本文主要是介绍语音情感基座模型emotion2vec,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在语音技术领域,准确理解用户的语音指令和意图是构建高效人机交互系统的基础。一个高品质的语音交互系统不仅需要理解字面上的语言内容,更应捕捉到说话者语音中蕴含的情感信息。这正是语音情感识别(SER)技术要解决的问题:通过分析语音的声调、节奏、强度等副语言学信息,来判断说话者的情感状态,从而实现对人类意图的更真实和自然的理解。
技术亮点:
一、SOTA效果的通用语音情感表征模型emotion2vec
二、开源语音情感识别基座模型
情感识别技术可以应用于各种场景,例如客服机器人可以根据客户语气的焦急程度调整其响应策略,智能助手可以根据用户情绪的变化提供更符合心理需求的建议,情感健康应用可以监测和支持用户的情感状态。
在此背景下,上海交通大学、阿里巴巴、复旦大学和香港中文大学的研究者们联手开发了一个通用的语音情感表征模型emotion2vec [1]。这一模型利用自监督学习方法,在大量无标记的公开情感数据上进行预训练,成功地学习到了高度通用的语音情感特征。在多种语言和不同场景的数据集上测试表明,emotion2vec在多种情感任务上的表现超越了现有的最先进技术。emotion2vec的推出,为众多场景中的情感理解提供了强大的技术支持,有望极大地提升用户体验和满意度。
基于emotion2vec,研究者们进一步训练了一个语音情感识别基座模型。具体来说,首先使用语音情感识别学术数据集fine-tune emotion2vec,然后对15万小时中英数据进行标注,筛选文本情感与语音情感相同,并且置信度高的数据(超过1万小时)再次fine-tune emotion2vec,获得该版本权重。相对以往工作,通过迭代训练和大幅度提升数据量,该模型可以作为语音情感识别的基座模型,目前已经开源,在线体验demo已经在modelscope上线。
emotion2vec通用语音情感表征模型👇:
https://www.modelscope.cn/models/iic/emotion2vec_base/summary
emotion2vec语音情感识别基座模型在线体验👇:
https://www.modelscope.cn/models/iic/emotion2vec_base_finetuned/summary
论文链接👇:
https://arxiv.org/abs/2312.15185
开源代码仓库👇:
