容仅作为辅助因素。 一个不使用视觉内容的强大模型超越了当前最先进的模型,展示了所提出的成对融合机制的力量和文本的主要作用。
- 为了证明我们提出的简单基线模型的有效性,我们在 TextVQA (Singh et al 2019) 和 TextCaps (Sidorov et al 2020) 任务上对其进行了测试。 对于 TextVQA,我们在 TextVQA 数据集和 ST-VQA 的所有三个任务上都优于最先进的 (SOTA),并且在两个排行榜上均排名第一。 更重要的是,所有比较的 SOTA 模型都使用与我们相似的 Transformer 解码器,但编码机制要复杂得多。 对于 TextCaps,我们超越了 TextCaps Challenge 2020 的获胜者,现在在排行榜上排名第一。
- 总的来说,这项工作的主要贡献是为基于文本的视觉和语言研究提供了一个简单但相当强大的基线。 这可能是 TextVQA 和 TextCaps 的新基线(主干)模型。 更重要的是,我们希望这项工作能够激发多模态编码器设计的新思维——简单并不容易。
相关工作
- 基于文本的视觉问答。 VQA(Antol et al 2015;Johnson et al 2017;Kahou et al 2018;Wang et al 2018)近年来发展迅速。一项新任务——TextVQA 更进一步,旨在理解和推理图像中的场景文本。模型需要先阅读文本,然后在自然的日常情境中回答相关问题。同时引入了两个数据集 TextVQA (Singh et al 2019) 和 ST-VQA (Biten et al 2019) 来衡量该领域的进展。为了解决这个问题,还提出了各种方法。 LoRRA 是 TextVQA 中的基线模型,它使用自下而上和自上而下 (Anderson et al 2018) 对视觉对象和文本的注意来从词汇表或固定索引 OCR 中选择答案。 M4C (Hu et al 2019) 配备了 avanilla 转换器解码器以迭代地生成答案和一个灵活的指针网络,以在一个解码步骤中指向最多可能的 OCR 令牌。 MM-GNN (Gao et al 2020c) 设计了三个图的表示,并引入了三个聚合器来更新问题回答的消息传递。
- 基于文本的图像字幕。 图像字幕挑战模型以根据图像中的内容自动生成自然语言描述。 现有的数据集,例如 COCO Captions (Chen et al 2015) 和 Flickr30k (Young et al 2014),更多地关注视觉对象。 为了增强图像上下文中的文本理解,提出了一个名为 TextCaps (Sidorov et al 2020) 的新数据集。 它需要一个模型来阅读和推理文本并生成连贯的描述。 TextCaps 中的基线模型对上述 M4C 进行了轻微修改,直接删除了问题输入。
- 生成变压器解码器。 为了解决这两个基于文本的任务中的答案通常由多个单词连接的问题,我们在答案模块中使用了transformer (Devlin et al 2019)解码器的结构。 在之前的工作之后,我们还使用生成式变压器解码器进行公平比较。
方法
- 给定三种模式(问题、OCR 标记、视觉对象),我们模型的第一步是通过将特征投影到相同的维度来准备特征。 然后我们描述了用于特征总和的注意力块的制定。 将块堆叠在一起会产生用于下游任务的编码器。 使用编码器输出生成答案中的第一个单词,然后我们使用迭代解码器来预测其余单词。 整个过程如图 3 所示。当转移到 TextCaps 时,我们只进行最小的修改,这将在 3.3 节中详细说明。
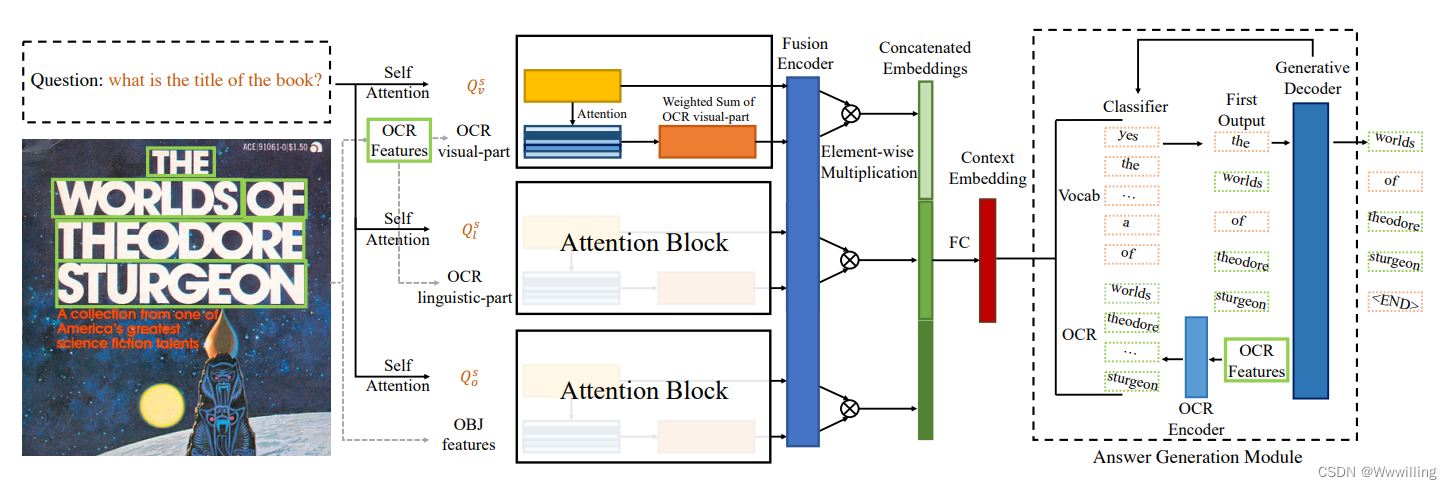
