本文主要是介绍MySQL实战项目:淘宝母婴购物数据可视化分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
前言
一、数据获取
1.母婴信息表:tianchi_mum_baby.csv
2.购物行为表: tianchi_mum_baby_trade_history.csv
二、数据预处理:
1.修改数据类型
2.检查重复数据:
3.检查空格
4.去异常
三.数据分析
1.流量分析
2.类别分析
3.性别分析
总结
前言
母婴用品是淘宝的热门购物类目,随着国家鼓励二胎、三胎政策的推进,会进一步促进了母婴类目商品的销量。与此年轻一代父母的育儿观念也发生了较大的变化,因此中国母婴电商市场发展形态也越来越多样化。随之引起各大母婴品牌更加激烈的争夺,越来越多的母婴品牌管窥到行业潜在的商机,纷纷加入母婴电商,行业竞争越来越激烈。本项目会基于"淘宝母婴购物"数据集进行可视化分析。
一、数据获取
本数据集分析案例来自天池“淘宝母婴购物行为”数据集:淘宝母婴购物数据集_数据集-阿里云天池 ,并根据实际分析需要删除和重命名部分字段。包含两张数据集表:
1.母婴信息表:tianchi_mum_baby.csv
包括如下字段:
| 字段 | 字段说明 | 提取说明 |
|---|---|---|
| user_id | 用户标识 | 抽样和字段脱敏 |
| birthday | 出身日期 | YYYYMMDD,精确到天 |
| gender | 性别 | 0:男孩,1:女孩,2:性别不明 |
部分数据预览:
2.购物行为表: tianchi_mum_baby_trade_history.csv
包括如下字段:
| 字段 | 字段说明 | 提取说明 |
|---|---|---|
| user_id | 用户标识 | 抽样和字段脱敏 |
| auction_id | 交易ID | 字段脱敏 |
| category_1 | 商品一级类目 | 字段脱敏 |
| category_2 | 商品二级类目 | 字段脱敏 |
| buy_mount | 购买数量 | |
| day | 交易时间 | YYYYMMDD,精确到天 |

二、数据预处理:
1.修改数据类型
可以观察到日期均为int类型,为了后续方便,修改为date类型
ALTER TABLE tianchi_mum_babyuserMODIFY birthday DATE;
ALTER TABLE tianchi_mum_baby_trade_historyMODIFY `day` DATE;
2.检查重复数据:
SELECT user_id,COUNT(*) FROM tianchi_mum_babyuser
GROUP BY user_id
HAVING COUNT(*)>1;查询结果为空,未发现重复项。
SELECT user_id ,auction_id,COUNT(*) FROM tianchi_mum_baby_trade_history
GROUP BY user_id,auction_id
HAVING COUNT(*)>1;查询结果为空,未发现重复项。
3.检查空格
SELECT * FROM tianchi_mum_babyuser WHERE user_id IS NULL;SELECT * FROM tianchi_mum_babyuser WHERE birthday IS NULL;SELECT * FROM tianchi_mum_babyuser WHERE gender IS NULL;SELECT * FROM tianchi_mum_baby_trade_history WHERE user_id IS NULL;SELECT * FROM tianchi_mum_baby_trade_history WHERE auction_id IS NULL;SELECT * FROM tianchi_mum_baby_trade_history WHERE category_2 IS NULL;SELECT * FROM tianchi_mum_baby_trade_history WHERE category_1 IS NULL;SELECT * FROM tianchi_mum_baby_trade_history WHERE buy_mount IS NULL;SELECT * FROM tianchi_mum_baby_trade_history WHERE `day` IS NULL;查询结果为空,未发现空值