https://github.com/ddlBoJack/emotion2vec
研究问题
在人工智能领域,从语音中提取情感表现是诸如语音情感识别(SER)和情感分析等情感相关任务的基础步骤。传统的方法通常使用滤波器组(FBanks)或梅尔频率倒谱系数(MFCCs)作为语音特征,但这些特征在语义信息方面的表达是有限的,因此在情感任务上表现有限。为了改进性能,流行的方法转向利用基于语音的自监督学习(SSL)预训练模型提取的特征,这确实在一定程度上带来了显著的性能提升。
然而,一个潜在的挑战是现有的SSL模型并不完全适用于情感任务。先前的研究尝试对SSL模型进行无微调、部分微调和全部微调来适应SER任务,并在IEMOCAP数据集上得出了一些经验性结论。这种方法是一种临时的解决方案,因为,一方面,对SSL模型进行微调需要大量的计算成本;另一方面,这些结论可能特定于数据或受到模型限制。
最近有研究者提出了Vesper [2]的SER模型,该模型通过WavLM-large模型在情感数据中蒸馏得到。Vesper专门设计用于执行SER任务,但其通用表示能力仍有待验证。因此,迫切需要一种通用的基于语音的情感表示模型,以支持在多样化情感任务中提取语音特征。
为了应对这一挑战,我们提出了emotion2vec,这是一种通用的情感表示模型。它通过在262小时的开源情感数据上进行自监督预训练,并使用在线蒸馏范式来获得。鉴于音频中全局信息和局部细节都能表达情感,我们提出了一种结合句子级损失和帧级损失的预训练策略,来更好地捕捉情感信息。这种策略能够帮助模型学习到更为丰富和准确的情感特征,从而提高在各种情感任务上的表现。
提出方法
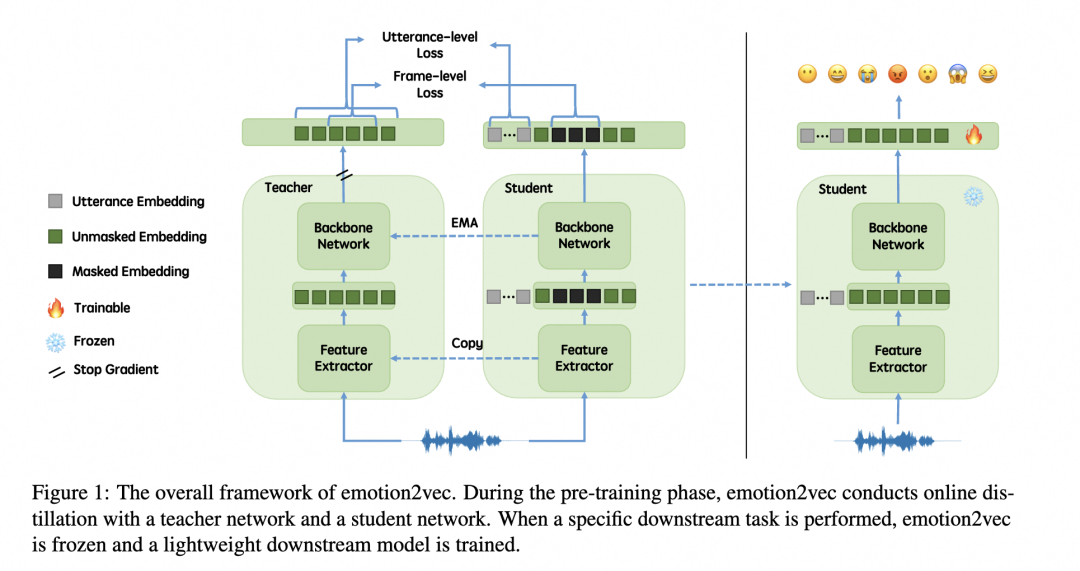
图示:emotion2vec总体框架图
本文提出的emtion2vec为一种自监督预训练方法,其核心为句子级别损失与帧级别损失,以及在线蒸馏范式。
采用data2vec自监督框架,emotion2vec模型在预训练阶段包含两个网络:教师网络T和学生网络S。这两个网络拥有相同的架构,包括由多层卷积神经网络组成的特征提取器F,以及由多层Transformer组成的主干网络B。
>>>句子级别损失
在emotion2vec模型中,句子级别损失(Utterance-level Loss)被引入作为一个预先设定的任务,用于学习整体的全局情绪。我们使用均方误差(Mean Squared Error, MSE)来计算这个损失,其计算方式如下:通过时间池化(temporal pooling)教师网络T的输出和学生网络S的言语嵌入,得到各自的平均值,然后计算两者的均方差,作为句子级别的损失。