- 图 3:TextVQA 的简单基线模型。 给定一个图像和一个问题,我们准备了三个特征(OCR 视觉部分、OCR 语言部分和对象特征)和三个问题自注意力输出。 这六个序列被放入注意力块并融合成六个向量,我们在此基础上计算元素乘积 2 以 2 以获得连接的嵌入。 编码器输出预测第一个单词,其余答案由迭代解码器产生。
- 符号 在本文的其余部分,所有 W W W 都是学习的线性变换,用不同的符号表示相关参数,例如 KaTeX parse error: Expected '}', got 'EOF' at end of input: W_{fr。 L N LN LN 是层归一化(Ba、Kiros 和 Hinton 2016)。 ◦ ◦ ◦ 表示逐元素乘积。
功能准备
- 问题特征。 对于 L L L 个单词的问题,我们首先使用三层 BERT (Devlin et al. 2019) 模型将其嵌入到 Q = { q i } i = 1 L Q = \{q_i\} ^L_{i=1} Q={qi}i=1L。 此 BERT 模型在训练期间进行了微调。
- OCR 功能。 在基于文本的 VQA 和图像字幕问题中,文本至关重要。 简单地将文本的每个特征聚集在一起是不够有效的。 当面对一堆 OCR 时,人类识别系统倾向于使用两种互补的方法来选择后续的单词,或者通过寻找看起来相似且空间上接近的单词,或者选择在语言含义上连贯的单词。 为了这个直观的目的,我们将 N 个 OCR 标记的特征分成两部分:视觉和语言。
-
- OCR 视觉部分。 视觉特征是由外观特征和空间特征组合而成的,因为它们显示了眼睛所捕捉到的东西,而不需要进一步处理自然语言系统。 从这部分,模型可以获取文字字体、颜色和背景等视觉信息。 这两个是由现成的 Faster R-CNN (Ren et al 2015) 检测器提取的。
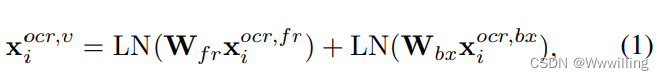
- OCR 视觉部分。 视觉特征是由外观特征和空间特征组合而成的,因为它们显示了眼睛所捕捉到的东西,而不需要进一步处理自然语言系统。 从这部分,模型可以获取文字字体、颜色和背景等视觉信息。 这两个是由现成的 Faster R-CNN (Ren et al 2015) 检测器提取的。
- 其中 x i o c r , f r {x_i}^ {ocr,fr} xiocr,fr 是从 Faster R-CNN 检测器的 fc6 层提取的外观特征。 fc7 权重根据我们的任务进行了微调。 x i o c r , b x {x_i}^ {ocr,bx} xiocr,bx是边界框特征,格式为 [ x t l , y t l , x b r , y b r ] [x_{tl}, y_{tl}, x_{br}, y_{br}] [xtl,ytl,xbr,ybr],其中 t l tl tl 和 b r br br 分别表示左上角和右下角坐标。
-
- OCR 语言部分。 语言特征由 1) FastText 特征 x i o c r , f t {x_i}^ {ocr,ft} xiocr,ft和 2) 字符级 Pyramidal Histogram of Characters (PHOC) (Almazan et al. 2014) 特征 x i o c r , p h {x_i}^ {ocr,ph} xiocr,ph 组成 它们包含与自然语言相关的信息。
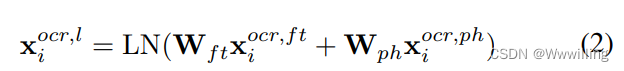
