textvqa专题
【Transformer论文】简单并不容易:TextVQA 和 TextCaps 的简单强基线
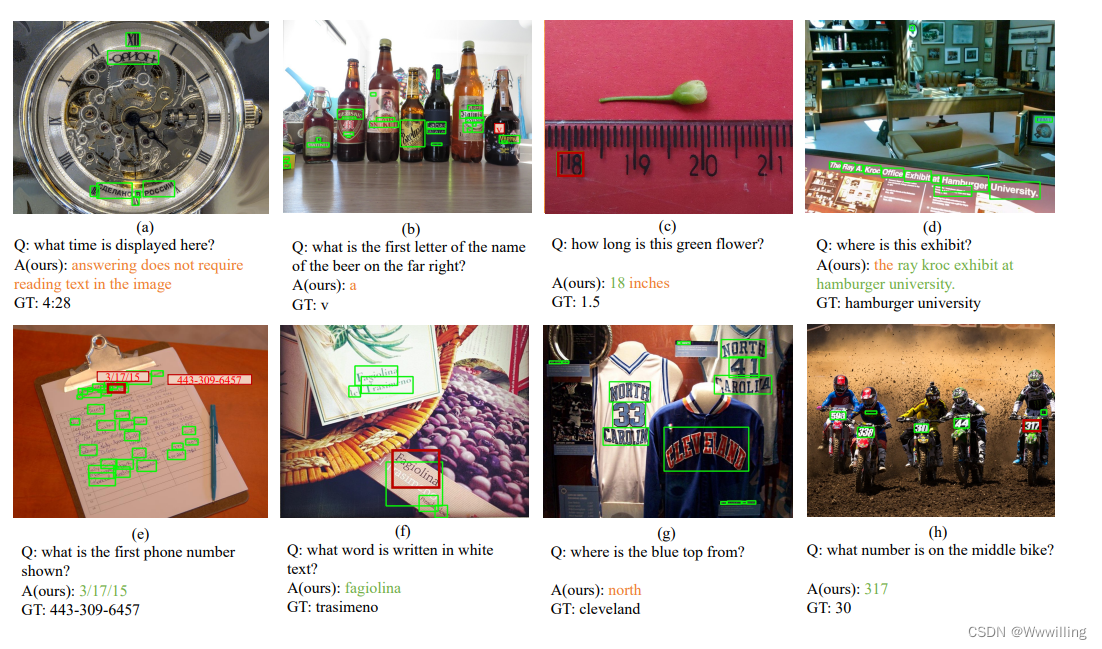
文献题目:Simple is not Easy: A Simple Strong Baseline for TextVQA and TextCaps 摘要 OCR(光学字符识别)工具可以识别的日常场景中出现的文本包含重要信息,例如街道名称、产品品牌和价格。两项任务——基于文本的视觉问答和基于文本的图像字幕,以及来自现有视觉语言应用程序的文本扩展,正在迅速流行起来。为了解决这些问题,正在使用许多

M4C精读:融合多种模态到公共语义空间,使用指针增强多模态变形器来迭代应答TextVQA任务 Iterative Answer Prediction Pointer-Augmented
M4C精读:融合多种模态到公共语义空间,使用指针增强多模态变形器来迭代应答TextVQA任务 Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA 论文点我 Code点我 摘要 许多视觉场景都包含了承载重要信息的文本,因此理解图像中的文本对于后续的推理任务是至关重要的。例