文章进一步提出了三种计算句子级别损失的方法,即单嵌入(Token Embedding)、块嵌入(Chunk Embedding)和全局嵌入(Global Embedding)。
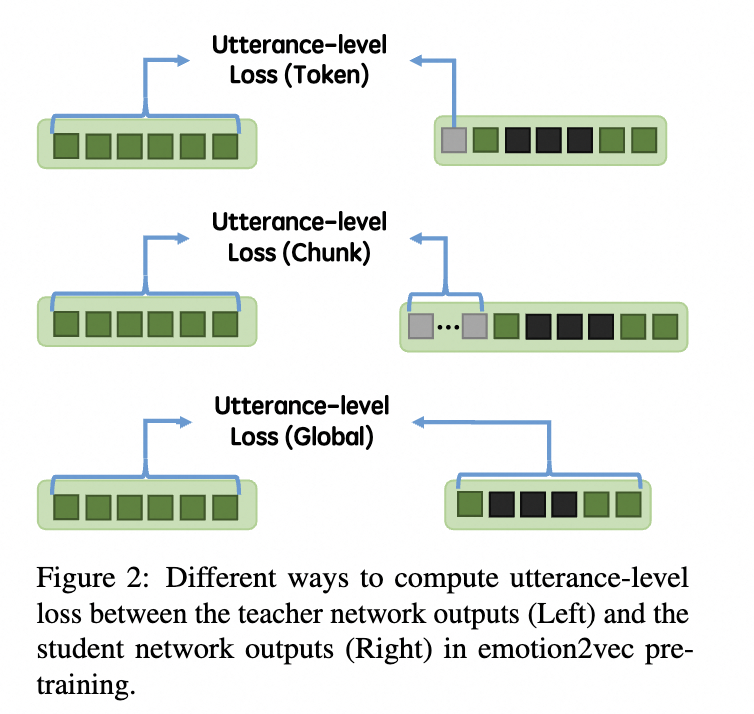
图示:句子级别损失中3种嵌入示意图
单嵌入(Token Embedding):通过一个单一的嵌入来代表学生网络S编码的全局情绪信息。具体来说,就是将可学习的言语嵌入U中的N设置为1。
块嵌入(Chunk Embedding):使用多个嵌入来表征全局情绪信息。在这种情况下,可以在一个块内聚合更多的全局信息。
全局嵌入(Global Embedding):在全局嵌入的情况下,并不添加额外的言语令牌。我们使用学生网络S的帧级别输出嵌入的时间池化结果。
这些方法为模型提供了不同的方式来集成和理解全局情感信息,进而在预训练过程中帮助模型更好地捕捉到情感的全局特性,为后续的情感识别任务奠定基础。
>>>帧级别损失
在emotion2vec模型中,帧级别损失(Frame-level Loss)被设计为一个逐帧的预设任务,用于学习上下文中的情绪信息。按照掩码语言模型(Mask Language Modeling, MLM)预设任务的常见做法,我们只计算被掩码部分的损失。具体来说,帧级别损失L是通过求教师网络T的输出与学生网络S的输出在被掩码的帧上的均方差来计算的。
通过这种方式,模型能够专注于预测那些在输入中被随机掩盖的部分,从而学习到在给定上下文中预测情感所需的信息。这种训练方式促使网络能够更细致地理解情感的局部或帧级别变化,为后续基于帧的情感识别打下坚实基础。
>>>在线蒸馏
在线蒸馏(Online Distillation)是一种自监督学习策略,适用于教师-学生(Teacher-Student)学习框架,在这个框架中,学生网络通过反向传播更新参数,而教师网络则通过指数移动平均(Exponential Moving Average, EMA)更新参数。在学生网络S中,总损失L是帧级别损失和句子级别损失的组合,可以通过一个可调节的权重alpha来平衡这两部分损失。
对于教师网络T,其参数T初始化为与学生网络S相同的参数,然后在每个小批量训练过程中通过EMA进行更新。这种在线蒸馏方法使得模型能够从师生两个网络中迭代学习,不断提升模型对情感特征的捕捉和理解能力。