- OCR 语言部分。 语言特征由 1) FastText 特征 x i o c r , f t {x_i}^ {ocr,ft} xiocr,ft和 2) 字符级 Pyramidal Histogram of Characters (PHOC) (Almazan et al. 2014) 特征 x i o c r , p h {x_i}^ {ocr,ph} xiocr,ph 组成 它们包含与自然语言相关的信息。
-
- OCR 附加功能。 在我们用于将 OCR 识别为 kens 的 SBD-Trans (Liu et al 2019; Wang et al 2019) 中,特定文本区域中的整体表示本身就是视觉特征,然而,它们被用于语言词分类目的 . 因此,它们涵盖了 OCR 令牌的视觉和语言上下文,因此我们从该网络中引入了 Recog-CNN 特征 x i o c r , r g {x_i}^ {ocr,rg} xiocr,rg 以丰富文本特征。
- 最后,将 Recog-CNN 特征同时添加到 OCR 视觉和语言部分。
- 视觉特征。 在基于文本的任务中,图像中的视觉内容可用于辅助推理过程中的文本信息。 为了证明我们的简单注意力块具有使用各种形式的视觉特征的能力,我们采用基于网格的全局特征或基于区域的对象特征。
-
- 全局特征。 我们从在 ImageNet 上预训练的 ResNet-152 (He et al. 2016) 模型获得图像全局特征 x i g l o b {x_i}^{glob} xiglob,通过平均池化来自 res-5c 块的 2048D 特征,为一张图像产生 14 × 14 × 2048 特征 。为了与其他特征保持一致,我们将特征调整为 196 × 2048,共 196 个均匀切割的网格。
- 全局特征。 我们从在 ImageNet 上预训练的 ResNet-152 (He et al. 2016) 模型获得图像全局特征 x i g l o b {x_i}^{glob} xiglob,通过平均池化来自 res-5c 块的 2048D 特征,为一张图像产生 14 × 14 × 2048 特征 。为了与其他特征保持一致,我们将特征调整为 196 × 2048,共 196 个均匀切割的网格。
- 2)对象特征。 基于区域的对象特征是从与 OCR 特征部分中提到的相同的 Faster F-CNN 模型中提取的。
- 其中 x i o b j , f r {x_i}^{obj,fr} xiobj,fr是外观特征, x i o b j , b x {x_i}^{obj,bx} xiobj,bx是边界框特征。
注意力块作为特征总结
- 在跨越计算机视觉和自然语言处理领域的任务中,模态融合非常重要。 将它们视为联合嵌入空间中的同质实体可能很容易实现,但是并未针对特定问题进行仔细定制。 此外,大型模型中所有实体(例如 Transformer)的许多参数消耗大量计算。 为了在进入大型融合层之前掌握模态之间的交互以获得最大收益并过滤掉不相关或冗余的特征,我们使用一个简单的注意力块来输入两个实体序列并输出两个处理后的向量,如图 3 中的注意力块。
- 这两个实体序列可能是我们想要的任何序列。 对于 TextVQA 问题,问题是实时变化的,并在最终答案中起主导作用。 问题的设计需要仔细考虑,它的存在应该在整个过程中发挥作用。 例如,这里我们使用问题作为注意力块中查询的一个输入。 疑问词序列在转发到注意块之前经过一个自我注意过程。
- 首先我们将问题词序列 Q = { q i } i = 1 L Q = \{q_i\}^L_{i=1} Q={qi}i=1L 通过一个全连接的前馈网络,该网络由两个线性变换(或两个以 1 为核大小的卷积)和它们之间的一个 ReLU 激活函数组成。
- softmax 层用于计算问题中每个单词的注意力。
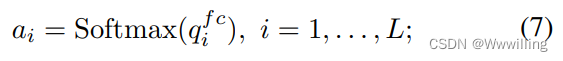
