本文主要是介绍【参赛作品95】DLI Flink SQL+kafka+(opengauss和mysql)进行电商实时业务数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:吴毅
电商实时业务数据分析案例,
测试环境:操作系统:EulerOS_2.8_ARM-20200308_20200308192159
硬件配置:4vCPUs | 16 GiB | kc1.xlarge.4 IP地址:192.168.0.2
在上一篇已经部署好docker和docker版的opengauss。
1 部署docker版的kafka,要找支持arm64的docker版kafka。
1.1 先部署支持arm64的zookeeper,命令如下:
docker pull pi4k8s/k8szk:v3.4.14 docker run -itd --name zookeeper -p 21810:2181 -e ZK_REPLICAS=1 -e ZK_HEAP_SIZE=512M --hostname=zk-1 -v /opt/moudles/zookeeper/data:/var/lib/zookeeper -v /opt/moudles/zookeeper/log:/var/log/zookeeper pi4k8s/k8szk:v3.4.14 /bin/bash -c "/usr/bin/zkGenConfig.sh && /usr/bin/zkServer.sh start-foreground"
1.2 部署支持arm64的kafka
docker pull iecedge/cp-kafka-arm64:5.0.1 docker run -d --name=kafka -p 1099:1099 -p 9092:9092 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=192.168.0.2:21810 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.2:9092 -e KAFKA_JMX_PORT=1099 -e KAFKA_JMX_HOSTNAME=192.168.0.2 -e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 -e KAFKA_HEAP_OPTS="-Xmx512M -Xms512M" -v /opt/moudles/kafka/data:/var/lib/kafka/data iecedge/cp-kafka-arm64:5.0.1
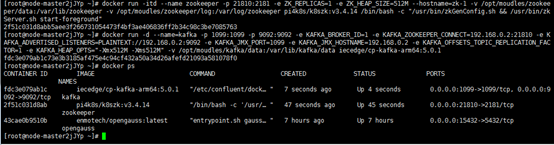
** 1.3 部署完后,下载kafka的源码包:**
cd /opt/softwares wget https://archive.apache.org/dist/kafka/2.3.0/kafka_2.12-2.3.0.tgz tar zxf /opt/softwares/kafka_2.12-2.3.0.tgz -C /opt/modules/ cd /opt/modules/kafka_2.12-2.3.0/bin
1.4 创建topic
./kafka-topics.sh --create --zookeeper 192.168.0.2:21810 --replication-factor 1 --partitions 1 --topic trade_order
1.5 查看创建topic的数目
./kafka-topics.sh --list --zookeeper 192.168.0.2:21810
1.6 kafka生产者
./kafka-console-producer.sh --broker-list 192.168.0.2:9092 --topic trade_order
1.7 kafka消费者
./kafka-console-consumer.sh --bootstrap-server 192.168.0.2:9092 --topic trade_order --from-beginning
特别注意要放开9092(Kafka连接端口)。
2. 连接opengauss和创建表
2.1 连接opengauss
gsql -d testdb -U wuyi -p 5432 –r
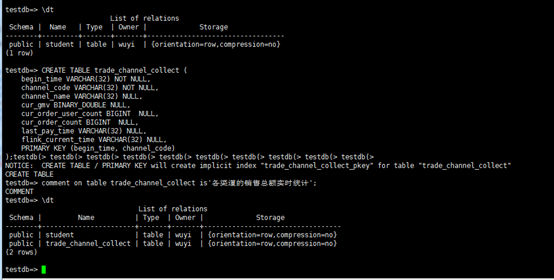
2.2 创建表trade_channel_collect
CREATE TABLE trade_channel_collect (begin_time VARCHAR(32) NOT NULL,channel_code VARCHAR(32) NOT NULL,channel_name VARCHAR(32) NULL,cur_gmv BINARY_DOUBLE NULL,cur_order_user_count BIGINT NULL,cur_order_count BIGINT NULL,last_pay_time VARCHAR(32) NULL,flink_current_time VARCHAR(32) NULL,PRIMARY KEY (begin_time, channel_code)
);
comment on table trade_channel_collect is'各渠道的销售总额实时统计';
3 创建 DLI 增强型跨源
3.1 在控制台单击“服务列表”,选择“数据湖探索”,单击进入DLI服务页面。
单击“队列管理”,在队列列表中您所创建的通用队列
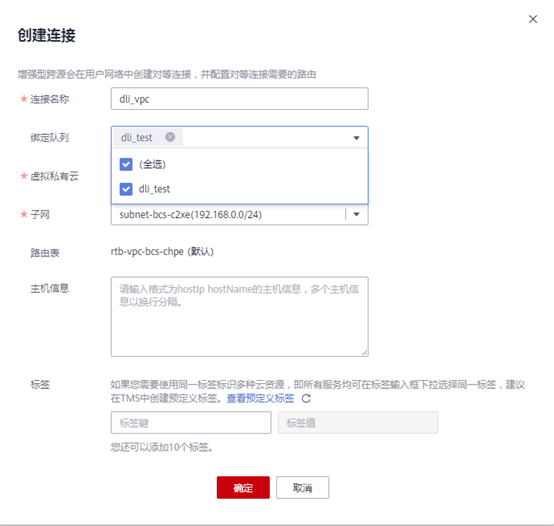
3.2 单击“跨源连接” >“增强型跨源” >“创建”。
配置如下:
– 绑定队列:选择您所创建的通用队列。
– 虚拟私有云:选择 Kafka 与 opengauss 实例所在的VPC
– 子网:选择 Kafka 与 opengauss 实例所在的子网。
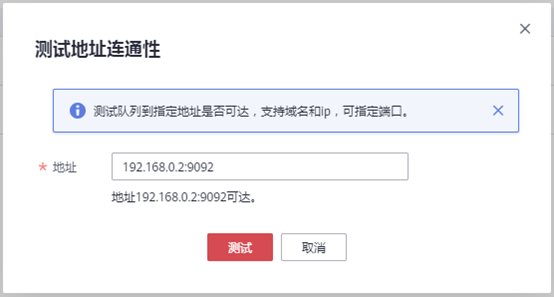