实验结果
>>>IEMOCAP情感数据集上对比测试
实验结果在Table2中展示,对比了在IEMOCAP数据集上不同自监督学习(SSL)预训练模型的性能,包括大型预训练模型以及最新设计的专门用于语音情感识别(SER)任务的专家模型。我们按照SUPERB [3]的评估标准,冻结了预训练模型,并训练下游线性层,隐藏层的维度设定为256。
从实验结果可以看出,emotion2vec在所有现有的SSL预训练模型中表现最佳,不论是参数规模相似的基础模型还是参数规模更大的大型模型。与通过从WavLM-large蒸馏得到的SER模型Versper-12相比,emotion2vec在使用更少参数的情况下取得了更好的性能。
此外,最新的SER专家模型如TIM-NET、MSTR和DST分别采用了不同规模的上游特征和下游网络。在仅使用线性层的情况下,emotion2vec的性能要么超过要么与这些模型相当,而后者的下游网络参数量分别是emotion2vec的2倍、135倍和114倍。
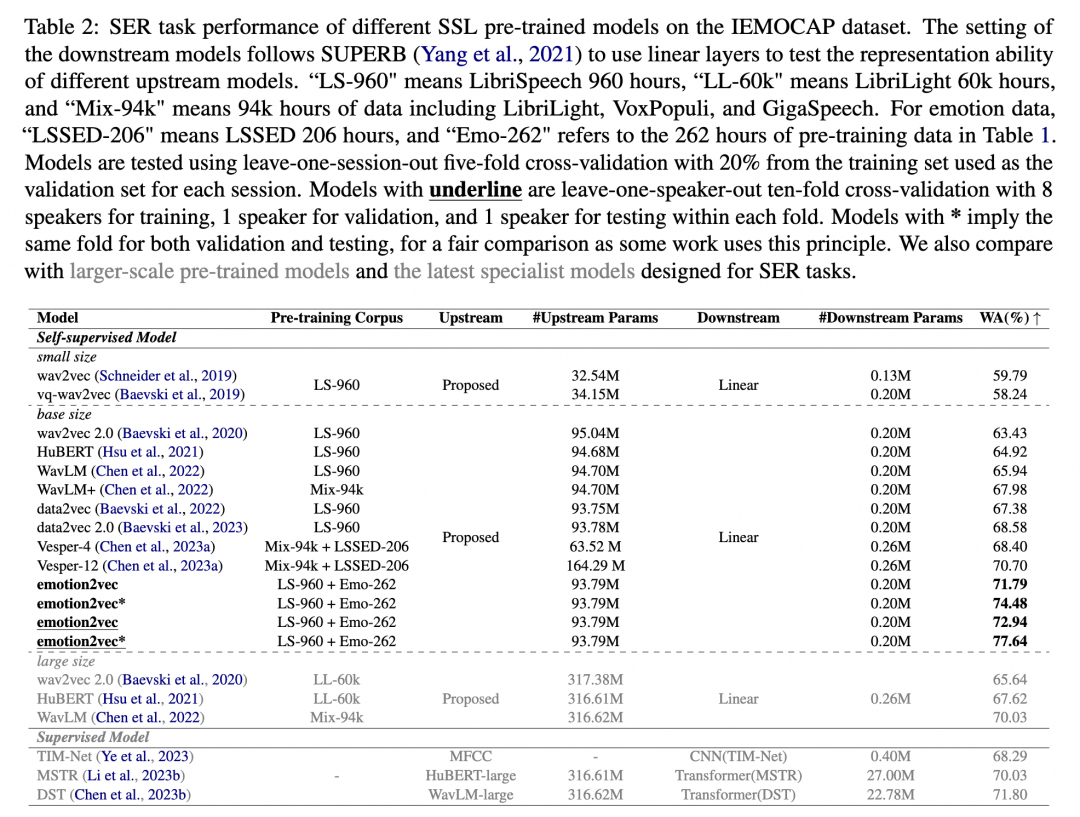
图示:IEMOCAP情感数据上对比结果
我们还在其他主流英语数据集上进行了实验,以证明emotion2vec在不同环境中的泛化能力,实验结果见Table3。其中,MELD是一个嘈杂的数据集,用于在复杂环境中测试模型的语音情感识别(SER)性能。RAVDESS和SAVEE是来自不同录音环境的跨领域数据集。
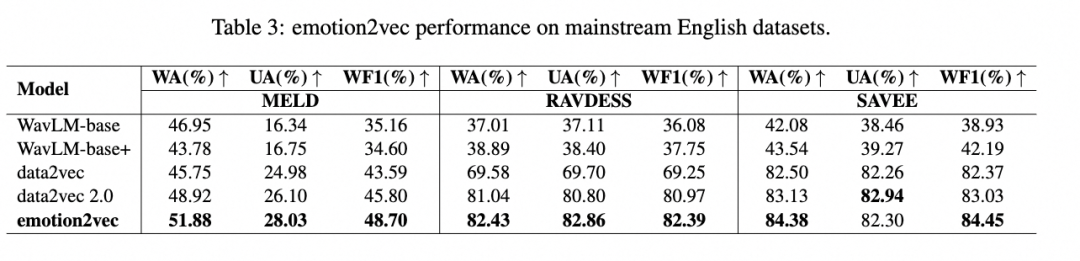
图示:其他主流英语数据集对比
实验结果表明,emotion2vec在不同数据集上都展现了最先进的性能。这证明了emotion2vec不仅能够在被训练的数据集上表现优异,还能够很好地适应不同的录音条件和背景噪声,有着良好的性能泛化能力。
>>>语种泛化性
鉴于各种语言的存在,语音情感识别(SER)数据集之间存在显著的领域差异。模型对未见语言的泛化能力对于SER至关重要。我们验证了emotion2vec及其他基线模型在跨领域语种的SER数据集上的泛化能力。
我们按照SUPERB的评估标准,冻结了预训练模型,并训练下游线性层,隐藏层的维度设定为256,其中WavLM-base、WavLM-base+、data2vec、data2vec 2.0和emotion2vec是我们根据上述实践进行的实现。
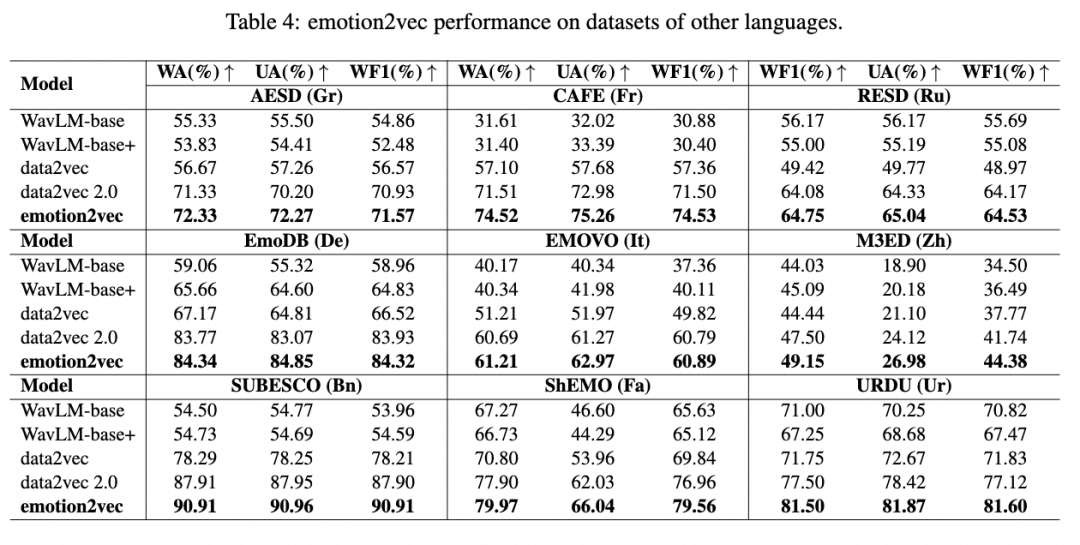
图示:在不同语言数据集上的表现