4.去异常
- 查询最大最小日期,删除这个范围以外的日期
SELECT MAX(`day`),MIN(`day`) FROM tianchi_mum_baby_trade_history;查询结果:最大日期2015-02-05,最小日期2012-07-02
- 删除异常数据
DELETE FROM tianchi_mum_baby_trade_historyWHERE `day` < '2012-07-02'OR `day` > '2015-02-05';-
为了方便分析,过滤掉性别未知的数据
DELETE FROM tianchi_mum_babyuser
WHERE gender = 2;三.数据分析
1.流量分析
年/季度/月/日的商品销量如何?有什么规律
- 年销量
SELECT COUNT(buy_mount),DATE_FORMAT(DAY,'%Y') FROM tianchi_mum_baby_trade_historyGROUP BY DATE_FORMAT(DAY,'%Y')ORDER BYDATE_FORMAT(DAY,'%Y');
在数据预处理章节我们得知,本次抽样数据跨度为2012/07到2015/02,2013、2014为两个完整的年份,趋势应该是逐年递增的
- 季度销量
SELECT COUNT(buy_mount),SUBSTR(`day`,1,4) ,QUARTER(DAY) FROM tianchi_mum_baby_trade_historyGROUP BY SUBSTR(`day`,1,4) ,QUARTER(DAY)ORDER BYSUBSTR(`day`,1,4) ,QUARTER(DAY);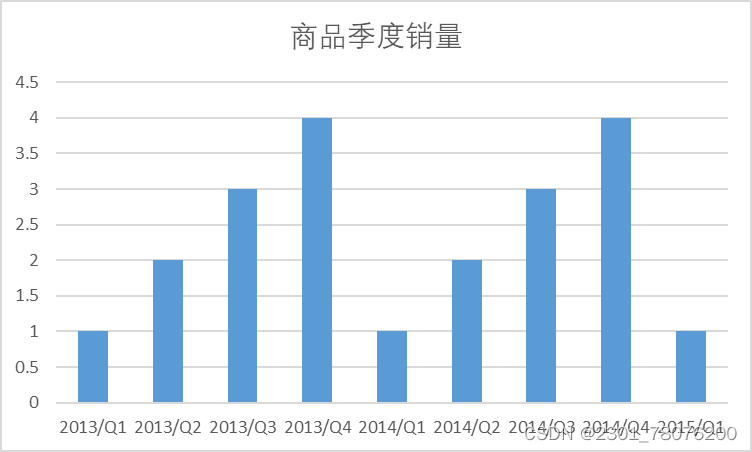
以2013、2014两个完整年为例,一般规律是Q1为全年销量最低的年份、Q4是全年销量最高的年份,猜想一个可能的原因是Q1因为春节假期导致的销量下滑,Q4是因为有双十一、双十二营销活动带来的增长。我们可以再按月分析来验证我们的结论:
- 月销量
SELECT DATE_FORMAT(`day`, '%Y-%m' ) ,COUNT( buy_mount) FROMtianchi_mum_baby_trade_historyGROUP BY DATE_FORMAT( `day`, '%Y-%m' ) ORDER BY DATE_FORMAT( `day`, '%Y-%m' );
还是以2013、2014年为例,2013年2月份、2014年1月份为全年销量最低,通过万年历查询我们知道这两个月份刚好位当年的春节所在的月份,11月份分别为两年的销售高峰。初步印证了我们关于春节和双十一营销活动对销量带来影响的猜想。 我们可以更进一步,以天为单位来观察销量数据:
- 日销量
SELECT DATE_FORMAT( `day`, '%Y-%m-%d' ) ,COUNT(buy_mount) FROM tianchi_mum_baby_trade_history
GROUP BY DATE_FORMAT( `day`, '%Y-%m-%d' )
ORDER BY DATE_FORMAT( `day`, '%Y-%m-%d' );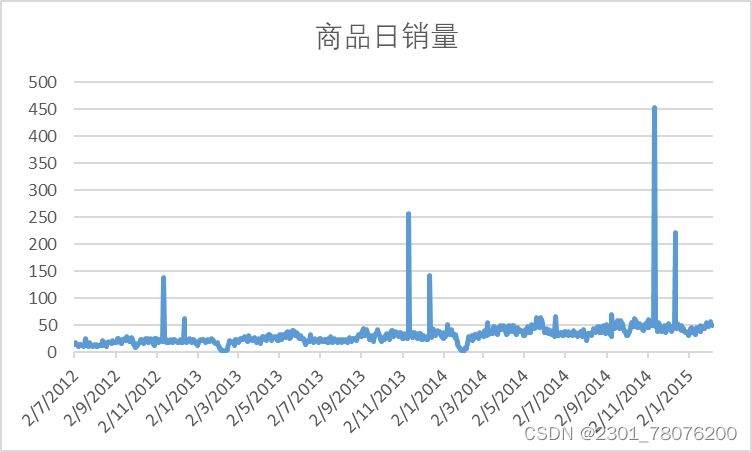
可以看到,相比其他日期,双11购物节当天的销量出现了顶峰。 完成年/季度/月/日的销量分析后,我们再来看看商品类目的销售情况。
2.类别分析
商品销量按照类目分类有什么规律?哪些类目的商品更有价值?