3.3 测试队列与kafka和opengauss实例连通性。
单击“队列管理”,选择您所使用的队列,单击“操作”列中的“更多” >“测试地址连通性”

3.4 创建并提交 Flink 作业
单击DLI控制台左侧“作业管理”,选择“Flink作业”。单击“创建作业”。
– 类型:选择作业类型为: Flink OpenSource SQL。
– 名称:自定义
代码:
--********************************************************************--
-- 数据源:trade_order_detail_info (订单详情宽表)
--********************************************************************--
create table trade_order_detail (order_id string, -- 订单IDorder_channel string, -- 渠道order_time string, -- 订单创建时间pay_amount double, -- 订单金额real_pay double, -- 实际付费金额pay_time string, -- 付费时间user_id string, -- 用户IDuser_name string, -- 用户名area_id string -- 地区ID
) with ("connector.type" = "kafka","connector.version" = "0.10","connector.properties.bootstrap.servers" = "192.168.0.2:9092", -- Kafka连接地址-- "connector.properties.group.id" = "kafka-test", -- Kafka groupID"connector.topic" = "test", -- Kafka topic"format.type" = "json","connector.startup-mode" = "latest-offset"
);
––
– 结果表:trade_channel_collect (各渠道的销售总额实时统计)
––
create table trade_channel_collect(
begin_time date, –统计数据的开始时间
channel_code varchar, – 渠道编号
channel_name varchar, – 渠道名
–cur_gmv INTEGER, – 当天GMV
cur_order_user_count bigint, – 当天付款人数
cur_order_count bigint, – 当天付款订单数
last_pay_time varchar, – 最近结算时间
flink_current_time varchar,
primary key (begin_time, channel_code) not enforced
) with (
“connector.type” = “jdbc”,
“connector.url” = “jdbc:postgresql://192.168.0.2:15432/testdb”, – opengauss连接地址,jdbc格式
“connector.table” = “trade_channel_collect”, – opengauss表名
“connector.driver” = “org.postgresql.Driver”,
“connector.username” = “wuyi”, – opengauss用户名
“connector.password” = “xxxxx”, – opengauss密码
“connector.write.flush.max-rows” = “1000”,
“connector.write.flush.interval” = “1s”
);
––
– 临时中间表
––
create view tmp_order_detail
as
select *
, case when t.order_channel not in (“webShop”, “appShop”, “miniAppShop”) then “other”
else t.order_channel end as channel_code –重新定义统计渠道 只有四个枚举值[webShop、appShop、miniAppShop、other]
, case when t.order_channel = “webShop” then _UTF8"网页商城"
when t.order_channel = “appShop” then _UTF8"app商城"
when t.order_channel = “miniAppShop” then _UTF8"小程序商城"
else _UTF8"其他" end as channel_name –渠道名称
from (
select *
, row_number() over(partition by order_id order by order_time desc ) as rn –去除重复订单数据
, concat(substr(“2021-03-25 12:03:00”, 1, 10), " 00:00:00") as begin_time
, concat(substr(“2021-03-25 12:03:00”, 1, 10), " 23:59:59") as end_time
from trade_order_detail
where pay_time >= concat(substr(“2021-03-25 12:03:00”, 1, 10), " 00:00:00") –取今天数据,为了方便运行,这里使用"2021-03-25 12:03:00"替代cast(LOCALTIMESTAMP as string)
and real_pay is not null
) t
where t.rn = 1;
– 按渠道统计各个指标