- 这被称为自我注意,这些权重与原始问题嵌入相乘以获得词嵌入的加权和。
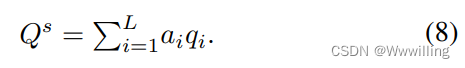
- 如果我们有几个单独的实体要与问题结合,则在具有独立参数的同一个问题上执行相应数量的并行自注意过程。 例如,我们可以分别得到 OCR 视觉部分、OCR 语言部分和对象区域的 Q v s Q^s_v Qvs、 Q l s Q^s_l Qls 和 Q o s Q^s_o Qos。
- 然后将 Q s Q^s Qs 用作相应特征的查询。 我们在 Q s Q^s Qs 的指导下计算注意力权重,然后将其放入 softmax 层。 最后将权重与原始查询特征相乘,得到过滤向量。 这里我们以 Q v s Q^s_v Qvs 和 x i o c r , v x_i^{ocr,v} xiocr,v 对为例:

- 其中 g o c r , v g^{ocr,v} gocr,v 是注意力块的输出。 类似地,我们可以得到 g o c r , l g^{ocr,l} gocr,l 表示 OCR 语言总结特征, g o b j g^{obj} gobj 表示对象总结特征。
- 与 M4C 将每个问题发送到 tokens、OCR tokens和对象到转换器特征融合层不同,这里我们只有 6 个特征向量( Q v s Q^s_v Qvs、 Q l s Q^s_l Qls、 Q o s Q^s_o Qos、 g o c r , v g^{ocr,v} gocr,v、 g o c r , l g^{ocr,l} gocr,l 和 g o b j g^{obj} gobj)被发送到以下过程。 考虑到变压器是一个参数繁重的网络,这大大降低了计算复杂度和负担。
堆叠块编码器
- 第 3.2 节中的注意力块可以堆叠在一起作为编码器,为下游任务生成组合嵌入。
- TextVQA 基线模型。如上述模块所示,问题通过自我注意发送到输出 Q v s Q^s_v Qvs、 Q l s Q^s_l Qls、 Q o s Q^s_o Qos。图像中的 OCR 特征分为视觉和语言部分,即 x o c r , v x^{ocr,v} xocr,v 和 x o c r , l x^{ocr,l} xocr,l。我们还有对象特征 x o b j x^{obj} xobj 。六个序列被放入三个注意块中,我们得到六个 768D 向量,然后将其转发到融合编码器中。图 3 中的融合编码器、OCR 编码器和生成解码器处于相同的变压器模型中,但承担不同的角色。在融合编码器处理之后,六个向量以成对的方式进行元素相乘,以获得连接在一起的对应嵌入。然后我们使用全连接层将连接的嵌入转换为具有适当维度的上下文嵌入,在此基础上我们生成第一个答案输出。给定第一个答案词,然后使用生成解码器来选择答案的其余部分,这将在第 3.4 节和补充材料中详细说明。
- TextCaps 基线模型。 由于 TextCaps 中没有问题,我们使用对象来引导 OCR 视觉和语言部分,并使用 OCR 来引导对象特征。 从技术上讲,我们只需将问题词序列替换为 OCR 标记序列或对象提议特征序列。 其他设置与 TextVQA 相同。 图 4 说明了我们的 Textcaps 基线模型。 轻松转移到另一个任务证明了我们方法的泛化能力和简单性。
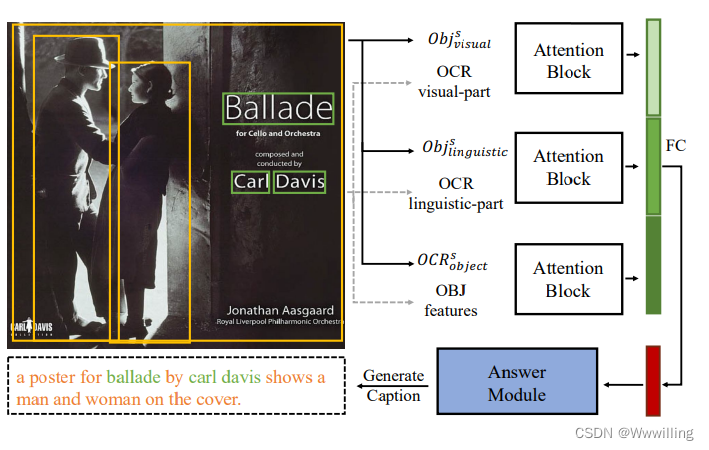
- 图4:TextCaps基线模型。它具有与TextVQA基线模型相同的结构。
答案生成模块