如Table4所示,emotion2vec在9种不同语言数据集上的加权平均(WA)、无权平均(UA)和加权F1(WF1)分数方面均优于所有SSL基线方法。这些结果证明了emotion2vec能够捕捉跨语言的情感模式,并展现了最先进的性能。这表明emotion2vec不仅在训练见过的语种上表现出色,还能够有效适应和识别训练未见的新语种中的情感特征,具有显著的语种泛化能力。
>>>任务泛化性
为了验证模型的泛化能力,除了语音情感识别之外,我们还测试了其他语音情感任务,包括歌曲情感识别、对话中的情感预测以及情感分析。
歌曲情感识别
歌曲情感识别是音乐情感识别(Music Emotion Recognition, MER)的一个子任务,其目标是识别歌声中表达的情感。按照通常的做法,我们执行五折交叉验证,并在每次训练时保留一个未见折,以此来展示特征的泛化能力。我们的实现包括WavLM-base、WavLM-base+、data2vec、data2vec 2.0和emotion2vec,都是按照上述实践进行的。而L3-NET、SpecMAE和VQ-MAE-S的结果则来自于它们各自的论文。
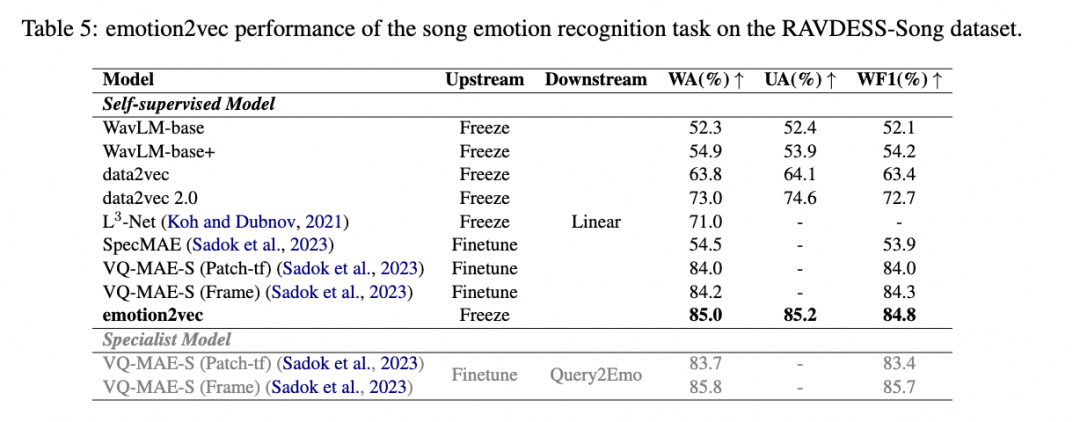
图示:歌曲情感识别
如Table5所示,在歌曲情感识别任务中,即使没有对模型进行微调,emotion2vec也胜过了所有已知的自监督学习(SSL)模型。这突显了emotion2vec在捕捉和理解歌曲中情感特征方面的卓越性能,进一步证明了其在不同情感识别任务中的有效性和强大的泛化能力。
对话中的情感预测
对话中的情感预测(EPC)指的是基于历史对话信息预测特定说话人未来的情感状态。我们复现了\cite{shi2023emotion}的方法,除了语音特征是使用我们提出的emotion2vec获得的。
简言之,该模型使用具有层次结构的多个GRU来进行情感预测。每次预测都会取对话的前6个回合,每个回合中一个说话人可以说多个话语。网络维度、超参数和训练策略与参考实现保持一致,并采用留一发言人外十折交叉验证。对于语音模态,输入是768维的emotion2vec特征;对于文本模态,输入是378维的BERT特征;对于语音+文本多模态,输入是emotion2vec特征和BERT特征的连接,也与参考实现保持一致。结果表明,在EPC任务中,用emotion2vec替换语音特征后,在单一语音模态和语音-文本多模态中均有性能提升。
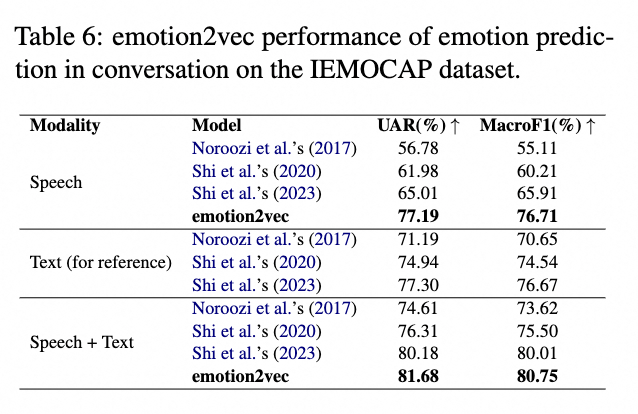