insert into trade_channel_collect
select
‘begin_time’ –统计数据的开始时间
, cast(channel_code as varchar) as channel_code
, cast(channel_name as varchar) as channel_name
, cast((COALESCE(sum(real_pay), 0) as integer) as cur_gmv) –当天GMV
, ((count(distinct user_id) as bigint) as cur_order_user_count –当天付款人数
, ((count(1) as bigint) as cur_order_count) –当天付款订单数
, cast((max(pay_time) as last_pay_time) as varchar) –最近结算时间
, cast((LOCALTIMESTAMP as flink_current_time) as varchar) –flink任务中的当前时间
from tmp_order_detail
where pay_time >= concat(substr(“2021-03-25 12:03:00”, 1, 10), " 00:00:00")
group by begin_time, channel_code, channel_name;
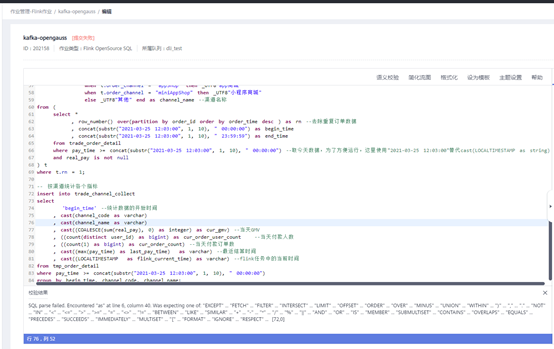
只要是kafka出来的数据是string类型,而opengauss不支持string。使用cast()函数也无法转换成功。下面使用mysql数据库来连接一下。Mysql数据类型兼容性好。
4. docker版mysql的部署
4.1 安装mysql
docker search biarms/mysql:5.7.30 docker pull biarms/mysql:5.7.30 docker run -d --name mysql57 --hostname= mysql57 -e MYSQL_ROOT_PASSWORD=123456 -p 3306:3306 biarms/mysql:5.7.30
特别要注意,mysql5.7要mysql:5.7.30以上的版本才能支持arm64
docker exec -it mysql57 /bin/bash docker cp mysql57:/etc/mysql/my.cnf /root/ /etc/mysql/mysql.conf.d/mysqld.cnf docker cp mysql57:/etc/mysql/mysql.conf.d/mysqld.cnf /root/
vi /root/mysqld.cnf [mysqld] character_set_server=utf8 [client] default-character-set=utf8 docker cp /root/mysql.cnf ,mysql:/etc/mysql/mysql.conf.d/ docker restart mysql57
reate database dli_demo DEFAULT CHARACTER SET = utf8mb4;
CREATE TABLE `dli_demo`.`trade_channel_collect` (`begin_time` VARCHAR(32) NOT NULL,`channel_code` VARCHAR(32) NOT NULL,`channel_name` VARCHAR(32) NULL,`cur_gmv` DOUBLE UNSIGNED NULL,`cur_order_user_count` BIGINT UNSIGNED NULL,`cur_order_count` BIGINT UNSIGNED NULL,`last_pay_time` VARCHAR(32) NULL,`flink_current_time` VARCHAR(32) NULL,PRIMARY KEY (`begin_time`, `channel_code`)
) ENGINE = InnoDBDEFAULT CHARACTER SET = utf8mb4COLLATE = utf8mb4_general_ciCOMMENT = '各渠道的销售总额实时统计';
4.2 查看创建topic的数目
cd /opt/modules/kafka_2.12-2.3.0/bin
./kafka-topics.sh --list --zookeeper 192.168.0.2:21810
# # kafka生产者
./kafka-console-producer.sh --broker-list 192.168.0.2:9092 --topic trade_order
kafka消费者
./kafka-console-consumer.sh --bootstrap-server 192.168.0.2:9092 --topic trade_order --from-beginning
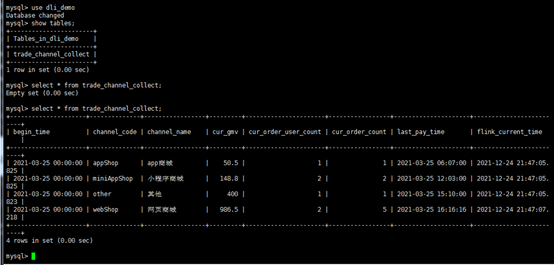
获得的数据连接华为云DLV,可以大屏数据可视化
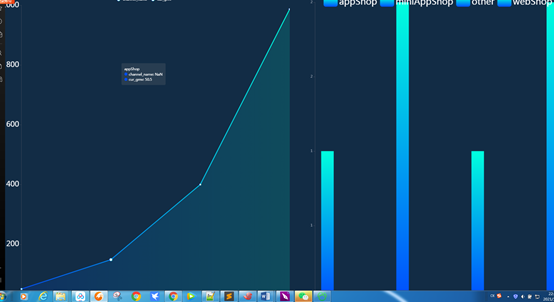
通过对opengauss和mysql的操作,可以很容易发现,mysql对数据类型兼容比较好。而且在创建表时,在数据库,表名和字段加上单引号或双引号都能成功建表,但是opengauss缺不行。Opengauss虽然有很多特性,但是在string的转换不是很好用,找了cast()函数还有其他方法都无法转换,也有可能是我水平不行,原本还想写关于opengauss的AI方面的特性,但是由于这个问题花了一段时间。只能等下次活动再写一下关于AI的特性。
这篇关于【参赛作品95】DLI Flink SQL+kafka+(opengauss和mysql)进行电商实时业务数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