- 为了回答问题或生成标题,我们使用基于 Transformer 的生成解码器。 它将来自上述编码器的“上下文嵌入”作为输入,并选择答案的第一个单词。 基于第一个输出单词,我们使用解码器根据评分函数从预先构建的词汇表或从给定图像中提取的候选 OCR 标记中找到下一个单词标记。
- 训练损失。 考虑到答案可能来自两个来源,我们使用多标签二元交叉熵(bce)损失:
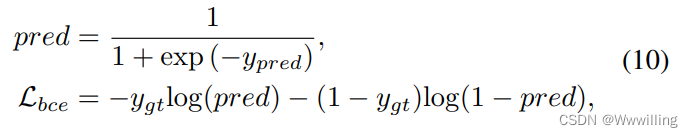
- 其中 y p r e d y_{pred} ypred 是预测, y g t y_{gt} ygt 是真实目标。
- 额外的训练损失。 然而,在某些情况下,由于阅读能力有缺陷(OCR),模型正确地选择了与我们预期的略有不同的单词。 为了利用这些预测,我们引入了一种新的策略梯度损失作为受强化学习启发的辅助任务。 在这个任务中,奖励越大越好。 我们采用平均归一化 Levenshtein Similarity (ANLS) 度量作为奖励,衡量预测答案和真实答案之间的字符相似度。
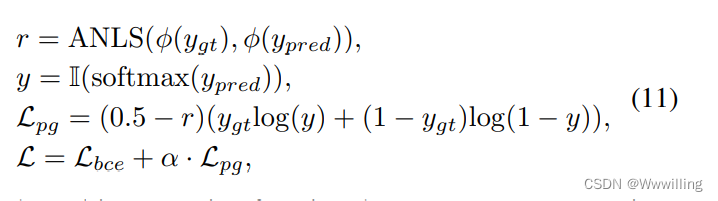
- 其中 φ φ φ 是一个映射函数,它返回给定预测分数的句子(例如 , y p r e d y_{pred} ypred), A N L S ( ⋅ ) ANLS(·) ANLS(⋅) 用于计算两个短语之间的相似度, I I I 是选择最大概率元素的指示函数。 额外的训练损失是 L b c e L_{bce} Lbce 和 L p g L_{pg} Lpg 的加权和,其中 α α α 是控制 L p g L_{pg} Lpg 权衡的超参数。 在引入策略梯度损失后,我们的模型能够学习细粒度的字符组合以及语言信息。 我们只在 ST-VQA 数据集上应用这个额外的损失,这带来了大约 1% 的改进。
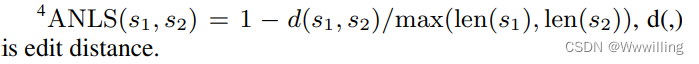
实验
- 对两类任务进行了广泛的实验:TextVQA 和 TextCap。 对于 TextVQA,我们在 TextVQA 数据集和 ST-VQA 的所有三个任务上设置了新的 state-of-the-art。 对于 TextCaps,我们超过了 2020 年 TextCaps 挑战冠军。 请参阅下面的更多实验细节。
实施细节
- 这组方法构建在 PyTorch 之上。 我们使用 Adam 作为优化器。 TextVQA 和 TexCaps 的学习率设置为 1e-4。 对于 TextVQA,我们在 14,000 和 15,000 次迭代中将学习率乘以 0.1,总共 24,000 次迭代。 对于 TextCaps,乘法是在 3, 000 和 4, 000 次迭代中完成的,总共 12, 000 次迭代。 我们将问题的最大长度设置为 L = 20 L = 20 L=20。我们最多识别 N = 50 N = 50 N=50 个 OCR 标记并检测最多 M = 100 M = 100 M=100 个对象。 解码步骤的最大数量设置为 12。我们模型中的 Transformer 层使用 12 个注意力头。 其他超参数与 BERT-BASE 相同(Devlin et al. 2019)。 我们在 TextVQA 和 ST-VQA 的三个任务上使用相同的模型,只是答案词汇不同,两者的大小都是固定的 5000。
TextVQA 数据集的消融研究
- TextVQA (Singh et al 2019) 是一个流行的基准数据集,用于测试场景文本理解和推理能力,其中包含 28、408 张图像的 45、336 个问题。 涉及查询时间、名称、品牌、作者等的各种问题以及可能旋转、随意或部分遮挡的动态 OCR 令牌使其成为一项具有挑战性的任务。
