本文主要是介绍Python爬虫实战(基础篇)—14获取【巴黎圣母院新闻网(Notre Dame News)】新闻写入Word(附完整代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 专栏导读
- 背景
- 1、网页分析+找到【Latest News】的URL
- 2、测试请求
- 测试代码如下
- 3、数据清洗+获取【Latest News】中每一个新闻的URL
- 4、获取每一篇新闻
- 获取标题 xpath
- 获取发布时间+作者 xpath
- 获取新闻内容 xpath
- 代码测试成功
- 5、写入Word文档中
- 6、完整代码
- 总结
专栏导读
🔥🔥本文已收录于《Python基础篇爬虫》
🉑🉑本专栏专门
针对于有爬虫基础准备的一套基础教学,轻松掌握Python爬虫,欢迎各位同学订阅,专栏订阅地址:点我直达
🤞🤞此外如果您已工作,如需利用Python解决办公中常见的问题,欢
迎订阅《Python办公自动化》专栏,订阅地址:点我直达
的
🔺🔺此外《Python30天从入门到熟练》专栏已上线,欢迎大家订阅,订阅地址:点我直达
背景
-
我是一个非常喜欢新闻的网友,特别喜欢的新闻网站是【巴黎圣母院新闻网】,我想获取每日的最新新闻,然后再写入Word中,方便我查看
1、网页分析+找到【Latest News】的URL
-
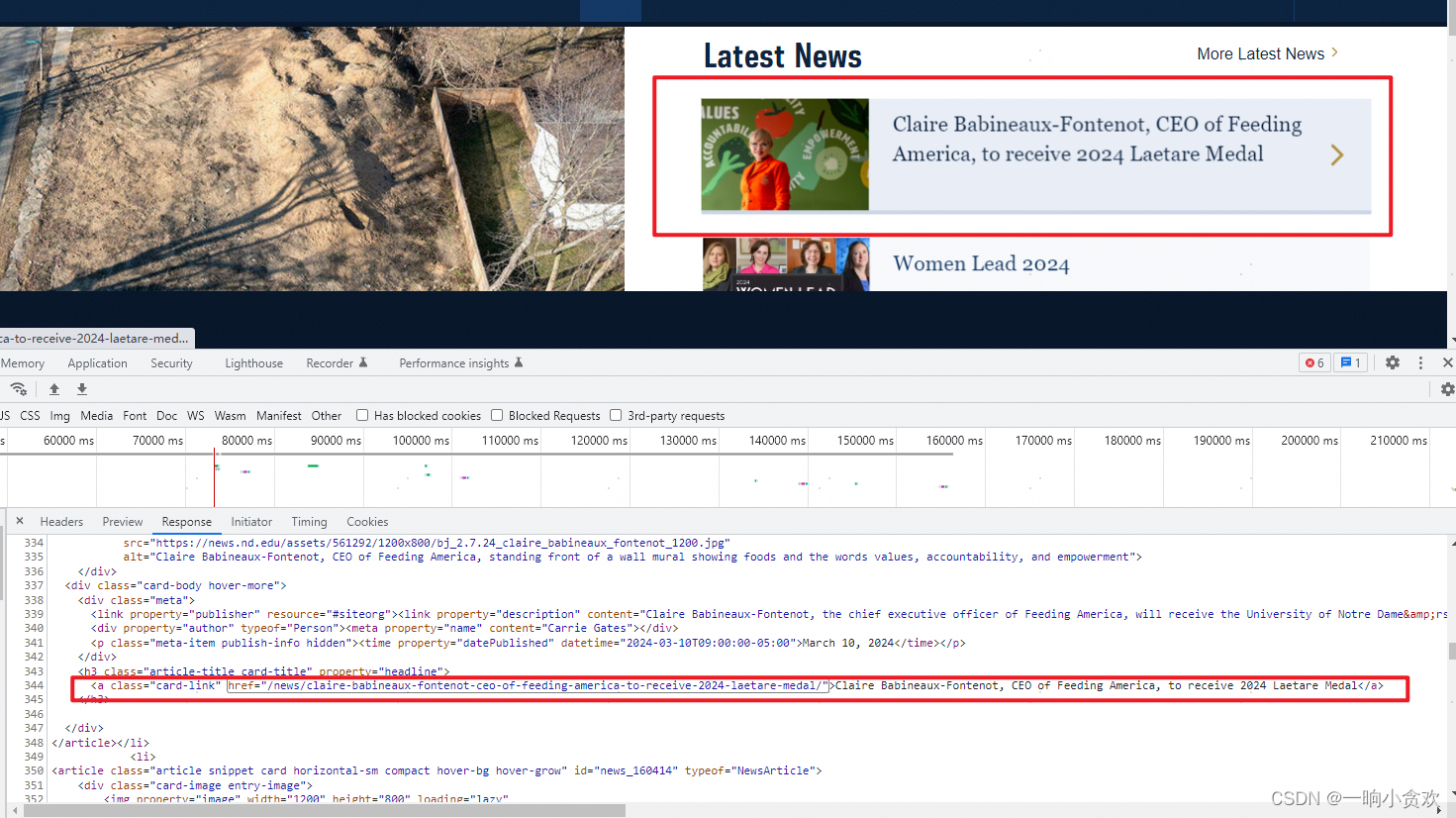
①、首先我们发现请求响应的返回在【Response】中;
-
②、我们发现网页中有【a】标签,存放着文章url链接
-
③、所以我们决定此次爬虫应该是用 lxml+xpath比较合适,说干就干!
-
④、请求方法是【GET】
-
⑤、请求参数是:无
2、测试请求
我们发现测试请求成功!

测试代码如下
# -*- coding: UTF-8 -*-
'''
@Project :巴黎圣母院新闻网(Notre Dame News)
@File :main_.py
@IDE :PyCharm
@Author :一晌小贪欢(278865463@qq.com)
@Date :2024/3/12 10:12
'''
import jsonimport requestsurl = 'https://news.nd.edu/'headers = {'User-Agent'这篇关于Python爬虫实战(基础篇)—14获取【巴黎圣母院新闻网(Notre Dame News)】新闻写入Word(附完整代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




