本文主要是介绍Focal Modulation Networks聚焦调制网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
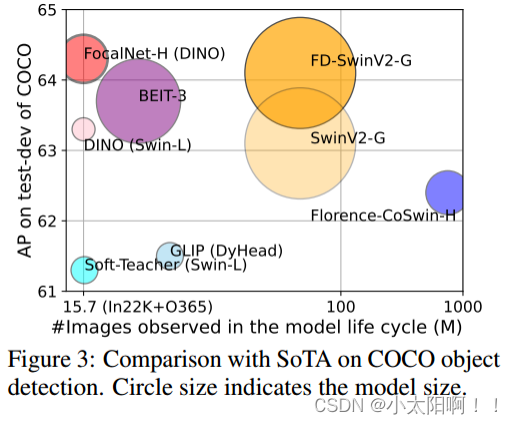
我们提出了 焦点调制网络 (简称 FocalNets) ,其中 自注意( SA )被 Focal Modulation 替换,这种机制 包括三个组件:( 1 )通过 depth-wise Conv 提取分级的上下文信息,同时编码短期和长期依赖;( 2 ) 门控聚合,基于每个 token 的内容选择性的聚集视觉上下文;( 3 )通过点乘或者仿射变换将汇集的信息 注入 query 。大量实验表明, FocalNets 表现出非凡的可解释性,并且在图像分类、对象检测和分割任务上优于具有类似计算成本的SoTA 对应物(例如, Swin 和 Focal Transformer) 。Focal Net主要是在 block 中加入了 Multi-level 的特征融合机制,类似于目标检测中常见的 FPN 结构,同时学习粗粒度的空间信息和细粒度的特征信息。提高网络性能。
1、介绍
Transformer 虽然效果好,但是效率低。为了提升其效率,已经提出了许多模型。
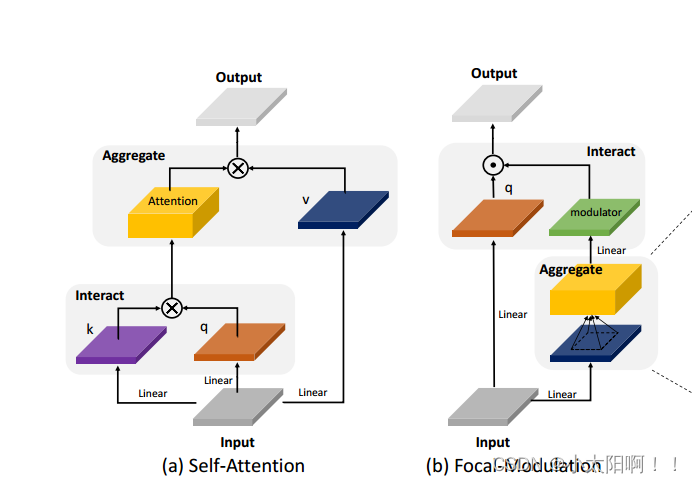
在这项工作中,我们旨在回答一个基本问题,有没有比 SA 更好的办法来建模依赖输入交互?我们首先分析了当前SA 的高级设计。在图 2 中, 2 左侧,我们展示了 ViTs 和 Swin Transformer 中提出的红色查询令牌及其周围橙色令牌之间常用的(窗口式)注意。然而,是否有必要进行如此繁重的互动和聚合?在这项工作中,我们采取了另一种方法 , 首先围绕每个 query 集中聚合上下文,然后用聚合的上下文自适应地 调制 query 。如图 2 右侧所示,我们可以简单地应用查询不可知的焦点聚合 (例如,深度卷积)来生成不同粒度级别的汇总token 。然后,这些汇总的 token 被自适应地聚合到调制器中,调制器最终被注入到query中。这种更改仍然能够实现依赖于输入的令牌交互,但通过将聚合与单个查询解耦,显著简化了过程,因此仅凭几个特性即可实现轻量级交互。我们的方法受到焦点注意力 [95] 的启发 , 焦点注意力执行 多个级别的聚合来捕捉细粒度和粗粒度的视觉上下文 。然而,我们的方法 在每个查询位置提取调制器, 并使用一种简单的方式进行查询 - 调制器交互 。我们将这种新机制称为 Focal Modulation ,用它取代 SA 来构建一个无注意力的架构,简称Focal ModulationNetwork 或 FocalNet。
2、相关工作
self-attention : Transformer 通过将图像分割成一系列视觉标记而首次引入视觉。 我们的焦点调制与 SA 有很大不同,它首先聚合来自不同粒度级别的上下文,然后调制单个查询令牌,为令牌交互提供了一种 无注意力的机制 。对于上下文聚合,我们的方法受到 [95] 中提出的焦点关注的启发。然而,焦点调制的上下文聚合是在每个查询位置而不是目标位置执行的,然后是调制而不是关注。这些机制上的差异导致了效率和性能显著提高。另一项密切相关的工作是Poolformer ,它使用池来总结局部上下文,并总结简单的减法来调整单个输入。尽管效率不错,但它在性能上落后于像Swin 这样的流行视觉变换器,正如我们将要展示的那样,捕捉不同层次的局部结构是至关重要的。