图示:对话中的情感预测
情绪分析
情绪分析是一项分析文本或语音的任务,旨在判断所传达的情感状态是积极的、消极的还是中性的。根据Lian et al. [5]的做法,我们去除了中性情绪,并在CMU-MOSI和CMU-MOSEI的标准训练/验证/测试集上分别进行二分类任务。同样遵循Lian et al. [5]的做法,我们使用预训练模型最后四层特征的平均值来训练下游线性层。
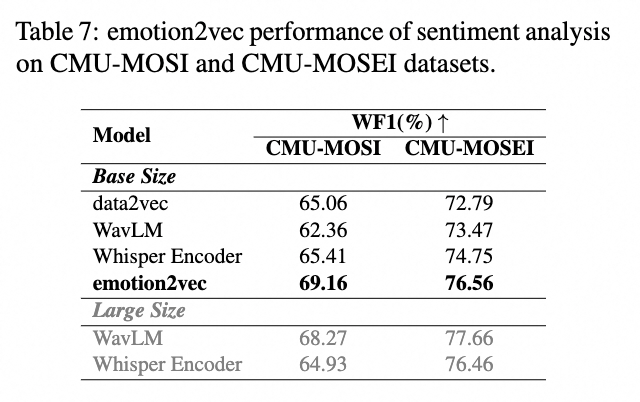
图示:情绪分析
如表格7所示,emotion2vec在使用自监督学习训练的data2vec和WavLM,以及在使用自动语音识别(ASR)任务进行监督学习训练的Whisper Encoder中表现最佳。这表明emotion2vec在情绪分析任务上的性能优于其他预训练模型,并证实了其在不同类型的情感任务中具有良好的泛化能力。
>>>表征可视化
为了探索emotion2vec和其他自监督学习(SSL)基线模型在情感表示学习上的直观效果,我们利用UMAP技术对WavLM、data2vec和emotion2vec学习的表示进行了可视化,相关的图像见图3。
我们在IEMOCAP数据集上采用留一会话外(leave-one-session-out)评估策略,并在SUBESCO数据集上采用8:2的保留集评估,两种情况下我们都从训练集中随机选择了10%的样本作为验证集。具体来说,为了公平比较,在不同SSL模型相同的训练阶段之后,我们选择了第一线性层的表示进行可视化。
图4上可视化了不同SSL模型对唤起值(arousal)的表示。在某种意义上,唤起值指的是情感强烈程度。图3上(a) 和图3上 (b)显示高唤起值和唤起值情感类别之间存在大量重叠。相比之下,图3上(c) 显示高唤起值和低唤起值的表示分别聚类,并且特征分布展示了从高唤起值过渡到低唤起值的趋势,与其他方法相比更为合理。
图4下展示了不同SSL模型表示离散情感类别的能力。如图3下 (a)和图3下 (b)所示,WavLM和data2vec存在类别混淆的问题。相反,emotion2vec学习的特征展现了更高的类内紧凑性和更大的类间间隔。
这些结果表明emotion2vec提供了更具类别区分性和情感感知性的表示,以支持其卓越的性能。

图示:学习到的表征可视化
Future Work
在这篇论文中,我们提出了emotion2vec,这是一个通用的情感表示模型。emotion2vec通过自监督在线蒸馏在262小时的未标记情感数据上进行预训练,从而获得了通用的情感表示能力。我们证明了在情感预训练过程中结合使用句子级别损失和帧级别损失的策略是有效的。