- 我们首先进行了一个只构建一个块的实验,一个问题的自注意力输出指导整个文本特征集作为比较。 这是表 1 中的单块模型,它的性能不如最先进的模型。 为了研究在不使用基于视觉网格或基于区域的特征的情况下文本特征的性能如何,我们构建了一个两块模型。 给定两类 OCR 特征——视觉和语言,我们发现我们的简单模型已经能够很好地解决 TextVQA 问题。 第 1 行和第 2 行清楚地说明了将文本特征分为两组的有效性(差异为 1.77%)。
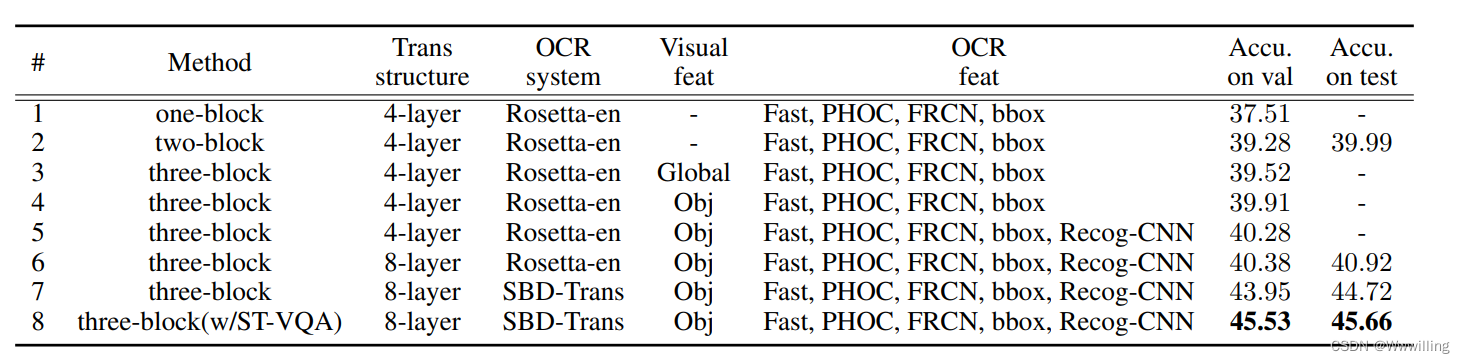
- 表 1:我们通过测试注意力块的数量、视觉对象特征的形式和 OCR 表示的添加来消融我们在 TextVQA 数据集上的模型。
- 在基于视觉内容构建我们的第三个块时,我们可以使用全局特征或对象级特征。 第三块的合并有适度的改进(全局为 0.24%,对象特征为 0.63%)。 从第 4 行到第 5 行,添加了一个新的 Recog-CNN 特征来丰富文本表示,并带来 0.37% 的改进。 我们还使用了更多的转换器层(从 4 到 8),结果提高了 0.1%。 然后我们使用更好的 OCR 系统(尤其是在识别部分)并获得很大的性能提升(从 40.38% 到 43.95%)。
- 定性的例子。 我们在图 5 中展示了四个示例,其中我们的模型显示了以类似于人类的方式真正阅读场景文本的能力,即从左到右然后从上到下。 相比之下,当前最先进的模型 M4C 无法以正确的顺序读取令牌。

- 图 5:我们的基线模型与 M4C 相比的定性示例。 虽然我们的模型可以按照书面语言系统阅读文本,但 M4C 只能以随机和错误的方式选择标记。
与最先进的比较
- TextVQA 数据集。 即使去掉图像中视觉内容的使用,我们的两块模型在测试集上已经超过当前最先进的 M4C 0.98%(表 1 中的第 2 行 VS. 表 2 中的第 4 行) . 使用相同的 OCR 系统,我们的基线模型在 M4C 上进一步提高了 0.98% 的 val 和 1.91% 的测试(表 2 中的第 7 行与第 4 行)。
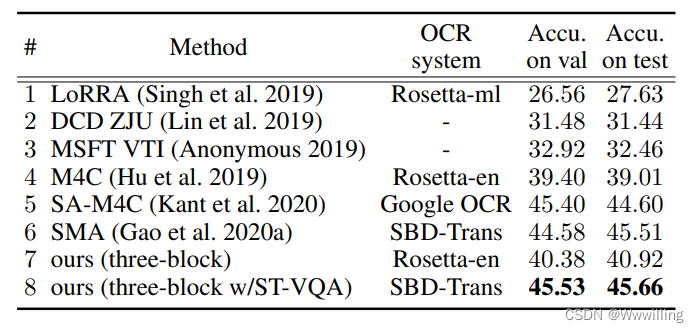
- 表 2:与之前在 TextVQA 数据集上的工作的比较。 我们的模型以极其简单的设计设置了新的最先进技术。
- 与 TextVQA Challenge 2020 的顶级参赛作品相比,我们的基线模型设计明显更简单,尤其是在编码器方面。 M4C 和 SA-M4C 将实体的所有参数放入转换器层并加入大量计算。 SMA 使用异构图来明确考虑不同的节点并计算 5 相邻图上的注意力权重。 我们超越所有这些的模型仅将六个整体向量 2×2 发送到变换器层,这极大地节省了计算量。
- ST-VQA 数据集。 ST-VQA 数据集(Biten et al 2019)是另一个流行的数据集,包含三个任务,难度逐渐增加。 任务 1 为每个图像提供 100 个单词的动态候选字典,而任务 2 为整个数据集提供 30、000 个单词的固定答案字典。 然而,对于任务 3,模型应该在没有额外信息的情况下生成答案。 我们还在 ST-VQA 数据集上评估我们的模型,对所有三个任务使用来自 TextVQA 的相同模型。 在没有任何额外训练数据的情况下,我们的模型在任务 2 和任务 3(表 3 中的第 4 行)上达到了最高水平。 使用 TextVQA 数据集作为额外的训练数据,我们的模型在所有三个任务上都设置了新的最先进技术,并且大大优于当前的方法。
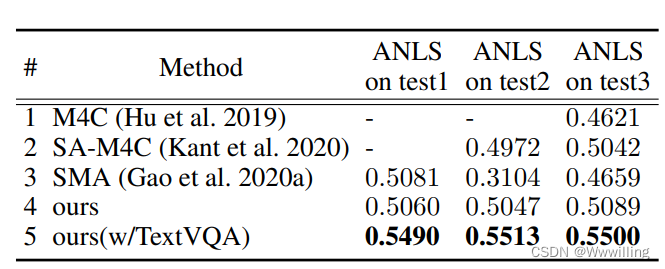
- 表 3:与之前在 ST-VQA 数据集上的工作的比较。 通过 TextVQA 预训练,我们的模型大大优于当前方法。
TextCaps 数据集