MLP 结构。 Visual MLP 可分为两组:( i) 全局混合 MLP ,如 MLP Mixer 和 ResMLP ,通过各种技术(如门控、路由和傅里叶变换)增强的空间投影来执行视觉标记之间的全局通信。(Ii) 局部混合 MLP 使用空间 移位、置换和伪核混合对附近的 token 进行采样以进行交互 。最近, MixShift MLP 以类似的焦点关注精神,利用了与MLP 的局部和全局交互。 MLP 架构和我们的焦点调制网络都是无需注意的。然而,具有多级上下文聚合的焦点调制自然地捕获了短距离和长距离结构,从而实现了更好的精度- 效率权衡。
3、焦点调制网络
3.1从SA到焦点调制
给定视觉特征图  作为输入 ,通用编码过程通过 T 与其周围 X (例如相邻
作为输入 ,通用编码过程通过 T 与其周围 X (例如相邻 


token )的交互以及上下文中的聚合M,为每个视觉标记  (查询) 生成一个特征表示
(查询) 生成一个特征表示  。
。
self-attention 自我注意模块使用后期聚合过程,公式如下:
其中上下文 X 上的聚合 M1 是在经由交互 T1 计算出查询和目标之间的注意力得分之后执行的。
Focal modulation 相反, Focal modulation 使用公式化为:
其中 首先使用 M2 在每个位置 i 处聚合上下文特征,然后 query 基于聚合 T2 与聚合的特征交互以形成 yi 。 比较等式(1) 和等式 (2) ,我们看到 (i) 焦点调制 M2 的上下文聚合通过共享算子(例如,深度卷积)来分摊 上下文的计算 ,而 SA 中的 M1 在计算上更昂贵,因为它需要对不同查询的不可共享注意力分数求和; (ii) 交互 T2 是 token 与其上下文之间的轻量级算子 ,而 T1 涉及计算 token 到 token 的注意力分数,其具有二次 复杂度。
基于等式( 2 ),我们将我们的 焦点调制实例化为 :
其中 q(.) 是 query 投影函数 ,并且是逐元素乘法。 m(.) 是一个上下文聚合函数,其输出称为调制器 。图 4(a)和 (b) 比较了自注意和焦点调制。所提出的焦点调制具有以下有利特性:
平移不变性 。因为 q(.) 和 m(.) 总是以 query token i 为中心,并且不使用位置嵌入,因此调制对输入特征 图x 的平移是不变的。
显式输入依赖关系 。调制器是通过聚集目标位置 i 周围的局部特征来通过 m(.) 计算的,因此我们的焦点调制是明确依赖于输入的。
空间和通道特定 。作为 m(.) 的指针的目标位置 i 实现空间特定调制。逐元素乘法实现特定于信道的调制。 分离的特征粒度 。 q(.) 为单个 token 保留了最好的信息,而 m(.) 提取了更粗糙的上下文。它们是解耦的,但通过调制进行组合。
3.2 通过m(.)进行上下文聚合
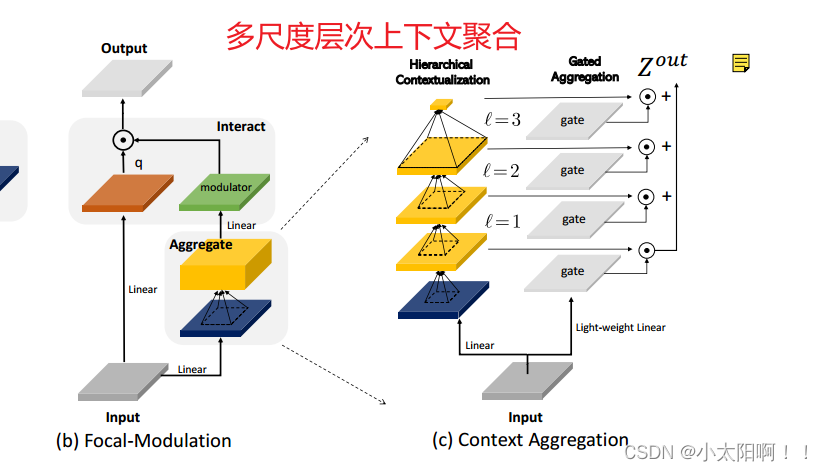
已经证明,短期和长期上下文对视觉建模都很重要。然而,具有更大感受野的单个聚集不仅在时间和内存上计算昂贵,而且还会破坏局部细粒度结构,这对于密集预测任务特别有用。受[95] 的启发,我们 提 出了一种多尺度层次上下文聚合 。如图 4(c) 所示
, 聚合过程由两个步骤组成:分层上下文化以提取不同粒度级别的从局部到全局范围的上下文,以及门 控聚合以将不同粒度级别上的所有上下文特征浓缩到调制器中 。
Step 1: 分层上下文化