通过广泛的实验,我们证明了所提出的emotion2vec具有跨不同任务、语言和场景提取情感表示的能力。在未来,我们将探索情感表示模型的规模化定律,即如何通过更多数据和更大的模型参数提供更好的表示。这意味着,我们将研究在数据规模和模型复杂性增加时,如何优化情感表示模型的性能,并将情感表示的准确性和泛化能力提升到一个新的水平。
参考文献:
[1] Ma, Ziyang, et al. "emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation." arXiv preprint arXiv:2312.15185 (2023).
[2] Chen, Weidong, et al. "Vesper: A compact and effective pretrained model for speech emotion recognition." IEEE Transactions on Affective Computing (2024).
[3] Yang, Shu-wen, et al. "SUPERB: Speech processing universal performance benchmark." Proc. Interspeech (2021).
[4] Shi, Xiaohan, et al. "Emotion Awareness in Multi-utterance Turn for Improving Emotion Prediction in Multi-Speaker Conversation." Proc. Interspeech (2023).
[5] Lian, Zheng, et al. "MER 2023: Multi-label learning, modality robustness, and semi-supervised learning." Proceedings of the 31st ACM International Conference on Multimedia. (2023).
文章转载于 阿里语音AI 马子阳 高志付等
这篇关于语音情感基座模型emotion2vec的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