本次抽样数据共包含6个商品大类(一级类目),662个商品二级类目。因本次抽样数据样本量较小,因此我们主要分析商品一级类目。 我们先来看看商品一级类目的销售情况:
1.category_1购买人数
SELECT COUNT(category_1), category_1 FROM
tianchi_mum_baby_trade_history
GROUP BY category_1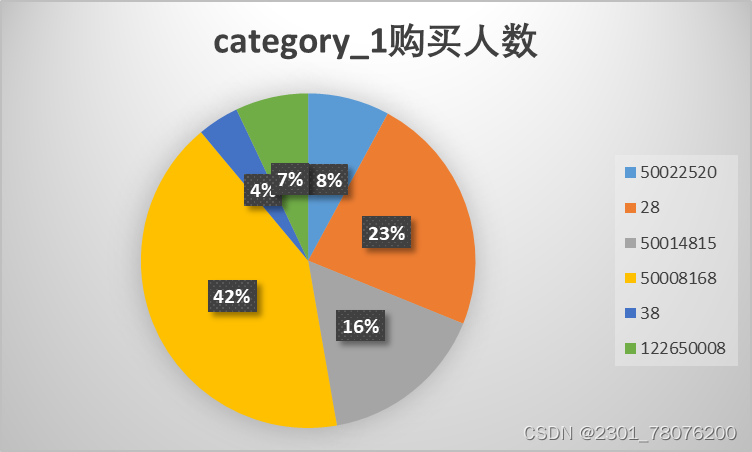
从购买频次上,最受用户喜欢的前三类商品分别是50008168、28、50014815;
2.category_1销量
SELECT category_1,SUM(buy_mount) FROM
tianchi_mum_baby_trade_history
GROUP BYcategory_1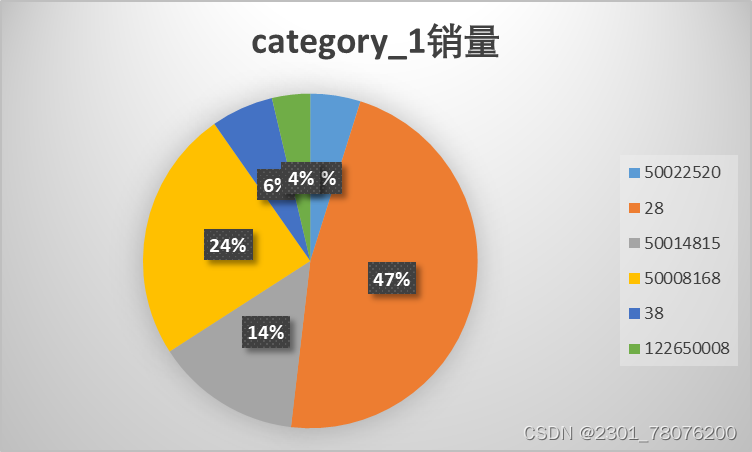
以商品销量视角来看,最受大客户喜欢的前三类商品分别是28、50014815、50008168。
无论是从商品的购买频次还是商品销量上来看,商品一级分类可划分为两个梯度:畅销用品(50008168、28、50014815)及 一般用品(38、50022520、122650008),因此下一阶段主要针对畅销用品销量进行分析。
针对以上现象,平台或许可以将三类畅销商品展示在母婴用品相关购物主页上,以减轻用户购买负担,进一步提升畅销品销量。
3.性别分析
不同性别的婴幼儿购买行为相似吗?是否符合我们的常识呢?