给定输入特征图X,我们首先将其投影到具有线性层 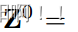
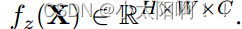 的 新特征空间中。 然后,使用 L 个 depth-wise Conv 的堆栈来
的 新特征空间中。 然后,使用 L 个 depth-wise Conv 的堆栈来 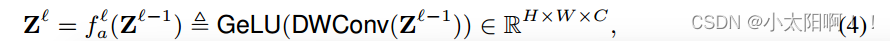 其中,
其中, 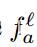 是 第l级的上下文函数,通过内核大小为
是 第l级的上下文函数,通过内核大小为 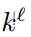 的 的深度卷积 DWConv 实现,然后是 GeLU激活 函数。将深度卷积用于等式 4 的分层上下文化。与池化相比,深度卷积是可学习的,并且具有结构感知能 力。与常规卷积相比,它是通道式的,因此在计算上便宜的多。
的 的深度卷积 DWConv 实现,然后是 GeLU激活 函数。将深度卷积用于等式 4 的分层上下文化。与池化相比,深度卷积是可学习的,并且具有结构感知能 力。与常规卷积相比,它是通道式的,因此在计算上便宜的多。 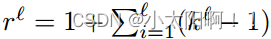 远大于核大小
远大于核大小 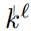 。 为了捕捉整个输入的全局上下文
。 为了捕捉整个输入的全局上下文
获得上下文的分层表示。在焦点级别 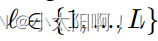 ,输出
,输出 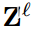 由 以下公式导出:
由 以下公式导出:
等式 (4) 的分层上下文化, 生成 L 个级别的特征图 。在水平l处,有效感受野为:
(可以是高分辨率的) ,我们 在第L级特征图 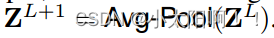 ,
,
上使用全 局平均池化 。因此,我们总共获得了(L+1)个特征图 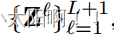 ,它们共同
,它们共同 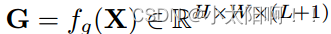
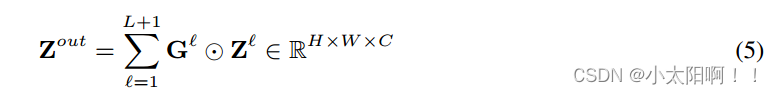
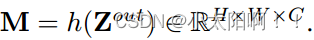

捕获了不同粒度级别的短期和长期上下文。
step2 :门控聚合
在这个步骤中, 通过分层上下文化获得的( L+1) 个特征图被浓缩到调制解调器中 ,在图像中,视觉
token(query) 与其周围上下文之间的关系通常取决于内容本身。例如,该模型可能依赖于局部细粒度特征来编码显著视觉对象的查询,但主要依赖于全局粗粒度特征来编码背景场景的查询。基于这种直觉,我们使用门控机制来控制每个查询从不同级别聚合的数量 。具体地,我们 使用线性层来获得空间和级别 感知的选通权重
然后,我们 通过逐元素乘法 执行加权和以获得具有与输入X相同大小的单个特征图 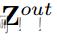
其中,  是级别 的 G 的切片。当可视化这些门控图在图5中,
是级别 的 G 的切片。当可视化这些门控图在图5中, 