- TextCaps 是一个新的数据集,它需要一个模型来读取图像中的文本并根据场景文本理解和推理生成描述。 在 TextCaps 中,自动字幕指标 (BLEU (Papineni et al. 2002)、ME TEOR (Denkowski and Lavie 2014)、ROUGE L (Lin 2004)、SPICE (Anderson et al. 2016) 和 CIDEr (Vedantam, Lawrence Zitnick, and Parikh 2015)) 与人类评估分数进行比较。 所有自动指标都显示出与人类分数的高度相关性,其中 CIDEr 和 ME TEOR 的相关性最高。
- M4C-Captioner 是 TextCaps 中提供的方法,它是在 M4C 模型的基础上修改的,只是简单地去掉了问题输入。 同样,只需将 TextVQA 基线模型中的问题替换为对象或 OCR 序列即可生成我们的 TextCaps 基线模型。 使用完全相同的 OCR 系统、OCR 表示,我们的 Rosetta-en OCR 基线(表 4 上的第 2 行)已经超过了 M4C-Captioner(表 4 上的第 1 行),尤其是在 BLUE-4 和 CIDEr 指标上。 通过将我们的 OCR 系统升级到 SBD Trans 并在我们的编码器-解码器结构中使用 6 层转换器,我们的基线在 BLUE-4 和 CIDEr 指标上进一步超过了 TextCaps Challenge Winner,如表 4 的第 5 行和第 6 行所示。
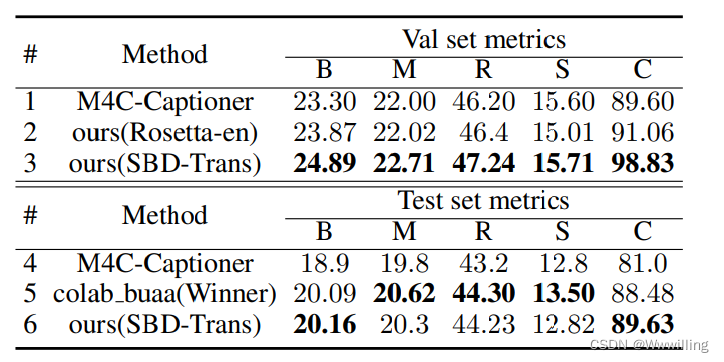
- 表 4:TextCaps 数据集的结果。 (B:BLEU-4;M:ME TEOR;R:ROUGE L;S:SPICE;C:CIDEr
结论
- 在本文中,我们为基于文本的视觉和语言研究提供了一个简单但相当强大的基线。 我们不是通过联合嵌入空间或通过复杂的图结构编码来处理所有模态,而是使用 vanilla attention 机制来融合成对模态。 我们进一步将文本特征分成两个功能不同的部分,即语言部分和视觉部分,它们流入相应的注意力分支。 我们在 TextVQA、ST-VQA 和 TextCaps 上评估我们的简单基线模型,所有这些都导致在公共排行榜上的最佳性能。 这设置了新的最先进技术,我们的模型可能是 TextVQA 和 TextCaps 的新骨干模型。 更重要的是,我们相信这项工作激发了多模态编码器设计的新思维。
算法
- 算法 1 提供了 TextVQA 问题中答案生成过程的伪代码。 TextCaps 问题中的描述生成过程大致相同,只是解码步长 T T T 设置为 30 而不是 12 以获得更长和更具表现力的图像描述。 顺便说一句,问题特征也被 OCR 特征和对象特征所取代,以相互引导。

编码器之间计算复杂度的比较
- 由于我们的模型和 M4C 具有相同的生成解码器,我们仅比较表 5 中的编码器。

- 表 5:两个模型编码器的计算复杂度。 L = 20 是问题的长度; N = 50 是 OCR 令牌的数量; M = 100 是检测到的对象的数量。 为简单起见,这里我们省略了所有向量维度 D。 在我们模型的 Transformer 编码器中,除了六个向量之外,我们还输入了 50 个 OCR 标记来计算答案选择中的点积值。
- 在一个注意块中,主要操作是逐元素乘法和最终矩阵乘法,产生 O ( n ⋅ d ) = 2 n ⋅ d O(n·d) = 2n·d O(n⋅d)=2n⋅d 操作,其中 n n n 是查询特征的数量。 在 Transformer 编码器中,复杂度为 O ( n 2 ⋅ d ) O(n^2·d) O(n2⋅d),其中 n n n 是序列长度, d d d 是表示维度。