根据用户的宝宝性别和各种类商品的销量情况,分析不同性别宝宝的购买偏好。
- 婴儿性别与用户购买频次关系
SELECT COUNT(gender) FROM tianchi_mum_babyuser
WHERE gender = 0;SELECT COUNT(gender) FROM tianchi_mum_babyuser
WHERE gender = 1;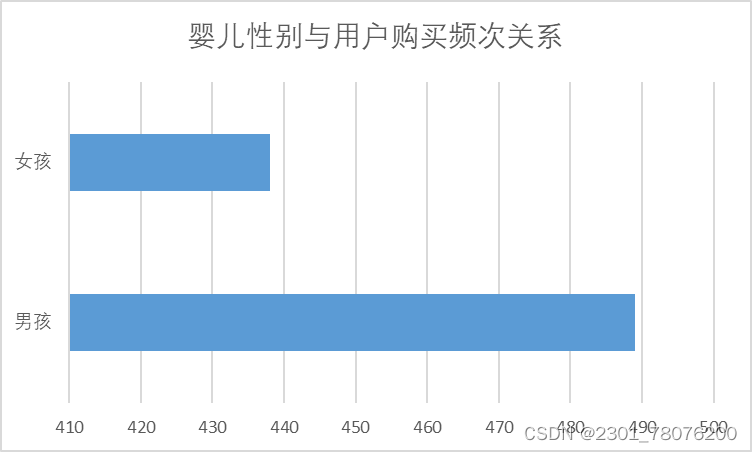
- 婴儿性别与用户购买量的关系
SELECT b.gender , SUM(buy_mount) FROM
tianchi_mum_babyuser b JOIN tianchi_mum_baby_trade_history t ON b.user_id = t.user_id
GROUP BYb.gender;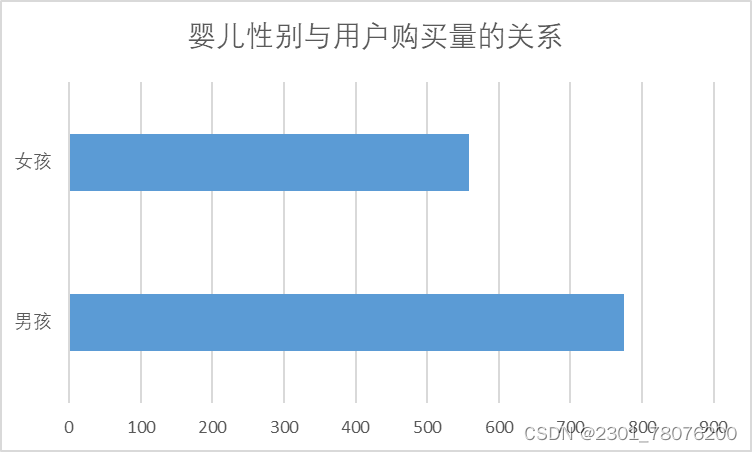
我们再来统计性别在商品大类销售中的体现,看看能看到什么规律:
- 男孩的类别销量统计:

- 女孩的类别销量统计:
SELECT t.category_1 ,SUM(buy_mount) ,b.gender FROM
tianchi_mum_babyuser b JOIN tianchi_mum_baby_trade_history t ON b.user_id = t.user_id
WHERE b.gender=1
GROUP BYt.category_1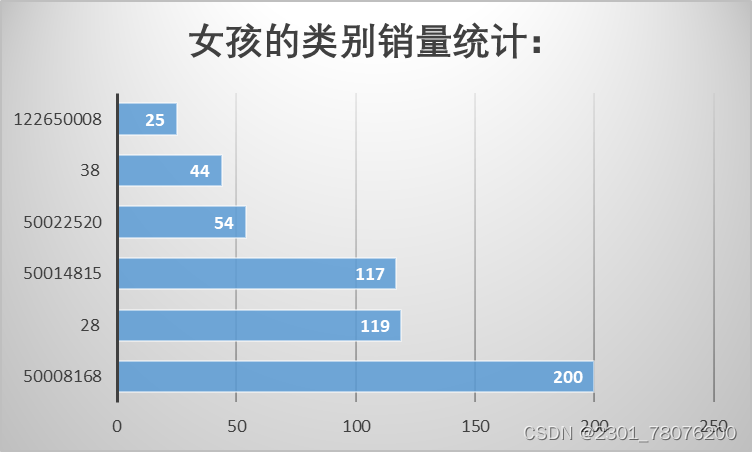
从上面图表中可以看出,一级类别28、50008168和50014815三种类别销量最高,且在各年份中这三类商品的销量一直较高,所以可以大力推广宣传和供应这三类商品。男性宝宝和女性宝宝都比较偏爱于50008168类商品,可以重点将这类商品推荐给用户。
总结
本项目对淘宝母婴购物数据集做了初步的数据分析,通过数据分析我们能对业务做出更好的洞察。使用了mysql查询,以及excel制图功能,完成了流量分析、类别分析和用户画像分析的实验。
这篇关于MySQL实战项目:淘宝母婴购物数据可视化分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