我们惊讶地发现,我们的 FocalNet 确实像我们预期的那样自适应地从不同的焦点级别收集上下文 。正如我们所看到的,对于小对象上的 token ,它更多地关注低焦点级别的细粒度局部结构,而统一背景中的 token 需要从更高级别了解更大的上下文 。 到目前为止,所有聚合都是空间的 ,为了实现不同信道之间的通信,我们使用另一个线性层 h(.) 来获得调制器图
在图 6 中,我们在 FocalNet 的最后一层可视化调制器 M 的幅度。有趣的是,调节器会自动更多地关注诱导类别的对象,这意味着解释FocalNets 的一种简单方法。 焦点调制 :给定如上所述的 m(.) 的实现, 等式( 3) 的焦点调制可以在 token 级别重写为 :
其中 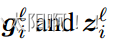 分别是
分别是 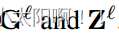 的 位置 i 处的门控值和视觉特征。我们总结了算法
的 位置 i 处的门控值和视觉特征。我们总结了算法 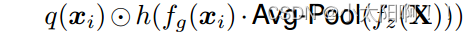
1 中 pytorch 风格伪代码中提出的焦点调制,该算法由几个深度卷积和线性层实现。
3.3与其他建筑设计的关系
基于等式( 6 ),我们在我们的焦点调制和自注意之外的其他相关架构设计之间建立了联系。
深度卷积 已用于增强 SA 的局部结构建模,或纯粹用于实现有效的长范围相互作用。我们的焦点调制也采 用深度卷积作为构建块之一。然而,我们的Focal Modulation 不是直接使用其相应作为输出,而是使用 深度卷积来捕获分层上下文,然后将其转换为调制器来调制每个query 。
挤压和激励( SE ):是在视觉变换器出现之前在 [35] 中提出来的。它利用全局平均池来全局压缩上下 文,然后使用多层感知(MLP )和 Sigmoid 来获得每个通道的激励标量。 SE 可以被认为是焦点调制的一种特殊情况。在等式(6 )中,设置 L=0 ,焦点调制退化为
,类似于 SE 。在我们的实验中,我们研究了这个变体,发现全局上下文远远不足以进行视觉建模。 PoolFormer 由于其简单性而引起了许多关注。它使用平均池在滑动窗口中本地提取上下文,然后使用元素减法调整query token 。它与 SE-Net 有着相似的精神,但使用局部上下文而不是全局上下文,使用减法而不是乘法。把它和Focal Modulation 放在一起,我们可以发现它们都提取了本地上下文,并启用了查询上下文交互,但方式不同。
3.4网络结构
使用与 Swin 和 Focal Transformer 中相同的布局和隐藏尺寸,但用 Focal Modulation 取代了 SA 模块。因 此,我们构建了一系列焦点调制网络(FocalNet) 变体。在 FocalNets 中,我们只需要指定焦点 focal levels(L)的数量和每个级别的内核大小 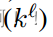 。 为了简单起见,我们将内核大小从较低的焦点级别逐渐增加到较高的焦点级别
。 为了简单起见,我们将内核大小从较低的焦点级别逐渐增加到较高的焦点级别  。
。
这篇关于Focal Modulation Networks聚焦调制网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