其他实验细节
- TextCaps 中的 OCR 和对象自注意。 与 TextVQA 问题中使用 BERT 模型来捕获序列信息的问题自注意力不同,对于 TextCaps 中的 OCR 和对象自注意力,我们使用 LSTM (Hochreiter and Schmidhuber 1997) 层在自我注意计算之前捕获孤立区域的循环特征。
- SBD-Trans 训练数据。 SBD 模型在 60k 数据集上进行了预训练,该数据集由来自 LSVT (Sun et al 2019) 训练集的 30, 000 张图像、来自 MLT 2019 (Nayef et al 2019) 训练集的 10, 000 张图像、来自 ArT 的 5, 603 张图像组成 (Chng et al 2019),以及从一堆数据集中选择的 14、859 张图像 – RCTW-17 (Shi et al 2017)、IC DAR 2013 (Karatzas et al 2013)、ICDAR 2015 (Karatzas et al 2015)、MSRA -TD500 (Yao et al 2012)、COCO Text (Veit et al 2016) 和 USTB-SV1K (Yin et al 2015)。 该模型最终在 MLT 2019 训练集上进行了微调。 强大的基于转换器的网络在以下数据集上进行训练:IIIT 5K-Words(Mishra、Alahari 和 Jawa har 2012)、街景文本(Wang、Babenko 和 Belongie 2011)、ICDAR 2013、ICDAR 2015、Street 查看文本 Perspective (Quy Phan et al 2013)、CUTE80 (Risnumawan et al 2014) 和 ArT。
其他定性示例
- 为了证明我们的模型不仅学习了问题和突出的 OCR tokens 之间固定的表面相关性,我们在数据集中展示了几个图像,其中包含两个不同的问题,我们的模型都正确回答了这些问题,而其他模型(如 M4C)则失败了 ,在图 6 中。TextCaps 示例在图 7 中。
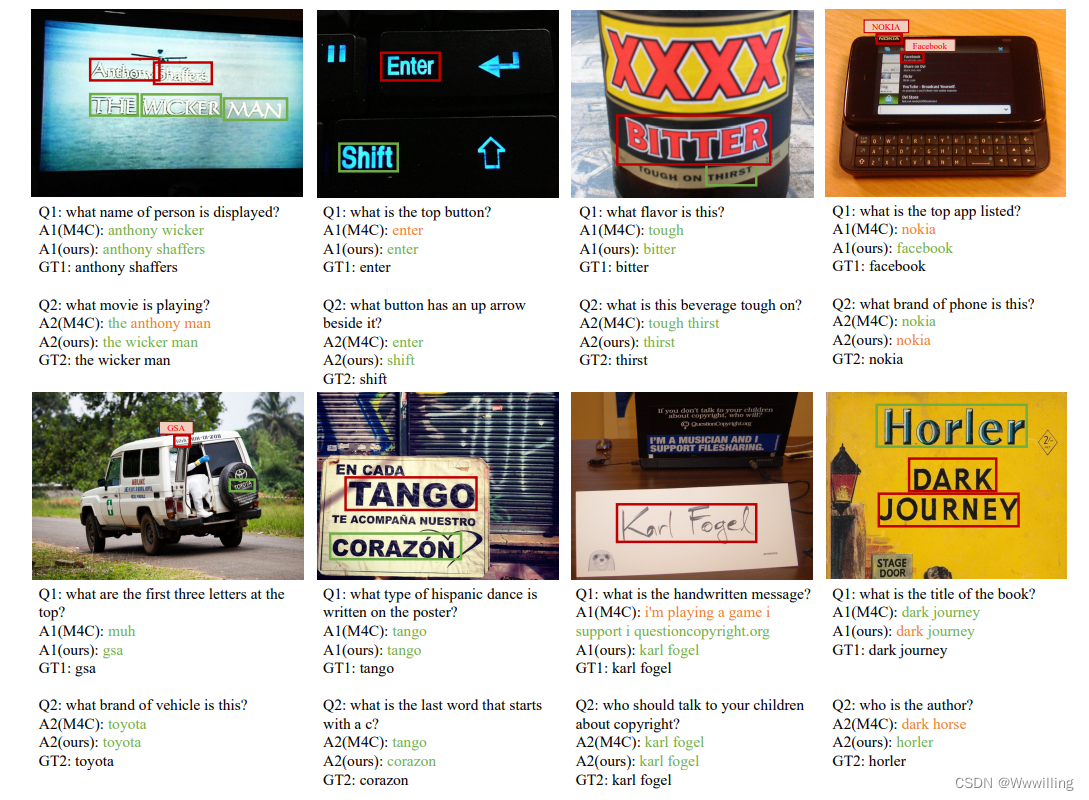
- 图 6:我们在 TextVQA 上的模型的其他定性示例。 给定一张图片和两个问题,我们的模型可以正确回答这两个问题。 “GT”表示真实答案。 绿色单词是 OCR 标记,橙色单词是词汇条目。 整篇论文都使用这种颜色表示。

- 图 7:我们模型在 TextCaps 上的定性示例。
TextVQA上的失败案例
- 我们的模型努力解决的问题可以分为几组。 首先,由于数据集设计不当,需要模型来读取时间、查找单词中的特定字母或读取标尺,例如图 8a)、b) 和 c)。 其次,即使我们的模型给出了合理的答案,它也不在图 8d 所示的真值区域内。 第三,由于 OCR 令牌根本不包括候选答案的阅读能力有缺陷,可能会发生错误,如图 8e) 所示。 第四,难以辨别令牌的颜色,如图 8f) 所示。 最后,当涉及到细微的关系理解时,我们的模型还不够复杂,无法推理,如图 8g) 和 h) 所示。
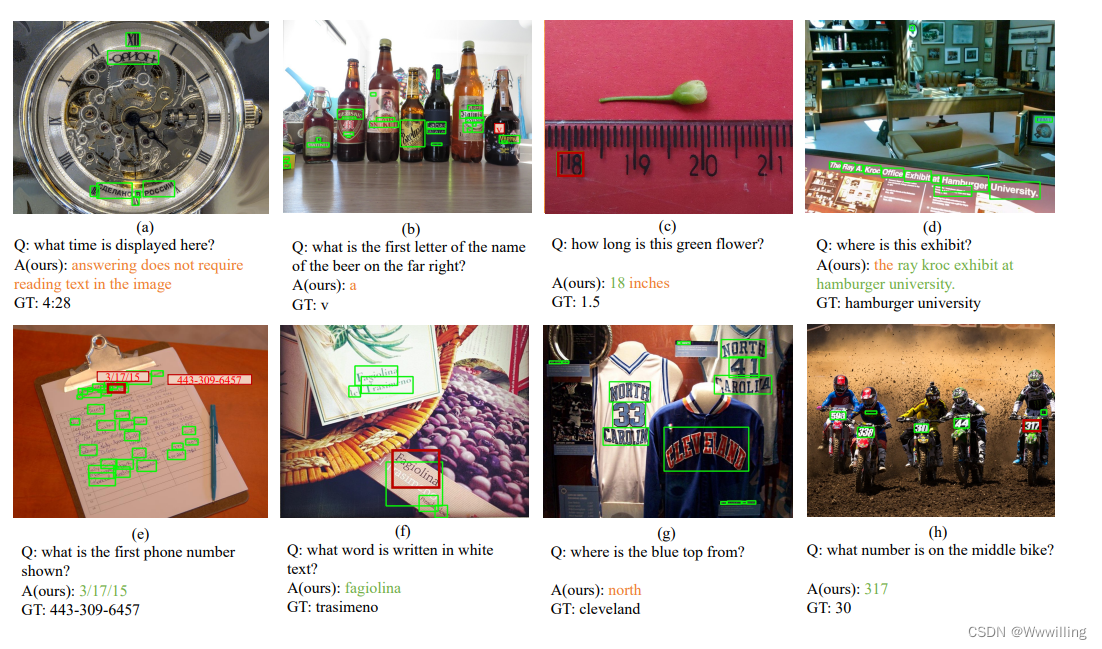
- 图 8:我们的模型在 TextVQA 上失败的示例
这篇关于【Transformer论文】简单并不容易:TextVQA 和 TextCaps 的简单强基线的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






